kafka2.3.1+zookeeper3.5.6+kafka-manager2.0.0.2集群部署(centos7.7)
一、准备三台服务器,配置好主机名和ip地址

二、服务器初始化:包括安装常用命令工具,修改系统时区,校对系统时间,关闭selinux,关闭firewalld,修改主机名,修改系统文件描述符,优化内核参数,优化数据盘挂载参数
1、安装常用命令工具
yum install vim net-tools bash-completion wget unzip ntp bzip2 epel-release -y
2、修改系统时区,校对系统时间
timedatectl set-timezone Asia/Shanghai
ntpdate pool.ntp.org
3、关闭selinux
vim /etc/selinux/config
SELINUX=disabled
4、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
5、修改主机名
vim /etc/hostname
kafka-broker1
6、修改系统文件描述符大小
vim /etc/security/limits.conf
最后添加:
* soft nofile 655360
* hard nofile 655360
* soft nproc 655360
* hard nproc 655360
* soft memlock unlimited
* hard memlock unlimited
7.优化内核参数
vim /etc/sysctl.conf
最后添加:
vm.max_map_count = 655360
net.core.rmem_max = 2097152
net.core.wmem_max = 2097152
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_max_syn_backlog = 8192
net.core.netdev_max_backlog = 10000
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
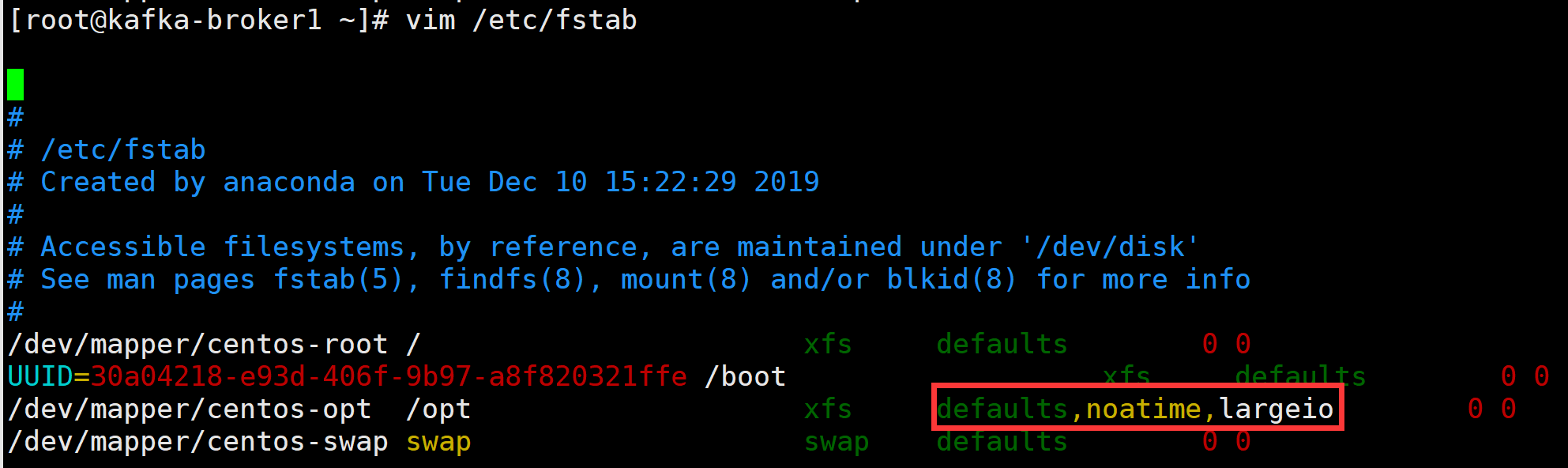
8.优化数据盘挂载参数,我的数据盘挂载在opt下,对应自己数据盘作相应调整
vim /etc/fstab
/dev/mapper/centos-opt /opt xfs defaults,noatime,largeio 0 0
9.重启系统使配置生效
init 6
三、安装zookeeper集群
1.因zookeeper和kafka需要java启动
首先安装jdk1.8环境
yum install java-1.8.0-openjdk-devel.x86_64 -y
2.Kakfa集群需要依赖ZooKeeper存储Broker、Topic等信息,所以我们先安装zookeeper集群
cd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz
mv apache-zookeeper-3.5.6 zookeeper-3.5.6
3.修改zookeeper配置文件
cd zookeeper-3.5.6/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:
dataDir=/opt/zookeeper-3.5.6/data
末尾添加集群其他节点信息
server.1=192.168.0.13:2888:3888
server.2=192.168.0.14:2888:3888
server.3=192.168.0.15:2888:3888
4.添加zookeeper数据目录
创建/opt/zookeeper-3.5.6/data目录
mkdir /opt/zookeeper-3.5.6/data
在data目录里创建myid文件,写上该节点id

