embedding技术
word2vec
Word2Vec是一个可以将语言中的字词转换为低维、稠密、连续的向量表达(Vector Respresentations)的模型,其主要依赖的假设是Distributional Hypothesis(1954年由Harris提出分布假说,即上下文相似的词,其语义也相似;我的理解就是词的语义可以根据其上下文计算得出)
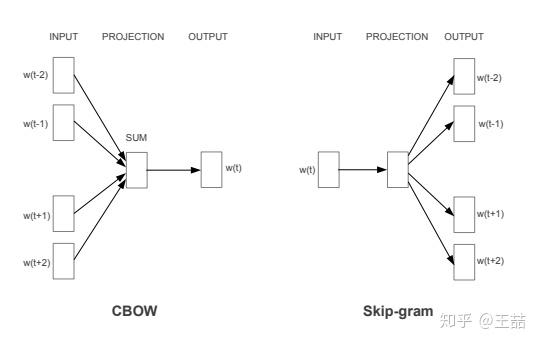
Word2vec主要分为CBOW(Continuous Bag of Words)和Skip Gram两种模式,其中CBOW是从原始数据推测目标字词;而Skip-Gram是从目标字词推测原始语句,其中CBOW对小型数据比较合适,而Skip-Gram在大型预料中表现得更好。
负采样
负采样的基本思想是用采样一些负例的方式近似代替遍历整个词汇。
目标函数
$ J^h( \theta ) = log \sigma( \Delta S_{\theta}(w,h)) + k log(1 - \sigma(\Delta S_{\theta}(w,h))) $
\(其中h=w_1,...,w_n为上下文词序列\)
\(P_n(w)代表负样本分布为,w是抽样词\)
\(P_d(w)代表正样本(真实数据)分布\)
$ \sigma(x)=\frac{1}{1+e^{-x}}是sigmoid函数 $
$ \theta 代表模型参数$
\(k 代表负样本与正样本的比例\)
\(P^h( D=1|w,\theta ) = \frac{P^h_{\theta}(w)}{P^h_{\theta}(w)+kP_n(w)}=\sigma(\Delta S_{\theta}(w,h)) 代表在给定上下文h,参数\theta情况下w是正样本的概率\)
\(其中S_{\theta}(w,h)=\hat{q}(h)^T q_w + b_w = (\sum^n_{i=1}c_i \bigodot r_{w_i})^T q_w + b_w\)
\(\hat{q}(h) = \sum^n_{i=1}c_i \bigodot r_{w_i}是上下文词向量的线性加权,代表对目标词的估计值\)
\(c_i代表上下文词在位置i的权重向量\)
\(r_{w_i}代表上下文词i的词向量表示\)
\(q_w代表目标词的词向量表示\)
\(b_w代表上下文无关的偏置项\)
反向梯度
$ \frac{\partial }{\partial \theta} J^{h,w}(\theta) = (1-\sigma(\Delta S_{\theta}(w,h))) \frac{\partial }{\partial \theta}logP^h_\theta(w) - \sum^k_{i=1}[\sigma(\Delta S_{\theta}(w,h))\frac{\partial }{\partial \theta}logP^h_\theta(x_i)]$
公式中使用k个噪音样本的词向量加和来代替词典全部词汇的加和,所以NCE的训练时间只线性相关于负样本个数,与词典大小无关。
层次softmax
Hierarchical Softmax中不更新每个词的输出词向量,更新的是二叉树(哈夫曼树)上节点对应的向量。代价由
embedding技术的更多相关文章
- 将句子表示为向量(上):无监督句子表示学习(sentence embedding)
1. 引言 word embedding技术如word2vec,glove等已经广泛应用于NLP,极大地推动了NLP的发展.既然词可以embedding,句子也应该可以(其实,万物皆可embeddin ...
- 推文《阿里凑单算法首次公开!基于Graph Embedding的打包购商品挖掘系统解析》笔记
推文<阿里凑单算法首次公开!基于Graph Embedding的打包购商品挖掘系统解析>笔记 从17年5月份开始接触Graph Embedding,学术论文读了很多,但是一直不清楚这技术是 ...
- GNN 相关资料记录;GCN 与 graph embedding 相关调研
最近做了一些和gnn相关的工作,经常听到GCN 和 embedding 相关技术,感觉很是困惑,所以写下此博客,对相关知识进行索引和记录: 参考链接: https://www.toutiao.com/ ...
