xshell5运行hadoop集群
---恢复内容开始---
1.CentOS主机配置
在配置Hadoop过程中,防火墙必须优先关闭SELinux,否则将影响后续Hadoop配置与使用,命令如下:
# 查看 “系统防火墙” 状态命令
systemctl status firewalld.service
# 关闭 “系统防火墙” 命令
systemctl stop firewalld.service
# 关闭 “系统防火墙” 自启动命令
systemctl disable firewalld.service
# 关闭 “SELinux”命令
setenforce 0
# 关闭“SELinux”系统系统自启动服务
vi /etc/selinux/config
# 修改内容
SELINUX=disabled
(1)执行图结果如下:
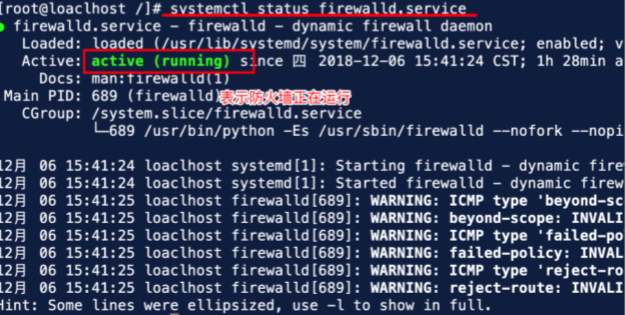
(2)上图的防火墙处于运行状态,现在关闭防火墙,如下图:
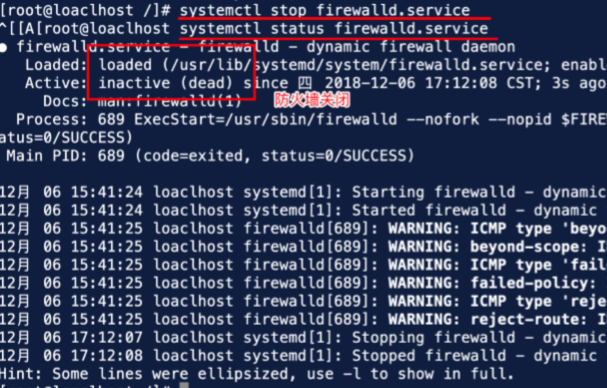
(3)关闭防火墙后,因为重启服务器防火墙会自动重启,关闭系统自启动命令如下:
# systemctl firewalld.service
2.设置主机名称
(1)使用vi编译器编译 #vi /etc/sysconfig/network,修改其内容:
# 修改为:
NETWORKING=yes
HOSTNAME=master
(2)修改主机名,进入#vi /etc/hostname里修改内容:
# 修改为: master
3.配置hosts文件
(1)编译#vi /etc/hosts添加内容,不用去掉原先内容:
#添加内容
192.168.56.110 master
(2)192.168.56.110为IP地址。
4.验证配置结果
(1)重启后主机为master。
# 重启系统命令
reboot now
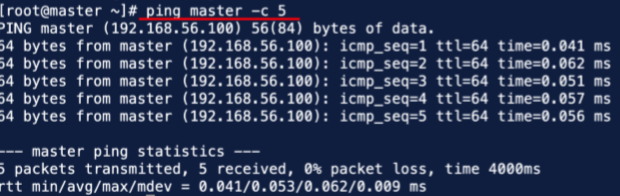
(2)在终端输入命令 #ping master -c 5查看是否成功。
5.JavaJDK环境配置
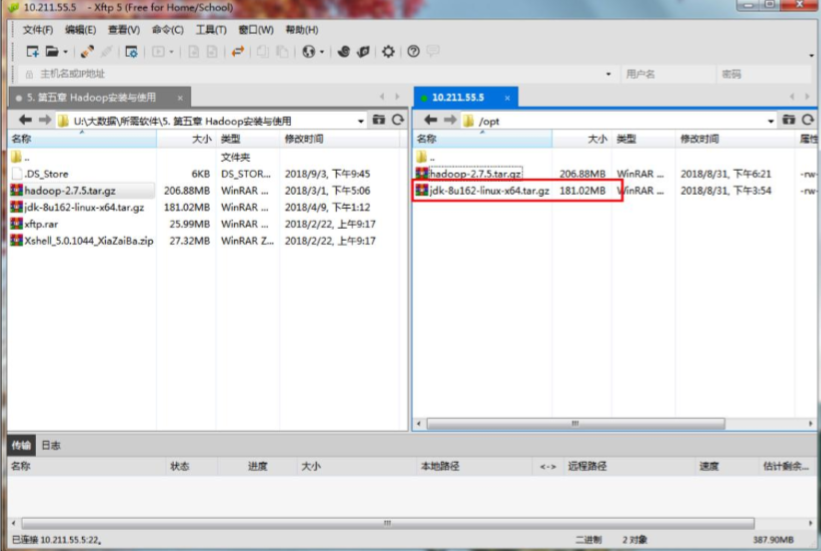
(1)上传JDK文件,使用xftp将jdk传到/opt目录下,如图:
(2)解压缩JDK安装包
进入/opt 目录并解 压 缩 文 件 #tar -zxvf /opt/jdk-8u162-linux-x64.tar.gz
(3)移动 javaJDK 目录至/usr/local/java 中 ,其环境变量地址与Java目录一致
#mv /opt/jdk1.8.0_162 /usr/local/java
(4)配置环境变量
编辑 .bash_profile 文件 :
#vi /root/.bash_profile
添加内容 :
export JAVA_HOME=/usr/local/java
export PATH=$JAVA_HOME/bin:$PATH
使环境变量生效:
#source /root/.bash_profile