然后将opt下zookeeper-3.5.6目录上传到其他两个节点上
scp -r zookeeper-3.5.6 192.168.0.14:/opt
scp -r zookeeper-3.5.6 192.168.0.15:/opt
修改其他两个节点data下myid文件内容分别为2和3
5.启动zookeeper服务
三台节点分别启动zookeeper服务
/opt/zookeeper-3.5.6/bin/zkServer.sh start
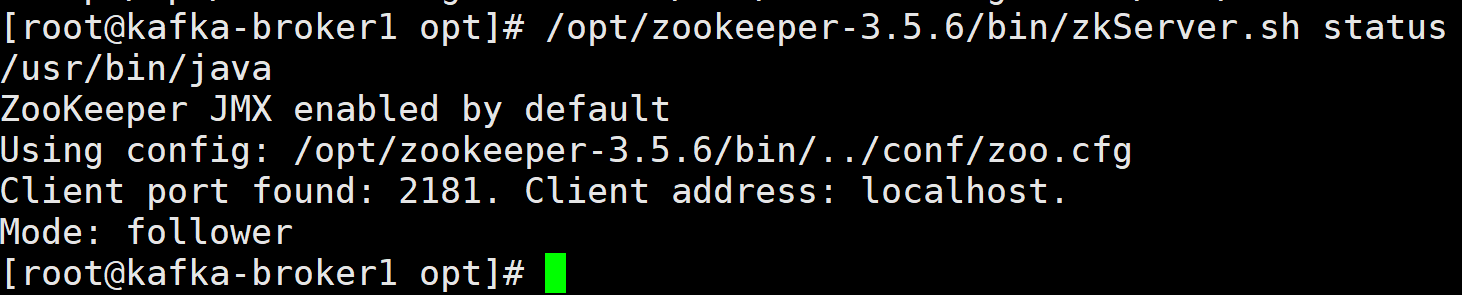
6.查看节点zookeeper状态
/opt/zookeeper-3.5.6/bin/zkServer.sh status
四、安装kafka集群
1.官网下载kafka
cd /opt
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.1/kafka_2.12-2.3.1.tgz
tar -zxvf kafka_2.12-2.3.1.tgz
2.修改kafka配置文件
cd kafka_2.12-2.3.1/config
vim server.properties
修改以下参数
broker.id=1
host.name=192.168.0.13
listeners=PLAINTEXT://192.168.0.13:9092
delete.topic.enable=true
log.cleanup.policy=delete
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
auto.create.topics.enable=true
num.network.threads=24
num.io.threads=48
log.dirs=/opt/kafka_2.12-2.3.1/kafka-logs
num.partitions=3
