使用DOM4J 对xml解析操作
参考自:https://blog.csdn.net/redarmy_chen/article/details/12969219
dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。dom4j是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件,可以在SourceForge上找到它.
对主流的Java XML API进行的性能、功能和易用性的评测,dom4j无论在那个方面都是非常出色的。如今你可以看到越来越多的Java软件都在使用dom4j来读写XML,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
使用Dom4j开发,需下载dom4j相应的jar文件
一、DOM4j中,获得Document对象的方式有三种:
|
//1.获取document对象(3种方式) //1.1.读取XML文件,获得document对象 SAXReader reader = new SAXReader(); Document document = reader.read("./src/pol.xml"); //1.2解析XML形式的文本,得到document对象 //String text = "<csdn></csdn>"; //Document document = DocumentHelper.parseText(text); //1.3主动创建document对象. //Document document = DocumentHelper.createDocument();//创建根节点 //Element root = document.addElement("csdn"); |
二、节点对象操作的方法
|
1.获取文档的根节点. Element root = document.getRootElement(); 2.取得某个节点的子节点. Element element=node.element(“四大名著"); 3.取得节点的文字 String text=node.getText(); 4.取得某节点下所有名为“csdn”的子节点,并进行遍历. List nodes = rootElm.elements("csdn"); for (Iterator it = nodes.iterator(); it.hasNext();) { Element elm = (Element) it.next(); // do something } 5.对某节点下的所有子节点进行遍历. for(Iterator it=root.elementIterator();it.hasNext();){ Element element = (Element) it.next(); // do something } 6.在某节点下添加子节点 Element elm = newElm.addElement("朝代"); 7.设置节点文字. elm.setText("明朝"); 8.删除某节点.//childElement是待删除的节点,parentElement是其父节点 parentElement.remove(childElment); 9.添加一个CDATA节点.Element contentElm = infoElm.addElement("content");contentElm.addCDATA(“cdata区域”); |
三、节点对象的属性方法操作
|
1.取得某节点下的某属性 Element root=document.getRootElement(); //属性名name Attribute attribute=root.attribute("id"); 2.取得属性的文字 String text=attribute.getText(); 3.删除某属性 Attribute attribute=root.attribute("size"); root.remove(attribute); 4.遍历某节点的所有属性 Element root=document.getRootElement(); for(Iterator it=root.attributeIterator();it.hasNext();){ Attribute attribute = (Attribute) it.next(); String text=attribute.getText(); System.out.println(text); } 5.设置某节点的属性和文字. newMemberElm.addAttribute("name", "sitinspring"); 6.设置属性的文字 Attribute attribute=root.attribute("name"); attribute.setText("csdn"); |
四、将文档写入XML文件
|
1.文档中全为英文,不设置编码,直接写入的形式. XMLWriter writer = new XMLWriter(new FileWriter("ot.xml")); writer.write(document); writer.close(); 2.文档中含有中文,设置编码格式写入的形式. OutputFormat format = OutputFormat.createPrettyPrint();// 创建文件输出的时候,自动缩进的格式 format.setEncoding("UTF-8");//设置编码 XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format); writer.write(document); writer.close(); |
五、字符串与XML的转换
|
1.将字符串转化为XML String text = "<csdn> <java>Java班</java></csdn>"; Document document = DocumentHelper.parseText(text); 2.将文档或节点的XML转化为字符串. SAXReader reader = new SAXReader(); Document document = reader.read(new File("csdn.xml")); Element root=document.getRootElement(); String docXmlText=document.asXML(); String rootXmlText=root.asXML(); Element memberElm=root.element("csdn"); String memberXmlText=memberElm.asXML(); |
六、案例(解析xml文件并对其进行curd的操作)
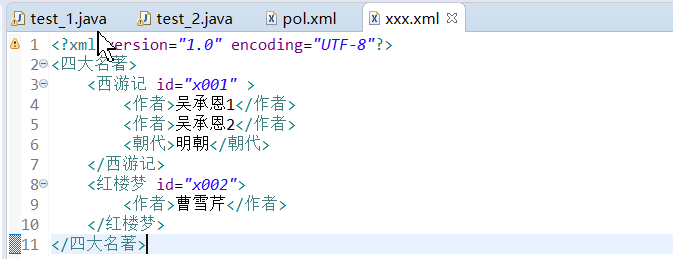
|
public class test_1 { public static void main(String[] args) throws DocumentException, IOException { // 1.创建saxReader对象 SAXReader reader = new SAXReader(); // 2.通过read方法获取一个文件,转换成Document对象 Document document = reader.read(new File("src/xxx.xml")); // 3.获取根节点元素对象 Element rootElement = document.getRootElement(); listNodes(rootElement); // 4.