NameNode的HA
HA概述
1)所谓HA(High Available),即高可用(7*24小时不中断服务)。
2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
4)NameNode主要在以下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
HDFS-HA工作机制
通过双NameNode消除单点故障
HDFS-HA工作要点
1. 元数据管理方式需要改变
内存中各自保存一份元数据;
Edits日志只有Active状态的NameNode节点可以做写操作;
两个NameNode都可以读取Edits;
共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现);
2. 需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。
3. 必须保证两个NameNode之间能够ssh无密码登录
4. 隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
HDFS-HA自动故障转移工作机制
前面学习了使用命令hdfs haadmin -failover手动进行故障转移,在该模式下,即使现役NameNode已经失效,系统也不会自动从现役NameNode转移到待机NameNode,下面学习如何配置部署HA自动进行故障转移。自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程,如图3-20所示。ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
1)故障检测:集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
2)现役NameNode选择:ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
1)健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
2)ZooKeeper会话管理:当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
3)基于ZooKeeper的选择:如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役NameNode,然后本地NameNode转换为Active状态。
在Hadoop 1.x 中,Namenode是集群的单点故障,一旦Namenode出现故障,整个集群将不可用,重启或者开启一个新的Namenode才能够从中恢复。值得一提的是,Secondary Namenode并没有提供故障转移的能力。集群的可用性受到影响表现在:
- 当机器发生故障,如断电时,管理员必须重启Namenode才能恢复可用。
- 在日常的维护升级中,需要停止Namenode,也会导致集群一段时间不可用。
架构
Hadoop HA(High Available)通过同时配置两个处于Active/Passive模式的Namenode来解决上述问题,分别叫Active Namenode和Standby Namenode. Standby Namenode作为热备份,从而允许在机器发生故障时能够快速进行故障转移,同时在日常维护的时候使用优雅的方式进行Namenode切换。Namenode只能配置一主一备,不能多于两个Namenode。
主Namenode处理所有的操作请求(读写),而Standby只是作为slave,维护尽可能同步的状态,使得故障时能够快速切换到Standby。为了使Standby Namenode与Active Namenode数据保持同步,两个Namenode都与一组Journal Node进行通信。当主Namenode进行任务的namespace操作时,都会确保持久会修改日志到Journal Node节点中的大部分。Standby Namenode持续监控这些edit,当监测到变化时,将这些修改应用到自己的namespace。
当进行故障转移时,Standby在成为Active Namenode之前,会确保自己已经读取了Journal Node中的所有edit日志,从而保持数据状态与故障发生前一致。
为了确保故障转移能够快速完成,Standby Namenode需要维护最新的Block位置信息,即每个Block副本存放在集群中的哪些节点上。为了达到这一点,Datanode同时配置主备两个Namenode,并同时发送Block报告和心跳到两台Namenode。
确保任何时刻只有一个Namenode处于Active状态非常重要,否则可能出现数据丢失或者数据损坏。当两台Namenode都认为自己的Active Namenode时,会同时尝试写入数据(不会再去检测和同步数据)。为了防止这种脑裂现象,Journal Nodes只允许一个Namenode写入数据,内部通过维护epoch数来控制,从而安全地进行故障转移。
