线性分类 Linear Classification
软分类:y 的取值只有正负两个离散值,例如 {0, 1}
硬分类:y 是正负两类区间中的连续值,例如 [0, 1]
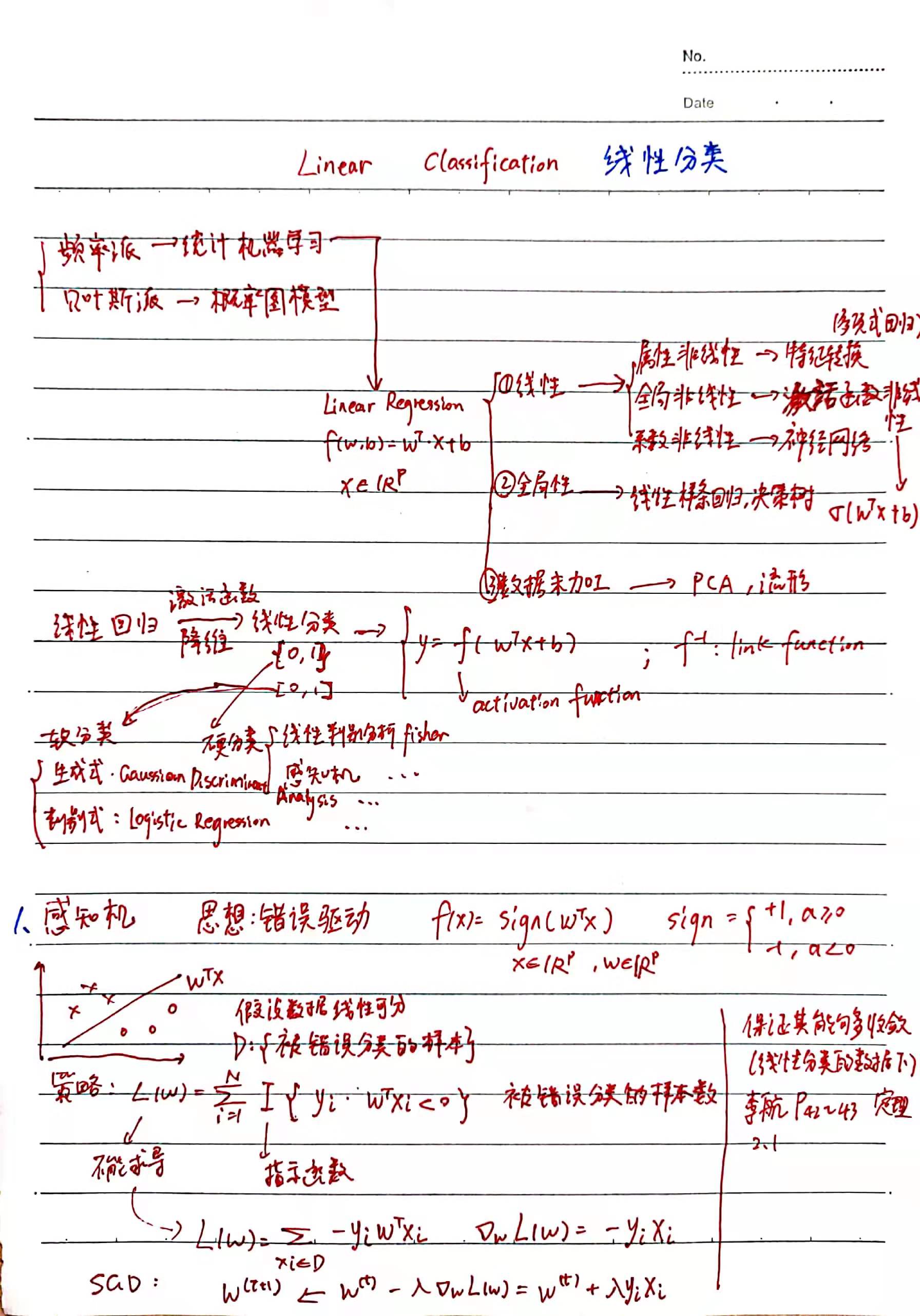
一、感知机
主要思想:分错的样本数越少越好
用指示函数统计分错的样本数作为损失函数,不可微;
对错误分类样本,∑ -yi * f(xi) = ∑ -yi * WTxi (因为求和项一定大于0,所以损失函数越小表示错误分类的样本越少)
二、线性判别分析
主要思想:同一类别的样本方差足够小,不同类别之间分散开(类内小,类间大)
Rayleigh quotient 和 generalized Rayleigh quotient
函数 R(A, x) = xHAx / xHx ,其中 A 是 Hermitan矩阵,如果是实矩阵则满足 AT = A。
性质:λmin <= R(A, x) <= λmax ,即最大值为 A 的最大特征值、最小值为 A 的最小特征值
函数 R(A, B, x) = xHAx / xHBx ,其中 A、B 是 Hermitan矩阵,B 正定。
令 x = B-1/2x',由瑞利商性质可知,R(A, B, x) 的最大值是 B-1/2AB-1/2 (或者 B-1A)的最大特征值,最小值是其最小特征值
与 LDA 的关系:
二类:
数据是 p 维,只有两个类别,经过 LDA 投影到投影到一条直线,投影直线为向量 w(只关心其方向,设为单位向量即可),样本点xi 在直线上的投影为zi = wTxi ,记类别 1 和类别 2 两个集合为c1、c2,对 p 维数据 x 两个集合的样本均值和方差分别为 μc1 、 μc2 、Sc1 、Sc2
样本点投影到直线后有样本均值 zk拔 和样本方差 Sk
LDA 目标函数的定义要让类内方差小类间方差大,则
J(W) = (z1拔 - z2拔 )2 / (S1 + S2)
= wT (μc1 - μc2)(μc1 - μc2)Tw / wT (Sc1 + Sc2) w
= wT Sb w / wT Sw w
这个目标函数的 argmax 可以对其求导后令导数为零,得到向量 w 正比于 Sw-1(μc1 - μc2)。也可以直接利用瑞利商的结论,最大值为 Sw-1Sb 的最大特征值,二分类时 Sb w 的方向恒为 μc1 - μc2 (因为(μc1 - μc2)Tw 结果是 scalar),令 Sb w = λ (μc1 - μc2) ,代入 (Sw-1Sb)w = λw,得到 w = Sw-1(μc1 - μc2) 结果一样。

多类:
数据是 p 维,有 K 个类别,经过 LDA 投影到低维(q 维)平面,基为(w1,w2,...,wq),共同构成矩阵Wpxq
