phper使用MySQL 针对千万级的大表要怎么优化?
有需要学习交流的友人请加入交流群的咱们一起,群内都是1-7年的开发者,希望可以一起交流,探讨PHP,swoole这块的技术 或者有其他问题 也可以问,获取swoole或者php进阶相关资料私聊管理即可
首先采用Mysql存储千亿级的数据,确实是一项非常大的挑战。Mysql单表确实可以存储10亿级的数据,只是这个时候性能非常差,项目中大量的实验证明,Mysql单表容量在500万左右,性能处于最佳状态。
针对大表的优化,主要是通过数据库分库分表来解决,目前比较普遍的方案有三个:分区,分库分表,NoSql/NewSql。实际项目中,这三种方案是结合的,目前绝大部分系统的核心数据都是以RDBMS存储为主,NoSql/NewSql存储为辅。
分区
首先来了解一下分区方案。
分区表是由多个相关的底层表实现的。这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引。这个方案对用户屏蔽了sharding的细节,即使查询条件没有sharding column,它也能正常工作(只是这时候性能一般)。
不过它的缺点很明显:很多的资源都受到单机的限制,例如连接数,网络吞吐等。如何进行分区,在实际应用中是一个非常关键的要素之一。
下面开始举例:以客户信息为例,客户数据量5000万加,项目背景要求保存客户的银行卡绑定关系,客户的证件绑定关系,以及客户绑定的业务信息。
此业务背景下,该如何设计数据库呢。项目一期的时候,我们建立了一张客户业务绑定关系表,里面冗余了每一位客户绑定的业务信息。
基本结构大致如下:
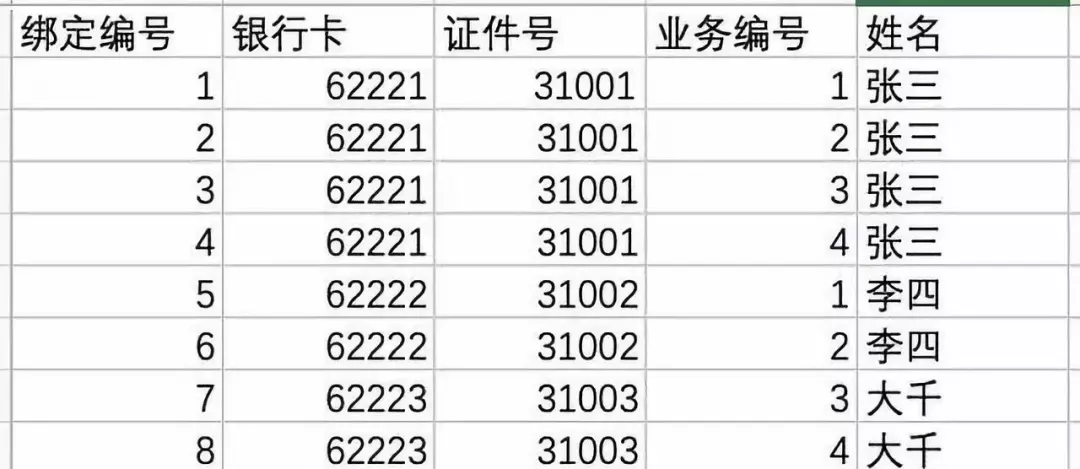
查询时,对银行卡做索引,业务编号做索引,证件号做索引。随着需求大增多,这张表的索引会达到10个以上。而且客户解约再签约,里面会保存两条数据,只是绑定的状态不同。
假设我们有5千万的客户,5个业务类型,每位客户平均2张卡,那么这张表的数据量将会达到惊人的5亿,事实上我们系统用户量还没有过百万时就已经不行了。这样的设计绝对是不行的,无论是插入,还是查询,都会让系统崩溃。
mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看), 一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。这三个文件都非常的庞大,尤其是.myd文件,快5个G了。下面进行第一次分区优化,Mysql支持的分区方式有四种:
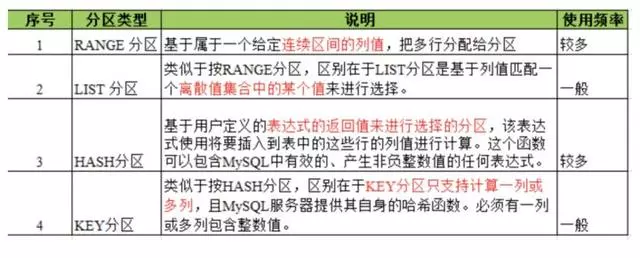
在我们的项目中,range分区和list分区没有使用场景,如果基于绑定编号做range或者list分区,绑定编号没有实际的业务含义,无法通过它进行查询,因此,我们就剩下 HASH 分区和 KEY 分区了,HASH分区仅支持int类型列的分区,且是其中的一列。
KEY 分区倒是可以支持多列,但也要求其中的一列必须是int类型;看我们的库表结构,发现没有哪一列是int类型的,如何做分区呢?增加一列,绑定时间列,将此列设置为int类型,然后按照绑定时间进行分区,将每一天绑定的用户分到同一个区里面去。
这次优化之后,我们的插入快了许多,但是查询依然很慢,为什么?
