集合类源码(四)Collection之BlockingQueue(ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue)
ArrayBlockingQueue
功能
全名
public class ArrayBlockingQueue<E>
extends AbstractQueue<E>
implements BlockingQueue<E>, Serializable
简述
由数组支持的有界阻塞队列。这个队列对元素FIFO(先进先出)排序。队列的头是队列中存在时间最长的元素。队列的尾部是队列中存在时间最短的元素。新元素插入到队列的尾部,队列检索操作获取队列头部的元素。
这是一个典型的“有界缓冲区”,其中大小固定的数组保存由生产者插入并由消费者提取的元素。一旦创建,容量就不能更改。试图将一个元素放入一个满队列将导致操作阻塞;尝试从空队列中获取元素也会发生阻塞。
该类支持一个可选的公平性策略,用于对正在等待的生产者和消费者线程进行排序。默认情况下,不保证这种顺序。但是,将公平性设置为true的队列将按FIFO顺序授予线程访问权。公平性通常会降低吞吐量,但会降低可变性并避免饥饿。
方法
// 在不超过队列容量的情况下立即插入指定的元素,成功后返回true,如果队列已满则抛出IllegalStateException。
public boolean add(E e) // 在不超过队列容量的情况下立即在队列末尾插入指定的元素,如果成功则返回true,如果队列已满则返回false。此方法通常比add(E)方法更好,后者插入元素失败只能抛出异常。
public boolean offer(E e) // 将指定的元素插入到此队列的末尾,如果队列已满则等待直到有可用的空间。
public void put(E e) throws InterruptedException // 将指定的元素插入到此队列的末尾,如果队列已满,则在指定的超时时间之内等待空间可用,超时返回false。
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException // 检索并删除此队列的头,如果此队列为空,则返回null。
public E poll() // 检索并删除此队列的头,如有必要则等待,直到某个元素可用为止。
public E take() throws InterruptedException // 检索并删除此队列的头,如果有必要则在指定的等待时间之内等待元素可用,超时返回null。
public E poll(long timeout, TimeUnit unit) throws InterruptedException // 检索但不删除此队列的头,或在此队列为空时返回null。
public E peek() // 返回此队列中的元素数量。
public int size() // 返回此队列在理想情况下(在没有内存或资源约束的情况下)可以不阻塞地接受的新元素的数量。它总是等于这个队列的初始容量减去这个队列的当前大小。
public int remainingCapacity() // 如果指定元素存在,则从此队列中移除该元素的单个实例。更正式地说,如果队列中包含一个或多个这样的元素,则只删除匹配到的第一个元素
public boolean remove(Object o) // 如果此队列包含至少一个指定的元素,则返回true。
public boolean contains(Object o) // 返回一个数组,该数组包含此队列中的所有元素,按适当的顺序排列。返回的数组将是“安全的”,因为此队列不维护对它的引用。
public Object[] toArray() // 返回一个数组,该数组包含此队列中的所有元素,按适当的顺序排列;返回数组的运行时类型是指定数组的运行时类型。
public <T> T[] toArray(T[] a) // 返回此集合的字符串表示形式。
public String toString() // 删除此队列中的所有元素。此调用返回后,队列将为空。
public void clear() // 从此队列中删除所有可用元素并将它们添加到给定集合中。此操作可能比重复轮询此队列更有效。在试图将元素添加到集合c时遇到失败抛出相关异常时可能会导致:元素不在原集合或者集合c中,或者两个集合中都没有。
public int drainTo(Collection<? super E> c) // 从该队列中最多删除给定数量的可用元素,并将它们添加到给定集合中。异常情况同上
public int drainTo(Collection<? super E> c, int maxElements) // 按适当的顺序返回此队列中元素的迭代器。元素将按从第一个(head)到最后一个(tail)的顺序返回。返回的迭代器是弱一致的。
public Iterator<E> iterator() // 返回该队列中元素的Spliterator。返回的spliterator是弱一致的。
public Spliterator<E> spliterator()
原理
/** 队列里元素数量 */
int count;
/** 存储结构 */
final Object[] items; /** 为下一次执行 take, poll, peek or remove 操作提供的index */
int takeIndex; /** 为下一次执行 put, offer, or add 操作提供的index */
int putIndex; /** 当队列为空时获取等待 */
private final Condition notEmpty; /** 当队列满时插入等待 */
private final Condition notFull;
offer和put
public boolean offer(E e) {
// 不允许null值
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 队列里元素的数量等于队列长度(队列满,插入返回false)
if (count == items.length)
return false;
else {
// 插入
enqueue(e);
return true;
}
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
// 插入数据
items[putIndex] = x;