有两种方式可以进行edit log共享:
- 使用NFS共享edit log(存储在NAS/SAN)
- 使用QJM共享edit log
使用NFS共享存储
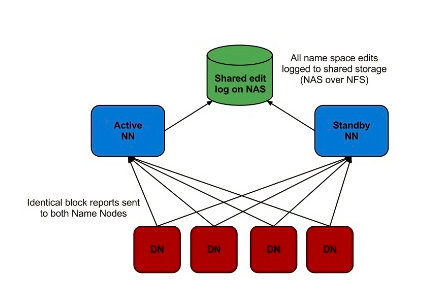
如图所示,NFS作为主备Namenode的共享存储。这种方案可能会出现脑裂(split-brain),即两个节点都认为自己是主Namenode并尝试向edit log写入数据,这可能会导致数据损坏。通过配置fencin脚本来解决这个问题,fencing脚本用于:
- 将之前的Namenode关机
- 禁止之前的Namenode继续访问共享的edit log文件
使用这种方案,管理员就可以手工触发Namenode切换,然后进行升级维护。但这种方式存在以下问题:
- 只能手动进行故障转移,每次故障都要求管理员采取措施切换。
- NAS/SAN设置部署复杂,容易出错,且NAS本身是单点故障。
- Fencing 很复杂,经常会配置错误。
- 无法解决意外(unplanned)事故,如硬件或者软件故障
因此需要另一种方式来处理这些问题:
- 自动故障转移(引入ZooKeeper达到自动化)
- 移除对外界软件硬件的依赖(NAS/SAN)
- 同时解决意外事故及日常维护导致的不可用
Quorum-based 存储 + ZooKeeper
QJM(Quorum Journal Manager)是Hadoop专门为Namenode共享存储开发的组件。其集群运行一组Journal Node,每个Journal 节点暴露一个简单的RPC接口,允许Namenode读取和写入数据,数据存放在Journal节点的本地磁盘。当Namenode写入edit log时,它向集群的所有Journal Node发送写入请求,当多数节点回复确认成功写入之后,edit log就认为是成功写入。例如有3个Journal Node,Namenode如果收到来自2个节点的确认消息,则认为写入成功。
而在故障自动转移的处理上,引入了监控Namenode状态的ZookeeperFailController(ZKFC)。ZKFC一般运行在Namenode的宿主机器上,与Zookeeper集群协作完成故障的自动转移。整个集群架构图如下:

QJM
Namenode使用QJM 客户端提供的RPC接口与Namenode进行交互。写入edit log时采用基于仲裁的方式,即数据必须写入JournalNode集群的大部分节点。
在Journal Node节点上(服务端)
服务端Journal运行轻量级的守护进程,暴露RPC接口供客户端调用。实际的edit log数据保存在Journal Node本地磁盘,该路径在配置中使用dfs.journalnode.edits.dir属性指定。
Journal Node通过epoch数来解决脑裂的问题,称为JournalNode fencing。具体工作原理如下:
1)当Namenode变成Active状态时,被分配一个整型的epoch数,这个epoch数是独一无二的,并且比之前所有Namenode持有的epoch number都高。
2)当Namenode向Journal Node发送消息的时候,同时也带上了epoch。当Journal
Node收到消息时,将收到的epoch数与存储在本地的promised
epoch比较,如果收到的epoch比自己的大,则使用收到的epoch更新自己本地的epoch数。如果收到的比本地的epoch小,则拒绝请求。
3)edit log必须写入大部分节点才算成功,也就是其epoch要比大多数节点的epoch高。
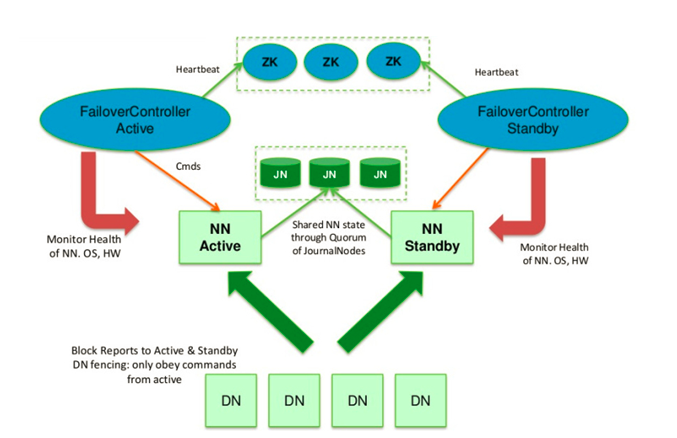
这种方式解决了NFS方式的3个问题:
- 不需要额外的硬件,使用原有的物理机
- Fencing通过epoch数来控制,避免出错。
- 自动故障转移:Zookeeper处理该问题。
使用Zookeeper进行自动故障转移
前面提到,为了支持故障转移,Hadoop引入两个新的组件:Zookeeper Quorum和ZKFailoverController process(简称ZKFC)。
Zookeeper的任务包括:
- 失败检测: 每个Namnode都在ZK中维护一个持久性session,如果Namnode故障,session过期,使用zk的事件机制通知其他Namenode需要故障转移。
- Namenode选举:如果当前Active namenode挂了,另一个namenode会尝试获取ZK中的一个排它锁,获取这个锁就表名它将成为下一个Active NN。
在每个Namenode守护进程的机器上,同时也会运行一个ZKFC,用于完成以下任务:
- Namenode健康健康
- ZK Session管理
- 基于ZK的Namenode选举
