学习spark 技术
spark sql 可以说是 spark 中的精华部分了,我感觉整体复杂度是 spark streaming 的 5 倍以上,现在 spark 官方主推 structed streaming, spark streaming 维护的也不积极了, 我们基于 spark 来构建大数据计算任务,重心也要向 DataSet 转移,原来基于 RDD 写的代码迁移过来,好处是非常大的,尤其是在性能方面,有质的提升, spark sql 中的各种内嵌的性能优化是比人裸写 RDD 遵守各种所谓的最佳实践更靠谱的,尤其对新手来讲, 比如有些最佳实践讲到先 filter 操作再 map 操作,这种 spark sql 中会自动进行谓词下推,比如尽量避免使用 shuffle 操作,spark sql 中如果你开启了相关的配置,会自动使用 broadcast join 来广播小表,把 shuffle join 转化为 map join 等等,真的能让我们省很多心。
spark sql 的代码复杂度是问题的本质复杂度带来的,spark sql 中的 Catalyst 框架大部分逻辑是在一个 Tree 类型的数据结构上做各种折腾,基于 scala 来实现还是很优雅的,scala 的偏函数和强大的 Case 正则匹配,让整个代码看起来还是清晰的, 这篇文章简单的描述下 spark sql 中的一些机制和概念。
SparkSession 是我们编写 spark 应用代码的入口,启动一个 spark-shell 会提供给你一个创建 SparkSession, 这个对象是整个 spark 应用的起始点,我们来看下 sparkSession 的一些重要的变量和方法:
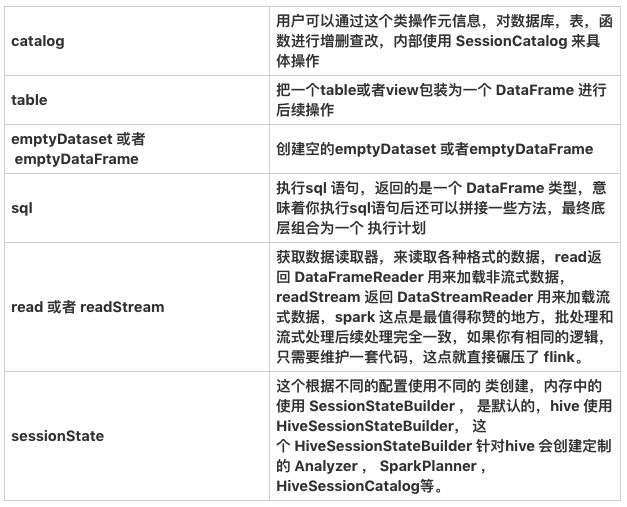
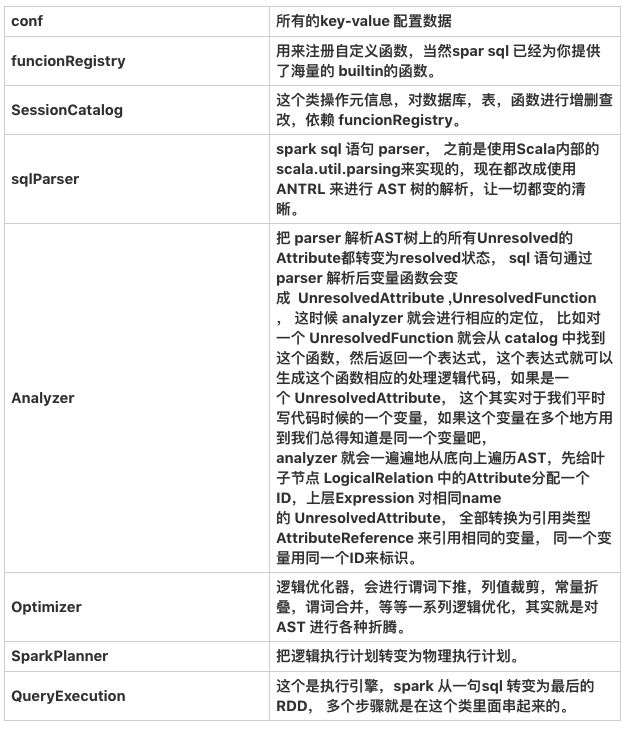
上面提到的 sessionState 是一个很关键的东西,维护了当前 session 使用的所有的状态数据,有以下各种需要维护的东西:
spark sql 内部使用 dataFrame 和 Dataset 来表示一个数据集合,然后你可以在这个数据集合上应用各种统计函数和算子,有人可能对 DataFrame 和 Dataset 分不太清,其实 DataFrame 就是一种类型为 Row 的 DataSet,