J(W) = WT Sb W / WT Sw W,类间方差 Sb = Σ Nj (μcj - μ)(μcj - μ)T ,for j = 1, 2, ..., K;类内方差 Sw = Σ Σ (xi - μcj)(xi - μcj)T for j = 1, 2, ..., K and every xi in ci
为了应用瑞利商结论,分子分母都各自求主对角线元素乘积,J(W) = ∏ wiT Sb wi / wiT Sw wi ,for i = 1, 2, ..., q 。目标函数的最大值为 Sw-1Sb 最大的q个特征值的乘积,W 就由这 q 个最大特征值对应的特征向量组成。
注意降到的维度 q 最大为 K-1。(因为知道了前K-1个 μcj 后最后一个μcj 可以由前K-1个表示)
监督降维:根据以上分析,对 xi 就可以进行降维 zi = WTxi
分类:LDA 用来分类的思路,假设各个类别的数据符合各自的高斯分布,LDA 投影后用 MLE 计算各个类别的均值和方差,就得到了各个类别服从高斯的概率密度函数。对于一个新样本,将其投影后的向量代入各类的分布计算一下概率,最大的就是样本所属的类。
三、Logistic 回归
判别模型,直接用一个函数拟合,计算后验概率 P(y|x)。直接用 MLE 来估计参数 W / 用梯度下降优化求参数 W 。

看一下 logistic regression 和 linear regression 中的梯度:

sigmoid函数怎么来的?——高斯判别分析
四、高斯判别分析:
生成模型,不对条件概率 P(y | x) 直接建模,引入 P(y) 的先验分布。
根据贝叶斯定理(执果索因):P(y | x) = P(x | y)P(y) / P(x),也即 P(y=ck | xi) 正比于 P(xi | y=ck) P(y=ck),分别对这两部分建模后,对于一个新样本计算P(y=ck | xi),概率最大的ck 就是样本所属的类别。
以二分类为例,对先验 P(y=ck) 建模最直觉的想法就是遍历所有训练数据,计算 P(y=ck) = Nk / N 。这个结果其实也就来源于,假设 Y 服从参数为 p 的伯努利分布,通过 MLE 进行参数估计。
对似然 P(x | y=ck) 的估计呢?——对每个类别都假设 P(x | y=ck) 服从均值为 μk 、方差为 Σk 的高斯分布就好了。
P(x | y=ck) = ∏ P(xi | y=ck) ,for every xi in ck ,MLE 估计所有的 μk 和 Σk 。
结果比较差,怎么改进? ——不同类别的高斯分布共享同一个 Σ,减少参数改善过拟合。


可以看出,高斯判别分析认为输入的各个维度特征之间存在相关性。
能不能和 sigmoid 函数联系起来?