如果ZKFC所在机器的Namenode健康状态良好,并且用于选举的znode锁未被其他节点持有,则ZKFC会尝试获取锁,成功获取这个排它锁就代表获得选举,获得选举之后负责故障转移,如果有必要,会fencing掉之前的namenode使其不可用,然后将自己的namenode切换为Active状态。
部署与配置
硬件资源
为了允许HA集群,需要以下资源:
1)Namenode机器:运行Active Namenode和Standby Namenode的机器配置应保持一样,也与不使用HA情况下的配置一样。
2)JournalNode机器:运行JournalNode的机器,这些守护进程比较轻量级,所以可以将其部署在Namenode或者YARN
ResourceManager。至少需要部署3个Journalnode节点,以便容忍一个节点故障。通常配置成奇数,例如总数为N,则可以容忍(N-1)/2台机器发生故障后集群仍然可以正常工作。
需要注意的是,Standby Namenode同时完成了原来Secondary namenode的checkpoint功能,因此不需要独立再部署Secondary namenode。
HA配置
Nameservices: 服务的逻辑名称
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
Namenode配置:
dfs.ha.namenodes.[nameservices]: nameserviecs对应的namenode:
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value> <!--目前最大只能2个-->
</property>
Namenode RPC地址:
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
Namenode HTTP Server配置:
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:50070</value>
</property> <!--如果启用了Hadoop security,需要使用https-address-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>
edit log保存目录,也就是Journal Node集群地址,分号隔开:
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value>
</property>
客户端故障转移代理类,目前只提供了一种实现:
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
edit日志保存路径:
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/path/to/journal/node/local/data</value>
</property>
fencing方法配置:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>
虽然在使用QJM作为共享存储时,不会出现同时写入的脑裂现象。但是旧的namenode依然可以接受读请求,这可能会导致数据过时,直到原有namenode尝试写入journal node时才关机。因此也推荐配置一种合适的fencing方法。
部署启动
配置完成之后,使用如下命令启动JQM集群:
hadoop-daemon.sh start journalnode
配置并启动Zookeeper集群,与常规的而配置方式完成一样,主要包括数据保存位置、节点id、时间配置等,在zoo.cfg中配置。这里不列出详细步骤。使用之前,需要格式化zk的文件:
hdfs zkfc -formatZK
格式化Namenode:
hdfs namenode -format
启动两个namenode:
//master
hadoop-daemon.sh start namenode27
//备用namenode上
hdfs namenode -bootstrapStandby
其他组件的启动方式与常规方式一样。
NameNode的HA的更多相关文章
- NameNode配置HA后及其反过程Hive路径不正确的问题解决
在CDH5.7下,配置了NameNode的HA后,Hive无正常查询数据了,但是其他的组件HDFS , HBase ,Spark都正常的.Hive新建表出现如下异常: CREATE TABLE `x_ ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- hadoop NameNode 手动HA
官网配置地址:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWit ...