// 如果putIndex+1等于队列长度,将putIndex置为0,为下一轮插入做准备
if (++putIndex == items.length)
putIndex = 0;
// 队列元素数量+1
count++;
// 通知读取线程可以读取了
notEmpty.signal();
}
public void put(E e) throws InterruptedException {
// null值检查
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 获取一个优先考虑中断的锁
lock.lockInterruptibly();
try {
// 只要队列满了,则插入线程阻塞,直到有可用空间
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
// null值检查
checkNotNull(e);
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 在队列满了之后进入循环
while (count == items.length) {
// 如果小于等于0则超时,返回false
if (nanos <= 0)
return false;
// awaitNanos方法:使当前线程等待,直到收到signal或被中断,或指定的等待时间过期。
// 如果在时间之内收到了signal,则返回timeout - 已等待的时间;如果超时了,则返回0或者负数
nanos = notFull.awaitNanos(nanos);
}
enqueue(e);
return true;
} finally {
lock.unlock();
}
}
poll和take
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 如果队列空了,直接返回null
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex]; // 临时变量存储返回结果
items[takeIndex] = null; // 当前位置置为空
// 如果takeIndex+1等于队列长度,takeIndex置为0,为下一轮读取做准备
if (++takeIndex == items.length)
takeIndex = 0;
// 队列元素数量-1
count--;
// 如果当前迭代器不为空,迭代器也要做出更新
if (itrs != null)
itrs.elementDequeued();
// 通知写入线程写入数据
notFull.signal();
return x;
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 如果队列为空则一直等待,直到有可用元素
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
// 获取一个优先考虑中断的锁
lock.lockInterruptibly();
try {
// 队列为空进入循环
while (count == 0) {
// 如果小于等于0则超时,返回null
if (nanos <= 0)
return null;
// awaitNanos方法:使当前线程等待,直到收到signal或被中断,或指定的等待时间过期。
// 如果在时间之内收到了signal,则返回timeout - 已等待的时间;如果超时了,则返回0或者负数
nanos = notEmpty.awaitNanos(nanos);
}
return dequeue();
} finally {
lock.unlock();
}
}
从上面的进队出队我们可以知道大概的流程,首先内部存储结构是一个定长数组,初始情况putIndex和takeIndex都为0
当执行插入后,putIndex+1,为下一次插入做准备。当putIndex移动到最后的时候,+1正好等于队列最大长度,这个时候要将它置为初始状态也就是0。takeIndex同样的道理。
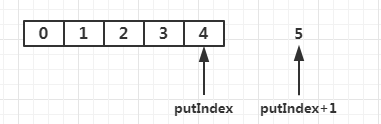
那么为什么要这么做,我已经知道了:避免了插入删除导致的元素移动!同时也保证了队列的性质:先进先出。
remove方法
public boolean remove(Object o) {
if (o == null) return false;
final Object[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock();
try {
if (count > 0) {
// final变量,不可变,下面循环做条件
final int putIndex = this.putIndex;
// 初始从takeIndex所指的位置开始
int i = takeIndex;
do {
// 找到了,执行移除代码
if (o.equals(items[i])) {
removeAt(i);
return true;
}
// 到末尾了,从头开始找
if (++i == items.length)
i = 0;
} while (i != putIndex); // 只要不是putIndex所指,继续找(因为putIndex所指的位置是null)
}
return false;
} finally {
lock.unlock();
}
}
void removeAt(final int removeIndex) {
// assert lock.getHoldCount() == 1;
// assert items[removeIndex] != null;
// assert removeIndex >= 0 && removeIndex < items.length;
final Object[] items = this.items;
// 如果移除的位置和takeIndex指向一致,相当于执行了一次出队操作,仅仅改变takeIndex即可。
if (removeIndex == takeIndex) {
// removing front item; just advance
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
} else {
// an "interior" remove
// slide over all others up through putIndex.