先看一个后验概率表达式,把分子除下去就看到熟悉的 σ (z) 形式了,可以发现 sigmoid 函数的作用就是把 logit 压到 probability。
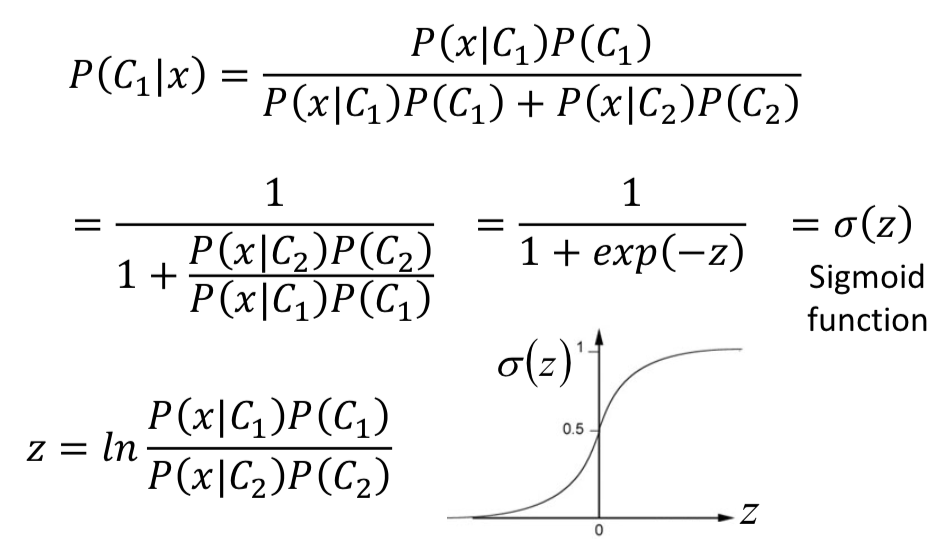
另一个结论:似然设为服从高斯分布,且不同类别的高斯分布共享方差矩阵的情况下,高斯判别分析:

那为什么不直接去找 W 和 b 呢? ——logistic regression
概率判别模型和概率生成模型的一点比较分析:
五、朴素贝叶斯
服从条件独立性假设
后验概率最大化 等价于 期望风险最小化


线性分类 Linear Classification的更多相关文章
- 从损失函数优化角度:讨论“线性回归(linear regression)”与”线性分类(linear classification)“的联系与区别
1. 主要观点 线性模型是线性回归和线性分类的基础 线性回归和线性分类模型的差异主要在于损失函数形式上,我们可以将其看做是线性模型在多维空间中“不同方向”和“不同位置”的两种表现形式 损失函数是一种优 ...
- 【cs231n】图像分类-Linear Classification线性分类
[学习自CS231n课程] 转载请注明出处:http://www.cnblogs.com/GraceSkyer/p/8824876.html 之前介绍了图像分类问题.图像分类的任务,就是从已有的固定分 ...
- 1. cs231n k近邻和线性分类器 Image Classification
第一节课大部分都是废话.第二节课的前面也都是废话. First classifier: Nearest Neighbor Classifier 在一定时间,我记住了输入的所有的图片.在再次输入一个图片 ...