- hadoop2.x通过Zookeeper来实现namenode的HA方案以及ResourceManager单点故障的解决方案
我们知道hadoop1.x之前的namenode存在两个主要的问题:1.namenode内存瓶颈的问题,2.namenode的单点故障的问题.针对这两个问题,hadoop2.x都对它进行改进和解决.其 ...
- Hadoop-2.3.0-cdh5.0.1完全分布式环境搭建(NameNode,ResourceManager HA)
编写不易,转载请注明(http://shihlei.iteye.com/blog/2084711)! 说明 本文搭建Hadoop CDH5.0.1 分布式系统,包括NameNode ,Resource ...
- Hadoop中Namenode的HA查询和切换
有一段时间没有关注公司服务器上自己搭的三台小型hadoop集群了,上星期公司机房停电了,这次上去start了集群,但是发现start之后无法工作了. 查看了jps发现该有的进程都有了,敲入 hadoo ...
- 【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】
问题描述: 上一篇就是NameNode 的HA 部署完成,但是存在问题,问题是如果 主NameNode的节点宕机了,还是需要人工去使用命令来切换NameNode的Acitve 这样很不方便,所以 ...
- Namenode HA原理详解(脑裂)
转自:http://blog.csdn.net/tantexian/article/details/40109331 Namenode HA原理详解 社区hadoop2.2.0 release版本开始 ...
- 安装部署Apache Hadoop (完全分布式模式并且实现NameNode HA和ResourceManager HA)
本节内容: 环境规划 配置集群各节点hosts文件 安装JDK1.7 安装依赖包ssh和rsync 各节点时间同步 安装Zookeeper集群 添加Hadoop运行用户 配置主节点登录自己和其他节点不 ...
随机推荐
- jquery的Layer弹出框操作
在layer中,我们要先获取窗口的索引,然后再进行操作. var index = parent.layer.getFrameIndex(window.name); //获取窗口索引 $("# ...
- 用Powershell强制同步Windows主机与Internet time server的时间
第一步,判断Windows Time服务是否正在运行,如果没有,则开启它. 第二步,强制同步,不知为何,往往第一次会失败,那么就多运行几次好了. Get-Service w32time | Where ...
- play framework + sbt入门之环境搭建
一 sbt的使用 SBT = (not so) Simple Build Tool,是scala的构建工具,与java的maven地位相同.其设计宗旨是让简单的项目可以简单的配置,而复杂的项目可以复杂 ...
- 启动Sonar报错,ERROR: [1] bootstrap checks failed [1]: system call filters failed to install
错误提示信息: ERROR: [1] bootstrap checks failed[1]: system call filters failed to install; check the logs ...
- Direct Buffer介绍
Direct Buffer 前言 上篇文章Buffer末尾中谈到堆内Buffer(Heap Buffer)和直接Buffer(Direct Buffer)的概念,但是却一笔带过,并未涉及其细节,这篇文 ...
- SQL server中常用sql语句
--循环执行插入10000条数据 declare @ID intbeginset @ID=1 while @ID<=10000begininsert into table_name values ...
- a属性+DOM创建回流+动画运动+
超链接a的属性 href分析: < a href = " " > 点击刷新页面,相当于向后台发送了一次请求 < a href = " # &quo ...
- vue组件6 使用vue添加样式
class绑定,内联样式 数组语法 :class="[stylename]" js:data{stylename:classname} 对象语法:class={stylena ...
- rem适配移动端
一.屏幕宽度 / 设计稿宽度 *100 来设置根元素的 font-size 10px = 0.10rem (function (doc, win) { var docEl = doc.docume ...
- Java 之 多线程
一.并发与并行 1.并发 指两个或多个事件在同一时间段内发生. 2.并行 指两个或多个事件在同一时刻发生(同时发生). 在操作系统中,安装了多个程序,并发指的是在一段时间内宏观上有多个程序同时运行,这 ...