关于千里马招标网知道创宇反爬虫521状态码的解决方案(python代码模拟js生成cookie _clearence值)
一、问题发现
近期我在做代理池的时候,发现了一种以前没有见过的反爬虫机制。当我用常规的requests.get(url)方法对目标网页进行爬取时,其返回的状态码(status_code)为521,这是一种以前没有见过的状态码。再输出它的爬取内容(text),发现是一些js代码。看来是新问题,我们来探索一下。
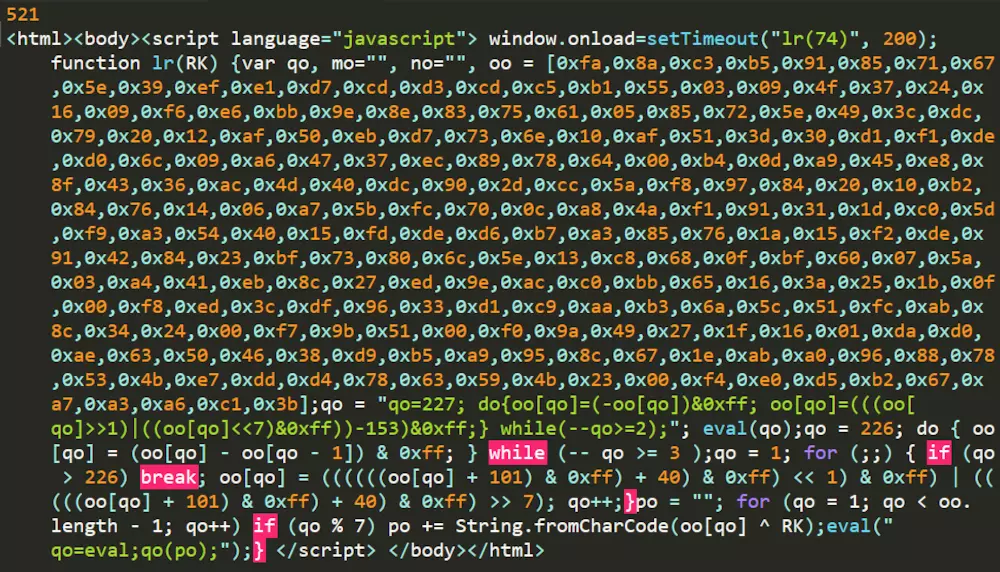
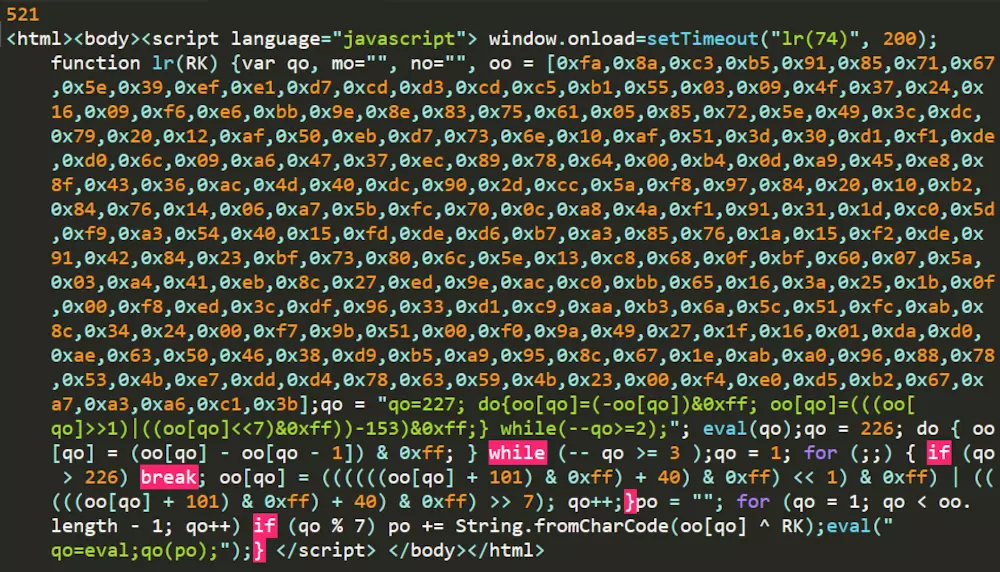
二、原理分析
打开Fiddler,抓取访问网站的包,我们发现浏览器对于同一网页连续访问了两次,第一次的访问状态码为521,第二次为200(正常访问)。看来网页加了反爬虫机制,需要两次访问才可返回正常网页。

下面我们来对比两次请求的区别:
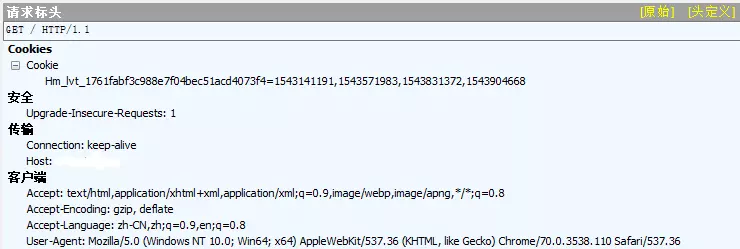
521请求:
200请求:
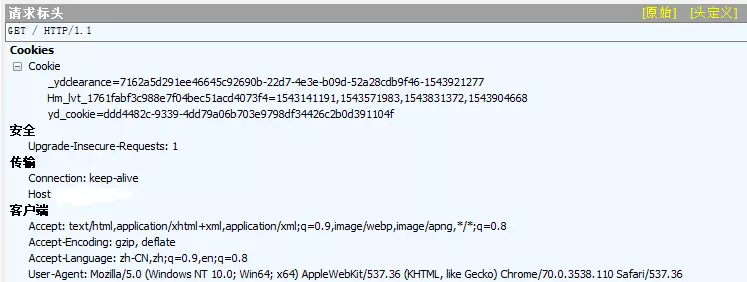
通过对比两次请求头,我们发现第二次访问带了新的cookie值。再考虑上面程序对爬取结果的输出为js代码,可以考虑其操作过程为:第一次访问时服务器返回一段可动态生成cookie值的js代码;浏览器运行js代码生成cookie值,并带cookie重新进行访问;服务器被正常访问,返回页面信息,浏览器渲染加载。
三、解决流程
弄清楚浏览器的执行过程后,我们就可以模拟其行为通过python作网页爬取。操作步骤如下:
用request.get(url)获取js代码
通过正则表达式对代码进行解析,获得JS函数名,JS函数参数和JS函数主体,并将执行函数eval()语句修改为return语句返回cookie值
调用execjs库的executeJS()功能执行js代码获得cookie值
将cookie值转化为字典格式,用request.get(url, cookies = cookie)方法获取得到正确的网页信息
四、代码实现
实现程序所需要用到的库:
import re #实现正则表达式
import execjs #执行js代码
import requests #爬取网页
第一次爬取获得包含js函数的页面信息后,通过正则表达式对代码进行解析,获得JS函数名,JS函数参数和JS函数主体,并将执行函数eval()语句修改为return语句返回cookie值。
# js_html为获得的包含js函数的页面信息
# 提取js函数名
js_func_name = ''.join(re.findall(r'setTimeout\(\"(\D+)\(\d+\)\"', js_html))