- 深度解析Graph Embedding
Graph Embedding是推荐系统.计算广告领域最近非常流行的做法,是从word2vec等一路发展而来的Embedding技术的最新延伸:并且已经有很多大厂将Graph Embedding应用于 ...
- GNN 相关资料记录;GCN 与 graph embedding 相关调研;社区发现算法相关;异构信息网络相关;
最近做了一些和gnn相关的工作,经常听到GCN 和 embedding 相关技术,感觉很是困惑,所以写下此博客,对相关知识进行索引和记录: 参考链接: https://www.toutiao.com/ ...
- 【转载】Emdedding向量技术在蘑菇街推荐场景的应用
花名:越祈 部门:算法中心搜索策略组 入职时间:2017/06/01 主要从事蘑菇街推荐算法相关研发工作 蘑菇街是一家社会化导购电商平台,推荐一直是其非常重要的流量入口.在电商平台中,推荐的场景覆盖到 ...
- C_C++圣战(摘录)
我的回忆和有趣的故事 --- C/C++圣战篇 李维 (声明以下的这篇文章内容是我个人的回忆以及看法,没有任何特别的偏见,许多的事情是根据我的记忆以及从许多人的诉说中得知的,也许内容不是百分之百的正确 ...
- 深度召回模型在QQ看点推荐中的应用实践
本文由云+社区发表 作者:腾讯技术工程 导语:最近几年来,深度学习在推荐系统领域中取得了不少成果,相比传统的推荐方法,深度学习有着自己独到的优势.我们团队在QQ看点的图文推荐中也尝试了一些深度学习方法 ...
- 手把手教你用 Keras 实现 LSTM 预测英语单词发音
1. 动机 我近期在研究一个 NLP 项目,根据项目的要求,需要能够通过设计算法和模型处理单词的音节 (Syllables),并对那些没有在词典中出现的单词找到其在词典中对应的押韵词(注:这类单词类似 ...
随机推荐
- RestTemplate最详解
目录 1. RestTemplate简单使用 2. 一些其他设置 3. 简单总结 在项目中,当我们需要远程调用一个HTTP接口时,我们经常会用到RestTemplate这个类.这个类是Spring框架 ...
- Vue+ElementUI项目使用webpack输出MPA
目录 Vue+ElementUI项目使用webpack输出MPA 一. 需求分析 二. 原方案分析 三. 多页面改造3步走 四. 小结 Vue+ElementUI项目使用webpack输出MPA 示例 ...
- C笔记_动态库和静态库
1. 静态库 创建 工程属性配置中设置为lib静态库,编辑.h文件和.c文件,生成即可. 使用 方法一: 添加工程的头文件目录:工程---属性---配置属性---c/c++---常规---附加包含目录 ...
- TokuDB · 引擎特性 · HybridDB for MySQL高压缩引擎TokuDB 揭秘
原文出处:阿里云RDS-数据库内核组 HybridDB for MySQL(原名petadata)是面向在线事务(OLTP)和在线分析(OLAP)混合场景的关系型数据库.HybridDB采用一份数据存 ...
- Flutter学习笔记(25)--ListView实现上拉刷新下拉加载
如需转载,请注明出处:Flutter学习笔记(25)--ListView实现上拉刷新下拉加载 前面我们有写过ListView的使用:Flutter学习笔记(12)--列表组件,当列表的数据非常多时,需 ...
- Python Web Flask源码解读(一)——启动流程
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- Leetcode之深度优先搜索&回溯专题-491. 递增子序列(Increasing Subsequences)
Leetcode之深度优先搜索&回溯专题-491. 递增子序列(Increasing Subsequences) 深度优先搜索的解题详细介绍,点击 给定一个整型数组, 你的任务是找到所有该数组 ...
- 求大的组合数模板 利用Lucas定理
Lucas定理:A.B是非负整数,p是质数.A B写成p进制:A=a[n]a[n-1]…a[0],B=b[n]b[n-1]…b[0]. 则组合数C(A,B)与C(a[n],b[n])C(a[n-1], ...
- Vue使用MathJax动态识别数学公式
本人菜鸟一名,如有错误,还请见谅. 1.前言 最近公司的一个项目需求是在前端显示Latex转化的数学公式,经过不断的百度和测试已基本实现.现在此做一个记录. 2.MathJax介绍 MathJax是一 ...
- Python---网页元素
文章目录 1. 前言 万维网 万维网的关键技术 2. 网页基本框架 HTML CSS: JavaScript 在介绍审查元素之前我们先简单介绍一下网页的基本框架 1. 前言 万维网 万维网(英语:Wo ...