final int putIndex = this.putIndex;
for (int i = removeIndex;;) {
int next = i + 1;
if (next == items.length)
next = 0;
// 从移除位置开始,后面的向前复制
if (next != putIndex) {
items[i] = items[next];
i = next;
} else {
// 直到当前位置的下一个是putIndex,将当前位置置null,putIndex指向当前位置,跳出循环
items[i] = null;
this.putIndex = i;
break;
}
}
// 元素数量-1
count--;
// 同步迭代器
if (itrs != null)
itrs.removedAt(removeIndex);
}
notFull.signal();
}
remove方法,移除元素的位置不是takeIndex的时候,移除过程是下面这样
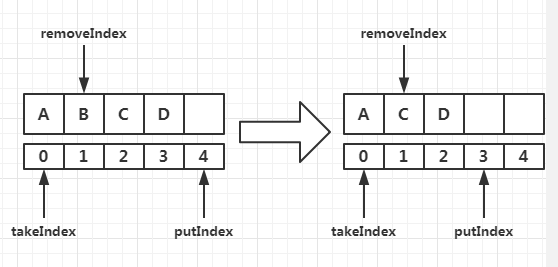
最后看一下drainTo
// 把队列元素删除,并将元素添加到集合c中
public int drainTo(Collection<? super E> c) {
// 这里可以看到,默认删除数量为Integer.MAX_VALUE
return drainTo(c, Integer.MAX_VALUE);
}
public int drainTo(Collection<? super E> c, int maxElements) {
checkNotNull(c);
if (c == this)
throw new IllegalArgumentException();
if (maxElements <= 0)
return 0;
final Object[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 从给定的数量和队列元素数量选出最小的一个(也就是说,无论你设置的数量为多大,最多也就是把整个队列清空,不然访问不存在的位置会出异常)
int n = Math.min(maxElements, count);
// 从takeIndex开始
int take = takeIndex;
int i = 0;
try {
// 操作n个元素
while (i < n) {
@SuppressWarnings("unchecked")
E x = (E) items[take];
// 添加到c中
c.add(x);
// 原队列删除
items[take] = null;
// take向后移动;如果到了队尾,从头开始
if (++take == items.length)
take = 0;
i++;
}
return n;
} finally {
// Restore invariants even if c.add() threw
if (i > 0) {
count -= i; // 剩余队列元素数量
takeIndex = take; // 重置takeIndex
if (itrs != null) {
// 如果队列空了,迭代器也要做出同步
if (count == 0)
itrs.queueIsEmpty();
else if (i > take)
// 当takeIndex变为0时调用。
itrs.takeIndexWrapped();
}
// 通知等待的插入线程
for (; i > 0 && lock.hasWaiters(notFull); i--)
notFull.signal();
}
}
} finally {
lock.unlock();
}
}
优缺点
优点:有界队列,避免了内存滥用;内部插入删除实现避免了元素移动,时间复杂度为O(1),高效率;线程安全;
缺点:我觉得这个在特定场景已经很完美了。
如果你想在进队出队时不满足条件立即返回,则直接用offer和poll;如果你希望等待,则用put和take;如果你希望等一会,不行再返回,则用offer(E e, long timeout, TimeUnit unit)和poll(long timeout, TimeUnit unit)。
remove方法尽量不用吧,因为它在删除之后要去判断调整putIndex或者takeIndex。
DelayQueue
功能
全名
public class DelayQueue<E extends Delayed>
extends AbstractQueue<E>
implements BlockingQueue<E>
简述
延迟元素的无界阻塞队列,其中一个元素只能在其延迟过期后才能被获取。
队列的头是延迟元素。如果没有过期,就没有head, poll将返回null。
当元素的getDelay(TimeUnit.NANOSECONDS)方法返回一个小于或等于零的值时,就会发生过期。
未过期的元素不能使用take或poll删除,它们被视为正常元素。根据定义,它的元素必须是Delayed接口的实现。
方法
// 将指定的元素插入此延迟队列。
public boolean add(E e) // 将指定的元素插入此延迟队列
public boolean offer(E e) // 将指定的元素插入此延迟队列。因为队列是无界的,所以这个方法永远不会阻塞。
public void put(E e) // 将指定的元素插入此延迟队列。因为队列是无界的,所以这个方法永远不会阻塞。
public boolean offer(E e, long timeout, TimeUnit unit) // 检索并删除此队列的头,如果此队列没有过期的元素,则返回null。
public E poll() // 检索并删除此队列的头,如有必要,将一直等待,直到此队列上有一个过期的元素可用为止。
public E take() throws InterruptedException // 检索并删除此队列的头,如有必要,将一直等待,直到此队列中具有过期延迟的元素可用,或指定的等待时间过期。
public E poll(long timeout,
TimeUnit unit)
