[Python] 数据结构--实现顺序表、链表、栈和队列
说明:
本文主要展示Python实现的几种常用数据结构:顺序表、链表、栈和队列。
附有实现代码。
来源主要参考网络文章。
一、顺序表
1、顺序表的结构
一个顺序表的完整信息包括两部分,一部分是表中元素集合,另一部分是为实现正确操作而需记录的信息,即有关表的整体情况的信息,这部分信息主要包括元素存储区的容量和当前表中已有的元素个数两项。

2、顺序表的两种基本实现方式
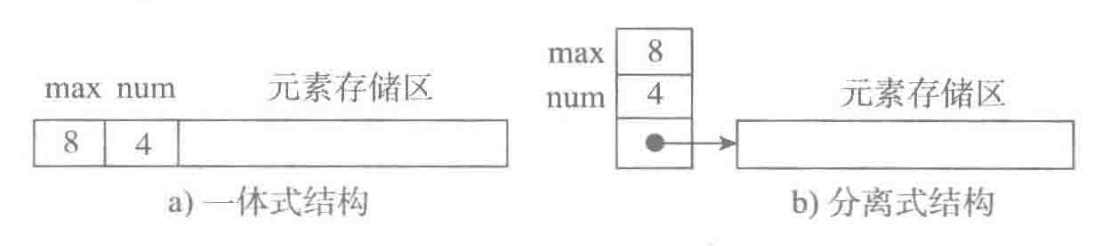
图a 为一体式结构,存储表信息的单元与元素存储区以连续的方式安排在一块存储区里,两部分数据的整体形成一个完整的顺序表对象。一体式结构整体性强,易于管理。但是由于数据元素存储区域是表对象的一部分,顺序表创建后,元素存储区就固定了。
图b 为分离式结构,表对象里只保存与整个表有关的信息(容量和元素个数),实际数据元素存放在另一个独立的元素存储区里,通过链接与基本表对象关联。
3、元素存储区替换
一体式结构由于顺序表信息区与数据区联系存储在一起,所以若想更换数据区,则只能整体搬迁,即整个顺序表对象(指存储顺序表的结构信息的区域)改变了。
分离式结构若想更换数据区,只需将表信息区中的数据区链接地址更新即可,而该顺序表对象不变。
4、元素存储区扩充及其策略
分离式结构的顺序表,如想将数据区更换为存储空间更大的区域,则可以在不改变表对象的前提下对其数据存储区进行了扩充,所有使用这个表的地方都不必修改。只要程序的运行环境(计算机系统)还有空闲存储,这种表结构就不会因为满了而导致操作无法进行。人们把采用这种技术实现的顺序表称为动态顺序表,因为其容量可以在使用中动态变化。
扩充的两种策略:
》每次扩充增加固定数目的存储位置,如每次扩充10个元素位置,这种策略可称为线性增长。
(特点:节省空间,但是扩充操作频繁,操作次数多)
》每次扩充容量加倍,如每次扩充增加一倍存储空间。
(特点:减少了扩充操作的执行次数,但可能会浪费空间资源。以空间换时间,推荐的方式)
》Python的官方实现中,list 实现采用了如下的策略:在建立空表(或很小的表)时,系统分配一块能容纳8个元素的存储区;在执行插入操作(insert或append)时,如果元素存储区满就换一块4倍大的存储区。但如果此时的表已经很大(目前阀值为50000),则改变策略,采用加一倍的方法。引入这种改变策略的方式,是为了避免出现过多的空闲的存储位置。
5、顺序表的操作
增加元素,下图为顺序表增加元素的三种方式:

a、尾端加入元素,时间复杂度为 O(1)
b、非保序的加入元素(不常见)没时间复杂度为 O(1)
c、保序的元素加入,时间复杂度为 O(n)
删除元素,下图为顺序表删除元素的三种方式:
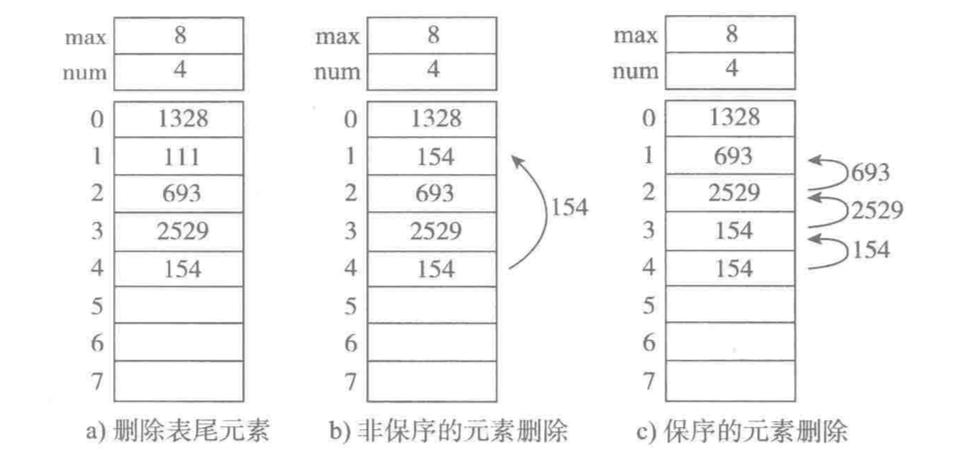
a、删除表尾元素,时间复杂度为 O(1)
b、非保序的元素删除(不常见),时间复杂度为 O(1)
c、保序的元素删除,时间复杂度为 O(n)
6、Python 中的顺序表
Python中的 list 和 tuple 两种类型采用了顺序表的实现技术,具有前面讨论的顺序表的所有性质。
tuple是不可变类型,即不变的顺序表,因此不支持改变其内部状态任何操作,而其他方面,则与list的性质类似。
list的基本实现技术:
Python表中类型list就是一种元素个数可变的线性表,可以加入和删除元素,并在各种操作维持已有元素顺序(即保序),而且还具有以下行为特征:
》基于下标(位置)的高效元素访问和更新,时间复杂度应该是 O(1);
为满足该特征,应该采用顺序表技术,表中元素保存在一块连续的存储区中。
》允许任意加入元素,而且在不断加入元素的过程中,表对象的标识(函数id得到的值)不变
为满足该特征,就必须能更换元素存储区,并且为保证更换存储区时list对象的标识id不变,只能采用分离式实现技术。
在Python官方实现中,list就是一种采用分离式技术实现的动态顺序表。这就是为什么用list.append(x)(或list.insert(len(list), x), 即尾部插入)比在指定位置插入元素效率高的原因。
二、链表
相对于顺序表,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理,因为顺序表的结构需要预先知道数据大小来申请连续的存储空间,而在进行扩充时又需要进行数据的搬迁。
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是不像顺序表一样连续存储数据,而是每一个结点(数据存储单元)里存放下一个结点的信息(即地址):

1、单向链表
单向链表也叫单链表,是表中最简单的一种形式,它的每个节点包含两个域,一个信息域(元素域)和一个链接域。这个链接指向链表中的下一个节点,而最后一个节点的链接域则指向一个空值。
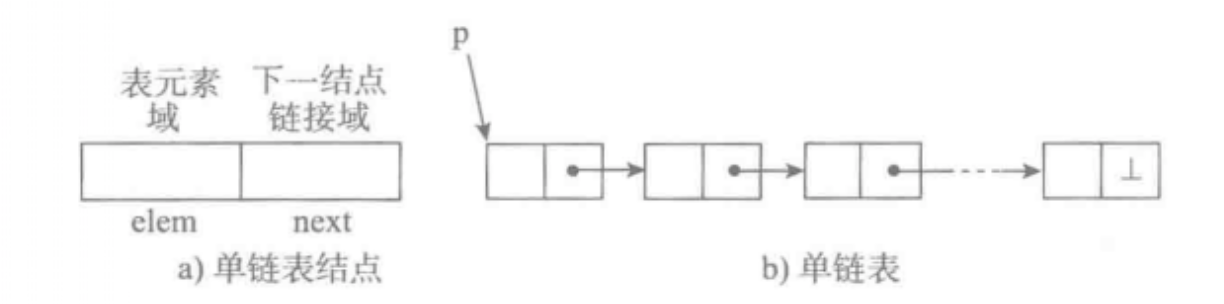
表中元素elem用来存放具体的数据。