(5)验证JDK配置是否成功,使用# java -version,结果如下:

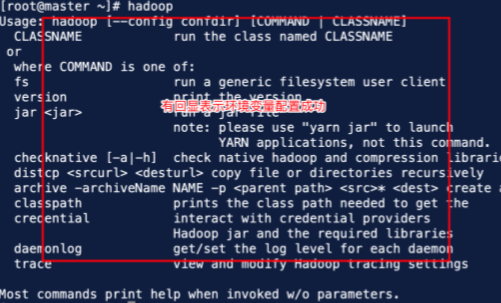
6.Hadoop安装与配置
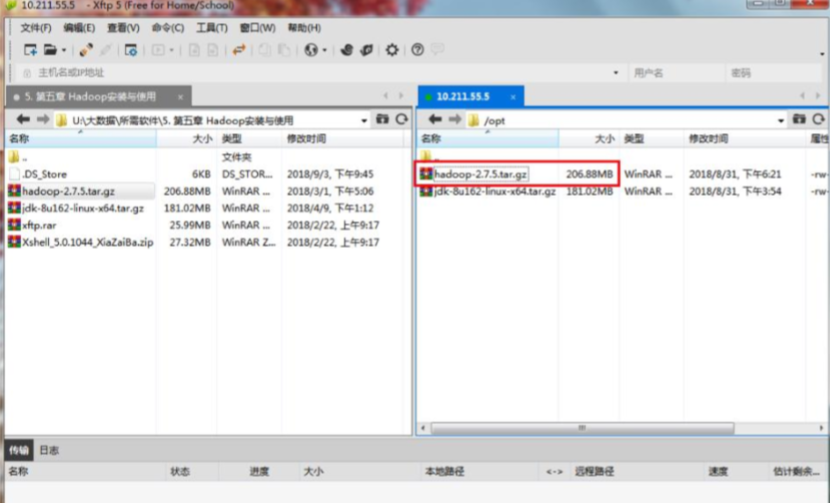
(1)使用xftp将Hadoop软件包上传至/opt下,如图:
(2)解压Hadoop
上传完成后,解压缩文件 #tar -zxvf /opt/hadoop-2.7.5.tar.gz
修改 hadoop-2.7.6-src 目录名称为 hadoop
#mv /opt/hadoop-2.7.5 /opt/hadoo
(3)配置环境变量
编辑 .bash_profile 文件:
#vi /root/.bash_profile
添加内容 :
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(4)添加完成后,输入命令 #source /root/.bash_profile 使环境变量生效。
7.配置其文件
(1)配置core-site.xml 文件
#vi /opt/hadoop/etc/hadoop/core-site.xml
配置其内容:
在<configuration>补充区域</configuration>中间补充
补充内容,如下
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>
(2)配置文件系统hdfs-site.xml
# vi /opt/hadoop/etc/hadoop/hdfs-site.xml
配置内容如下 :
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(3)配置资源管理器yarn-site.xml
#vi /opt/hadoop/etc/hadoop/yarn-site.xml
补充内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
(4)配置添加计算框架mapred-site.xml
复制文件
#cp /opt/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/etc/hadoop/mapredsite.xml
编辑文件
#vi /opt/hadoop/etc/hadoop/mapred-site.xml
配置内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)创建数据文件
创建文件
#mkdir /opt/hadoop/hadoopdata
格式化文件系统
#hadoop namenode -format
8.设置SSH网络
(1)ssh-keygen免密登陆设置,输入命令键回车三次
生成免登入密匙 #ssh-keygen -t rsa

(2)为 master 发送免登入密匙 #ssh-copy-id -i ~/.ssh/id_rsa root@192.168.56.110
注意:输入 yes 回车 yes