throws InterruptedException // 检索但不删除此队列的头,或在此队列为空时返回null。与poll方法不同,如果队列中没有可用的过期元素,此方法将返回下一个将要过期的元素(如果存在的话)。
public E peek() // 返回此集合中的元素数。如果此集合元素数大于Integer.MAX_VALUE,也只返回Integer.MAX_VALUE
public int size() // 从此队列中删除所有可用元素并将它们添加到给定集合中。此操作可能比重复轮询此队列更有效。在试图将元素添加到集合c时遇到失败抛出相关异常时可能会导致:元素不在原集合或者集合c中,或者两个集合中都没有。
public int drainTo(Collection<? super E> c) // 从该队列中最多删除给定数量的可用元素,并将它们添加到给定集合中。异常情况同上
public int drainTo(Collection<? super E> c, int maxElements) // 删除此延迟队列中的所有元素。此调用返回后,队列将为空。不等待未过期的元素;它们只是从队列中被丢弃。
public void clear() // 总是返回Integer.MAX_VALUE,因为延迟队列没有容量限制。
public int remainingCapacity() // 返回一个数组,该数组包含此队列中的所有元素,按适当的顺序排列。返回的数组将是“安全的”,因为此队列不维护对它的引用。
public Object[] toArray() // 返回一个数组,该数组包含此队列中的所有元素,按适当的顺序排列;返回数组的运行时类型是指定数组的运行时类型。
public <T> T[] toArray(T[] a) // 从此队列中删除指定元素的单个实例(如果存在),无论它是否已过期。
public boolean remove(Object o) // 返回此队列中所有元素(过期和未过期)的迭代器。迭代器不会以任何特定的顺序返回元素。返回的迭代器是弱一致的。
public Iterator<E> iterator()
原理
成员变量
private final transient ReentrantLock lock = new ReentrantLock();
// 延迟队列的内部存储结构是优先级队列 [praɪˈɒrəti][kjuː]
private final PriorityQueue<E> q = new PriorityQueue<E>(); private Thread leader = null;
// 当一个新的元素在队列的最前面可用,或者一个新线程需要成为leader时,就会发出条件信号。
private final Condition available = lock.newCondition();
offer和put
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 入队
q.offer(e);
if (q.peek() == e) {
leader = null;
// 如果队头元素是当前元素(新添加的元素已经过期),则通知等待线程
available.signal();
}
return true;
} finally {
lock.unlock();
}
}
// 实际调用的是offer
public void put(E e) {
offer(e);
}
// 不仅仅调用的offer,并且timeout参数,unit参数都没有用到
public boolean offer(E e, long timeout, TimeUnit unit) {
return offer(e);
}
// java.util.PriorityQueue#offer
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
// 内部存储结构修改次数
modCount++;
int i = size;
// 如果队列元素数量大于等于队列长度,则扩容
if (i >= queue.length)
grow(i + 1);
// 队列元素数量+1
size = i + 1;
if (i == 0)
// 如果队列为空,直接放在第一位
queue[0] = e;
else
// 队列不为空,在i的位置插入e。【这里面有个排序的过程,根据我们定义的排序规则把最早过期的排在内部数组第一位,保证队头是最早过期的元素】
siftUp(i, e);
return true;
}
// java.util.PriorityQueue#grow
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// 如果老容量小于64,则新容量 = 2*老容量+2;如果老容量大于等于64,则新容量 = 1.5*老容量
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
// java.util.PriorityQueue#peek
public E peek() {
// 不为空,则返回队列第一个元素(准确来说是内部数组第一个)
return (size == 0) ? null : (E) queue[0];
}
这里可以看出,延迟队列的内部实现是优先级队列,优先级队列的内部实现是一个数组,扩容的时候新容量与ArrayList的有一丢丢不一样。因为可以扩容,所以延时队列是个无界队列。
poll和take
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 获取队头
E first = q.peek();
// 如果队头为空或者未过期,直接返回空
if (first == null || first.getDelay(NANOSECONDS) > 0)
return null;
else
// 否则出队并返回
return q.poll();
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
// 如果获取不到,则等待
if (first == null)
available.await();
else {
// 获取剩余过期时间
long delay = first.getDelay(NANOSECONDS);
