MapReduce面试题
什么是mapreduce
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。容错高,扩展好,适合pB数据处理
MapReduce 执行过程分析
第一阶段map
.map task读取HDFS文件。每个block,启动一个map task。每个map task按照行读取一个block中的内容,对每一行执行map函数
.map函数对输入的数据进行拆分split,得到一个数组,组成一个键值对<word, >
.分区,每个分区对应1个reduce task
.对每个分区中的数据,按照key进行分组并排序
.在map段执行小reduce,输出<key,times> 第二阶段reduce
.每个分区对应一个reduce task,这个reduce task会读取相同分区的map输出;reduce task对接收到的所有map输出,进行排序分组<hello,{,}><me,{}><you,{}>
.执行reduce 操作,对一个分组中的value进行累加<hello,><me,><you,>
.每个分区输出到一个HDFS文件中
Mapreduce数据倾斜原因和解决方案
原因:
简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少的局面。
情形:group by 维度过小,某值的数量过多
后果:处理某值的reduce非常耗时
去重 distinct count(distinct xx)
情形:某特殊值过多
后果:处理此特殊值的reduce耗时
连接 join
情形1:其中一个表较小,但是key集中
后果1:分发到某一个或几个Reduce上的数据远高于平均值
情形2:大表与大表,但是分桶的判断字段0值或空值过多
后果2:这些空值都由一个reduce处理,非常慢
解决:
调优参数
set hive.map.aggr=true:在map中会做部分聚集操作,效率更高但需要更多的内存。
set hive.groupby.skewindata=true:数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。 、在 key 上面做文章,在 map 阶段将造成倾斜的key 先分成多组,例如 aaa 这个 key,map 时随机在 aaa 后面加上 ,,, 这四个数字之一,把 key 先分成四组,先进行一次运算,之后再恢复 key 进行最终运算。
、能先进行 group 操作的时候先进行 group 操作,把 key 先进行一次 reduce,之后再进行 count 或者 distinct count 操作。
、join 操作中,使用 map join 在 map 端就先进行 join ,免得到reduce 时卡住。
Java的序列化和hadoop序列化机制(Writable)
.紧凑
紧凑的格式能让我们充分利用网络带宽,而带宽是数据中心最稀缺的资源
.快速
进程通信形成了分布式系统的骨架,所以需要尽量减少序列化和反序列化的性能开销,这是基本的;
.可扩展
协议为了满足新的需求变化,所以控制客户端和服务器过程中,需要直接引进相应的协议,这些是新协议,原序列化方式能支持新的协议报文;
.互操作
能支持不同语言写的客户端和服务端进行交互;
Mapreduce的动态执行流程
MRAppMaster向RM申请2个container;
RM分配2个container,
NM启动该container,把container的地址返回给master。
container中开始运行map task或者reduce task。
