5.3 RDD编程---数据读写
一、文件数据读写
1.本地文件系统的数据读写
可以采用多种方式创建Pair RDD,其中一种主要方式是使用map()函数来实现
惰性机制,即使输入了错误的语句spark-shell也不会马上报错。
(1)读
给出路径名称,TextFile会把路径下面的所有文件都读进来,生成一个RDD
(2)写

当只有一个分区时,单线程才会出现part-0000
如果分了两个分区,写完之后会生成part-0000和part-0001
2.分布式文件系统HDFS的数据读写
(1)读
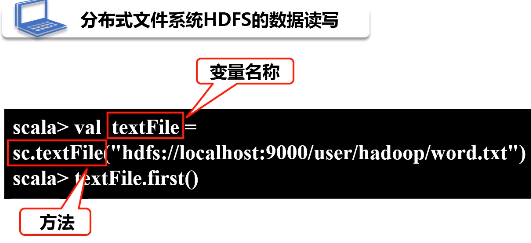

(2)写

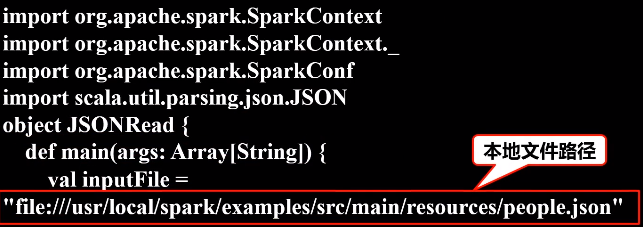
3.JSON文件的数据读写
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式
(1)读

Scala中有一个自带的JSON库——scala.util.parsing.json.JSON,可以实现对JSON数据的解析
JSON.parseFull(jsonString:String)函数,以一个JSON字符串作为输入并进行解析,如果解析成功则返回一个Some(map: Map[String, Any]),如果解析失败则返回None。

将整个应用程序打包成 JAR包,通过 spark-submit 运行程序

执行后可以在屏幕上的大量输出信息中找到如下结果:
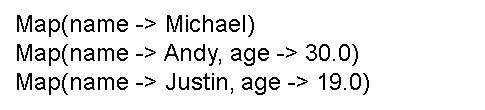
二、读写HBase数据
1.HBase简介
HBase是Google BigTable的开源实现


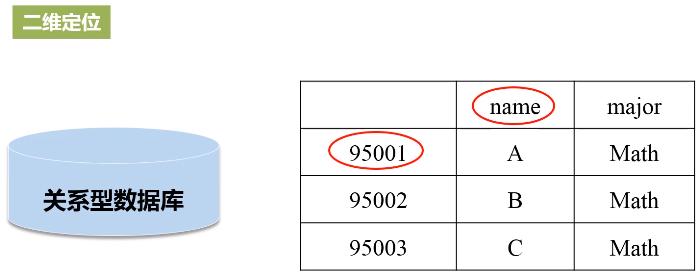
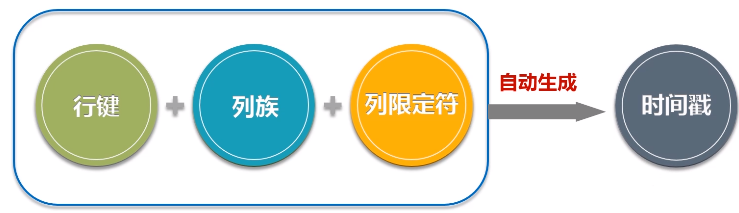
- HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳;
- 每个值是一个未经解释的字符串,没有数据类型;
- 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列;
- 表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起;
- 列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换;
- HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的)
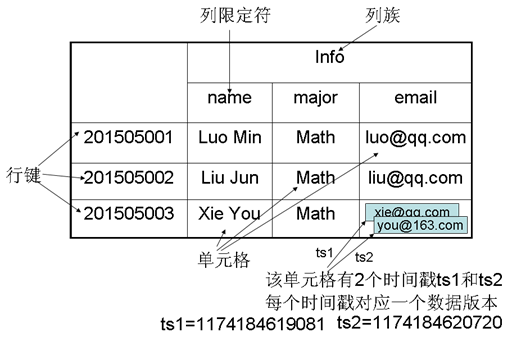
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
- 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元
- 列限定符:列族里的数据通过列限定符(或列)来定位
- 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
- 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引

