[大数据学习研究] 4. Zookeeper-分布式服务的协同管理神器
本来这一节想写Hadoop的分布式高可用环境的搭建,写到一半,发现还是有必要先介绍一下ZooKeeper这个东西。
ZooKeeper理念介绍
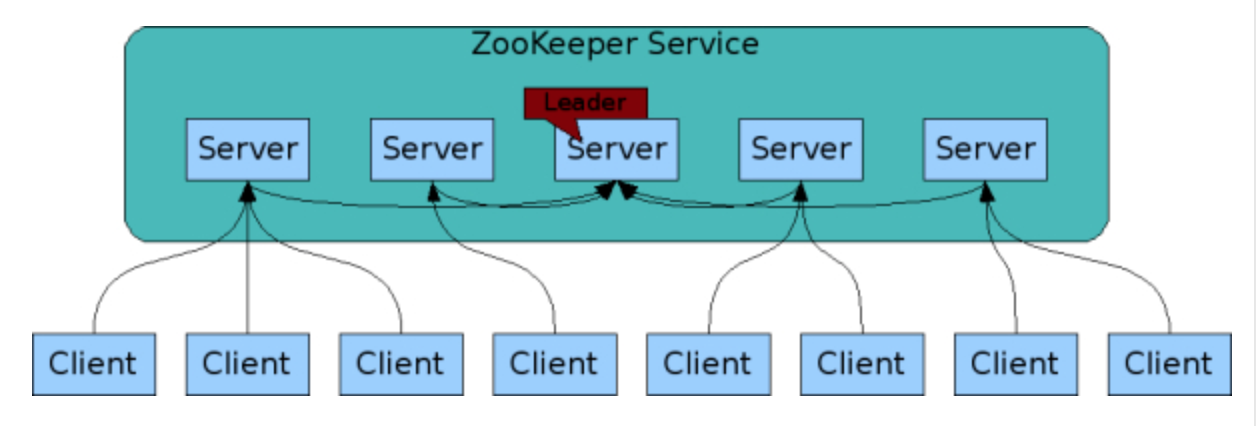
ZooKeeper是为分布式应用来提供协同服务的,而且ZooKeeper本身也是分布式的,由分布在至少三台机器上,这几台机器形成一个Quorum,就像一个剧团一样。这个团里有个团长,就是leader的角色,其他的是follower。这个剧团里的每个人脑子里都记住同样的东西(ZooKeeper是基于内存的),并且及时和leader保持同步,所有client可连接任何一个server即可。剧团里的每个人都有一个编号myid。如果剧团里的leader挂断后,剩下的几个要重新选举出新的leader来确保服务正常运行。
1. ZooKeepe的安装
ZooKeeper的安装挺简单,就是解压,设置环境变量就可以了
[root@hadoop100 bin]# tar -zxvf /opt/software/zookeeper-3.4..tar.gz -C /opt/modules/
打开/ect/profile 编辑环境变量,加上下面的内容:
#JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1..0_121
export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME
export HADOOP_HOME=/opt/modules/hadoop-2.7.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #ZOOKEEPER
export ZOOKEEPER_HOME=/opt/modules/zookeeper-3.4.
