NumPy数据的归一化
数据的归一化
首先我们来看看归一化的概念:
数据的标准化(normalization)和归一化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
归一化的目标
1 把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
2 把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。 比如,复数阻抗可以归一化书写:Z = R + jωL = R(1 + jωL/R) ,复数部分变成了纯数量了,没有量纲。
另外,微波之中也就是电路分析、信号系统、电磁波传输等,有很多运算都可以如此处理,既保证了运算的便捷,又能凸现出物理量的本质含义。
归一化后有两个好处
1. 提升模型的收敛速度
如下图,x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快(理解:也就是步长走多走少方向总是对的,不会走偏)
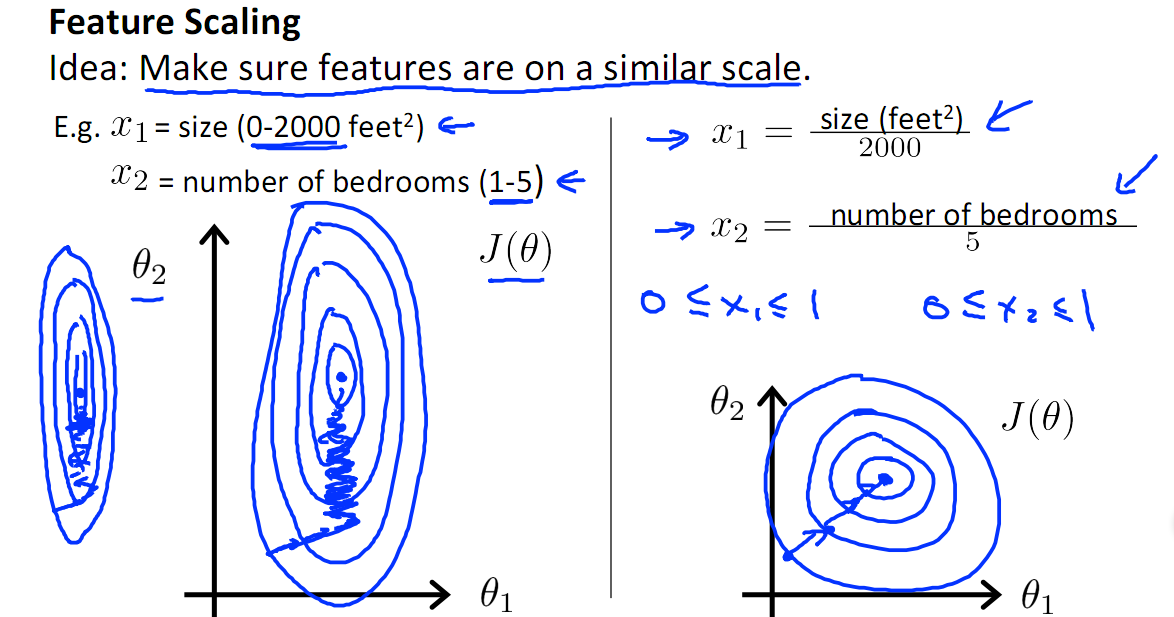
2.提升模型的精度
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。

现在我们再来看看基础的NumPy代码是如何实现的:
>>> x=np.random.random((,))
>>> x
array([[0.44951388, 0.58974524, 0.43980589],
[0.3082853 , 0.71042825, 0.02617535],
[0.10836115, 0.66774964, 0.85824697],
[0.01442332, 0.76459011, 0.75151452],
[0.64054078, 0.02121539, 0.87271819],
[0.75971598, 0.4268253 , 0.66039724],
[0.11865255, 0.14679259, 0.53782096],
[0.85085254, 0.26284603, 0.00246512],
[0.41957758, 0.96842006, 0.65555725],
[0.70227785, 0.78120928, 0.54771033]])
>>> x.mean()
array([0.43722009, 0.53398219, 0.53524118])
>>> xc=x-x.mean()
>>> xc
array([[ 0.01229379, 0.05576305, -0.0954353 ],
[-0.1289348 , 0.17644606, -0.50906583],
[-0.32885894, 0.13376745, 0.32300579],
[-0.42279677, 0.23060792, 0.21627333],
[ 0.20332068, -0.5127668 , 0.33747701],
[ 0.32249589, -0.10715689, 0.12515606],
[-0.31856754, -0.3871896 , 0.00257978],
[ 0.41363245, -0.27113616, -0.53277606],
[-0.01764252, 0.43443787, 0.12031607],
[ 0.26505776, 0.24722709, 0.01246915]])
>>> xc.mean()
array([ 5.55111512e-18, 3.33066907e-17, -4.44089210e-17])
因为最后归一化的均值在0附近,因此在机器精度范围之内,该均值为0。
NumPy数据的归一化的更多相关文章
- pandas学习(四)--数据的归一化
欢迎加入python学习交流群 667279387 Pandas学习(一)–数据的导入 pandas学习(二)–双色球数据分析 pandas学习(三)–NAB球员薪资分析 pandas学习(四)–数据 ...