在运行过程中,master与map task、reduce task保持心跳通讯,监测task的执行情况。
当map task和reduce task运行结束时,回收container。
当job运行结束时,master告诉RM,可以把自己回收了。
RM就让NM杀死master所在的container。
整个job运行完毕
切片机制
一个split的大小是由goalSize, minSize, blockSize这三个值决定的。
computeSplitSize的逻辑是,先从goalSize和blockSize两个值中选出最小的那个(比如一般不设置map数,这时blockSize为当前文件的块size,而goalSize是文件大小除以用户设置的map数得到的,如果没设置的话,默认是1)。
CombineTextInputFormat案例实操
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, );// 4m
CombineTextInputFormat.setMinInputSplitSize(job, );// 2m
suffer机制
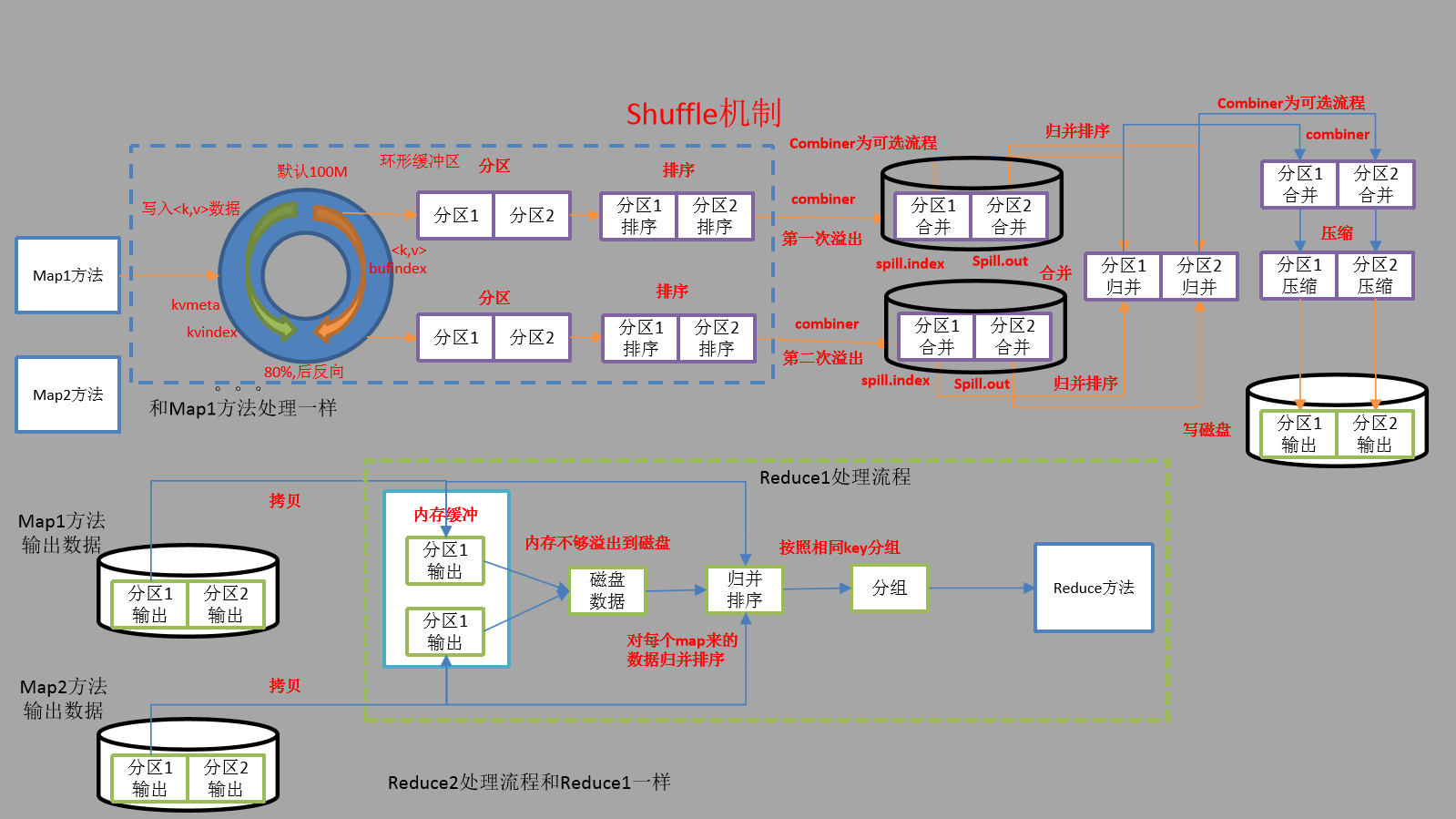
WritableComparable排序
bean对象实现WritableComparable接口重写compareTo方法,就可以实现排序
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? - : ;
if(this.sumFlow==o.getSumFlow()){
This.downFlow>o.getDownFlow() ? - :
}
}
自定义Partitioner
()自定义类继承Partitioner,重写getPartition()方法
public class ProvincePartitioner extends Partitioner<Text, FlowBean> { @Override
public int getPartition(Text key, FlowBean value, int numPartitions) { // 1 获取电话号码的前三位
String preNum = key.toString().substring(, ); int partition = ; // 2 判断是哪个省
if ("".equals(preNum)) {
partition = ;
}else if ("".equals(preNum)) {
partition = ;
}else if ("".equals(preNum)) {
partition = ;
}else if ("".equals(preNum)) {
partition = ;
}
return partition;
}
}
()在job驱动中,设置自定义partitioner:
job.setPartitionerClass(CustomPartitioner.class);
()自定义partition后,要根据自定义partitioner的逻辑设置相应数量的reduce task
job.setNumReduceTasks();
MapReduce面试题的更多相关文章
- Hadoop工程师面试题(1)--MapReduce实现单表汇总统计
数据源格式描述: 输入t1.txt源数据,数据文件分隔符"*&*",字段说明如下: 字段序号 字段英文名称 字段中文名称 字段类型 字段长度 1 TIME_ID 时间(到时 ...