export PATH=$PATH:ZOOKEEPER_HOME/bin
然后 source /ect/profile 让更改生效。记得用xsync 和xcall超级脚本,把更改同步到整个集群。
[root@hadoop100 bin]# xsync /etc/profile
[root@hadoop100 bin]# xcall source /etc/profile
2. ZooKeeper的配置
1. Zookeeper 需要一个data目录,用于存储zookeeper内存数据库的镜像和日志。然后更改zoo.cfg文件。ZooKeeper解压后提供了一个/opt/modules/zookeeper-3.4.10/conf/zoo_sample.cfg文件,把这个复制一下或者改个名字叫zoo.cfg, 修改一下里面的dataDir的指向。
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/modules/zookeeper-3.4.10/zkData
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
~
要搭建ZooKeeper的机器环境,zookeeper服务器的数量应该是奇数台。最少要3台。
# 连接到leader 服务器的tick数,超过这个tick数 这台服务器还没有连接上leader,那这台机
器就被认为是死掉了
initLimit =
# 在和leader同步过程中所允许落后的最大tick数,如果超过这个,那就是掉队了
syncLimit =
server.=hadoop100::
server.=hadoop101::
server.=hadoop102::
server.=hadoop103::
server.=hadoop104::
机器的参数配置的格式是这样的:
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
注意更改完毕后别忘了分发到集群中。zookeeper本身是也分布式的。先把相关文件分发到集群中的其他机器上。
[root@hadoop100 modules]# xsync zookeeper-3.4.10/
然后为每台机器做上独特的标记,在data目录里创建myId文件,内容就是上面配置文件中的数字
[root@hadoop100 zookeeper-3.4.]# cd zkData/
[root@hadoop100 zkData]# echo > myid
在集群的其他几台机器上修改myid文件的内容,让myid的内容和配置文件中的编号一致。这时候只能麻烦点,依次登录到每台机器上创建 data目录下的myid文件了。
[root@hadoop100 zkData]# ssh hadoop101
Last login: Thu Sep :: from gateway
[root@hadoop101 ~]# echo > /opt/modules/zookeeper-3.4./zkData/myid
[root@hadoop101 ~]#exit
[root@hadoop100 zkData]# ssh hadoop101
Last login: Thu Sep 19 14:10:35 2019 from gateway
[root@hadoop101 ~]# echo 101 > /opt/modules/zookeeper-3.4.10/zkData/myid
[root@hadoop101 ~]# exit
logout
Connection to hadoop101 closed.
[root@hadoop100 zkData]# ssh hadoop102
Last login: Tue Sep 17 13:26:48 2019 from hadoop100
[root@hadoop102 ~]# echo 102 > /opt/modules/zookeeper-3.4.10/zkData/myid
[root@hadoop102 ~]# exit
logout
Connection to hadoop102 closed.
[root@hadoop100 zkData]# ssh hadoop103
Last login: Tue Sep 17 13:17:00 2019 from hadoop100
[root@hadoop103 ~]# echo 103 > /opt/modules/zookeeper-3.4.10/zkData/myid
[root@hadoop103 ~]# exit
logout
Connection to hadoop103 closed.
[root@hadoop100 zkData]# ssh hadoop104
Last login: Tue Sep 17 11:04:38 2019 from hadoop100
[root@hadoop104 ~]# echo 104 > /opt/modules/zookeeper-3.4.10/zkData/myid
[root@hadoop104 ~]# exit
logout
Connection to hadoop104 closed.
检查一下确保没问题
[root@hadoop100 bin]# xcall cat /opt/modules/zookeeper-3.4./zkData/myid
---------running at localhost-------- ---------running at hadoop101------- ---------running at hadoop102------- ---------running at hadoop103------- ---------running at hadoop104------- [root@hadoop100 bin]#
好了,基本配置好了,准备启动了,ZooKeeper集群都要启动ZooKeeper服务。我用之前介绍过的超级脚本xcall. (后来发现用这种方式靠不住,说是启动了,其实没启动 ;;;)
[root@hadoop100 zkData]# xcall /opt/modules/zookeeper-3.4./bin/zkServer.sh start
---------running at localhost--------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------running at hadoop101-------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------running at hadoop102-------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------running at hadoop103-------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------running at hadoop104-------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@hadoop100 zkData]#
错误排查:Error contacting service. It is probably not running.
查看一下运行状态, 啊哦,怎么没启动呢?
[root@hadoop100 bin]# xcall /opt/modules/zookeeper-3.4./bin/zkServer.sh status
---------running at localhost--------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
---------running at hadoop101-------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
---------running at hadoop102-------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
---------running at hadoop103-------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
---------running at hadoop104-------
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
[root@hadoop100 bin]#
后来发现需要单独ssh到每台机器上单独启动就可以了,可能是xcall神器有的时候不可靠。不过提示一点,zkServer.sh start-foreground 命令,可以在查看详细启动过程,方便排查错误。
[root@hadoop101 ~]# /opt/modules/zookeeper-3.4./bin/zkServer.sh start-foreground
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
-- ::, [myid:] - INFO [main:QuorumPeerConfig@] - Reading configuration from: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
-- ::, [myid:] - INFO [main:QuorumPeer$QuorumServer@] - Resolved hostname: hadoop104 to address: hadoop104/192.168.56.104
-- ::, [myid:] - INFO [main:QuorumPeer$QuorumServer@] - Resolved hostname: hadoop103 to address: hadoop103/192.168.56.103
-- ::, [myid:] - INFO [main:QuorumPeer$QuorumServer@] - Resolved hostname: hadoop102 to address: hadoop102/192.168.56.102
-- ::, [myid:] - INFO [main:QuorumPeer$QuorumServer@] - Resolved hostname: hadoop101 to address: hadoop101/192.168.56.101
-- ::, [myid:] - INFO [main:QuorumPeer$QuorumServer@] - Resolved hostname: hadoop100 to address: hadoop100/192.168.56.100
-- ::, [myid:] - INFO [main:QuorumPeerConfig@] - Defaulting to majority quorums
-- ::, [myid:] - INFO [main:DatadirCleanupManager@] - autopurge.snapRetainCount set to
-- ::, [myid:] - INFO [main:DatadirCleanupManager@] - autopurge.purgeInterval set to
-- ::, [myid:] - INFO [main:DatadirCleanupManager@] - Purge task is not scheduled.