type DataFrame = Dataset[Row]这里说的 Row 类型在 Spark sql 对外暴露的 API 层面来说的, 然而 DataSet 并不要求输入类型为 Row,也可以是一种强类型的数据,DataSet 底层处理的数据类型为 Catalyst 内部 InternalRow 或者 UnsafeRow 类型, 背后有一个 Encoder 进行隐式转换,把你输入的数据转换为内部的 InternalRow,那么这样推论,DataFrame 就对应 RowEncoder。
在 Dataset 上进行 transformations 操作就会生成一个元素为 LogicalPlan 类型的树形结构, 我们来举个例子,假如我有一张学生表,一张分数表,需求是统计所有大于 11 岁的学生的总分。


这个 queryExecution 就是整个执行计划的执行引擎, 里面有执行过程中,各个中间过程变量,整个执行流程如下:
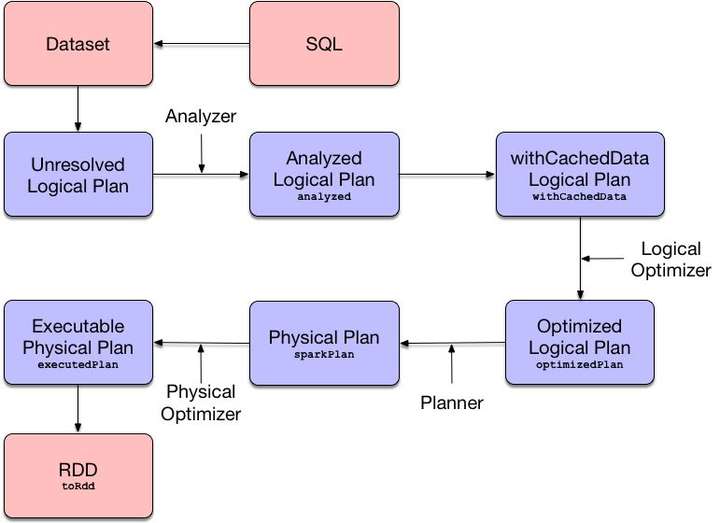
那么我们上面例子中的 sql 语句经过 Parser 解析后就会变成一个抽象语法树,对应解析后的逻辑计划 AST 为:

形象一点用图来表示:
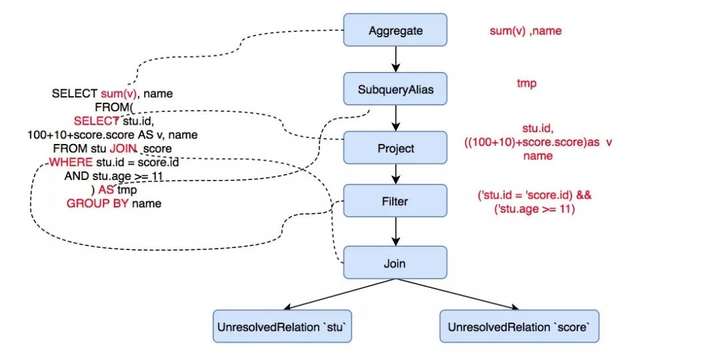
我们可以看到过滤条件变为了 Filter 节点,这个节点是 UnaryNode 类型, 也就是只有一个孩子,两个表中的数据变为了 UnresolvedRelation 节点,这个节点是 LeafNode 类型, 顾名思义,叶子节点, JOIN 操作就表位了 Join 节点, 这个是一个 BinaryNode 节点,有两个孩子。
上面说的这些节点都是 LogicalPlan 类型的, 可以理解为进行各种操作的 Operator, spark sql 对应各种操作定义了各种 Operator。
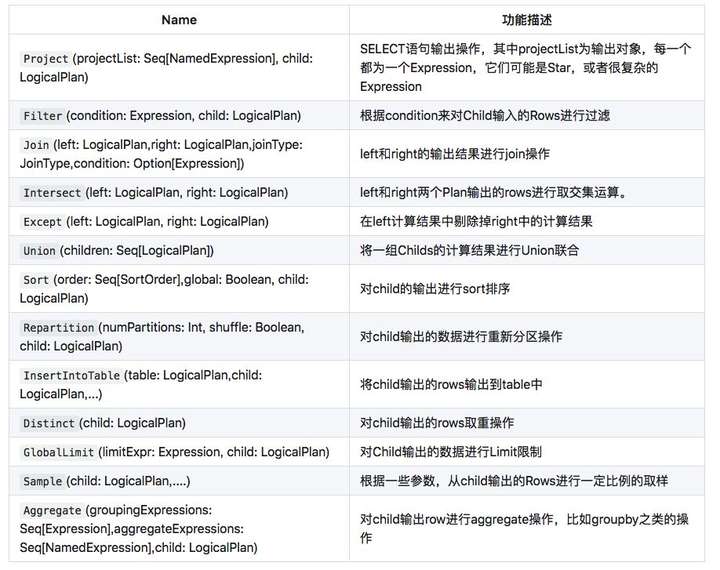
这些 operator 组成的抽象语法树就是整个 Catatyst 优化的基础,Catatyst 优化器会在这个树上面进行各种折腾,把树上面的节点挪来挪去来进行优化。
现在经过 Parser 有了抽象语法树,但是并不知道 score,sum 这些东西是啥,所以就需要 analyer 来定位, analyzer 会把 AST 上所有 Unresolved 的东西都转变为 resolved 状态,sparksql 有很多resolve 规则,都很好理解,例如 ResolverRelations 就是解析表(列)的基本类型等信息,ResolveFuncions 