Ceph添加、删除osd及故障硬盘更换
添加或删除osd均在ceph部署节点的cent用户下的ceph目录进行。
1. 添加osd
当前ceph集群中有如下osd,现在准备新添加osd:
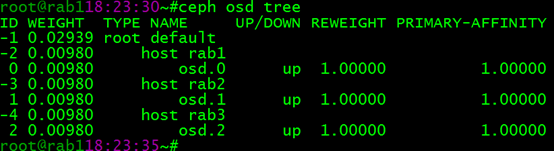
(1)选择一个osd节点,添加好新的硬盘:
(2)显示osd节点中的硬盘,并重置新的osd硬盘:
列出节点磁盘:
ceph-deploy disk list rab1
擦净节点磁盘:
ceph-deploy disk zap rab1 /dev/sbd(或者)ceph-deploy disk zap rab1:/dev/vdb1
(3)准备Object Storage Daemon:
ceph-deploy osd prepare rab1:/var/lib/ceph/osd1
(4)激活Object Storage Daemon:
ceph-deploy osd activate rab1:/var/lib/ceph/osd1
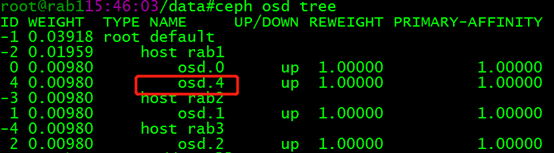
2. 删除osd
现在要将 rab1中的 osd.4 删除:
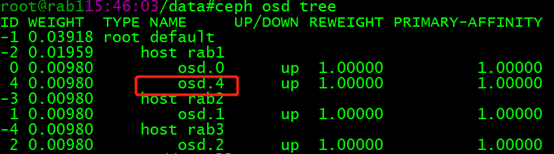
(1)把 OSD 踢出集群
ceph osd out osd.
(2)在相应的节点,停止ceph-osd服务
systemctl stop ceph-osd@.service
systemctl disable ceph-osd@.service

(3)删除 CRUSH 图的对应 OSD 条目,它就不再接收数据了
ceph osd crush remove osd.4

(4)删除 OSD 认证密钥
ceph auth del osd.
(5)删除osd.4
ceph osd rm osd.
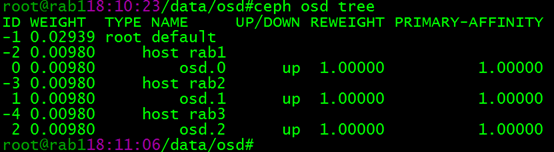
3. ceph osd故障硬盘更换
正常状态:
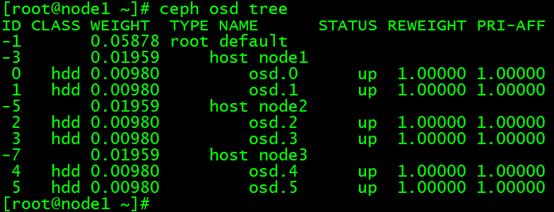
故障状态:


实施更换步骤:
(1)关闭ceph集群数据迁移:
osd硬盘故障,状态变为down。在经过mod osd down out interval 设定的时间间隔后,ceph将其标记为out,并开始进行数据迁移恢复。为了降低ceph进行数据恢复或scrub等操作对性能的影响,可以先将其暂时关闭,待硬盘更换完成且osd恢复后再开启:
for i in noout nobackfill norecover noscrub nodeep-scrub;do ceph osd set $i;done
(2)定位故障osd
ceph osd tree | grep -i down
(3)进入osd故障的节点,卸载osd挂载目录
[root@node3 ~]# umount /var/lib/ceph/osd/ceph-
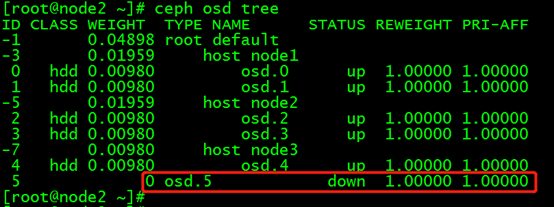
(4)从crush map 中移除osd
[root@node1 ~]# ceph osd crush remove osd.
removed item id name 'osd.5' from crush map
(5)删除故障osd的密钥
[root@node1 ~]# ceph auth del osd.
updated
(6)删除故障osd
[root@node1 ~]# ceph osd rm
removed osd.

