使用IDEA打包scala程序并在spark中运行
一、首先配置ssh无秘钥登陆,
先使用这条命令:ssh-keygen,然后敲三下回车;
然后使用cd .ssh进入 .ssh这个隐藏文件夹;
再创建一个文件夹authorized_keys,使用命令touch authorized_keys;
然后使用cat id_rsa.pub > authorized_keys 即可;
最后使用 chmod 600 authorized_keys修改权限就完成了。
二、创建spark项目
idea创建spark项目的过程这里就略过了,具体可以看这里https://www.cnblogs.com/xxbbtt/p/8143441.html
三、在pom.xml加入相关的依赖包
在pom.xml文件中添加:
<properties>
<spark.version>2.1.0</spark.version>
<scala.version>2.11</scala.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> </dependencies> <build>
<plugins> <plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin> </plugins>
</build>
然后等待就好了。。。
四、编写一个示范程序
创建一个scala类,并写以下代码,也可以是其他的,这里只是测试而已
object first {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount")
val sc = new SparkContext(conf)
val input = sc.textFile("/home/cjj/testfile/helloSpark.txt")
val lines = input.flatMap(line => line.split(" "))
val count = lines.map(word => (word, 1)).reduceByKey { case (x, y) => x + y }
val output = count.saveAsTextFile("/home/cjj/testfile/helloSparkRes")
