爬虫探索Chromedriver+Selenium初试
今天分享Python使用Chromedriver+Selenium爬虫的的方法,Chromedriver是一个有意思的爬虫插件,这个插件的爬虫方式主要是完全模拟浏览器点击页面,一步一步去找你要的东西,就跟个机器一样,不停的去执行命令。主要用于爬一些网站的反爬虫做的很好,自己又很想爬去里面的数据,那就可以用这个插件,
1. Selenium的安装
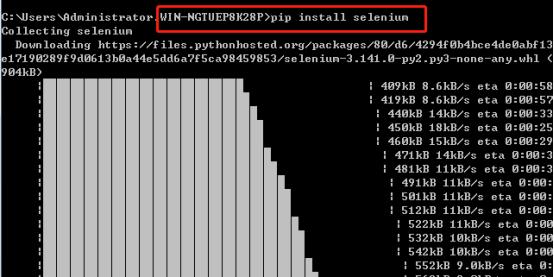
Selenium安装直接采用pip安装最为简便,即打开cmd,输入pip install selenium 安装成功如下:

2. Chromedriver安装
Chromedriver下载前需要先下载了google浏览器
Chromedriver下载地址:http://chromedriver.storage.googleapis.com/index.html
Chromedriver版本对应支持的Chrome版本如下表:
|
chromedriver版本 |
支持的Chrome版本 |
|
v2.43 |
v69-71 |
|
v2.42 |
v68-70 |
|
v2.41 |
v67-69 |
|
v2.40 |
v66-68 |
|
v2.39 |
v66-68 |
|
v2.38 |
v65-67 |
|
v2.37 |
v64-66 |
|
v2.36 |
v63-65 |
|
v2.35 |
v62-64 |
|
v2.34 |
v61-63 |
|
v2.33 |
v60-62 |
|
v2.32 |
v59-61 |
|
v2.31 |
v58-60 |
|
v2.30 |
v58-60 |
|
v2.29 |
v56-58 |
|
v2.28 |
v55-57 |
|
v2.27 |
v54-56 |
|
v2.26 |
v53-55 |
|
v2.25 |
v53-55 |
|
v2.24 |
v52-54 |
|
v2.23 |
v51-53 |
|
v2.22 |
v49-52 |
|
v2.21 |
v46-50 |
|
v2.20 |
v43-48 |
|
v2.19 |
v43-47 |
|
v2.18 |
v43-46 |
|
v2.17 |
v42-43 |
|
v2.13 |
v42-45 |
|
v2.15 |
v40-43 |
|
v2.14 |
v39-42 |
|
v2.13 |
v38-41 |
|
v2.12 |
v36-40 |
|
v2.11 |
v36-40 |
|
v2.10 |
v33-36 |
|
v2.9 |
v31-34 |
|
v2.8 |
v30-33 |
|
v2.7 |
v30-33 |
|
v2.6 |
v29-32 |
|
v2.5 |
v29-32 |
|
v2.4 |
v29-32 |
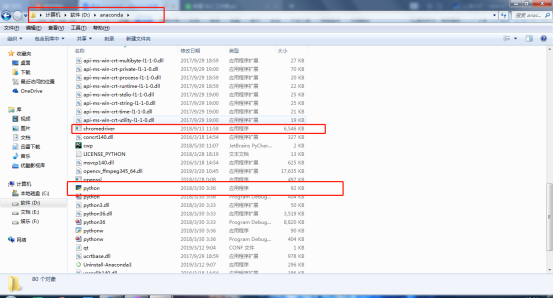
注意:解压好的Chromedriver需放在Python的安装路径下。我的Python路径在D:\anaconda中,以我的为例:
3. 测试
用一段Python代码检测Chromedriver+Selenium安装是否成功。在Pycharm编辑以下Python代码,运行下面代码,会自动打开浏览器,然后访问网页。

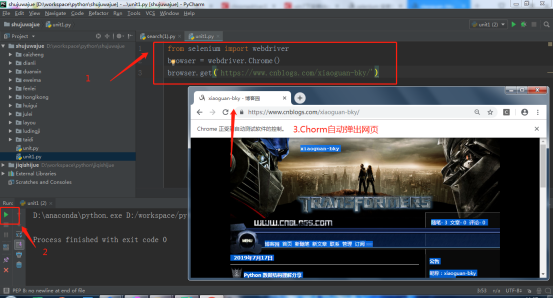
注意:建议运行代码时关闭360,金山等软件。
爬虫探索Chromedriver+Selenium初试的更多相关文章
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- 爬虫----爬虫请求库selenium
一 介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作, ...