(7)更换完新硬盘后,注意新硬盘的盘符,并创建osd
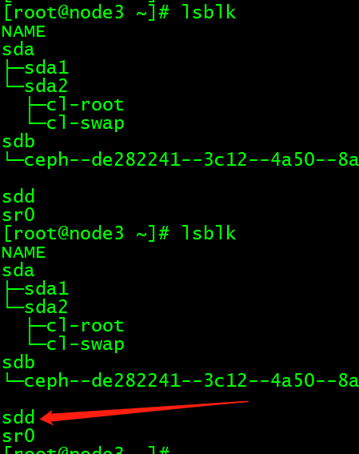
(8)在部署节点,切换为cent用户,添加新的osd
[cent@deploy ceph]$ ceph-deploy osd create --data /dev/sdd node3

(9)待新osd添加crush map后,重新开启集群禁用标志
for i in noout nobackfill norecover noscrub nodeep-scrub;do ceph osd unset $i;done
ceph集群经过一段时间的数据迁移后,恢复active+clean状态
Ceph添加、删除osd及故障硬盘更换的更多相关文章
- 分布式存储ceph——(4)ceph 添加/删除osd
一.添加osd: 当前ceph集群中有如下osd,现在准备新添加osd:
- ceph添加/删除OSD
一.添加osd: 当前ceph集群中有如下osd,现在准备新添加osd: (1)选择一个osd节点,添加好新的硬盘: (2)显示osd节点中的硬盘,并重置新的osd硬盘: 列出节点磁盘:ceph-de ...
- 分布式存储ceph——(5)ceph osd故障硬盘更换
正常状态:
- Ceph osd故障硬盘更换
正常状态: 故障状态: 实施更换步骤: (1)关闭ceph集群数据迁移: osd硬盘故障,状态变为down.在经过mod osd down out interval 设定的时间间隔后,ceph将其标记 ...
- 分布式存储ceph---ceph osd 故障硬盘更换(6)
正常状态: 故障状态: 实施更换步骤: 1.关闭ceph集群数据迁移: osd硬盘故障,状态变为down.在经过mod osd down out interval 设定的时间间隔后,ceph将其标记为 ...
- 分布式存储ceph--osd故障硬盘更换(6)
正常状态:
- 分布式存储ceph---ceph添加/删除osd(5)
一.添加osd 当前ceph集群中有如下osd,现在准备新添加osd: 1.选择一个osd节点,添加好新的硬盘: 2.显示osd节点中的硬盘,并重置新的osd硬盘: 列出节点磁盘:ceph-deplo ...
- Ceph添加/删除Mon(ceph.conf)
操作环境 ceph 0.87.7 Openstack liberty ubuntu 14.04 当前ceph配置文件如下 [global]fsid = c010eb34-ccc6-458d-9a03- ...
- UNIX故障--sun m4000服务器故障硬盘更换案例
一.故障诊断 查看messages日志c0d0t0这块盘不断报错,类型为:retryable,如下: root@gdhx # more /var/adm/messages Aug 5 16:43:0 ...
随机推荐
- 上传下载execl
ajax上传execl + easyexecl解析execl <!DOCTYPE html> <html> <head> <meta charset=&quo ...
- MySQL报错Packet for query is too large问题解决
今天用java写了批量插入运行时,报错: Error updating database. Cause: com.mysql.cj.jdbc.exceptions.PacketTooBigExcep ...
- 无限用teamviewer的一种方法,虚拟机中装teamviewer
可以使用window 多用户可以同时远程登陆的特性(win服务器版自动支持多用户同时远程登陆,非服务器版需要其他方法开启) 1.在window建立两个用户,如a,b. 2安装虚拟机vmware,安装操 ...
- spark 更改日志输出级别
package com.ideal.test import org.apache.spark.{SparkConf, SparkContext} import org.apache.log4j.{Le ...
- 晶体管放大电路与Multisim仿真学习笔记
前言 开始写点博客记录学习的点滴,第一篇就写基本的共射极放大电路吧. 很多教材都是偏重理论,而铃木雅臣著作的<晶体管电路设计>是一本很实用的书籍,个人十分推荐! 下面开始我的模电重温之旅吧 ...
- Install Teamviewer on 14.04? [repost]
Ref: http://askubuntu.com/questions/453157/how-to-install-teamviewer-on-14-04 TeamViewer 是一款优秀的跨平台免费 ...
- Asp Core部署到IIS服务器
之前有文章写了.Asp Core Kestrel服务器可以独立运行在linux下,也可以部署到Docker上面通过容器管理,当然也可以直接部署到IIS中 一:安装环境 1)首先需要在服务器安装对应环境 ...
- webbench网站测压工具源码分析
/* * (C) Radim Kolar 1997-2004 * This is free software, see GNU Public License version 2 for * detai ...
- 第1课,python输出,输入,变量,运算
课程内容: 为什么要学习python 如何学python 实践体验 图片来源网络分享 为什么要学python: 简单 (设计如此) 强大(因为开源,有库) 如何学习python: 变量 --> ...
- 嵌入式web服务器BOA+CGI+HTML+MySQL项目实战——Linux
准备环境操作系统: Ubuntu12.04 LTS环境搭建: 需要 BOA,Apache,CCGI,MySQL,GCC[Linux下嵌入式Web服务器BOA和CGI编程开发][数据库的相关知识——学习 ...