zookeeper.connect=192.168.0.13:2181,192.168.0.14:2181,192.168.0.15:2181
3.优化调整kafka jvm堆内存大小
vim /opt/kafka_2.12-2.3.1/bin/kafka-server-start.sh
export KAFKA_HEAP_OPTS="-Xmx5G -Xms5G"
4.开启kafka JMX监控
vim /opt/kafka_2.12-2.3.1/bin/kafka-server-start.sh
export JMX_PORT="9999"

4.其他两台节点按照上面步骤同步安装kafka
5.三台节点分别启动kafka
/opt/kafka_2.12-2.3.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.3.1/config/server.properties
五、安装kafka-manager,方便管理kafka
1.下载kafka-manager源码
cd /opt
wget https://github.com/yahoo/kafka-manager/archive/2.0.0.2.zip
mv 2.0.0.2.zip kafka-manager-2.0.0.2.zip
2.解压zip包
unzip kafka-manager-2.0.0.2.zip
cd kafka-manager-2.0.0.2
3.yum安装sbt(因为kafka-manager需要sbt编译)
curl https://bintray.com/sbt/rpm/rpm > /etc/yum.repos.d/bintray-sbt-rpm.repo
yum install sbt -y
4.编译kafka-manager
./sbt clean dist
可能要等好几个小时。
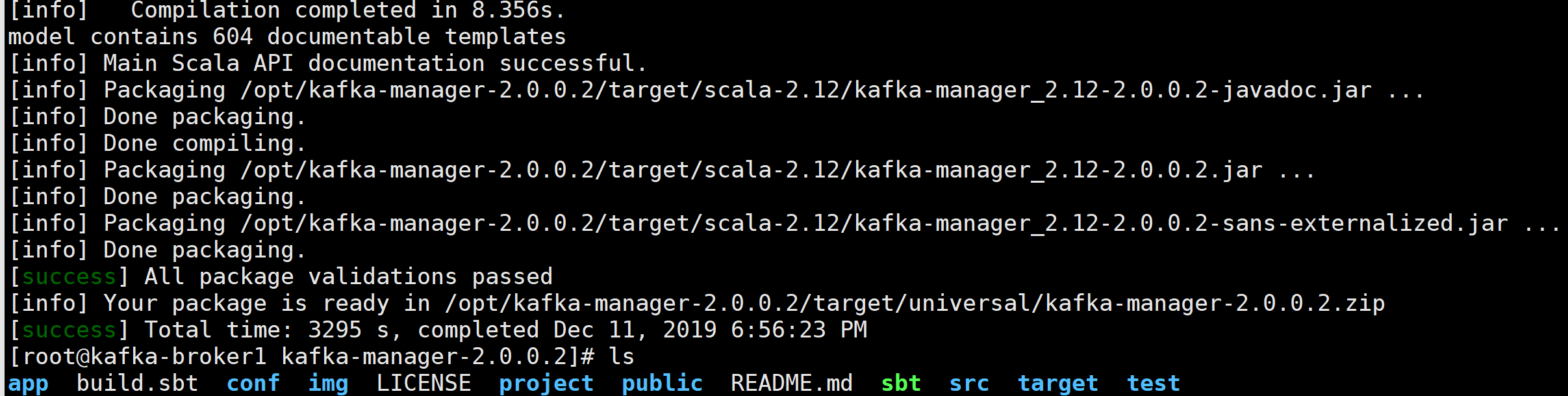
