Hive学习笔记(一)——概述
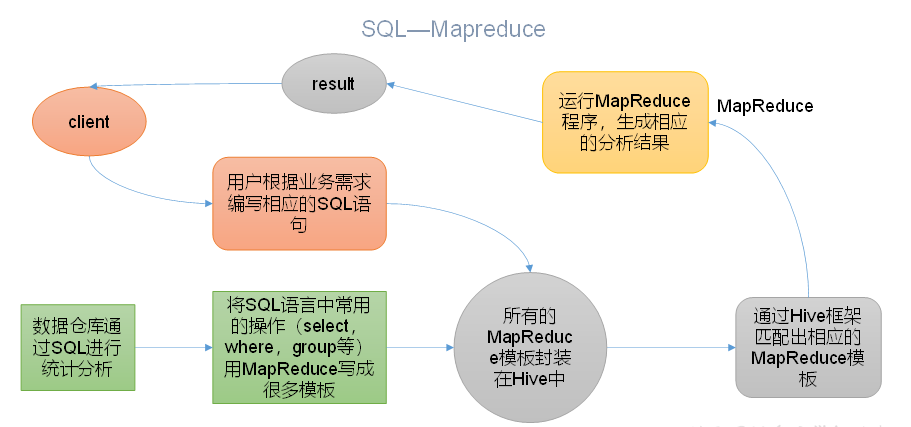
1.Hive是个什么玩意?
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据(有规律的数据)文件映射为一张表,并提供类SQL查询功能。
一句话暴力总结:通过写SQL语句的方式,代替原来的写MapReduce程序。
下边几点还需要留意一下:
Hive处理的数据存储在HDFS ;
Hive分析数据底层的实现是MapReduce ;
执行程序运行在Yarn上 ;
这就相当于Hive是Hadoop的客户端,不是分布式的
2. Hive的优缺点 (选看)
2.1 优点:
1)操作接口采用类SQL的语法,比较好上手,不用写代码;
2)避免写MapReduce程序代码,减少了开发人员的学习成本,也提高了开发效率嘛;
3)适用于数据分析,对实时性要求不高的场合,因为默认的实现是MapReduce;
4)Hive主要的优势在于处理大数据,对处理小数据没有优势,因为Hive的执行延迟比较高;
5)Hive支持用户自定函数,开发人员可以根据需求自定义函数。
2.2 缺点:
1)Hive的HQL表达能力有限:
(1)迭代式算法无法表达;
(2)数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
2)Hive的效率比较低:
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化;
(2)Hive调优比较困难,粒度较粗。
3. Hive的架构原理
Hive主要架构及协同工作的架构组件如下图:
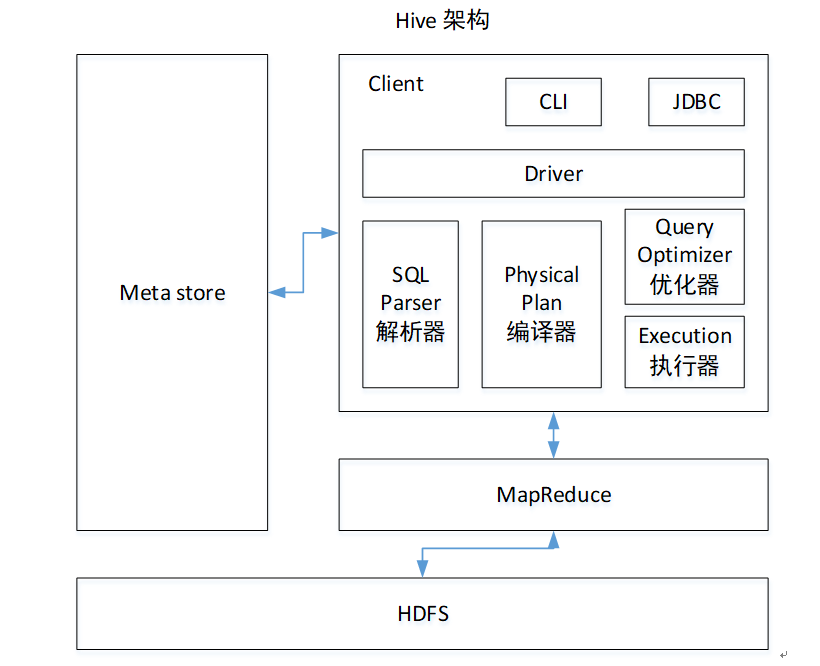
了解一下各个组件:
1)用户接口:Client,不属于hive的内部数据
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default库)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
例如:HDFS上有一个文件,有四个列,我们用Hive建了一个四个列的表与之相映射,这个映射关系就是元数据Metastore
元数据默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore(Hive要去HDFS上读数据,它怎么知道数据的位置呢?它要先访问Mysql里的元数据,根据元数据拼接处文件路径)。
3)Hadoop
Hive处理的数据存储在HDFS上,使用的是MapReduce进行计算。
4)驱动器:Driver
(1)解析器:将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误;
(2)编译器:将AST编译生成逻辑执行计划;【即翻译器:将HQL翻译成MapReduce】
(3)优化器:对逻辑执行计划进行优化;
(4)执行器:把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
小总结:Hive通过给用户提供的一系列交互接口,接收到用户的指令(HQL),使用自己的Driver,结合元数据(包括数据的存储路径和数据与表的映射关系),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
4. Hive和数据库比较
Hive 是为数据仓库而设计的 ,Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。比较一下两者吧:
- 查询语言:专门针对Hive的特性设计了类SQL的查询语言HQL ;
- 存储的位置:Hive是建立在Hadoop之上的,所以Hive的数据都存储在HDFS上。数据库的文件则存储在块设备上或者本地文件系统中;
- 数据更新:Hive是针对数据仓库设计的,数据仓库里的内容读多写少,Hive中不建议对数据改写,所有的数据都是在加载的时候确定好的。数据库中的内容则是需要频繁的读写;
- 执行:Hive的执行借助于Hadoop提供的MapReduce实现,数据库则是有自己的执行引擎;
- 执行延迟:Hive由于没有索引,需要扫描全表,因此延迟比较高;另一个导致延迟高的原因是MapReduce框架本身就有较高的执行延迟。相比较而言,数据库的执行延迟比较低,当然低是有条件的:即处理数据量小的时候比较低。当规模达到一定程度的时候,Hive的并行计算的优势就能体现出来了。
- 可扩展性:由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库在理论上的扩展能力也只有100台左右。