链接域next用来存放下一个节点的位置(Python中的标识)。
变量p指向链表的头节点(首节点)的位置,从p出发能找到表中的任意节点。
单链表的操作:
is_empty():链表是否为空
length():链表长度
travel():遍历整个链表
add(item):链表头部添加元素
append(item):链表尾部添加元素
insert(pos, item):指定位置添加元素
remove(item):删除节点
search(item):查找节点是否存在
代码实现:
# coding=utf-8
# 单链表的实现 class SingleNode:
"""单链表的节点"""
def __init__(self, item):
# item存放数据元素
self.item = item
# 下一个节点
self.next = None def __str__(self):
return str(self.item) class SingleLinkList:
"""单链表"""
def __init__(self):
self._head = None def is_empty(self):
"""判断链表是否为空"""
return self._head is None def length(self):
"""获取链表长度"""
cur = self._head
count = 0
while cur is not None:
count += 1
# 将cur后移,指向下一个节点
cur = cur.next
return count def travel(self):
"""遍历链表"""
cur = self._head
while cur is not None:
print(cur.item)
cur = cur.next
print("") def add(self, item):
"""链表头部添加元素"""
node = SingleNode(item) node.next = self._head
self._head = node def append(self, item):
"""链表尾部添加元素"""
node = SingleNode(item) if self.is_empty():
self._head = node
else:
cur = self._head
while cur.next is not None:
cur = cur.next # 此时cur指向链表最后一个节点,即 next = None
cur.next = node def insert(self, pos, item):
"""指定位置添加元素"""
# 若指定位置pos为第一个元素之前,则执行头部插入
if pos <= 0:
self.add(item) # 若指定位置超过链表尾部,则执行尾部插入
elif pos > (self.length() - 1):
self.append(item) # 找到指定位置
else:
node = SingleNode(item)
cur = self._head
cur_pos = 0
while cur.next is not None:
# 获取需要插入位置的上一个节点
if pos - 1 == cur_pos:
node.next = cur.next
cur.next = node
cur = cur.next
cur_pos += 1 def remove(self, item):
"""删除节点"""
cur = self._head
while cur is not None:
if cur.next.item == item:
cur.next = cur.next.next
break
cur = cur.next def search(self, item):
"""查找节点是否存在"""
cur = self._head
count = 0
while cur is not None:
if cur.item == item:
return count
cur = cur.next
count += 1 # 找不到元素
if count == self.length():
count = -1
return count if __name__ == "__main__":
ll = SingleLinkList()
ll.add(1) #
ll.add(2) # 2 1
ll.append(3) # 2 1 3
ll.insert(2, 4) # 2 1 4 3
print("length:", ll.length()) #
ll.travel() # 2 1 4 3
print("search(3):", ll.search(3)) #
print("search(5):", ll.search(5)) # -1
ll.remove(1)
print("length:", ll.length()) #
ll.travel() # 2 4 3
链表与顺序表的对比:
链表失去了顺序表随机读取的优点,同时链表由于增加了节点的指针域,空间开销比较大,但对存储空间的使用要相对灵活。
链表与顺序表的各种操作复杂度如下所示:
| 操作 | 链表 | 顺序表 |
| 访问元素 | O(n) | O(1) |
| 在头部插入/删除 | O(1) | O(n) |
| 在尾部安插入/删除 | O(n) | O(1) |
| 在中间插入/删除 | O(n) | O(n) |
注意:虽然表面看起来复杂度都是 O(n),但是链表和顺序表在插入和删除时进行的是完全不同的操作。链表的主要耗时操作是遍历查找,删除和插入操作本身的复杂度是O(1)。顺序表查找很快,主要耗时的操作是拷贝覆盖。因为除了目标元素在尾部的特殊情况,顺序表进行插入和删除时需要对操作点之后所有元素进行前后移位操作,只能通过拷贝和覆盖方法进行。
2、单向循环链表
单链表的一个变形是单向循环链表,链表中最后一个节点的next域不再为None,而是指向链表的头结点。

基本操作和单链表基本一样,实现代码如下:
# coding=utf-8
# 单向循环链表 class Node:
"""节点"""
def __init__(self, item):
self.item = item
self.next = None def __str__(self):
return str(self.item) class SinCycLinkedList:
"""单向循环链表"""
def __init__(self):
self._head = None def is_empty(self):
"""判断链表是否为空"""
return self._head is None def length(self):
"""链表长度"""
if self.is_empty():
return 0
count = 1
cur = self._head
while cur.next != self._head:
# print("cur", cur.item)
count += 1
cur = cur.next
return count def travel(self):
"""遍历"""
if self.is_empty():
return cur = self._head
print(cur.item)
while cur.next != self._head:
cur = cur.next
print(cur.item) def add(self, item):
"""在头部添加一个节点"""
node = Node(item)
if self.is_empty():
self._head = node
node.next = self._head
else:
node.next = self._head
cur = self._head
while cur.next != self._head:
cur = cur.next cur.next = node
self._head = node def append(self, item):
"""在尾部添加一个节点"""
node = Node(item)
if self.is_empty():
self._head = node
node.next = self._head
else:
cur = self._head
# print(type(cur), cur.item, cur.next)
while cur.next != self._head:
cur = cur.next # print(cur.item)
cur.next = node
node.next = self._head def insert(self, pos, item):
"""指定位置pos添加节点"""
if pos <= 0:
self.add(item)
elif pos > (self.length() - 1):
self.append(item)
else:
node = Node(item)
cur = self._head
cur_pos = 0
while cur.next != self._head:
if (pos - 1) == cur_pos:
node.next = cur.next
cur.next = node
break
cur_pos += 1
cur = cur.next def remove(self, item):
"""删除一个节点"""
if self.is_empty():
return pre = self._head
# 删除首节点
if pre.item == item:
cur = pre
while cur.next != self._head:
cur = cur.next cur.next = pre.next # 删除首节点(跳过该节点)
self._head = pre.next # 重新指定首节点 # 删除其他的节点
else:
cur = pre
while cur.next != self._head:
if cur.next.item == item:
cur.next = cur.next.next
cur = cur.next def search(self, item):
"""查找节点是否存在"""
if self.is_empty():
return -1 cur_pos = 0
cur = self._head
if cur.item == item:
return cur_pos while cur.next != self._head:
if cur.item == item:
return cur_pos
cur_pos += 1
cur = cur.next if cur_pos == self.length() - 1:
return -1 if __name__ == "__main__":
ll = SinCycLinkedList()
ll.add(1) #
ll.add(2) # 2 1
# ll.travel()
ll.append(3) # 2 1 3
ll.insert(2, 4) # 2 1 4 3
ll.insert(4, 5) # 2 1 4 3 5
ll.insert(0, 6) # 6 2 1 4 3 5
print("length:", ll.length()) #
ll.travel() # 6 2 1 4 3 5
print("search(3)", ll.search(3)) #
print("search(7)", ll.search(7)) # -1
print("search(6)", ll.search(6)) #
print("remove(1)")
ll.remove(1)
print("length:", ll.length()) # 6 2 4 3 5
print("remove(6)")
ll.remove(6)
ll.travel()
3、双向链表
一种更复杂的链表是 "双向链表" 或 "双面链表"。每个节点有两个链接:一个指向前一个节点,当次节点为第一个节点时,指向空值;而另一个指向下一个节点,当此节点为最后一个节点时,指向空值。

基本操作和单链表一样,不同的实现,代码如下:
# coding=utf-8
# 双向链表 class Node:
"""节点"""
def __init__(self, item):
self.item = item
self.prev = None
self.next = None class DLinkList:
"""双向链表"""
def __init__(self):
self._head = None def is_empty(self):
"""判断链表是否为空"""
return self._head is None def length(self):
"""获取链表长度"""
if self.is_empty():
return 0
else:
cur = self._head
count = 1
while cur.next is not None:
count += 1
cur = cur.next return count def travel(self):
"""遍历链表"""
print("↓↓" * 10)
if self.is_empty():
print("") else:
cur = self._head
print(cur.item)
while cur.next is not None:
cur = cur.next
print(cur.item)
print("↑↑" * 10) def add(self, item):
"""链表头部添加节点"""
node = Node(item)
if self.is_empty():
self._head = node
else:
cur = self._head node.next = cur
cur.prev = node
self._head = node def append(self, item):
"""链表尾部添加节点"""
node = Node(item)
if self.is_empty():
self._head = node
else:
cur = self._head
# 遍历找到最后一个节点
while cur.next is not None:
cur = cur.next # 在尾节点添加新的节点
cur.next = node
node.prev = cur def insert(self, pos, item):
"""指定位置添加"""
# 头部添加
if pos <= 0:
self.add(item) # 尾部添加
elif pos > (self.length() - 1):
self.append(item) # 其他位置添加
else:
node = Node(item) cur = self._head
cur_pos = 0
while cur.next is not None:
if cur_pos == (pos - 1):
# 与下一个节点互相指向
node.next = cur.next