# 提取js函数参数
js_func_param = ''.join(re.findall(r'setTimeout\(\"\D+\((\d+)\)\"', js_html))
# 提取js函数主体
js_func = ''.join(re.findall(r'(function .*?)</script>', js_html))
将执行函数eval()语句修改为return语句返回cookie值
# 修改js函数,返回cookie值
js_func = js_func.replace('eval("qo=eval;qo(po);")', 'return po')
调用execjs库的executeJS()功能执行js代码获得cookie值
# 执行js代码的函数,参数为js函数主体,js函数名和js函数参数
def executeJS(js_func, js_func_name, js_func_param):
jscontext = execjs.compile(js_func) # 调用execjs.compile()加载js函数主体内容
func = jscontext.call(js_func_name,js_func_param) # 使用call()通过函数名和参数执行该函数
return func
cookie_str = executeJS(js_func, js_func_name, js_func_param)
将cookie值转化为字典格式
# 将cookie值解析为字典格式,方便后面调用
def parseCookie(string):
string = string.replace("document.cookie='", "")
clearance = string.split(';')[0]
return {clearance.split('=')[0]: clearance.split('=')[1]}
cookie = parseCookie(cookie_str)
获得cookie后,采用带cookie的方式重新进行爬取,即可获得我们需要的网页信息了。
作者:欲摘桃花换酒钱
链接:https://www.jianshu.com/p/37d549a4bf44
来源:简书
关于千里马招标网知道创宇反爬虫521状态码的解决方案(python代码模拟js生成cookie _clearence值)的更多相关文章
- python爬虫遇到状态码304,705
304状态码是什么? 如果客户端发送了一个带条件的GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个304状态码.简单的表达就是:客户端已经 ...