}
}
这里使用了Spark实现的功能是,计算helloSpark.txt这个文件各个单词出现的次数,并保存在helloSparkRes文件夹中。
五、打包
file->Porject Structure->Artifacts->绿色的加号->JAR->from modules...
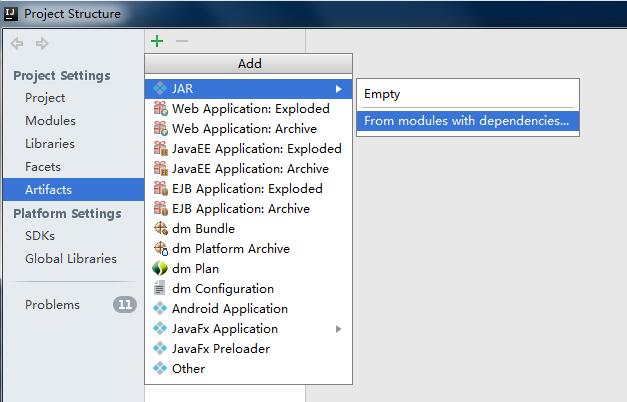
跳出以下对话框,选择要打包的类,然后选择copy to.....选项,这里的意思是只打包这一个类。
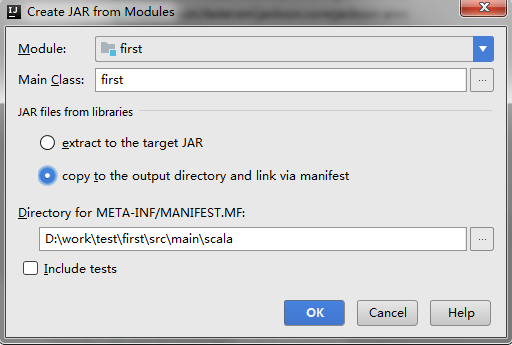
然后点击ok,然后ok。然后build->build Artifacts
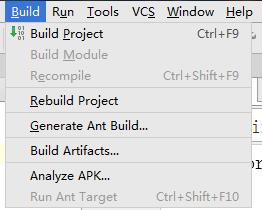
再然后点击build
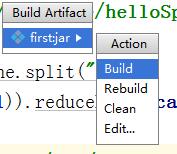
等待build完成。然后可以在项目的这个目录中找到刚刚打包的这个jar包
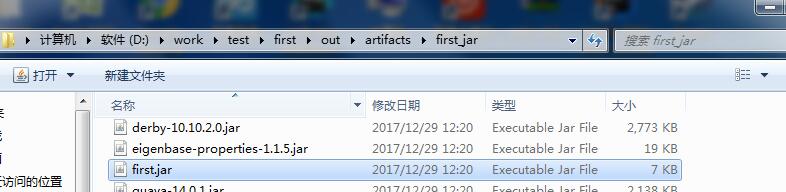
这里的first的我的项目名。
六、启动集群
先将刚才打包的jar包复制到虚拟机中,
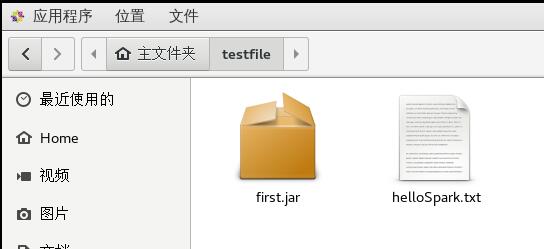
helloSpark.txt是我将要操作的文件。接着就是启动集群,分为三步
- 启动master ./sbin/start-master.sh
- 启动worker ./bin/spark-class
- 提交作业 ./bin/spark-submit
首先进入spark-2.2.1-bin-hadoop2.7文件夹,然后运行命令./sbin/start-master.sh
然后可以打开浏览器,进入localhost:8080,可以看到
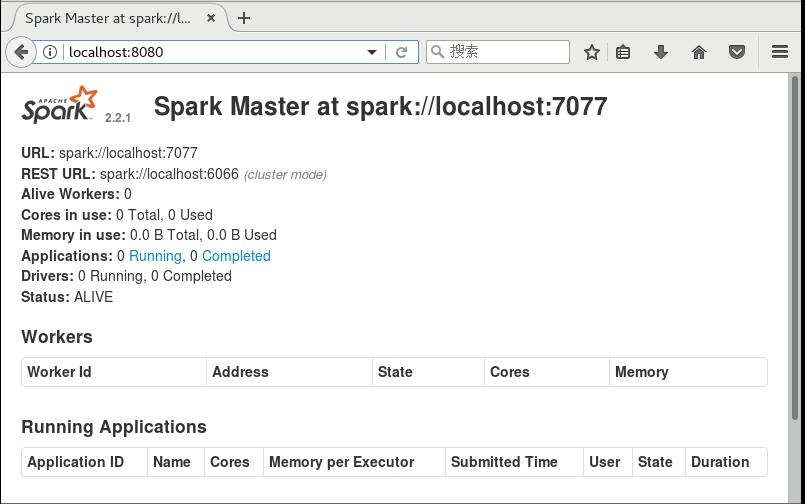
这里的URL spark://localhost:7077需要记下来下一步需要使用,下一步启动work,加上刚刚的URL,可以使用的命令是,
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