// 满足过期条件,出队并返回
if (delay <= 0)
return q.poll();
// 当线程等待,不保留这个引用
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 等待剩余过期时间那么长的时间
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
// 没有获取到有效元素
if (first == null) {
// timeout无效,返回空
if (nanos <= 0)
return null;
else
// 否则等待timeout那么长的时间
nanos = available.awaitNanos(nanos);
} else {
// 获取剩余过期时间
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
// 已经过期,顺利出队返回
return q.poll();
// timeout无效,返回空
if (nanos <= 0)
return null;
first = null; // don't retain ref while waiting
if (nanos < delay || leader != null)
// 如果timeout时间小于剩余过期时间,等待timeout那么长的时间
nanos = available.awaitNanos(nanos);
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 否则等待剩余过期时间那么长的时间
long timeLeft = available.awaitNanos(delay);
nanos -= delay - timeLeft;
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
小例子:
import java.util.concurrent.*;
public class Main {
public static void main(String[] args) throws Exception {
DelayQueue<MyDelay> list = new DelayQueue<>();
list.offer(new MyDelay(1000, "A"));
list.offer(new MyDelay(2000, "B"));
list.offer(new MyDelay(3000, "C"));
for (int i = 0; i < 3; i++){
System.out.println(list.take().toString());
}
}
}
class MyDelay implements Delayed {
private long expireTime;
private String name;
public MyDelay(long expireTime, String name) {
this.expireTime = System.currentTimeMillis() + expireTime;
this.name = name;
}
@Override
public long getDelay(TimeUnit unit) {
return expireTime - System.currentTimeMillis();
}
@Override
public int compareTo(Delayed o) {
return Long.compare(expireTime, ((MyDelay)o).expireTime);
}
@Override
public String toString() {
return "MyDelay{" +
"expireTime=" + expireTime +
", name='" + name + '\'' +
'}';
}
}
运行结果:按照过期顺序输出
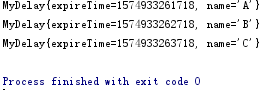
优缺点
内部是依赖优先级队列实现的,也可以说,延时队列是优先级队列的一个特例(按照时间过期顺序排序)。因为是无界队列,插入不会阻塞;由于过期时间的限制,poll和take会阻塞。
使用场景:
1. 订单超30分钟未付款即关闭订单。
2. 定时任务:延时队列保存要执行的任务,一旦获取到即执行。
3. 服务器中的客户端连接空闲一段时间之后就需要关闭。
为什么用Leader-Follower模式?
官方说法:Leader为等待队列头部的元素的线程。 Leader-Follower模式的这种变体可以最小化不必要的等待时间。在从take()或poll(…)返回之前,领导线程必须向其他线程发出信号,除非其他线程在此期间成为领导线程。
模式原理:一开始创建一个线程池,选取一个当做Leader监听任务,其它线程等待;当Leader拿到了任务,即释放自己的权利,然后从等待线程中选取一个作为新的Leader去监听任务,自己则去执行拿到的任务,执行完任务进入等待状态。由于接受任务和执行都是同一个线程,则避免了上下文切换的开销。
LinkedBlockingQueue
功能
全名
public class LinkedBlockingQueue<E>
extends AbstractQueue<E>
implements BlockingQueue<E>, Serializable
简述
基于链表的有界阻塞队列。这个队列对元素FIFO(先进先出)排序。队列的头是队列中存在时间最长的元素。队列的尾部是队列中时间最短的元素。
新元素插入到队列的尾部,队列检索操作获取队列头部的元素。链表队列通常比基于数组的队列具有更高的吞吐量,但在大多数并发应用程序中,其性能的可预测性较差。
构造函数里的容量参数用作防止队列过度扩展的一种方法。容量(如果未指定)等于Integer.MAX_VALUE。这里可以得知,LinkedBlockingQueue的有界和无界是灵活的:如果你需要有界,则必须在构造方法指定容量;如果不指定,容量等于Integer.MAX_VALUE,和无界没有什么区别了。
方法
// 返回此队列中的元素数量。