- k-近邻算法(kNN)准备数据:归一化数值
#准备数据:归一化数值 def autoNorm(dataSet): #autoNorm()函数可以自动将数字特征值转换为0到1的区间 minVals = dataSet.min(0) maxVals ...
- 数据分析与展示——NumPy数据存取与函数
NumPy库入门 NumPy数据存取和函数 数据的CSV文件存取 CSV文件 CSV(Comma-Separated Value,逗号分隔值)是一种常见的文件格式,用来存储批量数据. np.savet ...
- 数据标准化/归一化normalization
http://blog.csdn.net/pipisorry/article/details/52247379 基础知识参考: [均值.方差与协方差矩阵] [矩阵论:向量范数和矩阵范数] 数据的标准化 ...
- Numpy数据存取
Numpy数据存取 numpy提供了便捷的内部文件存取,将数据存为np专用的npy(二进制格式)或npz(压缩打包格式)格式 npy格式以二进制存储数据的,在二进制文件第一行以文本形式保存了数据的元信 ...
- 转:数据标准化/归一化normalization
转自:数据标准化/归一化normalization 这里主要讲连续型特征归一化的常用方法.离散参考[数据预处理:独热编码(One-Hot Encoding)]. 基础知识参考: [均值.方差与协方差矩 ...
- python numpy数据相减
numpy数据相减,a和b两者shape要一样,然后是对应的位置相减.要不然,a的shape可以是(1,m),注意m要等于b的列数. import numpy as np a = [ [0, 1, 2 ...
- Python数据分析与展示(1)-数据分析之表示(2)-NumPy数据存取与函数
NumPy数据存取与函数 数据的CSV文件存取 CSV文件 CSV(Comma-Separated Value,逗号分隔值) CSV是一种常见的文件格式,用来存储批量数据. 将数据写入CSV文件 np ...
- Batch Normalization的算法本质是在网络每一层的输入前增加一层BN层(也即归一化层),对数据进行归一化处理,然后再进入网络下一层,但是BN并不是简单的对数据进行求归一化,而是引入了两个参数λ和β去进行数据重构
Batch Normalization Batch Normalization是深度学习领域在2015年非常热门的一个算法,许多网络应用该方法进行训练,并且取得了非常好的效果. 众所周知,深度学习是应 ...
随机推荐
- Nginx入门简介和反向代理、负载均衡、动静分离理解
场景 Nginx简介 Nginx ("engine x")是一个高性能的 HTTP 和反向代理服务器 特点是占有内存少,并发能力强,事实上 nginx 的并发能力确实在同类型的网页 ...
- java工作流系统-流程引擎执行自定义URL
关键词:工作流快速开发平台 工作流流设计 业务流程管理 asp.net 开源工作流 bpm工作流系统 java工作流主流框架 自定义工作流引擎 概要介绍: 用户在表达自己的业务逻辑时 ...
- iOS核心动画高级技巧-4
8. 显式动画 显式动画 如果想让事情变得顺利,只有靠自己 -- 夏尔·纪尧姆 上一章介绍了隐式动画的概念.隐式动画是在iOS平台创建动态用户界面的一种直接方式,也是UIKit动画机制的基础,不过它并 ...
- ReactNative: 使用对话框组件AlertIOS组件
一.简介 在使用一款App的时候,经常会用到对话框进行信息的友好提示,一般简单要求性不高的时候我们可以使用web提供的alert实现即可.但是,对于需要交互性和美观性的对话框,alert就明显无法满足 ...
- React中refs持久化
根据使用React的版本,选择合适的方法. 字符串模式 :废弃不建议使用 回调函数,React版本 < 16.3 React.createRef() :React版本 >= 16.3 回调 ...
- IO - 同步 异步 阻塞 非阻塞的区别,学习Swoole有帮助
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?本文较长需耐心阅读,基础 ...
- MySQL 两张表关联更新(用一个表的数据更新另一个表的数据)
有两张表,info1, info2 . info1: info2: 现在,要用info2中的数据更新info1中对应的学生信息,sql语句如下: UPDATE info1 t1 JOIN info2 ...
- 《C#并发编程经典实例》学习笔记—2.9 处理 async void 方法的异常
问题 需要处理从 async void 方法传递出来的异常. 解决方案 书中建议尽量不写 async void 这样的方法,如果非写不可,建议在方法内部 try catch 所有的代码,即在方法内部处 ...
- 新学期教育教学小学家长会PPT模板推荐
模版来源:http://ppt.dede58.com/jiaoxuekejian/26569.html
- 使用“npm init”初始化项目
使用npm init初始化项目 为什么要使用npm init初始化项目 在node开发中使用npm init会生成一个pakeage.json文件,这个文件主要是用来记录这个项目的详细信息的,它会将我 ...