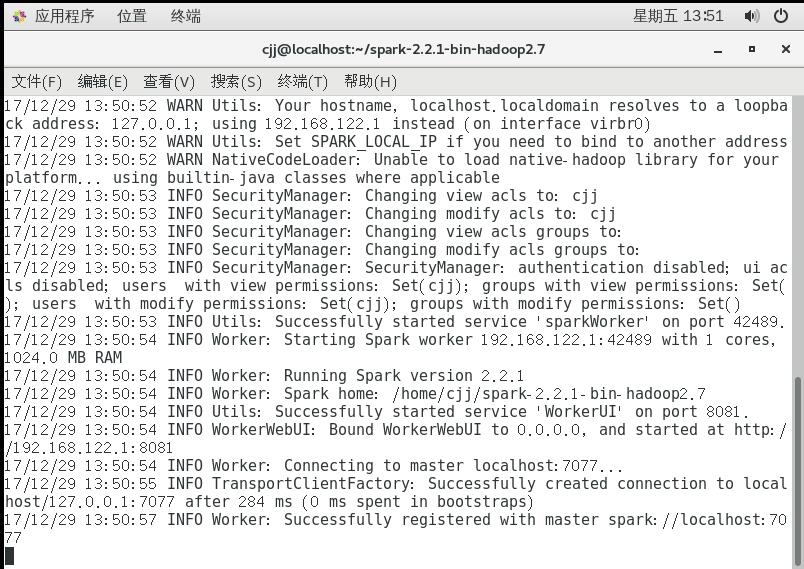
这时启动另一个窗口进行提交作业,同样需要先进入spark文件夹,然后运行命令
./bin/spark-submit --master spark://localhost:7077 --class first /home/cjj/testfile/first.jar
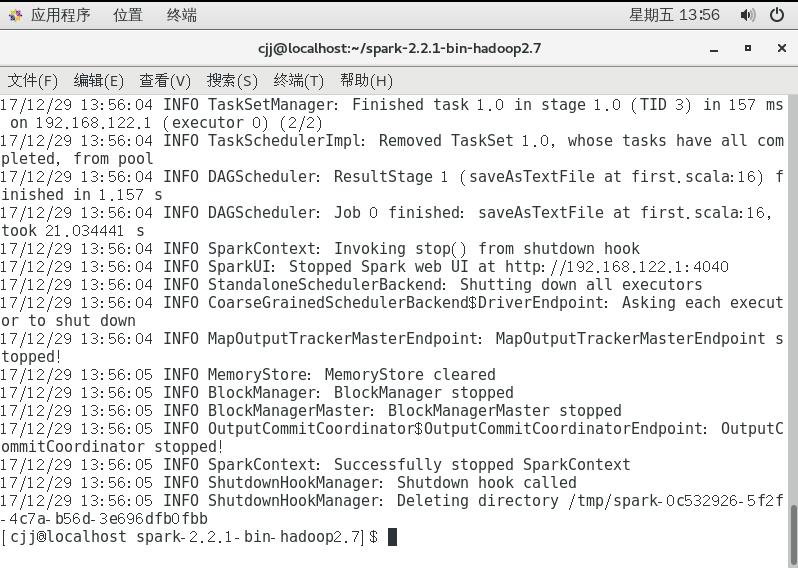
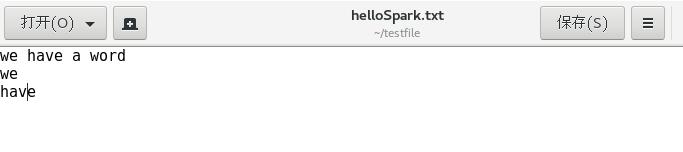
这样就算完成了,我们可以来看看结果,看结果之前需要先看一看helloSpark.txt的内容
结果保存在helloSparkRes中,下面是结果
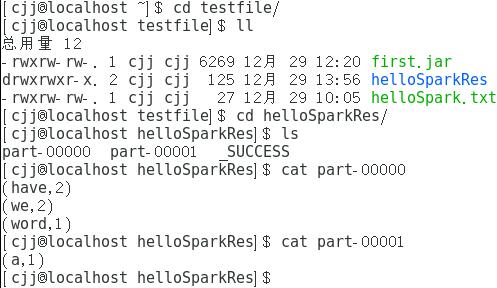
这里的结果告诉我们have和word的个数为2,word和a的个数为1。
使用IDEA打包scala程序并在spark中运行的更多相关文章
- docker 运行jenkins及vue项目与springboot项目(五.jenkins打包springboot服务且在docker中运行)
docker 运行jenkins及vue项目与springboot项目: 一.安装docker 二.docker运行jenkins为自动打包运行做准备 三.jenkins的使用及自动打包vue项目 四 ...
- intellij-idea打包Scala代码在spark中运行
.创建好Maven项目之后(记得添加Scala框架到该项目),修改pom.xml文件,添加如下内容: <properties> <spark.version></spar ...
- 使用IntelliJ IDEA编写Scala在Spark中运行
使用Scala写一个测试代码: object Test { def main(args: Array[String]): Unit = { println("hello world" ...
- 判断Java程序是否在jar中运行
URL url = TextRenderer.class.getResource(""); String protocol = url.getProtocol(); boolean ...