- scrapy爬虫框架和selenium的配合使用
scrapy框架的请求流程 scrapy框架? Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架.因此Scrapy使用了一种非阻塞(又名异步)的 ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- # Python3微博爬虫[requests+pyquery+selenium+mongodb]
目录 Python3微博爬虫[requests+pyquery+selenium+mongodb] 主要技术 站点分析 程序流程图 编程实现 数据库选择 代理IP测试 模拟登录 获取用户详细信息 获取 ...
- 爬虫进阶之Selenium和chromedriver,动态网页(Ajax)数据抓取
什么是Ajax: Ajax(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新.这意 ...
- C#爬虫之通过Selenium获取浏览器请求响应结果
前言 在进行某些爬虫任务的时候,我们经常会遇到仅用Http协议难以攻破的情况,比如协议中带有加密参数,破解需要花费大量时间,那这时候就会用Selenium去模拟浏览器进行页面上的元素抓取 大多数情况下 ...
- python3[爬虫实战] 使用selenium,xpath爬取京东手机
使用selenium ,可能感觉用的并不是很深刻吧,可能是用scrapy用多了的缘故吧.不过selenium确实强大,很多反爬虫的都可以用selenium来解决掉吧. 思路: 入口: 关键字搜索入口 ...
- 爬虫基础(三)-----selenium模块应用程序
摆脱穷人思维 <三> : 培养"目标导向"的思维: 好项目永远比钱少,只要目标正确,钱总有办法解决. 一 selenium模块 什么是selenium?seleni ...
随机推荐
- ubuntu之路——day11.6 多任务学习
在迁移学习transfer learning中,你的步骤是串行的sequential process 在多任务学习multi-task learning中,你试图让单个神经网络同时做几件事情,然后这里 ...
- fdconnection自动重连
fdconnection自动重连 1)设置 FDConnection1.ResourceOptions.AutoReconnect := True; 控制自动连接的恢复. 使用AutoReconnec ...
- Spark(五十):使用JvisualVM监控Spark Executor JVM
引导 Windows环境下JvisulaVM一般存在于安装了JDK的目录${JAVA_HOME}/bin/JvisualVM.exe,它支持(本地和远程)jstatd和JMX两种方式连接远程JVM. ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
- adc0和adc1
1 单片机里ADC是数模转换器:功能就是将模拟信号(电压0-5V)转换成数字信号 可以转换成8位数字量(即00H~FFH)也可以转换成10位.12位.16位的数字量.转换后的数字量与模拟量在数值上成正 ...
- git 删除远程和本地分支
RenGuoQiang@PC-RENGUOQIANG MINGW64 /d/zgg/zgg-crm (dev-rgq-userworkstatus) $ git push origin --delet ...
- Springmvc & Report: FineReport vs BIRT vs Jasperreport
Springmvc与jasperreport结合生成报表的一种方法 - OneThin的个人空间 - OSCHINAhttps://my.oschina.net/onethin/blog/14360 ...
- postgresql 臭氧8小时聚合函数
1.定义数据拼接函数 CREATE OR REPLACE FUNCTION "public"."sfun"("results" _numer ...
- ROS tf基础使用知识
博客参考:https://www.ncnynl.com/archives/201702/1306.html ROS与C++入门教程-tf-坐标变换 说明: 介绍在c++实现TF的坐标变换 概念: Co ...
- glib 检索地址
http://ftp.acc.umu.se/pub/GNOME/sources/glib/