看到Your package is ready in /opt/kafka-manager-2.0.0.2/target/universal/kafka-manager-2.0.0.2.zip代表编译成功了。
5.然后将编译好的zip包拷贝到/opt下,并删除原来kafka-manager-2.0.0.2文件夹
cp /opt/kafka-manager-2.0.0.2/target/universal/kafka-manager-2.0.0.2.zip /opt
rm -rf kafka-manager-2.0.0.2
unzip kafka-manager-2.0.0.2.zip
cd kafka-manager-2.0.0.2
6. 修改kafka-manager配置
vim conf/application.conf
kafka-manager.zkhosts="192.168.0.13:2181,192.168.0.14:2181,192.168.0.15:2181"
7.启动kafka-manager
nohup /opt/kafka-manager-2.0.0.2/bin/kafka-manager &>>/dev/null &
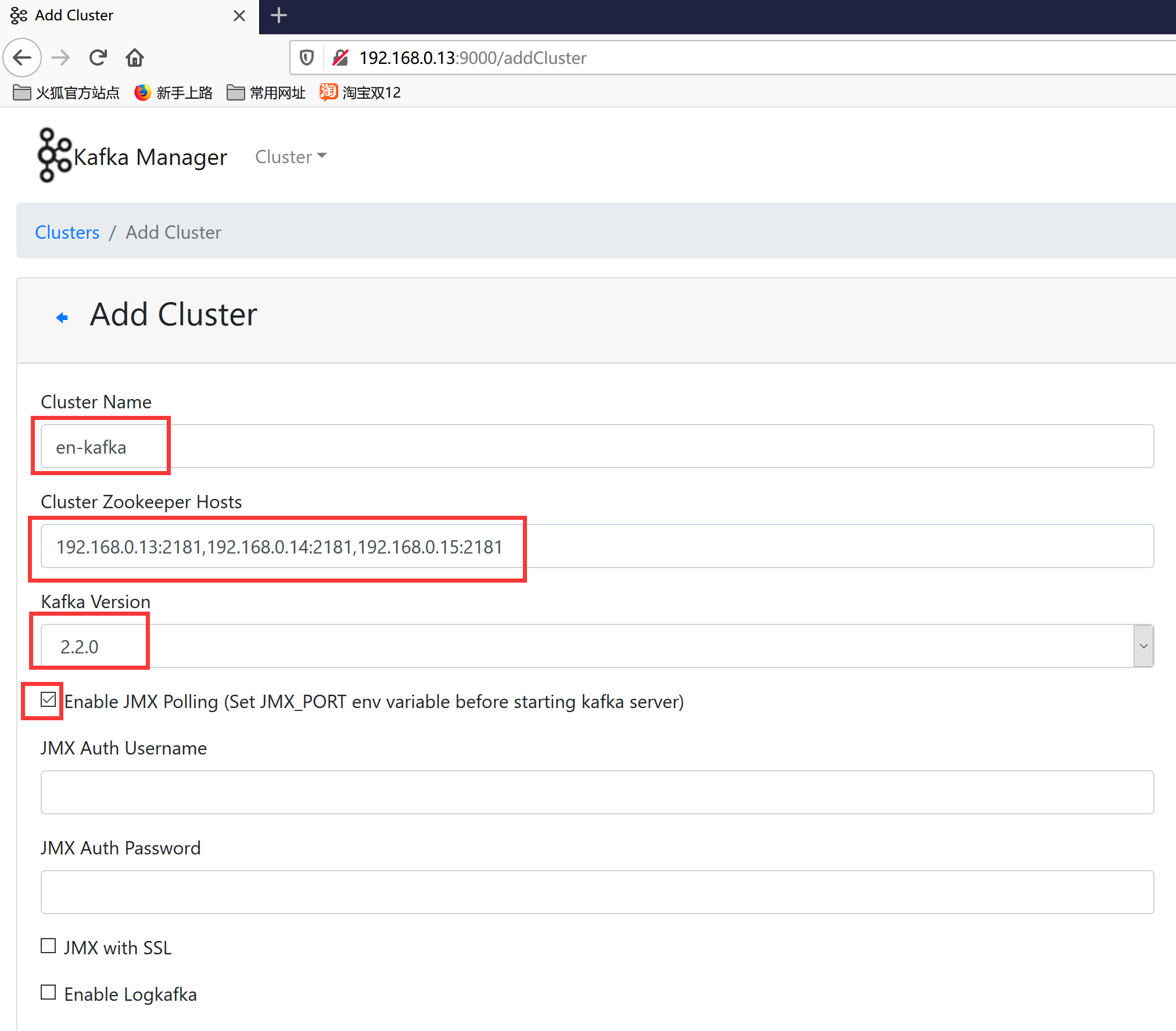
8.用浏览器访问http://192.168.0.13:9000/,添加集群
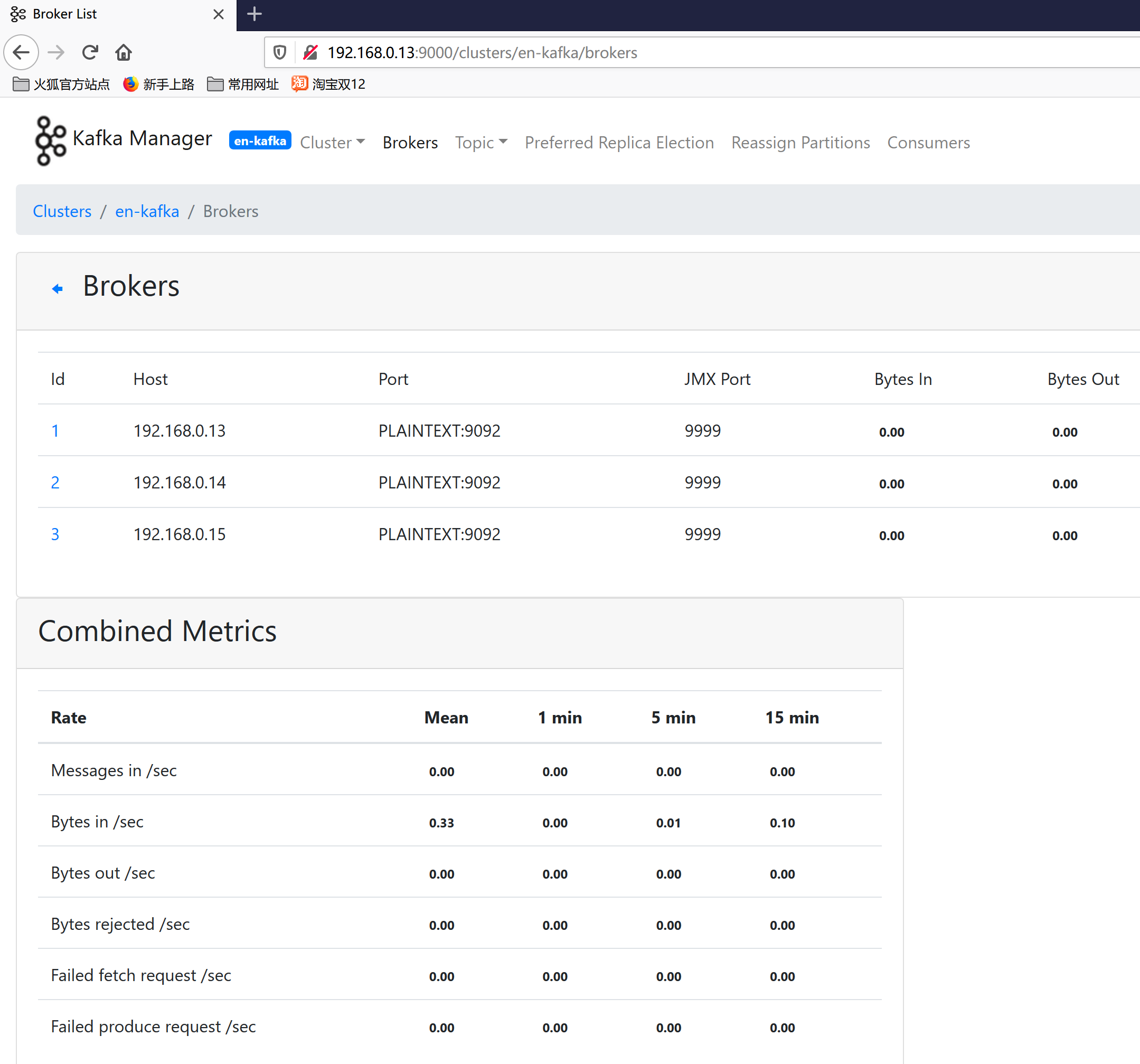
9.添加成功
kafka2.3.1+zookeeper3.5.6+kafka-manager2.0.0.2集群部署(centos7.7)的更多相关文章
- kafka单机版的安装、集群部署 及使用
1.安装kafka(单机版) 1.1上传 kafka_2.11-2.0.0.tgz 到 /root/Downloads 1.2解压 tar 包 tar -zxvf kafka_2.11-2.0.0.t ...