输入密码 ,密码为xshell密码。

(3)ssh 连接 master
#ssh master
(4)直接输入 JavaJDK 物理路径
配置文件
# vi /opt/hadoop/etc/hadoop/hadoop-env.sh
内容为 JAVA 路径 :
export JAVA_HOME=/usr/local/java
9.启动Hadoop
(1)开启命令 #start-all.sh
停止命令 #stop-all.sh
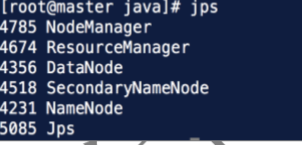
(2)验证配置是否成功
查看 Hadoop 进程
# jps
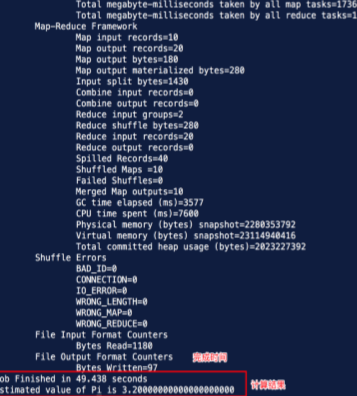
(3)计算PI,看Hadoop是否运行的起
Hadoop 运行 jar 包命令
# hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.j ar pi 10 10
10.多节点配置Hadoop
(1) 编辑文件
#vi /opt/hadoop/etc/hadoop/slaves
内容 :
slave1
slave2
(2)配置hosts主机文件
#vi /etc/hosts
添加内容
192.168.56.111 slave1
192.168.56.112 slave2
(3)虚拟机克隆IP地址

(4)修改克隆主机名
#slave1
NETWORKING=yes
HOSTNAME=slave1
#slave2
NETWORKING=yes
HOSTNAME=slave2
配置文件
#/etc/sysconfig/hostname
修改文件 slave1
修改文件 slave2
(5)配置三台机子免密登陆
ssh-copy-id -i ~/.ssh/id_rsa root@master
ssh-copy-id -i ~/.ssh/id_rsa root@slave1
ssh-copy-id -i ~/.ssh/id_rsa root@slave2
---恢复内容结束---
xshell5运行hadoop集群的更多相关文章
- 沉淀,再出发——手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群
手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群 一.准备,再出发 在项目启动之前,让我们看一下前面所做的工作.首先我们掌握了一些Linux的基本命令和重要的文件,其次我们学会 ...
- eclipse 远程链接访问hadoop 集群日志信息没有输出的问题l
Eclipse插件Run on Hadoop没有用到hadoop集群节点的问题参考来源 http://f.dataguru.cn/thread-250980-1-1.html http://f.dat ...
- Hadoop集群(第6期)_WordCount运行详解
1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然 ...