就是解析出来函数的基本信息,比如例子中的sum 函数,ResolveReferences 可能不太好理解,我们在 sql 语句中使用的字段比如 Select name 中的 name 对应一个变量, 这个变量在解析表的时候就作为一个变量(Attribute 类型)存在了,那么 Select 对应的 Project 节点中对应的相同的变量就变成了一个引用,他们有相同的 ID,所以经过 ResolveReferences 处理后,就变成了 AttributeReference 类型 ,保证在最后真正加载数据的时候他们被赋予相同的值,就跟我们写代码的时候定义一个变量一样,这些 Rule 就反复作用在节点上,指定树节点趋于稳定,当然优化的次数多了会浪费性能,所以有的 rule 作用 Once, 有的 rule 作用 FixedPoint, 这都是要取舍的。好了, 不说废话,我们做个小实验。

我们使用 ResolverRelations 对我们的 AST 进行解析,解析后可以看到原来的 UnresolvedRelation 变成了 LocalRelation,这个表示一个本地内存中的表,这个表是我们使用 createOrReplaceTempView 的时候注册在 catalog 中的,这个 relove 操作无非就是在 catalog 中查表,找出这个表的 schema, 而且解析出来相应的字段,把外层用户定义的 各个 StructField 转变为 AttibuteReference,使用 ID 进行了标记。

我们再使用 ResolveReferences 来搞一下,你会发现上层节点中的相同的字段都变成了拥有相同 ID 的引用,他们的类型都是 AttibuteReference。最终所有的 rule 都应用后,整个 AST 就变为了:
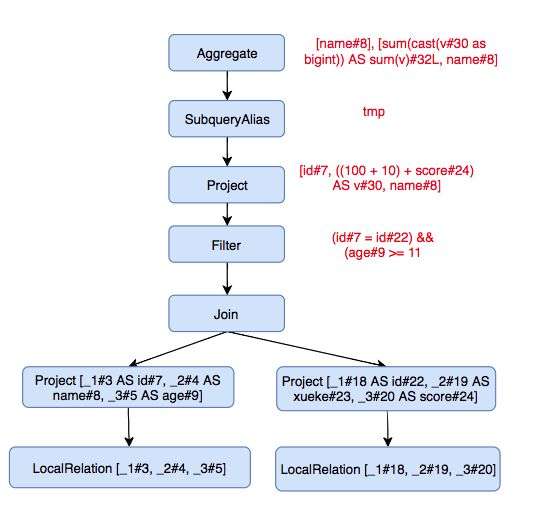
下面重点来了,要进行逻辑优化了,我们看下逻辑优化有哪些:
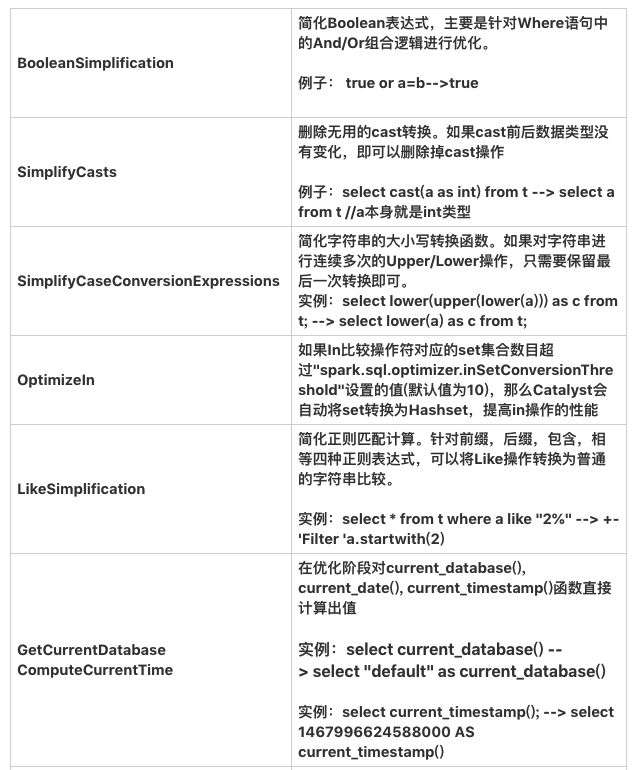
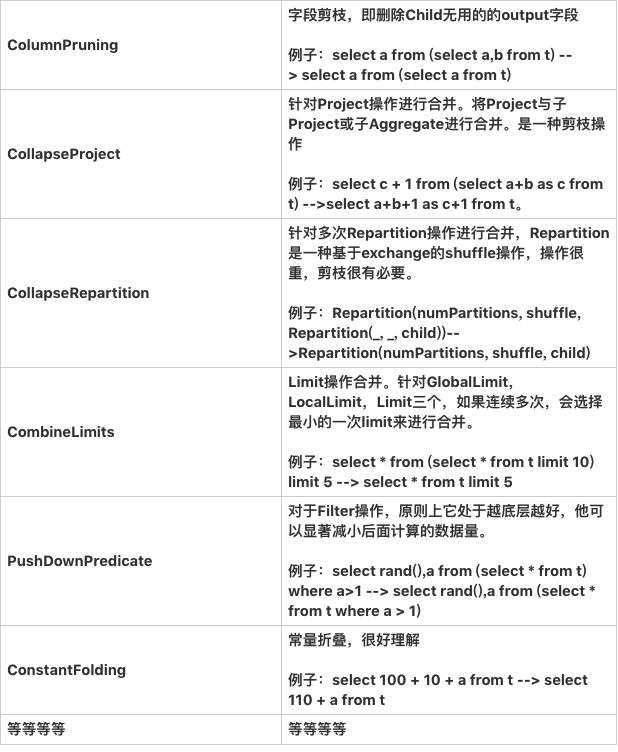
sparksql 中的逻辑优化种类繁多,spark sql 中的 Catalyst 框架大部分逻辑是在一个 Tree 类型的数据结构上做各种折腾,基于 scala 来实现还是很优雅的,scala 的偏函数 和 强大的 Case 正则匹配,让整个代码看起来还是清晰的,废话少说,我们来搞个小实验。