- Kafka server.properties配置,集群部署
server.properties中所有配置参数说明(解释) broker.id =0每一个broker在集群中的唯一表示,要求是正数.当该服务器的IP地址发生改变时,broker.id没有变化,则不 ...
- 消息中间件kafka+zookeeper集群部署、测试与应用
业务系统中,通常会遇到这些场景:A系统向B系统主动推送一个处理请求:A系统向B系统发送一个业务处理请求,因为某些原因(断电.宕机..),B业务系统挂机了,A系统发起的请求处理失败:前端应用并发量过大, ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- kafka 基础知识梳理及集群环境部署记录
一.kafka基础介绍 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特 ...
- Zookeeper+Kafka集群部署
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- kafka集群部署文档(转载)
原文链接:http://www.cnblogs.com/luotianshuai/p/5206662.html Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- ELK5.2+kafka+zookeeper+filebeat集群部署
架构图 考虑到日志系统的可扩展性以及目前的资源(部分功能复用),整个ELK架构如下: 架构解读 : (整个架构从左到右,总共分为5层) 第一层.数据采集层 最左边的是业务服务器集群,上面安装了file ...
- zookeeper集群+kafka集群 部署
zookeeper集群 +kafka 集群部署 1.Zookeeper 概述: Zookeeper 定义 zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目 Zooke ...
随机推荐
- 仿微信 即时聊天工具 - SignalR (一)
话不多说,先上图 背景: 微信聊天,经常会遇见视频发不了,嗯,还有聊天不方便的问题,于是我就自己买了服务器,部署了一套可以直接在微信打开的网页进行聊天,这样只需要发送个url给朋友,就能聊天了! 由于 ...
- DG中模拟failover故障与恢复
问题描述:情形是当主库真正出现异常之后,才会执行的操作,那么我们执行过failover 之后,如何在重新构建DG,这里我们利用flashback database来重构.模拟前主库要开启闪回区,否则要 ...
- java中的基本数据类型转换
Java 中的 8 种基本数据类型,以及它们的占内存的容量大小和表示的范围,如下图所示: 重新温故了下原始数据类型,现在来解释下它们之间的转换关系. 自动类型转换 自动类型转换是指:数字表示范围小的数 ...
- 浅析scrapy与scrapy-redis的区别
首先,要了解两者的区别,就要清楚scrapy-redis是如何产生的,有需求才会有发展,社会在日新月异的飞速发展,大量相似网页框架的飞速产生,人们已经不满足于当前爬取网页的速度,因此有了分布式爬虫,让 ...
- easywechat微信开发SDK之小微商户进件(一)
微信本身不提供小微商户进件的SDK,偶然发现easywechat这么个东西,官网地址是https://www.easywechat.com/ 整合了微信开发中常用的接口,包括微信公众号相关接口,微信 ...
- Spire.Cloud.Word 添加Word水印(文本水印、图片水印)
概述 Spire.Cloud.Word提供了watermarksApi接口可用于添加水印,包括添加文本水印(SetTextWatermark).图片水印(SetImageWatermark),本文将对 ...
- 【Python还能干嘛】爬取微信好友头像完成马赛克拼图(千图成像)~
马赛克拼图 何谓马赛克拼图(千图成像),简单来说就是将若干小图片平凑成为一张大图,如下图路飞一样,如果放大看你会发现里面都是一些海贼王里面的图片. Our Tragets 爬取所有微信好友的头像
- 如何把图片变得炫酷多彩,Python教你这样实现!
有趣的图片 如何能让图片变得好玩?首先需要让它动起来!可如果是多张图片,我们还可以将其拼接起来组成gif动图,可一张图怎么玩?记得之前写过一个小练习,把一张图片拆分成九宫格的分片图.那么,能否由此下手 ...
- 自学python中的心得
以后的日子里我将与可爱的亲们一起度过我自学python的岁月,请博客园里的大佬们监督与见证.
- 过滤器和监听器实现用户的在线登录人数,以及设置session时长。
过滤器: package com.bjsxt.filter; import java.io.IOException; import javax.servlet.Filter; import javax ...