- Hadoop集群运行JNI程序
要在Hadoop集群运行上运行JNI程序,首先要在单机上调试程序直到可以正确运行JNI程序,之后移植到Hadoop集群就是水到渠成的事情. Hadoop运行程序的方式是通过jar包,所以我们需要将所有 ...
- hadoop集群的三种运行模式
单机(本地)模式: 这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统.在单机模式(standalone)中不会存在守护进程,所有东西都运行在一个JVM上.这里同样没有D ...
- 编写hadoop程序,并打包jar到hadoop集群运行
windows环境下编写hadoop程序 新建:File->new->Project->Maven->next GroupId 和ArtifactId 随便写(还是建议规范点) ...
- Windows平台开发Mapreduce程序远程调用运行在Hadoop集群—Yarn调度引擎异常
共享原因:虽然用一篇博文写问题感觉有点奢侈,但是搜索百度,相关文章太少了,苦苦探寻日志才找到解决方案. 遇到问题:在windows平台上开发的mapreduce程序,运行迟迟没有结果. Mapredu ...
- Hadoop集群WordCount运行详解(转)
原文链接:Hadoop集群(第6期)_WordCount运行详解 1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对 ...
- [转]Hadoop集群_WordCount运行详解--MapReduce编程模型
Hadoop集群_WordCount运行详解--MapReduce编程模型 下面这篇文章写得非常好,有利于初学mapreduce的入门 http://www.nosqldb.cn/1369099810 ...
随机推荐
- liteos C++支持(十七)
1 概述 1.1 基本概念 C++作为目前使用最广泛的编程语言之一,支持类.封装.重载等特性,是在C语言基础上开发的一种面向对象的编程语言. 1.2 运作机制 STL(Standard Templat ...
- xposed 原理分析
1.添加hook方法 首先是init进程打开 app_process,然后进入XposedInit.java main() - > initForZygote() 加入对ActivityThre ...
- CF-1175 B.Catch Overflow!
题目大意:有一个初始变量,值为0,三种操作 for x 一个循环的开始,循环x次 end 一个循环的结束 add 将变量值加一 问最后变量的值是否超过2^32-1,若超过,输出一串字符,不超过则输出变 ...
- CF-1238 C.Standard Free2play
题目大意: 有一个墙,高度为h,在每一个高度处都有一个踏板,有的踏板是隐藏着的,有的是伸出来的,小人站在h高度处(题目保证h高度处的踏板一定是伸出来的),这个小人每站到一个踏板上,就可以点一个开关,将 ...
- AtCoder Beginner Contest 139F Engines
链接 problem 给出\(n\)个二元组\((x,y)\).最初位于原点\((0,0)\),每次可以从这\(n\)个二元组中挑出一个,然后将当前的坐标\((X,Y)\)变为\((X+x,Y+y)\ ...
- nuxtjs踩坑指南
1.nuxt引入问题:Can't resolve 'stylus-loader' 原因在于没有安装stylus,安装即可:npm install stylus stylus-loader --save ...
- Jupyter notebook中的.ipynb文件转换成python的.py文件
转自:https://blog.csdn.net/wyr_rise/article/details/82656555 Jupyter notebook中.py与.ipynb文件的import问题 ...
- 数据分析常用的Excel函数
Excel是我们工作中经常使用的一种工具,对于数据分析来说,这也是处理数据最基础的工具. 本文对数据分析需要用到的函数做了分类,并且有详细的例子说明,文章已做了书签处理,点击可跳转至相应位置. 函数分 ...
- 解决python 缺少os.fspath
在python3.6下运行pandas会报错缺少os.fspath 升级到python3.7 3.7 安装参考:https://www.cnblogs.com/jifeng/p/11221469.ht ...
- python-3-条件判断练习题
前言 我们在前面两章学习了基础数据类型与条件判断语句,今天我们来做下练习题.如果你有不一样的解题思路在评论区亮出你的宝剑!!! 一.习题如下: 1.使用 while 循环输出 1 2 3 4 5 6 ...