因为在做查询的时候,我们也只是根据银行卡或者证件号进行查询,并没有根据时间查询,相当于每次查询,mysql都会将所有的分区表查询一遍。
进行第二次方案优化,既然 HASH 分区和 KEY分区要求其中的一列必须是int类型的,那么创造出一个int类型的列出来分区是否可以?
分析发现,银行卡的那串数字有秘密。银行卡一般是16位到19位不等的数字串,我们取其中的某一位拿出来作为表分区是否可行呢,通过分析发现,在这串数字中,其中确实有一位是0到9随机生成的,我们基于银行卡号+随机位进行KEY分区,每次查询的时候,通过计算截取出这位随机位数字,再加上卡号,联合查询,达到了分区查询的目的,需要说明的是,分区后,建立的索引,也必须是分区列,否则Mysql还是会在所有的分区表中查询数据。
通过银行卡号查询绑定关系的问题解决了,那么证件号呢,如何通过证件号来查询绑定关系。
前面已经讲过,做索引一定是要在分区健上进行,否则会引起全表扫描。我们再创建了一张新表,保存客户的证件号绑定关系,每位客户的证件号都是唯一的,新的证件号绑定关系表里,证件号作为了主键,那么如何来计算这个分区健呢,客户的证件信息比较庞杂,有身份证号,港澳台通行证,机动车驾驶证等等,如何在无序的证件号里找到分区健。
为了解决这个问题,我们将证件号绑定关系表一分为二,其中的一张表专用于保存身份证类型的证件号,另一张表则保存其他证件类型的证件号,在身份证类型的证件绑定关系表中,我们将身份证号中的月数拆分出来作为了分区健,将同一个月出生的客户证件号保存在同一个区,这样分成了12个区,其他证件类型的证件号,数据量不超过10万,就没有必要进行分区了。
这样每次查询时,首先通过证件类型确定要去查询哪张表,再计算分区健进行查询。作了分区设计之后,保存2000万用户数据时银行卡表的数据保存文件就分成了10个小文件,证件表的数据保存文件分成了12个小文件,解决了这两个查询的问题,还剩下一个问题:业务编号怎么办?一个客户有多个签约业务,如何进行保存?这时候,采用分区的方案就不太合适了,它需要用到分表的方案。
分表
我们前面有提到过对于mysql,其数据文件是以文件形式存储在磁盘上的。当一个数据文件过大时,操作系统对大文件的操作就会比较麻烦耗时,且有的操作系统就不支持大文件,这个时候就必须分表了。
另外对于mysql常用的存储引擎是Innodb,它的底层数据结构是B+树。当其数据文件过大的时候,查询一个节点可能会查询很多层次,而这必定会导致多次IO操作进行装载进内存,肯定会耗时的。
除此之外还有Innodb对于B+树的锁机制。对每个节点进行加锁,那么当更改表结构的时候,这时候就会树进行加锁,当表文件大的时候,这可以认为是不可实现的。所以综上我们就必须进行分表与分库的操作。
如何进行分库分表,目前互联网上有许多的版本,比较知名的一些方案:阿里的TDDL,DRDS和cobar,京东金融的sharding-jdbc;民间组织的MyCAT;360的Atlas;美团的zebra;其他比如网易,58,京东等公司都有自研的中间件。
这么多的分库分表中间件方案归总起来,就两类:client模式和proxy模式。
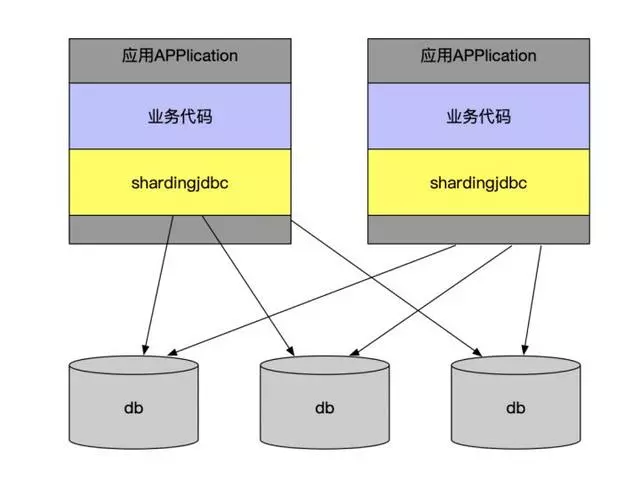
client模式

proxy模式
无论是client模式,还是proxy模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。个人比较倾向于采用client模式,它架构简单,性能损耗也比较小,运维成本低。
如何对业务类型进行分库分表。分库分表最重要的一步,即sharding column的选取,sharding column选择的好坏将直接决定整个分库分表方案最终是否成功。而sharding column的选取跟业务强相关。
在我们的项目场景中,sharding column无疑最好的选择是业务编号。通过业务编号,将客户不同的绑定签约业务保存到不同的表里面去,根据业务编号路由到相应的表中进行查询,达到进一步优化sql的目的。
phper使用MySQL 针对千万级的大表要怎么优化?的更多相关文章
- MySQL 对于千万级的大表要怎么优化?