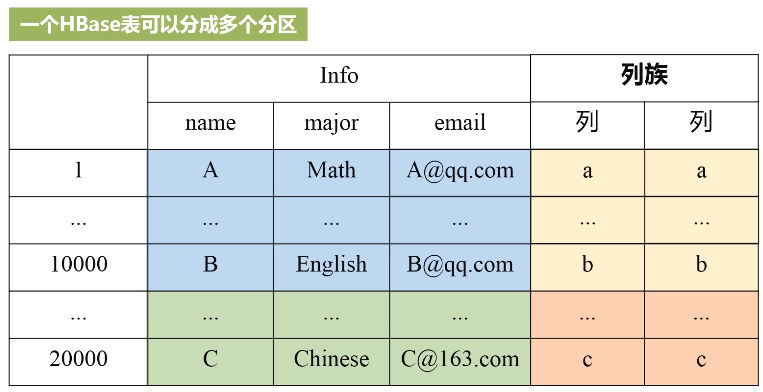
先切水平(学号1-10000,10001-20000,...),再切竖直(按列族分),每一种颜色得到小方格内都是一个分区,一个分区就是属于负载分发的基本单位,这样就可以实现分布式存储。有个元数据表可以存储每个分区对应的位置。
2.创建一个HBase表
第一步:安装配置HBase,将HBase安装成伪分布式
第二步:启动Hadoop和HBase

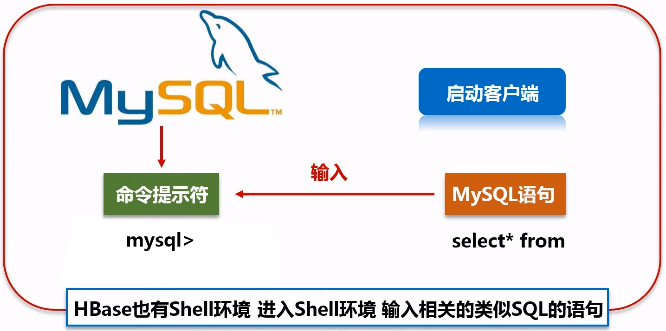
HBase也有shell环境,可以输入类似SQL的语句




3.配置Spark
把HBase的lib目录下的一些jar文件拷贝到Spark中,这些都是编程时需要引入的jar包,需要拷贝的jar文件包括:所有hbase开头的jar文件、guava-12.0.1.jar、htrace-core-3.1.0-incubating.jar和protobuf-java-2.5.0.jar

4.编写程序读取HBase数据
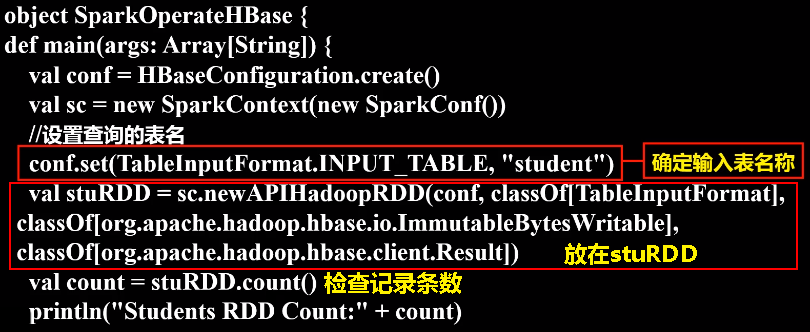
如果要让Spark读取HBase,就需要使用SparkContext提供的newAPIHadoopRDD这个API将表的内容以RDD的形式加载到Spark中。

- import org.apache.hadoop.conf.Configuration
- import org.apache.hadoop.hbase._
- import org.apache.hadoop.hbase.client._
- import org.apache.hadoop.hbase.mapreduce.TableInputFormat
- import org.apache.hadoop.hbase.util.Bytes
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
- // 在SparkOperateHBase.scala文件中输入以下代码:
- object SparkOperateHBase {
- def main(args: Array[String]) {
- val conf = HBaseConfiguration.create()
- val sc = new SparkContext(new SparkConf())
- //设置查询的表名
- conf.set(TableInputFormat.INPUT_TABLE, "student")
- val stuRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
- classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
- classOf[org.apache.hadoop.hbase.client.Result])
- val count = stuRDD.count()
- println("Students RDD Count:" + count)
- stuRDD.cache()
- //遍历输出
- stuRDD.foreach({ case (_,result) =>
- val key = Bytes.toString(result.getRow)
- val name = Bytes.toString(result.getValue("info".getBytes,"name".getBytes))
- val gender = Bytes.toString(result.getValue("info".getBytes,"gender".getBytes))
- val age = Bytes.toString(result.getValue("info".getBytes,"age".getBytes))
- println("Row key:"+key+" Name:"+name+" Gender:"+gender+" Age:"+age)
- })
- }
- }