- 关于python程序在VS code中运行时提示文件无法找到的报错
经过测试,在设置文件夹目录时,可以找到当前目录下的htm文件,采用with open()语句可以正常执行程序,如下图. 而当未设置当前目录,直接用vscode执行该程序时,就会报错文件无法找到File ...
- C编译器MinGW安装、下载及在notepad++中运行C程序
一.C编译器MinGW的下载及安装步骤 打开MinGW官网:http://www.mingw.org/ 图一 图二 图三 图四 图五 图六 系统中配置环境变量: 图七 验证是否安装成功: CMD中运行 ...
- sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类
sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类 详述 使用sbt对写的Spark程序打包,过程中没有问题 spark-submit提交jar包运行提示找不到对应的类 解 ...
- 通过IDEA搭建scala开发环境开发spark应用程序
一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安装scala插件,具体安装办法如下. 1.打开idea,点击c ...
- IDEA搭建scala开发环境开发spark应用程序
通过IDEA搭建scala开发环境开发spark应用程序 一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安 ...
随机推荐
- 线性表的顺序存储C++代码实现
关于线性表的概念,等相关描述请参看<大话数据结构>第三章的内容, 1 概念 线性表list:零个或多个数据的有限序列. 可以这么理解:糖葫芦都吃过吧,它就相当于一个线性表,每个 ...
- 三个标签完成springboot定时任务配置
1. 问题描述 Java项目定时任务是必备模块,月高风黑夜跑个批处理,记录或者统计一些系统信息. 2. 解决方案: 结合springboot,只需三个标签就能完成定时任务配置. 2.1 标签1 用在s ...
- ~~函数基础(三):嵌套函数&匿名函数~~
进击のpython 嵌套函数&匿名函数 讲完作用域之后 对变量的作用范围有大致的了解了吗? 讲个稍微小进阶的东西吧 能够帮助你更加的理解全局和局部变量 嵌套函数 玩过俄罗斯套娃不? 没玩过听过 ...
- 【Phabricator】教科书一般的Phabricator安装教程(配合官方文档并带有踩坑解决方案)
随着一声惊雷和滂沱的大雨,我的Phabricator页面终于在我的学生机上跑了起来. 想起在这五个小时内踩过的坑甚如大学隔壁炮王干过的妹子,心里的成就感不禁油然而生. 接下来,我将和大家分享一下本人在 ...
- Python爬虫学习代码
[1]用一个简单的程序来显示Python的数字类型. code: class ShowNumType(object): def __init__(self): self.showInt() self. ...
- .md 文件格式
# .md 文件怎么编写 > 整理一套常用操作,自己来使用 > ## 标题 >> 写法: \# 这是一个一级标题 \## 这是一个二级标题 \### 这是一个三级标题 \### ...
- [USACO09FEB]股票市场Stock Market
题意简述: 给定⼀个DDD天的SSS只股票价格矩阵,以及初始资⾦ MMM:每次买股票只能买某个股票价格的整数倍,可以不花钱,约定获利不超过500000500000500000.最⼤化你的 总获利. 题 ...
- 【Android UI】顶部or底部菜单的循环滑动效果一
实现了分页的滑动效果,做的demo流畅运行 注:貌似支持的样式(控件)有一定的限制,我试过短信的listview页面,暂无法实现滑动效果 java文件:MainActivity.java.Activi ...
- Excel催化剂开源第42波-与金融大数据TuShare对接实现零门槛零代码获取数据
在金融大数据功能中,使用了TuShare的数据接口,其所有接口都采用WebAPI的方式提供,本来还在纠结着应该搬那些数据接口给用户使用,后来发现,所有数据接口都有其通用性,结合Excel灵活友好的输入 ...
- 浅入深出Vue:代码整洁之去重
在开始本篇的主题之前,让我们把上次遗留下来的问题都清理一下: 将其他组件中 axios 请求的地方封装起来. 这里就不把代码放在开头了,相关代码都放在文末,有兴趣了解的童鞋可以先往下翻. 好了, 我们 ...