cur.next.prev = node
# 与上一个节点互相指向
cur.next = node
node.prev = cur
cur_pos += 1
cur = cur.next def remove(self, item):
"""删除节点"""
if self.is_empty():
return
else:
cur = self._head
# 删除首节点
if cur.item == item:
self._head = cur.next
cur.next.prev = None # 删除其他节点
else:
while cur.next is not None:
if cur.item == item:
# 删除之前:1 ←→ [2] ←→ 3
# 删除之后:1 ←→ 3
cur.prev.next = cur.next
cur.next.prev = cur.prev
cur = cur.next # 删除尾节点
if cur.item == item:
cur.prev.next = None def search(self, item):
"""查找节点是否存在"""
if self.is_empty():
return -1
else:
cur = self._head
cur_pos = 0
while cur.next is not None:
if cur.item == item:
return cur_pos cur_pos += 1
cur = cur.next if cur_pos == (self.length() - 1):
return -1 if __name__ == "__main__":
ll = DLinkList()
ll.add(1) #
ll.add(2) # 2 1
ll.append(3) # 2 1 3
ll.insert(2, 4) # 2 1 4 3
ll.insert(4, 5) # 2 1 4 3 5
ll.insert(0, 6) # 6 2 1 4 3 5
print("length:", ll.length()) #
ll.travel() # 6 2 1 4 3 5
print("search(3)", ll.search(3))
print("search(4)", ll.search(4))
print("search(10)", ll.search(10))
ll.remove(1)
print("length:", ll.length())
ll.travel()
print("删除首节点 remove(6):")
ll.remove(6)
ll.travel()
print("删除尾节点 remove(5):")
ll.remove(5)
ll.travel()
三、栈
栈(stack),也称为堆栈,是一种容器,可存入数据元素、访问元素、删除元素,它的特点在于只能允许在容器的一端(称为栈顶端指标:top)进行加入数据(push)和输出数据(pop)的运算。没有了位置概念,保证任何时候可以访问、删除的元素都是此前最后存入的那个元素,确定了一种默认的访问顺序。
由于栈数据结构只允许在一端进行操作,因为按照后进先出(LIFO,Last In First Out)的原理运作。
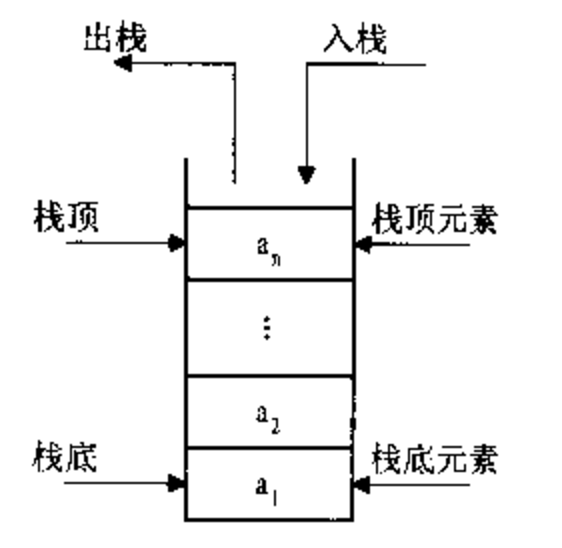
栈可以用顺序表实现,也可以用链表实现。
1、栈的操作:
Stack():创建一个新的空栈
push(item):添加一个新的元素item到栈顶
pop():弹出栈顶元素
peek():返回栈顶元素
is_empty():判断栈是否为空
size():返回栈的元素个数
2、代码实现
# coding=utf-8 class Stack:
"""栈"""
def __init__(self):
self.items = [] def is_empty(self):
"""判断是否为空"""
return self.items == [] def push(self, item):
"""加入元素"""
self.items.append(item) def pop(self):
"""弹出元素"""
return self.items.pop() def peek(self):
"""返回栈顶元素"""
return self.items[len(self.items) - 1] def size(self):
"""返回栈的元素个数"""
return len(self.items) if __name__ == "__main__":
stack = Stack()
stack.push("hello")
stack.push("world")
stack.push("stack")
print(stack.size()) #
print(stack.peek()) # stack
print(stack.pop()) # stack
print(stack.pop()) # world
print(stack.pop()) # hello
