scrapy+splash 爬取京东动态商品
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
splash是容器安装的,从docker官网上下载windows下的docker进行安装。
下载完成之后直接点击安装,安装成功后,桌边会出现三个图标:

点击 Docker QuickStart 图标来启动 Docker Toolbox 终端。
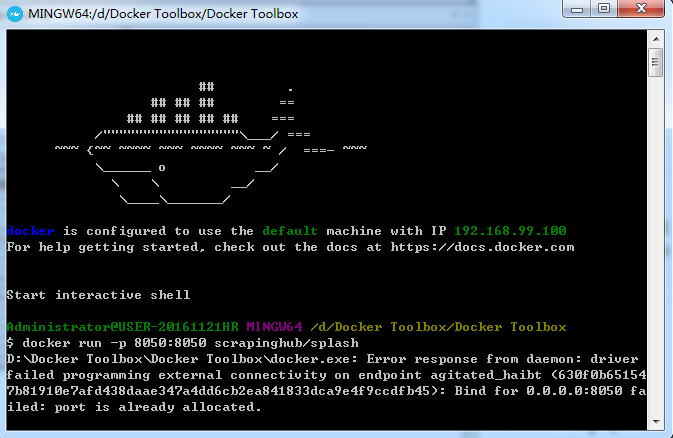
使用docker启动服务命令启动Splash服务
docker run -p 8050:8050 scrapinghub/splash
这里我已经开启服务了打开cmd,在当前目录下开始scrapy爬虫:
scrapy startproject scrapy_examples
在spider文件夹中新建python文件jd_book.py用于编写爬虫
在项目下新建pybook.py用于对数据文件csv处理
京东上的商品是动态加载的,爬取python书籍的前20页,获取每个商品的评论数、书名、简介。
SplashRequest(url,endpoint='execute',args={'lua_source':lua_script},cache_args=['lua_source'])请求页面并执行JS函数渲染页面
endpoint='execute':在页面中执行一些用户自定义的JavaScript代码
args={'lua_source':lua_script}:用户自定义的lua脚本
cache_args=['lua_source']:让Splash服务器缓存该函数
用户自定义的lua脚本中必须包含一个main函数作为程序入口,main函数被调用时会传入一个splash对象(lua中的对象),用户可以调用该对象上的方法操纵Splash。
splash.args属性:用户传入参数的表,通过该属性可以访问用户传入的参数
splash:go方法:类似于在浏览器中打开某url地址的页面,页面所需资源会被加载,并进行JavaScript渲染
splash:wait方法:等待页面渲染,time参数为等待的秒数
splash:runjs方法:在当前页面下,执行一段JavaScript代码
splash:html方法:splash:html()获取当前页面的HTML文本。
middlewares.py随机产生User-Agent添加到每个请求头中
pipelines.py处理爬取的数据并存入数据库
settings.py配置splash服务信息、设置请求延迟反爬虫、添加数据库信息
# -*- coding:utf-8 -*-
import scrapy
from scrapy import Request
from scrapy_splash import SplashRequest
from splash_examples.items import PyBooksItem lua_script ='''
function main(splash)
splash:go(splash.args.url)
splash:wait(2)
splash:runjs("document.getElementsByClassName('pn-next')[0].scrollIntoView(true)")
splash:wait(2)
return splash.html()
end
'''
class JDBookSpider(scrapy.Spider):
name = "jd_book"
allowed_domains = ['search.jd.com']
base_url = 'https://search.jd.com/Search?keyword=python&enc=utf-8&wq=python'
def start_requests(self):
yield Request(self.base_url,callback=self.parse_urls,dont_filter=True)
def parse_urls(self,response):
for i in range(20):
url = '%s&page=%s' % (self.base_url,2*i+1)
yield SplashRequest(url,
endpoint='execute',
args={'lua_source':lua_script},
cache_args=['lua_source'])
def parse(self, response):
for sel in response.css('ul.gl-warp.clearfix>li.gl-item'):
pyjdbooks = PyBooksItem()
pyjdbooks['name'] = sel.css('div.p-name').xpath('string(.//em)').extract_first()
pyjdbooks['comment']=sel.css('div.p-commit').xpath('string(.//a)').extract_first()
pyjdbooks['promo_words']=sel.css('div.p-name').xpath('string(.//i)').extract_first()
yield pyjdbooks
jd_book.py
import scrapy class PyBooksItem(scrapy.Item):
name=scrapy.Field()
comment=scrapy.Field()
promo_words=scrapy.Field()
items.py
from fake_useragent import UserAgent
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
request.headers.setdefault("User-Agent", UserAgent().random)
middlewares.py
class SplashExamplesPipeline(object):
def __init__(self):
self.book_set = set() def process_item(self, item, spider):
if not(item['promo_words']):
item['promo_words'] = item['name']