- 数据规模:由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive学习笔记(一)——概述的更多相关文章
- hive学习笔记之一:基本数据类型
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之三:内部表和外部表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之四:分区表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之五:分桶
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之六:HiveQL基础
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之七:内置函数
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之九:基础UDF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之十:用户自定义聚合函数(UDAF)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<hive学习笔记>的第十 ...
- hive学习笔记之十一:UDTF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Struts2 学习笔记(概述)
Struts2 学习笔记 2015年3月7日11:02:55 MVC思想 Strust2的MVC对应关系如下: 在MVC三个模块当中,struts2对应关系如下: Model: 负责封装应用的状态,并 ...
随机推荐
- [2019BUAA软件工程]个人期末总结感想
写在前面 经过一学期对于软件工程的学习,笔者完成了一次结对编程以及三个周期的敏捷开发流程.在本博客中笔者对于一学期的学习进行了总结,并对于自己最初的疑惑做出了回答. 笔者在学期开始前应课程要求 ...
- Spring Cloud Zuul 概览
什么是API网关 网关这个词其实是一个硬件概念.因为按照定义,网络网关出现在网络的边缘,所以防火墙和代理服务器等相关功能 往往与之集成在一起.在家庭网络 和小型企业中,宽带路由器通常充当网络网关.它将 ...
- python 文字转语音
# coding=utf-8 import pyttsx3 text='I love you 韩长菊' voice=pyttsx3.init() voice.say(text) voice.runAn ...
- 简述 IntentFilter(意图过滤器)
1.什么是IntentFilter ? IntentFilter翻译成中文就是“意图过滤器”,主要用来过滤隐式意图.当用户进行一项操作的时候,Android系统会根据配置的 “意图过滤器” 来寻找可以 ...
- [原]JSON 字符串(值)做判断,比较 “string ”
现在我这样一个json字符串: char* cjson = "{\"code\": \"200\", \"code2\": 200 ...
- python开源项目聚合推荐【1】
******************************************************* 01项目名:unimatrix 功能介绍:Python模拟“黑客帝国”影片中的终端动画脚 ...
- 理解 uptime 的:“平均负载”? 如何模拟测试
每次发现系统变慢时,我们通常做的第一件事,就是执行 top 或者 uptime 命令,来了解系统的负载情况.比如像下面这样,我在命令行里输入了 uptime 命令,系统也随即给出了结果. [root@ ...
- Starting Jenkins bash: /usr/bin/java: 没有那个文件或目录
[root@localhost /]# systemctl status jenkins.service ● jenkins.service - LSB: Jenkins Automation Ser ...
- Jmeter+nfluxDB+Grafana性能监控平台
下载地址: nfluxDB下载地址:https://portal.influxdata.com/downloads/ Grafana下载地址:https://grafana.com/grafana/d ...
- C# HashSet集合类型使用介绍
1.HashSet集合 使用HashSet可以提高集合的运算.使用HashSet集合不自带排序方法,如果需要排序的需求可以参考使用List<T>集合配合Sort方法. HashSet的优势 ...