看到了没,把我的 (100 + 10) 换成了 110。

使用 PushPredicateThroughJoin 把一个单单对 stu 表做过滤的 Filter 给下推到 Join 之前了,会少加载很多数据,性能得到了优化,我们来看下最终的样子。

至少用了 ColumnPruning,PushPredicateThroughJoin,ConstantFolding,RemoveRedundantAliases 逻辑优化手段,现在我的小树变成了:
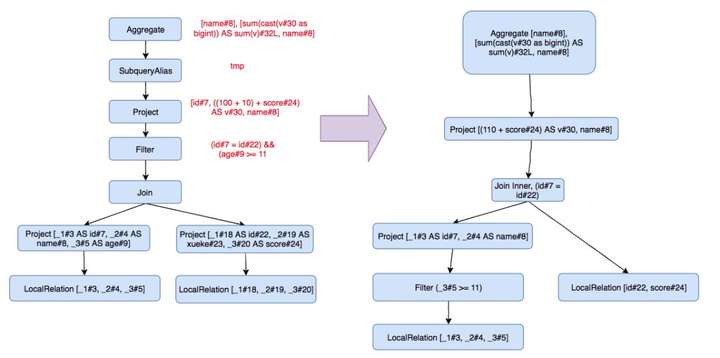
做完逻辑优化,毕竟只是抽象的逻辑层,还需要先转换为物理执行计划,将逻辑上可行的执行计划变为 Spark 可以真正执行的计划。
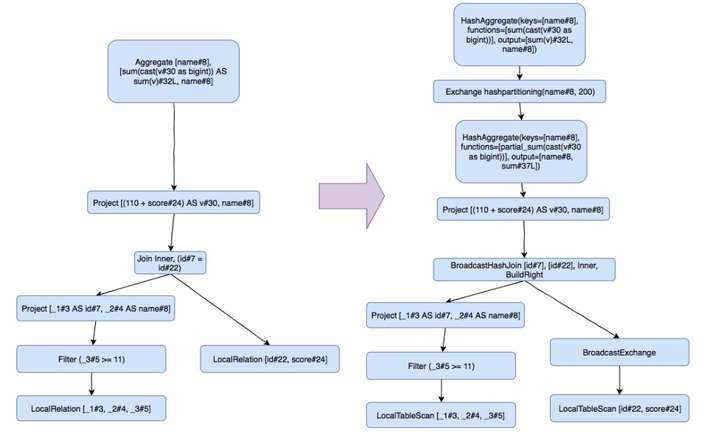
spark sql 把逻辑节点转换为了相应的物理节点, 比如 Join 算子,Spark 根据不同场景为该算子制定了不同的算法策略,有BroadcastHashJoin、ShuffleHashJoin 以及 SortMergeJoin 等, 当然这里面有很多优化的点,spark 在转换的时候会根据一些统计数据来智能选择,这就涉及到基于代价的优化,这也是很大的一块,后面可以开一篇文章单讲, 我们例子中的由于数据量小于 10M, 自动就转为了 BroadcastHashJoin,眼尖的同学可以看到好像多了一些节点,我们来解释下, BroadcastExchange 节点继承 Exchage 类,用来在节点间交换数据,这里的BroadcastExchange 就是会把 LocalTableScan出来的数据 broadcast 到每个 executor 节点,用来做 map-side join。最后的 Aggregate 操作被分为了两步,第一步先进行并行聚合,然后对聚合后的结果,再进行 Final 聚合,这个就类似域名 map-reduce 里面的 combine 和最后的 reduce, 中间加上了一个 Exchange hashpartitioning, 这个是为了保证相同的 key shuffle 到相同的分区,当前物理计划的 Child 输出数据的 Distribution 达不到要求的时候需要进行Shuffle,这个是在最后的 EnsureRequirement 阶段插入的交换数据节点,在数据库领域里面,有那么一句话,叫得 join 者得天下,我们重点讲一些 spark sql 在 join 操作的时候做的一些取舍。