comment = item['comment']
if comment[-2:] == "万+":
item['comment'] = str(int(float(comment[:-2])*10000))
elif comment[-1] == '+':
item['comment'] = comment[:-1]
return item import pymysql class MysqlPipeline(object):
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port @classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
) def open_spider(self, spider):
self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8', port=self.port)
self.cursor = self.db.cursor() def close_spider(self, spider):
self.db.close() def process_item(self, item, spider):
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'insert into books (%s) values (%s)' % (keys, values)
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
pipelines.py
BOT_NAME = 'splash_examples' SPIDER_MODULES = ['splash_examples.spiders']
NEWSPIDER_MODULE = 'splash_examples.spiders' #Splash服务器地址
SPLASH_URL = 'http://192.168.99.100:8050' #开启Splash的两个下载中间件并调整HttpCompressionMiddleware的次序
DOWNLOADER_MIDDLEWARES = {
'splash_examples.middlewares.RandomUserAgent':345,
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
#设置去重过滤器
DUPEFILTER_CLASS='scrapy_splash.SplashAwareDupeFilter' #用来支持cache_args
SPIDER_MIDDLEWARES ={
'scrapy_splash.SplashDeduplicateArgsMiddleware':100,
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' # Obey robots.txt rules
ROBOTSTXT_OBEY = False COOKIES_ENABLED = False
DOWNLOAD_DELAY = 3 ITEM_PIPELINES = {
'splash_examples.pipelines.SplashExamplesPipeline':400,
'splash_examples.pipelines.MysqlPipeline':543,
} MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'pybooks'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'root'
settings.py
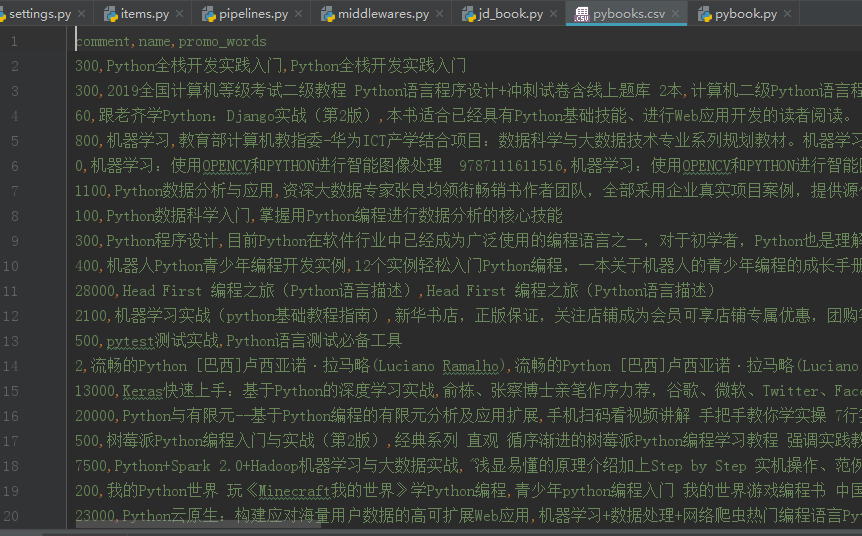
在Terminal中执行爬虫:scrapy crawl jd_book -o pybooks.csv
将数据存储到数据库并生成csv文件用于分析可视化
在数据库中查看有1187条信息

做数据分析可视化
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
obj = pd.read_csv('pybooks.csv')
Books = obj.sort_values('comment',ascending=False)[:200]
promoWords = []
for promo in Books['promo_words']:
promoWords.append(promo)
promoWordsStr = ''.join(promoWords)
bookTxt = jieba.lcut(promoWordsStr)
stopwords = ['学习','入门','掌握','教程','图书','使用','全面','推荐','读者','专家']
bookTxt = [token for token in bookTxt if token not in stopwords]
bookTxtSet = set(bookTxt)
txtCount = {}
for i in bookTxtSet:
if len(i) == 1:
continue
txtCount[i] = bookTxt.count(i)
txtCount = sorted(txtCount.items(),key=lambda key:key[1],reverse=True)
TxtStr = ' '.join(bookTxt)
ciyun = WordCloud(background_color = '#122',width=400,height=300,margin = 1).generate(TxtStr)
plt.imshow(ciyun)
plt.axis("off")
plt.show()
print(txtCount)
pybook.py

scrapy+splash 爬取京东动态商品的更多相关文章
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- JS+Selenium+excel追加写入,使用python成功爬取京东任何商品~
之前一直是requests库做爬虫,这次尝试下使用selenium做爬虫,效率不高,但是却没有限制,文章是分别结合大牛的selenium爬虫以及excel追加写入操作而成,还有待优化,打算爬取更多信息 ...