public int size() // 返回此队列在理想情况下(在没有内存或资源约束的情况下)可以不阻塞地接受新元素的数量。它总是等于这个队列的初始容量减去这个队列的当前大小。
public int remainingCapacity() // 将指定的元素插入到此队列的末尾,如果需要,则等待空间可用。
public void put(E e) throws InterruptedException // 将指定的元素插入到此队列的末尾,如有必要,将等待指定的等待时间,直到空间可用为止。超时则返回false。
public boolean offer(E e,
long timeout,
TimeUnit unit)
throws InterruptedException // 在不超过队列容量的情况下立即在队列末尾插入指定的元素,如果成功则返回true,如果队列已满则返回false。当使用容量受限的队列时,此方法通常比add方法更好,后者插入失败仅抛出异常。
public boolean offer(E e) // 检索并删除此队列的头,如有必要则等待,直到某个元素可用为止。
public E take() throws InterruptedException // 检索并删除此队列的头,如有必要,将等待指定的等待时间,直到元素可用。超时返回null。
public E poll(long timeout, TimeUnit unit) throws InterruptedException // 检索并删除此队列的头,如果此队列为空,则返回null。
public E poll() // 检索并删除此队列的头,如果此队列为空,则返回null。
public E peek() // 如果指定元素存在,则从此队列中移除该元素的单个实例。更正式地说,如果队列中包含一个或多个这样的元素,则只删除第一个匹配到的元素。
public boolean remove(Object o) // 如果此队列包含至少一个指定的元素,则返回true。
public boolean contains(Object o) // 返回一个数组,该数组包含此队列中的所有元素,按适当的顺序排列。返回的数组将是“安全的”,因为此队列不维护对它的引用。
public Object[] toArray() // 返回一个数组,该数组包含此队列中的所有元素,按适当的顺序排列;返回数组的运行时类型是指定数组的运行时类型。
public <T> T[] toArray(T[] a) // 返回此集合的字符串表示形式。
public String toString() // 删除此队列中的所有元素。此调用返回后,队列将为空。
public void clear() // 从此队列中删除所有可用元素并将它们添加到给定集合中。此操作可能比重复轮询此队列更有效。在试图将元素添加到集合c时遇到失败抛出相关异常时可能会导致:元素不在原集合或者集合c中,或者两个集合中都没有。
public int drainTo(Collection<? super E> c) // 从该队列中最多删除给定数量的可用元素,并将它们添加到给定集合中。异常情况同上
public int drainTo(Collection<? super E> c, int maxElements) // 按适当的顺序返回此队列中元素的迭代器。元素将按从第一个(head)到最后一个(tail)的顺序返回。返回的迭代器是弱一致的。
public Iterator<E> iterator() // 返回该队列中元素的Spliterator。返回的spliterator是弱一致的。
public Spliterator<E> spliterator()
原理
成员变量
/** 队列容量,默认Integer.MAX_VALUE */
private final int capacity; /** 当前队列元素数量 */
private final AtomicInteger count = new AtomicInteger(); /**
* 链表的head
*/
transient Node<E> head; /**
* 链表的tail
*/
private transient Node<E> last; /** 由take, poll方法持有的锁 */
private final ReentrantLock takeLock = new ReentrantLock(); /** 当take的时候,如果队列为空,则等待 */
private final Condition notEmpty = takeLock.newCondition(); /** 由put, offer方法持有的锁 */
private final ReentrantLock putLock = new ReentrantLock(); /** 当put的时候,如果队列为空,则等待 */
private final Condition notFull = putLock.newCondition();
put和offer
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
Node<E> node = new Node<E>(e);
// 拿到putLock
final ReentrantLock putLock = this.putLock;
// 拿到计数器
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
/*
* Note that count is used in wait guard even though it is
* not protected by lock. This works because count can
* only decrease at this point (all other puts are shut
* out by lock), and we (or some other waiting put) are
* signalled if it ever changes from capacity. Similarly
* for all other uses of count in other wait guards.