Join 操作基本上能上会把两张 Join 的表分为大表和小表,大表作为流式遍历表,小表作为查找表,然后对大表中的每一条记录,根据 Key 来取查找表中取相同 Key 的记录。
spark 支持所有类型的 Join:
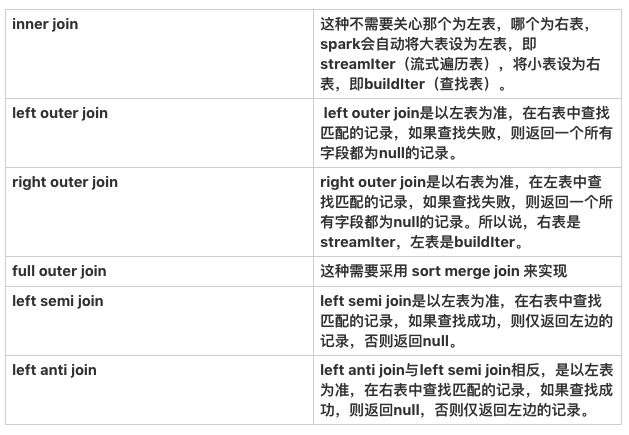
spark sql 中 join 操作根据各种条件选择不同的 join 策略,分为 BroadcastHashJoin, SortMergeJoin, ShuffleHashJoin。
- BroadcastHashJoin:spark 如果判断一张表存储空间小于 broadcast 阈值时(Spark 中使用参数 spark.sql.autoBroadcastJoinThreshold 来控制选择 BroadcastHashJoin 的阈值,默认是 10MB),就是把小表广播到 Executor, 然后把小表放在一个 hash 表中作为查找表,通过一个 map 操作就可以完成 join 操作了,避免了性能代码比较大的 shuffle 操作,不过要注意, BroadcastHashJoin 不支持 full outer join, 对于 right outer join, broadcast 左表,对于 left outer join,left semi join,left anti join ,broadcast 右表, 对于 inner join,那个表小就 broadcast 哪个。
- SortMergeJoin:如果两个表的数据都很大,比较适合使用 SortMergeJoin, SortMergeJoin 使用shuffle 操作把相同 key 的记录 shuffle 到一个分区里面,然后两张表都是已经排过序的,进行 sort merge 操作,代价也可以接受。
- ShuffleHashJoin:就是在 shuffle 过程中不排序了,把查找表放在hash表中来进行查找 join,那什么时候会进行 ShuffleHashJoin 呢?查找表的大小不能超过 spark.sql.autoBroadcastJoinThreshold 值,不然就使用 BroadcastHashJoin 了,每个分区的平均大小不能超过 spark.sql.autoBroadcastJoinThreshold ,这样保证查找表可以放在内存中不 OOM, 还有一个条件是 大表是小表的 3 倍以上,这样才能发挥这种 Join 的好处。