- python利用urllib实现的爬取京东网站商品图片的爬虫
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -* ...
- 毕设二:python 爬取京东的商品评论
# -*- coding: utf-8 -*- # @author: Tele # @Time : 2019/04/14 下午 3:48 # 多线程版 import time import reque ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
- Scrapy实战篇(七)之Scrapy配合Selenium爬取京东商城信息(下)
之前我们使用了selenium加Firefox作为下载中间件来实现爬取京东的商品信息.但是在大规模的爬取的时候,Firefox消耗资源比较多,因此我们希望换一种资源消耗更小的方法来爬取相关的信息. 下 ...
- scrapy爬取京东iPhone11评论(一)
咨询行业中经常接触到文本类信息,无论是分词做词云图,还是整理编码分析用,都非常具有价值. 本文将记录使用scrapy框架爬取京东IPhone11评论的过程,由于一边学习一边实践,更新稍慢请见谅. 1. ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
随机推荐
- 学习笔记之DBeaver
DBeaver Community | Free Universal Database Tool https://dbeaver.io/ Universal Database Tool Free mu ...
- ES6 新增集合----- Set 和Map
Sets 和数组一样,都是一些有序值的的集合,但是Sets 和数组又有所不同,首先Sets 集合中不能存有相同的值,如果你向Sets 添加重复的值,它会忽略掉, 其次Sets 集合的作用也有所不同,它 ...
- Google 浏览器保存mht网页文件(单个网页)的方法(无需插件)
1.找到设置打开单个网页保存的地方 在google浏览器地址栏输入:chrome://flags”,回车 2.实现保存单个网页 打开你要保存的网页后,只需 Ctrl+s ,搞定!如下: 假设找到了一篇 ...
- windows环境下安装mysql5.7.20
配置my.ini文件 [client] port=3306 default-character-set=utf8 [mysqld] # 设置为自己MYSQL的安装目录 basedir=D:\Progr ...
- 11g包dbms_parallel_execute在海量数据处理过程中的应用
11g包dbms_parallel_execute在海量数据处理过程中的应用 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也 ...
- termux 为 python3 添加 numpy 库
1 本机环境 Termux v0.77 python3.8 2 配置步骤 2.1 安装 python 和 ipython apt updateapt upgradepkg install python ...
- Navicat Premium 12破解激活11
下载Navicat Premium 12并安装: 百度云下载:Navicat Premium 12注册机 链接:https://pan.baidu.com/s/1UcA5yXjtdfXlBZI-2 ...
- poj1734 Sightseeing trip(Floyd求无向图最小环)
#include <iostream> #include <cstring> #include <cstdio> #include <algorithm> ...
- 《Java设计模式》之代理模式 -Java动态代理(InvocationHandler) -简单实现
如题 代理模式是对象的结构模式.代理模式给某一个对象提供一个代理对象,并由代理对象控制对原对象的引用. 代理模式可细分为如下, 本文不做多余解释 远程代理 虚拟代理 缓冲代理 保护代理 借鉴文章 ht ...
- ARTS-week5
Algorithm 给定两个有序整数数组 nums1 和 nums2,将 nums2 合并到 nums1 中,使得 num1 成为一个有序数组.说明:初始化 nums1 和 nums2 的元素数量分别 ...