四、队列
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出(FIFO,First In First Out)的线性表。允许插入的一端为队尾,允许删除的一端为队头。队列不允许在中间部位进行操作!假设队列 q=(a1, a2, ,..., an),那么a1就是队头元素,而an是队尾元素。这样在删除时,总是从a1开始,而插入时,总是在队列最后。

1、队列的实现(同栈一样,队列也可以用顺序表或者链表实现):
队列的操作:
Queue():创建一个空的队列
enqueue(item):往队列中添加一个item元素
dequeue():从队列头部删除一个元素
is_empty():判断一个队列是否为空
size():返回队列的大小
# coding=utf-8 class Queue:
"""队列"""
def __init__(self):
self.items = [] def is_empty(self):
return self.items == [] def enqueue(self, item):
"""添加元素"""
self.items.insert(0, item) def dequeue(self):
"""从队列头部删除一个元素"""
return self.items.pop() def size(self):
return len(self.items) if __name__ == "__main__":
q = Queue()
q.enqueue("hello")
q.enqueue("world")
q.enqueue("queue")
print(q.size())
print(q.dequeue()) # hello
print(q.dequeue()) # world
print(q.dequeue()) # queue
2、双端队列的实现
双端队列(deque,全名 double-ended queue),是一种具有队列和栈的性质的数据结构。
双端队列中的元素可以从两端弹出,其限定插入和删除操作在表的两端进行。双端队列可以在队列任意一端入队和出队。
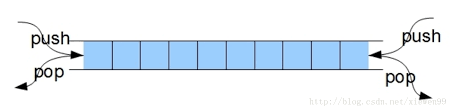
操作:
Deque():创建一个空的双端队列
add_front(item):从队头加入一个item元素
add_rear(item):从队尾加入一个item元素
remove_front():从队头删除一个元素
remove_rear():从队尾删除一个元素
is_empty():判断双端队列是否为空
size():返回队列的大小
# coding=utf-8 class Deque:
"""双端队列"""
def __init__(self):
self.items = [] def add_front(self, item):
"""从队头加入一个元素"""
self.items.insert(0, item) def add_rear(self, item):
"""从队尾加入一个元素"""
self.items.append(item) def remove_front(self):
"""从队头删除一个元素"""
return self.items.pop(0) def remove_rear(self):
"""从队尾删除一个元素"""
return self.items.pop() def is_empty(self):
"""是否为空"""
return self.items == [] def size(self):
"""队列长度"""
return len(self.items) if __name__ == "__main__":
deque = Deque()
deque.add_front(1)
deque.add_front(2)
deque.add_rear(3)
deque.add_rear(4)
print(deque.size()) #
print(deque.remove_front()) #
print(deque.remove_front()) #
print(deque.remove_rear()) #
print(deque.remove_rear()) #
[Python] 数据结构--实现顺序表、链表、栈和队列的更多相关文章
- python数据结构与算法第六天【栈与队列】
1.栈和队列的原理 栈:后进先出(LIFO),可以使用顺序表和链表实现 队列:先进先出(FIFO),可以使用顺序表和链表实现 2.栈的实现(使用顺序表实现) #!/usr/bin/env python ...
- 《数据结构与算法分析:C语言描述_原书第二版》CH3表、栈和队列_reading notes
表.栈和队列是最简单和最基本的三种数据结构.基本上,每一个有意义的程序都将明晰地至少使用一种这样的数据结构,比如栈在程序中总是要间接地用到,不管你在程序中是否做了声明. 本章学习重点: 理解抽象数据类 ...