上面提到 AST 上面的节点已经转换为了物理节点,这些物理节点最终从头节点递归调用 execute 方法,里面会在 child 生成的 RDD 上调用 transform操作就会产生一个串起来的 RDD 链, 就跟在 spark stremaing 里面在 DStream 上面递归调用那样。最后执行出来的图如下:
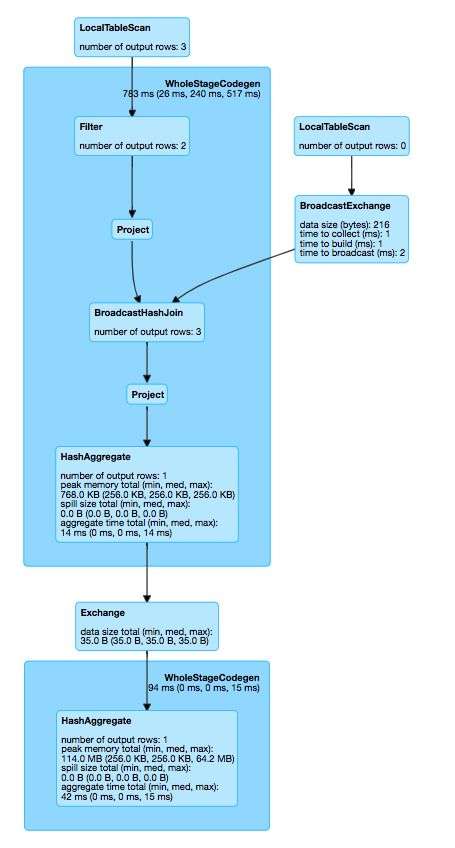
可以看到这个最终执行的时候分分成了两个 stage, 把小表 broeadcastExechage 到了大表上做 BroadcastHashJoin, 没有进化 shuffle 操作,然后最后一步聚合的时候,先在 map 段进行了一次 HashAggregate sum 函数, 然后 Exchage 操作根据 name 把相同 key 的数据 shuffle 到同一个分区,然后做最终的 HashAggregate sum 操作,这里有个 WholeStageCodegen 比较奇怪,这个是干啥的呢,因为我们在执行 Filter ,Project 这些 operator 的时候,这些 operator 内部包含很多 Expression, 比如 SELECT sum(v),name, 这里的 sum 和 v 都是 Expression,这里面的 v 属于 Attribute 变量表达式,表达式也是树形数据结构,sum(v) 就是 sum 节点和 sum 的子节点 v 组成的一个树形结构,这些表达式都是可以求值和生成代码的,表达式最基本的功能就是求值,对输入的 Row 进行计算 , Expression 需要实现 def eval(input: InternalRow = null): Any 函数来实现它的功能。
表达式是对 Row 进行加工,输出的可以是任意类型,但是 Project 和 Filter 这些 Plan 输出的类型是 def output: Seq[Attribute], 这个就是代表一组变量,比如我们例子中的 Filter (age >= 11) 这个plan, 里面的 age>11 就是一个表达式,这个 > 表达式依赖两个子节点, 一个Literal常量表达式求值出来就是 11, 另外一个是 Attribute 变量表达式 age, 这个变量在 analyze 阶段转变为了 AttributeReference 类型,但是它是Unevaluable,为了获取属性在输入 Row 中对应的值, 还得根据 schema 关联绑定一下这个变量在一行数据的 index, 生成 BoundReference,然后 BoundReference 这种表达式在 eval 的时候就可以根据 index 来获取 Row 中的值。 age>11 这个表达式最终输出类型为 boolean 类型,但是 Filter 这个 Plan 输出类型是 Seq[Attribute] 类型。