5.编写程序向HBase写入数据
下面编写应用程序把表中的两个学生信息插入到HBase的student表中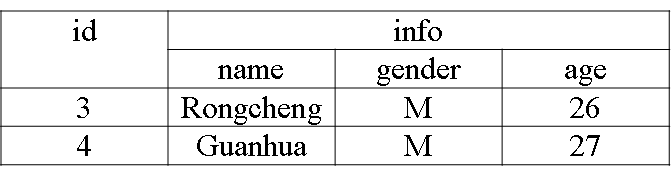
在SparkWriteHBase.scala文件中输入下面代码:
- import org.apache.hadoop.hbase.HBaseConfiguration
- import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
- import org.apache.spark._
- import org.apache.hadoop.mapreduce.Job
- import org.apache.hadoop.hbase.io.ImmutableBytesWritable
- import org.apache.hadoop.hbase.client.Result
- import org.apache.hadoop.hbase.client.Put
- import org.apache.hadoop.hbase.util.Bytes
- object SparkWriteHBase {
- def main(args: Array[String]): Unit = {
- val sparkConf = new SparkConf().setAppName("SparkWriteHBase").setMaster("local")
- val sc = new SparkContext(sparkConf)
- val tablename = "student"
- sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, tablename)
- val job = new Job(sc.hadoopConfiguration)
- job.setOutputKeyClass(classOf[ImmutableBytesWritable])
- job.setOutputValueClass(classOf[Result])
- job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
- val indataRDD = sc.makeRDD(Array("3,Rongcheng,M,26","4,Guanhua,M,27")) //构建两行记录
- val rdd = indataRDD.map(_.split(',')).map{arr=>{
- val put = new Put(Bytes.toBytes(arr(0))) //行健的值
- put.add(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(arr(1))) //info:name列的值
- put.add(Bytes.toBytes("info"),Bytes.toBytes("gender"),Bytes.toBytes(arr(2))) //info:gender列的值
- put.add(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(arr(3).toInt)) //info:age列的值
- (new ImmutableBytesWritable, put)
- }}
- rdd.saveAsNewAPIHadoopDataset(job.getConfiguration())
- }
- }


切换到HBase Shell中,执行如下命令查看student表


5.3 RDD编程---数据读写的更多相关文章
- Spark RDD编程-大数据课设
目录 一.实验目的 二.实验平台 三.实验内容.要求 1.pyspark交互式编程 2.编写独立应用程序实现数据去重 3.编写独立应用程序实现求平均值问题 四.实验过程 (一)pyspark交互式编程 ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- Python之IO编程——文件读写、StringIO/BytesIO、操作文件和目录、序列化
IO编程 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口.从 ...
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- JavaScript高级编程———数据存储(cookie、WebStorage)
JavaScript高级编程———数据存储(cookie.WebStorage) <script> /*Cookie 读写删 CookieUtil.get()方法根据cookie的名称获取 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- 5.1 RDD编程
一.RDD编程基础 1.创建 spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是: 本地文件系统的地址 分布式文件系统HDFS的地址 ...
随机推荐
- 修改Tooltip 文字提示 的背景色 箭头颜色
3==>vue 鼠标右击<div @contextmenu.prevent="mouseRightClick">prevent是阻止鼠标的默认事件 4==> ...
- 使用DRF来快速实现API调用服务
本帖最后由 范志远 于 2019-3-19 16:55 编辑 增加加载Djagno REST Framework模块的选项 对于settings.py文件的INSTALLED_APPS增加'rest_ ...
- Host '10.133.3.34' is not allowed to connect to this MySQL server mysql 本地拒接连接
mysql 本地拒接连接 解决方案是,把mysql库中的user表的host 改成% 运行所电脑连接 也可以把第一行复制一遍 把localhost改成你要连接电脑的ip(推荐这改,这样安全一点) 改 ...
- 用java写爬虫
今天学了怎么用java代码获取要爬取页面的源代码,因为只写了一点,所以接下来会陆续跟新此文章 首先,看一下我写的代码 这就是爬取下来的网页源代码,第一张图刚刚补注释有个注释写错了,别误导你们就行,接下 ...
- NOIP模拟赛 最佳组合
题目描述 Description \(Bzeroth\) 大陆最终还是覆灭了,所以你需要为地灾军团服务了. 地灾军团军师黑袍不擅长写题面,所以你只需要看简化版的题意即可. 给定 \(3\) 个长度均为 ...
- Oracle数据库的关键系统服务整理
在Windows 操作系统下安装Oracle 9i时会安装很多服务——并且其中一些配置为在Windows 启动时启动.在Oracle 运行在Windows 下时,有些服务可能我们并不总是需要但又害怕停 ...
- 【解决错误】Non-reversible reg-exp portion: '(?i'
在将Django升级到2.1后,运行 Django 自带后台后,或 使用 redirect 方法,就一直报错:Non-reversible reg-exp portion: '(?i'. 错误一 Dj ...
- JAVA 统计字符串中中文,英文,数字,空格,特殊字符的个数
引言 可以根据各种字符在Unicode字符编码表中的区间来进行判断,如数字为'0'~'9'之间,英文字母为'a'~'z'或'A'~'Z'等,Java判断一个字符串是否有中文是利用Unicode编码来判 ...
- python yield from (一)
1. yield from 会抛出iterator中所有的值:而yield只是抛出传进来的值,如果是值,就抛出值,如果是iterator对象,抛出iterator对象 def g1(iterable) ...
- Javascript 实现倒计时效果
代码来自于网上. <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://ww ...