便利所有元素节点 // 获取子节点为红楼梦的节点对象 Element element = rootElement.element("红楼梦"); // 获取element的id属性节点对象 Attribute attribute = element.attribute("id"); // 删除属性 attribute.detach(); // element.remove(attribute); // 添加新的属性 element.addAttribute("name", "作者"); // 在红楼梦元素节点添加朝代元素的节点 Element newElement = element.addElement("朝代"); newElement.setText("清朝"); // 获取element中作者元素节点对象 Element author = element.element("作者"); // 删除元素节点 boolean remove = element.remove(author); System.out.println(remove); // 添加CDATA区域 Element addCDATA = element.addCDATA("红楼梦,是一部爱情小说"); elementMethod(element); // 写入到一个新的文件中 // writer(document); } /* * 把document对象写到新的文件 */ public static void writer(Document document) throws IOException { // 紧凑的格式 // OutputFormat format = new OutputFormat().createCompactFormat(); // 排版缩进的格式 OutputFormat format = OutputFormat.createPrettyPrint(); // 设置编码 format.setEncoding("UTF-8"); // 创建XmlWriter对象,指定了写出文件及编码格式 // XMLWriter writer = new XMLWriter(new FileWriter(new // File("src/a.xml")),format); XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream(new File("src/a.xml")), "UTF-8"), format); writer.write(document); writer.flush(); writer.close(); } /** * 遍历当前节点元素下面的所有(元素的)子节点 * */ public static void listNodes(Element node) { System.out.println("当前节点的名称::" + node.getName()); // 获取当前节点的所有属性节点 List<Attribute> list = node.attributes(); // 遍历属性节点 for (Attribute attr : list) { System.out.println(attr.getText() + "-----" + attr.getName() + "---" + attr.getValue()); } if (!(node.getTextTrim().equals(""))) { System.out.println("文本内容::::" + node.getText()); } // 当前节点下面子节点迭代器 Iterator<Element> it = node.elementIterator(); // 遍历 while (it.hasNext()) { // 获取某个子节点对象 Element e = it.next(); // 对子节点进行遍历 listNodes(e); } } /** * 介绍Element中的element方法和elements方法的使用 * */ public static void elementMethod(Element node) { // 获取node节点中,子节点的元素名称为西游记的元素节点。 Element e = node.element("西游记"); // 获取西游记元素节点中,子节点为作者的元素节点(可以看到只能获取第一个作者元素节点) Element author = e.element("作者"); System.out.println(e.getName() + "----" + author.getText()); // 获取西游记这个元素节点 中,所有子节点名称为作者元素的节点 。 List<Element> authors = e.elements("作者"); for (Element aut : authors) { System.out.println(aut.getText()); } // 获取西游记这个元素节点 所有元素的子节点。 List<Element> elements = e.elements(); for (Element el : elements) { System.out.println(el.getText()); } } } |
七、字符串与XML互转换案例
|
/* * 字符串与XML互转换案例 */ public class test_2 { public static void main(String[] args) throws Exception { //创建saxreader对象 SAXReader reader = new SAXReader(); //读取一个文件,把这个文件转换成document对象 Document document = reader.read(new File("src/a.xml")); //获取根元素啊 Element rootElement = document.getRootElement(); //把文档转换成字符创串 String docXmlText = document.asXML(); System.out.println(docXmlText); System.out.println("----------------------"); //元素标签根转换的内容 String rootXmlText = rootElement.asXML(); System.out.println(rootXmlText); System.out.println("----------------"); //获取java元素标签内的内容 Element e = rootElement.element("java"); System.out.println(e.asXML()); test2(); } /* * 创建一个document对象,往document对象添加节点元素 转存为xml文件 * */ public static void test1() throws Exception { Document document = DocumentHelper.createDocument(); //创建根节点 Element root = document.addElement("根标签"); Element child1 = root.addElement("子标签1"); child1.setText("这是子标签1的内容"); Element child2 = root.addElement("子标签2"); child2.setText("这是字标签2的内容"); writer(document); } /* * 把一个文本字符串转化为Document对象 */ public static void test2() throws Exception { String text = " <方向><java方向>java班</java方向><云计算>云计算班</云计算></方向>"; Document document = DocumentHelper.parseText(text); Element rootElement = document.getRootElement(); System.out.println(rootElement.getName()); writer(document); } /* * 吧document对象写入新的文件 */ public static void writer(Document document) throws Exception { //紧凑的格式 // OutputFormat format = OutputFormat.createCompactFormat(); //排版缩进的格式 OutputFormat format = OutputFormat.createPrettyPrint(); //设置编码 format.setEncoding("UTF-8"); //创建XMLWriter对象,指定写出文件及编码格式 // XMLWriter writer = new XMLWriter(new FileWriter(new File("src/b.xml")), format); XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream(new File("src/b.xml")),"UTF-8"),format); //写入 writer.write(document); //立即写入 writer.flush(); //关闭操作 writer.close(); } } |
使用DOM4J 对xml解析操作的更多相关文章
- 使用Dom4j进行XML解析
1 概述 在进行ESB集成项目中,使用到了很多系统的接口,这些接口传输的数据大部分都采用了XML的格式,这样在使用ESB开发服务时就需要对XML数据进行解析或拼接的操作,本文以项目中流程服务为例,讲 ...