可以想象到,数据在一个一个的 plan 中流转,然后每个 plan 里面表达式都会对数据进行处理,就相当于经过了一个个小函数的调用处理,这里面就有大量的函数调用开销,那么我们是不是可以把这些小函数内联一下,当成一个大函数,WholeStageCodegen 就是干这事的。

可以看到最终执行计划每个节点前面有个 * 号,说明整段代码生成被启用,在我们的例子中,Filter, Project,BroadcastHashJoin,Project,HashAggregate 这一段都启用了整段代码生成,级联为了两个大函数,有兴趣可以使用 a.queryExecution.debug.codegen 看下生成后的代码长什么样子。然而 Exchange 算子并没有实现整段代码生成,因为它需要通过网络发送数据。
我今天的分享就到这里,其实 spark sql 里面有很多有意思的东西,但是因为问题的本质复杂度,导致需要高度抽象才能把这一切理顺,这样就给代码阅读者带来了理解困难, 但是你如果真正看进去了,就会有很多收获。如果对本文有任何见解,欢迎在文末留言说出你的想法。
学习spark 技术的更多相关文章
- 学习Spark——那些让你精疲力尽的坑
这一个月我都干了些什么-- 工作上,还是一如既往的写bug并不亦乐乎的修bug.学习上,最近看了一些非专业书籍,时常在公众号(JackieZheng)上写点小感悟,我刚稍稍瞄了下,最近五篇居然都跟技术 ...
- 5分钟学习spark streaming之 轻松在浏览器运行和修改Word Counts
方案一:根据官方实例,下载预编译好的版本,执行以下步骤: nc -lk 9999 作为实时数据源 ./bin/run-example org.apache.spark.examples.sql.str ...
- 我的第一本著作:Spark技术内幕上市!
现在各大网站销售中! 京东:http://item.jd.com/11770787.html 当当:http://product.dangdang.com/23776595.html 亚马逊:http ...
- Spark技术学院-进去能学到啥?