-- ::, [myid:] - INFO [main:QuorumPeerMain@] - Starting quorum peer
-- ::, [myid:] - INFO [main:NIOServerCnxnFactory@] - binding to port 0.0.0.0/0.0.0.0:
-- ::, [myid:] - ERROR [main:QuorumPeerMain@] - Unexpected exception, exiting abnormally
java.net.BindException: Address already in use
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:)
at sun.nio.ch.Net.bind(Net.java:)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:)
at org.apache.zookeeper.server.NIOServerCnxnFactory.configure(NIOServerCnxnFactory.java:)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:)
[root@hadoop101 ~]#
如果jps命令能看到QuorumPeerMain就是已经启动成功了。
[root@hadoop100 bin]# jps
QuorumPeerMain
Jps
SSH单独登录到各个服务器上依次启动,并查看状态,可以发现我现在的集群环境中hadoop102是leader,其他几台是follower:
[root@hadoop100 bin]# /opt/modules/zookeeper-3.4./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
[root@hadoop100 bin]# ssh hadoop101
Last login: Thu Sep :: from hadoop100
[root@hadoop101 ~]# /opt/modules/zookeeper-3.4./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
[root@hadoop101 ~]# exit
logout
Connection to hadoop101 closed.
[root@hadoop100 bin]# ssh hadoop102
Last login: Thu Sep :: from hadoop100
[root@hadoop102 ~]# /opt/modules/zookeeper-3.4./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: leader
[root@hadoop102 ~]# exit
logout
Connection to hadoop102 closed.
[root@hadoop100 bin]# ssh hadoop103
Last login: Thu Sep :: from hadoop100
[root@hadoop103 ~]# /opt/modules/zookeeper-3.4./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
[root@hadoop103 ~]# exit
logout
Connection to hadoop103 closed.
[root@hadoop100 bin]# ssh hadoop104
Last login: Thu Sep :: from hadoop100
[root@hadoop104 ~]# /opt/modules/zookeeper-3.4./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/modules/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
[root@hadoop104 ~]# exit
logout
Connection to hadoop104 closed.
[root@hadoop100 bin]#
好了,到现在为止,我的ZooKeeper集群环境已经搭建成功了。
题外话
学习研究的话可以用虚拟机,真要认真做点事还是要上云,比如阿里云。如果你需要,可以用我的下面这个链接,有折扣返现。
https://promotion.aliyun.com/ntms/yunparter/invite.html?userCode=vltv9frd
[大数据学习研究] 4. Zookeeper-分布式服务的协同管理神器的更多相关文章
- [大数据学习研究] 3. hadoop分布式环境搭建
1. Java安装与环境配置 Hadoop是基于Java的,所以首先需要安装配置好java环境.从官网下载JDK,我用的是1.8版本. 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中 ...
- [大数据学习研究]1.在Mac上利用VirtualBox搭建本地虚拟机环境
1. 大数据和Hadoop 研究学习大数据,自然要从Hadoop开始. Hadoop不是一个简单的软件,而是有一些列软件形成的生态,其核心思想来自Google当初发布的三篇论文,后来做了开源的实现, ...
- 大数据学习路线:Zookeeper集群管理与选举
大数据技术的学习,逐渐成为很多程序员的必修课,因为趋势也是因为自己的职业生涯.在各个技术社区分享交流成为很多人学习的方式,今天很荣幸给我们分享一些大数据基础知识,大家可以一起学习! 1.集群机器监控 ...