- hrbustoj 1545:基础数据结构——顺序表(2)(数据结构,顺序表的实现及基本操作,入门题)
基础数据结构——顺序表(2) Time Limit: 1000 MS Memory Limit: 10240 K Total Submit: 355(143 users) Total Accep ...
- python 使用顺序表实现栈和队列
栈: # -*- coding: utf-8 -*- # @author: Tele # @Time : 2019/04/24 下午 2:33 # 采用list(顺序表)实现栈结构,后入先出 clas ...
- C# 数据结构 线性表(顺序表 链表 IList 数组)
线性表 线性表是最简单.最基本.最常用的数据结构.数据元素 1 对 1的关系,这种关系是位置关系. 特点 (1)第一个元素和最后一个元素前后是没有数据元素,线性表中剩下的元素是近邻的,前后都有元素. ...
- 数据结构:顺序表(python版)
顺序表python版的实现(部分功能未实现) #!/usr/bin/env python # -*- coding:utf-8 -*- class SeqList(object): def __ini ...
- 学生信息管理系统-顺序表&&链表(数据结构第一次作业)
实验目的 : 1 .掌握线性表的定义: 2 .掌握线性表的基本操作,如建立.查找.插入和删除等. 实验内容: 定义一个包含学生信息(学号,姓名,成绩)的的 顺序表和链表,使其具有如下功能: (1) 根 ...
- 【数据结构 Python & C++】顺序表
用C++ 和 Python实现顺序表的简单操作 C++代码 // Date:2019.7.31 // Author:Yushow Jue #include<iostream> using ...
- 数据结构代码整理(线性表,栈,队列,串,二叉树,图的建立和遍历stl,最小生成树prim算法)。。持续更新中。。。
//归并排序递归方法实现 #include <iostream> #include <cstdio> using namespace std; #define maxn 100 ...
随机推荐
- sklearn学习 第一篇:knn分类
K临近分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,然后根据模型对新的数据点进行预测,预测新数据点的标签(label),也就是该数据所属的分类. 一,kNN算法的逻辑 kNN算法的核 ...
- Web Worker 多线程
Web Workers多线程 1 浏览器把所有事件都通过操作系统安排到事件队列中(例如:你去一个·窗口买菜,需要排队):浏览器使用单线程处理队列中的事件和执行用户代码(也就是单线程:web work ...
- H3C模拟器单臂路由配置实例
单臂路由:用802.1Q和子接口实现VLAN间路由 单臂路由利用trunk链路允许多个VLAN的数据帧通过而实现 网络拓扑图: RTA配置: SW1配置: PC1/2配置如图: 但是值得注意的是,在配 ...
- 在 dotnet core (C#)下的颜色渐变
直接使用等比例抽样算法,连同透明度一起计算. public IList<Color> ShadeColors(Color c1, Color c2, int resultCount) { ...
- java8-流的操作
流的操作 流的使用一般包括三件事: 一个数据源来执行一个查询; 一个中间操作链,形成一条流的流水线; 一个终端操作,执行流水线,并能生成结果 中间操作 操作 类型 返回类型 操作参数 函数描述符 fi ...
- 限流降级神器,带你解读阿里巴巴开源 Sentinel 实现原理
Sentinel 是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制.熔断降级.系统负载保护等多个维度来帮助用户保护服务的稳定性. 大家可能会问:Se ...
- 【Java笔记】【Java核心技术卷1】chapter3 D1JavaStandard
package chapter3;/*有包名,命令行编译javac -d . 名字.java(注意空格)运行时用java chapter3.JavaStandard*/ public/*访问修饰符*/ ...
- 几大排序算法的Java实现(原创)
几大排序算法的Java实现 更新中... 注: 该类中附有随机生成[min, max)范围不重复整数的方法,如果各位看官对此方法有什么更好的建议,欢迎提出交流. 各个算法的思路都写在该类的注释中了,同 ...
- Mybatis学习笔记之---环境搭建与入门
Mybatis环境搭建与入门 (一)环境搭建 (1)第一步:创建maven工程并导入jar包 <dependencies> <dependency> <groupId&g ...
- Vue小事例
login <!DOCTYPE html><html lang="ZH-cn"> <head> <meta charset="U ...