*/
// 如果元素数量等于容量,也就是队列满了,则阻塞
while (count.get() == capacity) {
notFull.await();
}
// 入队
enqueue(node);
// 获取并加1;注意这里的c = 加1之前的值
c = count.getAndIncrement();
// 通知其它线程继续入队
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 因为c的值是+1之前的,所以在此情况下:实际上队列元素数量为1,则通知等待中的take线程来拿取
if (c == 0)
signalNotEmpty();
}
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
long nanos = unit.toNanos(timeout);
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
// 如果队列满了,则等待指定时间;如果指定时间内有可用空间,则继续向下执行;如果超时,则返回false
while (count.get() == capacity) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
// 入队
enqueue(new Node<E>(e));
// 先获取元素数量, 然后+1
c = count.getAndIncrement();
// 入队之后还有可用空间,则通知其它等待线程,继续入队
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return true;
}
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
if (count.get() == capacity)
return false;
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
// 注意这里不是lockInterruptibly
putLock.lock();
try {
// 如果有可用空间,则入队;否则返回false(c= -1)
if (count.get() < capacity) {
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}
take和poll
public E take() throws InterruptedException {
E x;
int c = -1;
// 拿到计数器
final AtomicInteger count = this.count;
// 拿到takeLock
final ReentrantLock takeLock = this.takeLock;
// 优先响应中断
takeLock.lockInterruptibly();
try {
// 如果队列为空,则等待,直到有可用元素
while (count.get() == 0) {
notEmpty.await();
}
// 出队
x = dequeue();
// 获取并减1;注意这里的c = 减1之前的值
c = count.getAndDecrement();
// 通知其它等待线程,继续出队
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 因为c的值是-1之前的,所以在此情况下:队列里面元素数量 = 容量大小 - 1,则通知等待中的添加线程添加
if (c == capacity)
signalNotFull();
return x;
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E x = null;
int c = -1;
long nanos = unit.toNanos(timeout);
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
// 如果队列为空,则等待指定时间;如果指定时间内有可用元素,则继续向下执行;如果超时,则返回null
while (count.get() == 0) {
if (nanos <= 0)
return null;
nanos = notEmpty.awaitNanos(nanos);
}
// 出队
x = dequeue();
// 先获取元素数量,然后-1
c = count.getAndDecrement();
// 通知其它等待中的take线程
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 通知等待中的添加线程添加
if (c == capacity)
signalNotFull();
return x;
}
public E poll() {
final AtomicInteger count = this.count;
if (count.get() == 0)
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
// 如果有可用元素,出队;否则返回null
if (count.get() > 0) {
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
peek
public E peek() {
// 队列为空,返回null
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
// 返回head指向的数据
Node<E> first = head.next;
if (first == null)
return null;
else
return first.item;
} finally {
takeLock.unlock();
}
}
enqueue和dequeue
// 入队操作,就是把新结点添加到队列的最后
private void enqueue(Node<E> node) {
// assert putLock.isHeldByCurrentThread();
// assert last.next == null;
// 尾指针的next指向新结点,当前尾指针指向尾指针的next;
last = last.next = node;
} // 出队操作,就是把队头移除
private E dequeue() {
// assert takeLock.isHeldByCurrentThread();
// assert head.item == null;
// 当前队头
Node<E> h = head;
// 下一任队头(head的next节点)
Node<E> first = h.next;
h.next = h; // help GC
// 任命新的队头
head = first;
// 老数据
E x = first.item;
first.item = null;
// 将老数据返回
return x;
}
通过这个出队操作,可以得知,内部的链表的head指针不存储任何数据,仅仅是标记的作用(带头结点的链表,虽然多占了一个结点的空间,但是处理逻辑变简单了)
clear
public void clear() {
// 拿到两把锁
fullyLock();
try {
// 遍历链表删除
for (Node<E> p, h = head; (p = h.next) != null; h = p) {
h.next = h;
p.item = null;
}
// 最后首尾合一
head = last;
// assert head.item == null && head.next == null;
if (count.getAndSet(0) == capacity)
notFull.signal();
} finally {
fullyUnlock();
}
}
优缺点
内部结构是个链表,新增和删除操作都涉及结点的创建(封装成Node)和删除(Node的回收),相比ArrayBlockingQueue是直接在数组位置进行数据的赋值与删除,开销大了一些。
相比ArrayBlockingQueue只用了一把锁,LinkedBlockingQueue使用了takeLock和putLock两把锁,分别用于阻塞队列的读写线程,也就是说,读线程和写线程可以同时运行,在多线程高并发场景,可以有更高的吞吐量。
因为队列的读写分别在头部和尾部,相互竞争的几率较小,所以用双锁可以实现更高的吞吐量;而ArrayBlockingQueue,只有一个数组,也可以用双锁,但是代码可就复杂了。
集合类源码(四)Collection之BlockingQueue(ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue)的更多相关文章
- Java集合类源码解析:Vector
[学习笔记]转载 Java集合类源码解析:Vector 引言 之前的文章我们学习了一个集合类 ArrayList,今天讲它的一个兄弟 Vector.为什么说是它兄弟呢?因为从容器的构造来说,Vec ...