- 大数据学习笔记之Zookeeper(一):Zookeeper理论篇(一)
文章目录 1.1 概述 1.2 应用场景 1.3 下载地址 1.1 概述 Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目. Zookeeper从设计模式角度来理解: ...
- 大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念: Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. Hadoo ...
- Java学习之Dubbo+ZooKeeper分布式服务Demo
背景:在之前的一个<Java学习之SpringBoot整合SSM Demo>分享中说到搭建ZooKeeper和Dubbo分布式框架中遇到了一些技术问题没能成功,只分享了其中的一个中间产物, ...
- 大数据学习笔记之Zookeeper(四):Zookeeper实战篇(二)
文章目录 4.1 分布式安装部署 4.2 客户端命令行操作 4.3 API应用 4.3.1 eclipse环境搭建 4.3.2 创建ZooKeeper客户端: 4.3.3 创建子节点 4.3.4 获取 ...
- 大数据学习笔记之Zookeeper(三):Zookeeper理论篇(二)
文章目录 3.1 数据结构 3.2 节点类型 3.3 特点 3.4 选举机制 3.5 stat结构体 3.6 监听器原理 3.1 数据结构 ZooKeeper数据模型的结构与Unix文件系统很类似,整 ...
- [大数据学习研究]2.利用VirtualBox模拟Linux集群
1. 在主机Macbook上设置HOST 前文书已经把虚拟机的静态IP地址设置好,以后可以通过ip地址登录了.不过为了方便,还是设置一下,首先在Mac下修改hosts文件,这样在ssh时就不用输入ip ...
随机推荐
- 洛谷 P2016 战略游戏
题意简述简述 求一棵树的最小点覆盖 题解思路 树形DP dp[i][0]表示第i个点覆盖以i为根的子树的最小值,且第i个点不放士兵 dp[i][1]表示第i个点覆盖以i为根的子树的最小值,且第i个点放 ...
- 《机器学习基石》---Linear Models for Classification
1 用回归来做分类 到目前为止,我们学习了线性分类,线性回归,逻辑回归这三种模型.以下是它们的pointwise损失函数对比(为了更容易对比,都把它们写作s和y的函数,s是wTx,表示线性打分的分数) ...
- 优雅的在WinForm/WPF/控制台 中使用特性封装WebApi
优雅的在WinForm/WPF/控制台 中使用特性封装WebApi 说明 在C/S端作为Server,建立HTTP请求,方便快捷. 1.使用到的类库 Newtonsoft.dll 2.封装 HttpL ...
- ThreadLocal中优雅的数据结构如何体现农夫山泉的广告语
本篇文章主要讲解 ThreadLocal 的用法和内部的数据结构及实现.有时候我们写代码的时候,不太注重类之间的职责划分,经常造出一些上帝类,也就是什么功能都往这个类里放.虽然能实现功能但是并不优雅且 ...
- MQTT的学习之Mosquitto安装和使用
Mosquitto是一个实现了MQTT3.1协议的代理服务器,由MQTT协议创始人之一的Andy Stanford-Clark开发,它为我们提供了非常棒的轻量级数据交换的解决方案.本文的主旨在于记录M ...
- mybatis对象的插入
或者: 传入JAVA对象 mapper接口代码: public int findUserList(User user); xml代码: <select id="findUserList ...
- 【翻译】无需安装Python,就可以在.NET里调用Python库
原文地址:https://henon.wordpress.com/2019/06/05/using-python-libraries-in-net-without-a-python-installat ...
- LSTM 反向传播算法
1. https://www.cnblogs.com/pinard/p/6519110.html (详细原理!) 2. https://blog.csdn.net/abeldeng/article/d ...
- 终于跑通分布式事务框架tcc-transaction的示例项目
1.背景 前段时间在看项目代码的时候,发现有些接口的流程比较长,在各个服务里面都有通过数据库事务保证数据的一致性,但是在上游的controller层并没有对一致性做保证. 网上查了下,还没找到基于Go ...
- 吃货眼中的sqlalchemy外键和连表查询
前言 使用数据库一个高效的操作是连表查询,一条查询语句能够查询到多个表的数据.在sqlalchem架构下的数据库连表查询更是十分方便.那么如何连表查询?以及数据库外键对连表查询有没有帮助呢?本篇文章就 ...