- DOM4J -(XML解析包)
DOM4J - 简介 是dom4j.org出品的一个开源XML解析包.Dom4j是一个易用的.开源的库,用于XML,XPath和XSLT.它应用于Java平台,采用了Java集合框架并完全支持DOM, ...
- Dom4j 对XMl解析 新手学习,欢迎高手指正
废话不多,先看代码 public static void main(String args[]){ ReaderXml("d:/example.xml");//读取XML,传入XM ...
- XML解析【介绍、DOM、SAX详细说明、jaxp、dom4j、XPATH】
什么是XML解析 前面XML章节已经说了,XML被设计为"什么都不做",XML只用于组织.存储数据,除此之外的数据生成.读取.传送等等的操作都与XML本身无关! XML解析就是读取 ...
- Java使用DOM4J对XML文件进行增删改查操作
Java进行XML文件操作,代码如下: package com.founder.mrp.util; import java.io.File; import java.util.ArrayList; i ...
- Java之dom4j的简单解析和生成xml的应用
一.dom4j是一个Java的XML API,是jdom的升级品,用来读写XML文件的.dom4j是一个十分优秀的JavaXML API,具有性能优异.功能强大和极其易使用的特点,它的性能超过sun公 ...
- JAVA基础学习之XMLCDATA区、XML处理指令、XML约束概述、JavaBean、XML解析(8)
1.CDATA区在编写XML文件时,有些内容可能不想让解析引擎解析执行,而是当作原始内容处理.遇到此种情况,可以把这些内容放在CDATA区里,对于CDATA区域内的内容,XML解析程序不会处理,而是直 ...
- Java xml 操作(Dom4J修改xml + xPath技术 + SAX解析 + XML约束)
1 XML基础 1)XML的作用 1.1 作为软件配置文件 1.2 作为小型的"数据库" 2)XML语法(由w3c组织规定的) 标签: 标签名不能以数字开头,中间不能有空格,区分大 ...
- 简单用DOM4J结合XPATH解析XML
由于DOM4J在解析XML时只能一层一层解析,所以当XML文件层数过多时使用会很不方便,结合XPATH就可以直接获取到某个元素 使用dom4j支持xpath的操作的几种主要形式 第一种形式 ...
随机推荐
- js动态生成数据的抓取
需求:爬取https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html页面中的 ...
- 基于modelform和ajax的注册
forms文件 创建ModelForm组件 from django import forms from crm import models from django.core.exceptions im ...
- Java底层技术系列文章-线程池框架
一.线程池结构图 二.示例 定义线程接口 public class MyThread extends Thread { @Override publicvoid run() { System.o ...
- CDQZ集训DAY9 日记
彻彻底底的爆炸了…… 考试上来第一题看完30分暴力后就不知道怎么打了,然后看第二题,一开始脑残以为是网络流,后来发现是树状结构后觉得是那个经典的n^2的树上背包DP,然而脑子又一次犯笨,竟然,竟然去枚 ...
- STM32F072从零配置工程-自定义时钟配置详解
从自己的板子STM32F407入手,参考官方的SystemInit()函数: 核心在SetSysClock()这个函数,官方默认是采用HSE(设定为8MHz)作为PLL锁相环的输入输出168MHz的S ...
- WinForm控件之【CheckBox】
基本介绍 复选框顾名思义常用作选择用途,常见的便是多选项的使用: 常设置属性.事件 Checked:指示组件是否处于选中状态,true为选中处于勾选状态,false为未选中空白显示: Enabled: ...
- UVA816 Abbott的复仇 Abbott's Revenge
以此纪念一道用四天时间完结的题 敲了好几次代码的出错点:(以下均为正确做法) memset初始化 真正的出发位置必须找出. 转换东西南北的数组要从0开始. bfs没有初始化第一个d 是否到达要在刚刚取 ...
- GIL与异步回调
07.07自我总结 一.GIL 1.概念 在CPython中,这个全局解释器锁,也称为GIL,是一个互斥锁 2.带来的问题 首先必须明确执行一个py文件,分为三个步骤 从硬盘加载Python解释器到内 ...
- string的赋值
string的赋值 string s1="123456"; 一: 只能在刚开始定义的时候用: (1) 从后往前赋值 string s2(s1,3); ...
- 《C# 语言学习笔记》——委托
委托是一种可以把引用存储为函数的类型. 委托的声明非常类似于函数,但不带函数体,且要使用delegate关键字.委托的声明制定了一个返回类型和一个参数列表. 在定义了委托后,就可以声明该委托类型的变量 ...