- [Scikit-learn] 1.4 Support Vector Machines - Linear Classification
Outline: 作为一种典型的应用升维的方法,内容比较多,自带体系,以李航的书为主,分篇学习. 函数间隔和几何间隔 最大间隔 凸最优化问题 凸二次规划问题 线性支持向量机和软间隔最大化 添加的约束很 ...
- 【cs231n】线性分类笔记
前言 首先声明,以下内容绝大部分转自知乎智能单元,他们将官方学习笔记进行了很专业的翻译,在此我会直接copy他们翻译的笔记,有些地方会用红字写自己的笔记,本文只是作为自己的学习笔记.本文内容官网链接: ...
- CS231n课程笔记翻译3:线性分类笔记
译者注:本文智能单元首发,译自斯坦福CS231n课程笔记Linear Classification Note,课程教师Andrej Karpathy授权翻译.本篇教程由杜客翻译完成,巩子嘉和堃堃进行校 ...
- [CS231n-CNN] Image classification and the data-driven approach, k-nearest neighbor, Linear classification I
课程主页:http://cs231n.stanford.edu/ Task: Challenges: _________________________________________________ ...
- Android线性布局(Linear Layout)
Android线性布局(Linear Layout) LinearLayout是一个view组(view group),其包含的所有子view都以一个方向排列,垂直或是水平方向.我们能够用androi ...
- FastReport.Net使用:[24]其他控件(邮政编码(Zip Code),网格文本(Cellular Text)以及线性刻度尺(Linear Gauge))
邮政编码(Zip Code) Zip Code仅支持数字(0~9) Zip Code支持数据列绑定,表达式,文本等模式 可通过修改SegmentCount属性的值来确定Zip Code的位数. 数字右 ...
随机推荐
- 【Spring容器】项目启动后初始化数据的两种实践方案
早期业务紧急,没有过多的在意项目的运行效率,现在回过头看走查代码,发现后端项目(Spring MVC+MyBatis)在启动过程中多次解析mybatis的xml配置文件及初始化数据,对开发阶段开发人员 ...
- 小心使用strcpy函数时越界
strcpy()函数应该是我们用的比较常用的一个函数,基本功能是将一个字符串拷贝到我指定的内存空间.但是要复制的字符串长度超过这段内存空间的话,结果可能是未知的. 比如以下的程序: #include ...
- STM32F4xx系列_独立看门狗配置
看门狗由内部LSI驱动,LSI是一个内部RC时钟,并不是准确的32kHz,然而看门狗对时间的要求不精确,因此可以接收: 关键字寄存器IWDG_KR: 写入0xCCCCH开启独立看门狗,此时计数器开始从 ...
- How to Read a Paper丨如何阅读一篇论文
这是我在看论文时无意刷到的博客推荐的一篇文章"How to Read a Paper",教你怎么样看论文.对于研究生来说,看论文基本是日常,一篇论文十多二十页,如何高效地读论文确实 ...
- Kafka FAQ
报错如下: Unable to read additional data from client sessionid 0x15d2c867a770006 使用的kafka自带的zookeeper,测试 ...
- Maven(三)使用 IDEA 创建一个 Maven 项目
利用 IDEA 创建一个 Maven 项目 创建 Maven 项目 选择 File --> New --> Project 选中 Maven 填写项目信息 选择工作空间 目录结构 ├─sr ...
- 你可能不知道的github的秘密
github也可以使用快捷键 先举例子,如何快速查找项目中的文件? 只需要进入项目,并按下T键 在浏览代码时,如何快速跳到指定行? 只需要进入项目,并按下L键 下面是一些常用的快捷键 聚焦搜索栏 按下 ...
- vim 复制大块内容。 y,p(是单个y,而不是yy)
vim 复制大块内容. y,p(是单个y,而不是yy)
- 个人永久性免费-Excel催化剂功能第102波-批量上传本地图片至网络图床(外网可访问)
自我突破,在100+功能后,再做有质量的功能,非常不易,相对录制视频这些轻松活,还是按捺不住去写代码,此功能虽小,但功课也做了不少,希望对真正有需要的群体带来一些惊喜. 背景介绍 图床的使用,一般是写 ...
- Linux AUFS 文件系统
AUFS 的英文全称为 Advanced Mult-Layered Unification Filesystem,曾经是 Another Mult-Layered Unification Filesy ...