作者:哈哈链接:https://www.zhihu.com/question/19719997/answer/81930332来源:知乎著作权归作者所有,转载请联系作者获得授权. 第一优化你的sql和 ...
- MySQL 对于千万级的大表要怎么优化
转自知乎 作者:哈哈链接:http://www.zhihu.com/question/19719997/answer/81930332来源:知乎著作权归作者所有,转载请联系作者获得授权. 很多人第一反 ...
- 千万级的大表!MySQL这样优化更好
对于一个千万级的大表,现在可能更多的是亿级数据量,很多人第一反应是各种切分,可结果总是事半功倍,或许正是我们优化顺序的不正确.下面我们来谈谈怎样的优化顺序可以让效果更好. MySQL数据库一般都是按照 ...
- 记录一次MySQL两千万数据的大表优化解决过程,提供三种解决方案(转)
问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡死.严重影响业务 ...
- 转载:记录一次MySQL两千万数据的大表优化解决过程
地址:https://database.51cto.com/art/201902/592522.htm 虽然是广告文,但整体可读性尚可.
- mysql大表设计以及优化
MYSQL千万级数据量的优化方法积累https://m.toutiao.com/group/6583260372269007374/?iid=6583260372269007374 MySQL 千万级 ...
- Mysql千万级记录表分表策略
目前,比较流行的分表为2倍扩容. 表A(id, name, age, sex) 基于自增id分表, 通过触发器先同步A到B, 程序通过mod 2操作数据,然后drop掉触发器,在 删除两个A表的偶数i ...
- Mysql的行级锁与表级锁
在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的满足. 在DBMS中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎).表级锁(MYISAM ...
- Python批量删除mysql中千万级大量数据
场景描述 线上mysql数据库里面有张表保存有每天的统计结果,每天有1千多万条,这是我们意想不到的,统计结果咋有这么多.运维找过来,磁盘占了200G,最后问了运营,可以只保留最近3天的,前面的数据,只 ...
随机推荐
- Debug 利器:pstack & strace
工作中难免会遇到各种各样的 bug,对于开发环境 or 测试环境的问题还好解决,可以使用 gdb 打断点或者在代码中埋点来定位异常; 但是遇到线上的 bug 就很难受了,由于生产环境不能随意替换.中断 ...
- EFK教程(4) - ElasticSearch集群TLS加密通讯
基于TLS实现ElasticSearch集群加密通讯 作者:"发颠的小狼",欢迎转载 目录 ▪ 用途 ▪ ES节点信息 ▪ Step1. 关闭服务 ▪ Step2. 创建CA证书 ...
- 一个有意义的Day类
早晨去单位的路上听到电台里在说“Everyday is a new chance to change your life”,正好最近在学Python类的使用方法,于是我编了一个关于Day的类,以供参考 ...
- IDEA 更改提示一键补全快捷键
偏好设置-->KeyMap-->用关键字搜索可以用下面图中的任意词只要能定位到就是可以的 (Choose Lookup Item Replace)然后增加想用的键,个人喜欢直接加一个空格
- mysql那些事(4)建库建表编码的选择
mysql建数据库或者建表的时候会遇到选择编码的问题,以前我们都是习惯性的选择utf8,但是在mysql在5.5.3版本后加了utf8mb4的编码,utf8mb4可以存4个字节Unicode,mb4就 ...
- Delphi - 调用SuperDll 持续更新
调用SuperDll 接上一篇Delphi创建Superdll,将生成的SuperDll.dll文件复制到本工程路径下,创建如下代码进行Superdll各个接口的测试. 创建uSuperDll.pas ...
- Nacos集群配置实例(windows下测试)
1.首先 fork 一份 nacos 的代码到自己的 github 库,然后把代码 clone 到本地. git地址:https://github.com/alibaba/nacos.git 2.然后 ...
- luogu P1102 A-B 数对 |二分查找
题目描述 出题是一件痛苦的事情! 题目看多了也有审美疲劳,于是我舍弃了大家所熟悉的 A+B Problem,改用 A-B 了哈哈! 好吧,题目是这样的:给出一串数以及一个数字 C,要求计算出所有 A- ...
- 智能家居CC2530功率放大组网RFX2401C和AT2401C的区别
两者最大的区别就是RFX2401C的增益为12dbmAT2401C的增益为14dbm这就会导致AT2401C的功耗会比RFX2401C大一点点,但距离也会相对更远,并且增加了EDS防静电等级,多出2个 ...
- bundle 的生成和使用
一.bundle 的生成 1.打开XCode,创建iOS版用的bundle资源包,有两种方式:第一种直接将工作,open in finder.在目录中直接新建文件夹,文件夹以bundle格式.文件夹 ...