- python爬虫22 | 以后我再讲python「模拟登录」我就是狗
接下来就是 学习python的正确姿势 做爬虫 绕不开模拟登录 为此小帅b给大家支了几招 python爬虫19 | 遇到需要的登录的网站怎么办?用这3招轻松搞定! 有些网站的登录很弱鸡 传个用户名和密 ...
- [Python爬虫]煎蛋网OOXX妹子图爬虫(1)——解密图片地址
之前在鱼C论坛的时候,看到很多人都在用Python写爬虫爬煎蛋网的妹子图,当时我也写过,爬了很多的妹子图片.后来煎蛋网把妹子图的网页改进了,对图片的地址进行了加密,所以论坛里面的人经常有人问怎么请求的 ...
- 配置Nutch模拟浏览器以绕过反爬虫限制
原文链接:http://yangshangchuan.iteye.com/blog/2030741 当我们配置Nutch抓取 http://yangshangchuan.iteye.com 的时候,抓 ...
- Python 爬虫工程师必看,深入解读字体反爬虫
字体反爬虫开篇概述 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人 ...
- seebug的反爬虫技术初探
1.通过request库无法直接爬取,返回521 >>> import requests >>> req = requests.get('https://www.s ...
- 爬虫实例——爬取煎蛋网OOXX频道(反反爬虫——伪装成浏览器)
煎蛋网在反爬虫方面做了不少工作,无法通过正常的方式爬取,比如用下面这段代码爬取无法得到我们想要的源代码. import requests url = 'http://jandan.net/ooxx' ...
- 反反爬虫 IP代理
0x01 前言 一般而言,抓取稍微正规一点的网站,都会有反爬虫的制约.反爬虫主要有以下几种方式: 通过UA判断.这是最低级的判断,一般反爬虫不会用这个做唯一判断,因为反反爬虫非常容易,直接随机UA即可 ...
- 【Python3爬虫】常见反爬虫措施及解决办法(三)
上一篇博客的末尾说到全网代理IP的端口号是经过加密混淆的,而这一篇博客就将告诉你如何破解!如果觉得有用的话,不妨点个推荐哦~ 一.全网代理IP的JS混淆 首先进入全网代理IP,打开开发者工具,点击查看 ...
随机推荐
- 16、Python面向对象进阶
一.对象的继承 Python中支持一个类同时继承多个父类 class Parent1: pass class Parent2: pass class Sub1(Parent1, Parent2): p ...
- JMeter基础【第六篇】JMeter5.1事务、检查点、集合点、思考时间、其余设置等
JMeter5.1事务.检查点.集合点.思考时间.其余设置等
- wordpress列表分页添加Numeric数字分页
wordpress分类页的分页导航默认是上一页下一页,有时我们想让它显示数字分页要如何操作呢?大多数想着是安装一个插件就可以解决了,作为一位喜欢研究的开发者自然就会用代码来实现了,下面随着ytkah一 ...
- 用插件maven-surefire-report-plugin生成html格式测试报告
在默认情况下,执行maven test/maven package/maven install命令时会在target/surefire-reports目录下生成txt和xml格式的输出信息. 其实ma ...
- LeetCode 499. The Maze III
原题链接在这里:https://leetcode.com/problems/the-maze-iii/ 题目: There is a ball in a maze with empty spaces ...
- Python -- 正则表达式 regular expression
正则表达式(regular expression) 根据其英文翻译,re模块 作用:用来匹配字符串. 在Python中,正则表达式是特殊的字符序列,检查一个字符串是否与某种模式匹配. 设计思想:用一 ...
- cogs 997. [東方S2] 射命丸文
二次联通门 : cogs 997. [東方S2] 射命丸文 /* cogs 997. [東方S2] 射命丸文 二维前缀和 枚举每个子矩阵 更新最大值.. 莫名rank1 */ #include < ...
- 牛客网 牛客练习赛4 A.Laptop-二维偏序+离散化+树状数组
A.Laptop 链接:https://ac.nowcoder.com/acm/contest/16/A来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 131072K,其 ...
- shell expect的简单实用
一.在shell脚本中嵌入expect来实现密码输入 expect是一个自动交互功能的工具.expect是开了一个子进程,通过spawn来执行shell脚本,监测到脚本的返回结果,通过expect判断 ...
- vue-router踩坑日记Unknown custom element router-view
今天笔者在研究vue-router的时候踩到了一个小坑,这个坑是这样的 笔者的具体代码如下:router.js import Home from '@/components/Home.vue'; im ...