- J.U.C并发框架源码阅读(八)ArrayBlockingQueue
基于版本jdk1.7.0_80 java.util.concurrent.ArrayBlockingQueue 代码如下 /* * ORACLE PROPRIETARY/CONFIDENTIAL. U ...
- JDK8集合类源码解析 - HashSet
HashSet 特点:不允许放入重复元素 查看源码,发现HashSet是基于HashMap来实现的,对HashMap做了一次“封装”. private transient HashMap<E,O ...
- Java集合类源码解析:HashMap (基于JDK1.8)
目录 前言 HashMap的数据结构 深入源码 两个参数 成员变量 四个构造方法 插入数据的方法:put() 哈希函数:hash() 动态扩容:resize() 节点树化.红黑树的拆分 节点树化 红黑 ...
- JUC源码分析-集合篇(六)LinkedBlockingQueue
JUC源码分析-集合篇(六)LinkedBlockingQueue 1. 数据结构 LinkedBlockingQueue 和 ConcurrentLinkedQueue 一样都是由 head 节点和 ...
- Java集合类源码分析
常用类及源码分析 集合类 原理分析 Collection List Vector 扩充容量的方法 ensureCapacityHelper很多方法都加入了synchronized同步语句,来保 ...
- Java集合类源码解析:ArrayList
目录 前言 源码解析 基本成员变量 添加元素 查询元素 修改元素 删除元素 为什么用 "transient" 修饰数组变量 总结 前言 今天学习一个Java集合类使用最多的类 Ar ...
- Java集合类源码解析:AbstractList
今天学习Java集合类中的一个抽象类,AbstractList. 初识AbstractList AbstractList 是一个抽象类,实现了List<E>接口,是隶属于Java集合框架中 ...
- Java集合类源码解析:AbstractMap
目录 引言 源码解析 抽象函数entrySet() 两个集合视图 操作方法 两个子类 参考: 引言 今天学习一个Java集合的一个抽象类 AbstractMap ,AbstractMap 是Map接口 ...
- java集合类源码学习二
我们查看Collection接口的hierarchy时候,可以看到AbstractCollection<E>这样一个抽象类,它实现了Collection接口的部分方法,Collection ...
随机推荐
- CSS 选择器大全
在CSS中,选择器是用于选择要设置样式的元素的模式. 选择器 例子 描述 .class .intro 选择class=“intro”的所有元素 #id #firstname 选择id=“firstna ...
- 一次压测中tomcat生成session释放不及时导致的频繁fullgc性能优化案例
性能问题:老年代一直处于占满状态,为什么没有发生内存溢出 以HotSpot VM的分代式GC为例,普通对象分配都是在young gen进行的,具体是从在位于young gen中的eden space中 ...
- Qt我的文档 桌面路径
我的文档 QString location = QStandardPaths::writableLocation(QStandardPaths::DocumentsLocation); 桌面 QStr ...
- C# 测试网络速度例子
using System.Net.NetworkInformation; namespace PingExample { public partial class Form1 : Form { pub ...
- 安装教程-VMware 12 安装 Windows 10 企业版
VMware 12 安装 Windows 10 企业版 1.实验描述 在虚拟机中,手动安装 Windows10 企业版操作系统,为一些实验提供平台,因此,有关系统激活问题不再演示.可自行百度,或者加入 ...
- 【面试题】了解session和cookie吗?
问题:SESSION与COOKIE的区别? 1.cookie数据存放在客户的浏览器上,session数据放在服务器上. 2.cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKI ...
- C++编译错误 --- 成员函数定义在 .h 文件中出现重定义错误(Error LNK 2005)
今天写了一个简单的类,定义在 .h 文件中, 类很简单就将其成员函数定义在了一起(class类后面).运行的时候出现了如下图所示的编译错误(error LNK2005) 查资料,大部分都是说需要加上 ...
- 论文笔记系列-AutoFPN
原论文:Auto-FPN: Automatic Network Architecture Adaptation for Object Detection Beyond Classification 之前 ...
- JVM 常用启动参数
JVM 常用启动参数 默认值 -xms -xmx
- zz深度学习论文合集大全
Pull requestsIssues Marketplace Explore Learn Git and GitHub without any code! Using ...