- Hadoop,MapReduce,HDFS面试题
今天发这个的目的是为了给自己扫开迷茫,告诉自己该进阶了,下面内容不一定官方和正确.全然个人理解,欢迎大家留言讨论 1.什么是hadoop 答:是google的核心算法MapReduce的一个开源实现. ...
- Hadoop面试题总结(三)——MapReduce
1.谈谈Hadoop序列化和反序列化及自定义bean对象实现序列化? 1)序列化和反序列化 (1)序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输. (2) ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop 之面试题
颜色区别: 蓝色:hive,橙色:Hbase.黑色hadoop 请简述hadoop怎样实现二级排序. 你认为用Java,Streaming,pipe 方式开发map/reduce,各有哪些优缺点: 6 ...
- Hadoop 面试题之Hbase
Hadoop 面试题之九 16.Hbase 的rowkey 怎么创建比较好?列族怎么创建比较好? 答: 19.Hbase 内部是什么机制? 答: 73.hbase 写数据的原理是什么? 答: 75.h ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Java笔试题解答和部分面试题
面试类 银行类的问题 问题一:在多线程环境中使用HashMap会有什么问题?在什么情况下使用get()方法会产生无限循环? HashMap本身没有什么问题,有没有问题取决于你是如何使用它的.比如,你 ...
- 面试题_125_to_133_Java 面试中其他各式各样的问题
这部分包含 Java 中关于 XML 的面试题,JDBC 面试题,正则表达式面试题,Java 错误和异常及序列化面试题 125)嵌套静态类与顶级类有什么区别?(答案)一个公共的顶级类的源文件名称与类名 ...
随机推荐
- Highcharts error #16: www.highcharts.com/errors/16 js 单例
一.问题项目某一个页面用的highcharts用来显示一张图表,第一次刷新正常,第二次就出来这个错.1二.解决问题过程在网上找了很多同样是这个错误的解决方案. 第一:加载了highstock.js然后 ...
- rhcsa备战笔记
笔记全部手打 转载请加原文链接 0)重置密码开机按e 找到linux16行 rd.break console=tty0 ctrl+xmount -o remount,rw /sysrootchroo ...
- 2019.12.11 java练习
class Demo01 { public static void main(String[] args) { //数组求最大值 int[] arr={1,2,3,4,5,6,7,8,9}; int ...
- 关于System.ArgumentNullException异常
什么是ArgumentNullException 当将 null 引用(Visual Basic 中为 Nothing)传递到不接受其作为有效参数的方法时引发的异常. 继承 Object Except ...
- A revolutionary architecture for building a distributed graph
转自:https://blog.apollographql.com/apollo-federation-f260cf525d21 What if you could access all of you ...
- 使用go-mysql-server 开发自己的mysql server
go-mysql-server是一个golang 的mysql server 协议实现包,使用此工具我们可以用来做好多方便的东西 基于mysql 协议暴露自己的本地文件为sql 查询 基于mysql ...
- 回归模型的性能评价指标(Regression Model Performance Evaluation Metric)
回归模型的性能评价指标(Performance Evaluation Metric)通常有: 1. 平均绝对误差(Mean Absolute Error, MAE):真实目标y与估计值y-hat之间差 ...
- touchz,mkdir,vi的区别
touchz:创建空白文档 mkdir:创建一个目录 vi : 创建一个编辑状态的空文档,保存退出后创建成功.
- hdfs、yarn集成kerberos
1.kdc创建principal 1.1.创建认证用户 登陆到kdc服务器,使用root或者可以使用root权限的普通用户操作: # kadmin.local -q “addprinc -randke ...
- 【CSP模拟赛】Confess(数学 玄学)
题目描述 小w隐藏的心绪已经难以再隐藏下去了.小w有n+ 1(保证n为偶数)个心绪,每个都包含了[1,2n]的一个大小为n的子集.现在他要找到隐藏的任意两个心绪,使得他们的交大于等于n/2. 输入描述 ...