Spark技术学院是什么? 主要是浪尖,前腾讯现阿里的大神一起搞的知识分享基地,旨在帮助大家由入门到精通spark,hbase,kafka大数据重要的框架,还有给入门小白指点入门方法,分享入门资料,对 ...
- (转)如何学习Java技术?谈Java学习之路
51CTO编者注:这篇文章已经是有数年“网龄”的老文,不过在今天看来仍然经典.如何学习Java?本篇文章可以说也是面对编程初学者的一篇指导文章,其中对于如何学习Java的步骤的介绍,很多也适用于开发领 ...
- Spark技术内幕:Stage划分及提交源码分析
http://blog.csdn.net/anzhsoft/article/details/39859463 当触发一个RDD的action后,以count为例,调用关系如下: org.apache. ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- Spark技术内幕: Task向Executor提交的源码解析
在上文<Spark技术内幕:Stage划分及提交源码分析>中,我们分析了Stage的生成和提交.但是Stage的提交,只是DAGScheduler完成了对DAG的划分,生成了一个计算拓扑, ...
- Spark技术内幕:Master的故障恢复
Spark技术内幕:Master基于ZooKeeper的High Availability(HA)源码实现 详细阐述了使用ZK实现的Master的HA,那么Master是如何快速故障恢复的呢? 处于 ...
随机推荐
- 成功入职ByteDance,分享我的八面面经心得!
今天正式入职了字节跳动.办公环境也很好,这边一栋楼都是办公区域.公司内部配备各种小零食.饮料,还有免费的咖啡.15楼还有健身房.而且公司包三餐来着.下午三点半左右还会有阿姨推着小车给大家送下午茶.听说 ...
- v8环境搭建采坑记录
项目组有把js接入C++服务求的需求,故开始了v8接入的工作,用了一天多时间,v8才在centos环境上成功安装,过程中踩了很多坑,下面将采坑过程记录如下: centos下编译安装v8: 查看ce ...
- Java编程思想:NIO知识点
import java.io.*; import java.nio.*; import java.nio.channels.FileChannel; import java.nio.charset.C ...
- Python爬虫学习代码
[1]用一个简单的程序来显示Python的数字类型. code: class ShowNumType(object): def __init__(self): self.showInt() self. ...
- 个人永久性免费-Excel催化剂功能第100波-透视多行数据为多列数据结构
在数据处理过程中,大量的非预期格式结构需要作转换,有大家熟知的多维转一维(准确来说应该是交叉表结构的数据转二维表标准数据表结构),也同样有一些需要透视操作的数据源,此篇同样提供更便捷的方法实现此类数据 ...
- [leetcode] 406. Queue Reconstruction by Height (medium)
原题 思路: 一开始完全没有思路..看了别人的思路才解出来. 先按照他们的高度从高到低(因为我后面用的从前往后遍历插入,当然也可以从低到高)排序,如果高度一样,那么按照k值从小到大排序. 排完序后我们 ...
- 简单分析线程获取ReentrantReadWriteLock 读锁的规则
1. 问题 最近有同事问了我一个问题,在Java编程中,当有一条线程要获取ReentrantReadWriteLock的读锁,此时已经有其他线程获得了读锁,AQS队列里也有线程在等待写锁.由于读锁是共 ...
- echarts在react项目中的使用
数据可视化在前端开发中经常会遇到,万恶的图表,有时候总是就差一点,可是怎么也搞不定. 别慌,咱们一起来研究. 引入我就不多说了 npm install echarts 对于基础的可视化组件,我一般采用 ...
- SpringBoot(18)---通过Lua脚本批量插入数据到Redis布隆过滤器
通过Lua脚本批量插入数据到布隆过滤器 有关布隆过滤器的原理之前写过一篇博客: 算法(3)---布隆过滤器原理 在实际开发过程中经常会做的一步操作,就是判断当前的key是否存在. 那这篇博客主要分为三 ...
- 【JDK】JDK源码-Queue, Deque
概述 Queue 和 Deque 都是接口.其中 Queue 接口定义的是一个队列,它包含队列的基本操作:入队(enqueue)和出队(dequeue). Deque 接口继承自 Queue 接口,表 ...