Redis五大数据类型详解
关于Redis的五大数据类型,它们分别为:String、List、Hash、Set、SortSet。本文将会从它的底层数据结构、常用操作命令、一些特点和实际应用这几个方面进行解析。对于数据结构的解析,本文只会从大的方面来解析,不会介绍详细的代码实现。
String
1.实现结构
String是Redis中最常用的一种数据类型,也是Redis中最简单的一种数据类型。首先,表面上它是字符串,但其实他可以灵活的表示字符串、整数、浮点数3种值。Redis会自动的识别这3种值。那么,String的底层数据机构又是怎样的呢?由于Redis是使用c语言实现的,而c语言中没有String这一数据类型,那么就需要自己实现一个类似于String的结构体。它的名字就叫做SDS(simple dynamic string),下面是它的代码结构。
typedef struct sdshdr {
// buf中已经占用的字符长度
unsigned int len;
// buf中剩余可用的字符长度
unsigned int free;
// 数据空间
char buf[];
}
如果有了解过Java集合框架类的朋友都知道,这种结构与集合中动态数组结构类似,那么就会涉及到一系列的扩容判断和操作,但这些具体的做法在这里不深入讲解。不过有一点比较重要的就是String的value值最大可以存放512MB的数据,所以有时候它不仅仅可以存放字符,还可以存放字节数据。
2.实际应用
在讲实际应用之前,要声明的是Redis是基于单线程IO多路复用的架构实现的NoSql,意味着它的操作都是串行化的,所以在命令操作上不会出现线程安全问题,基于这个特性可以有很多应用。
- 分布式锁。利用Redis的串行化特性,可以轻松的实现分布式锁,其中用到的命令有:setnx key value , expire key time ,del key ,其中第一个setnx是指在key不存在时能赋值成功,expire 来设置key的存活时间来防止程序异常而没有及时del到key值的情况。但是程序也有可能在expire没有执行时就已经挂掉的时候,这是可以来一个增强版set key value NX EX time。这里的NX就是表示if not exist,而Ex表示时间单位秒,Px代表毫秒。
- 分布式session。这里仅仅是利用Redis的数据库功能,把分布式应用的session抽取到Redis中,普通的get、set,命令即可完成。
- 商品秒杀实现。把需要销售的商品提前放入Redis,通过redis的incr和decr命令安全的增加和减少库存。
- 限时验证。 expire key time ,判断exists key在短信验证时,当redis中存在数据则不允许再次请求验证发送。
List
1.实现结构
首先,List的主要存取操作有lpush、lpop、rpush、rpop,有点像是双向队列。List的实现是灵活多样的,它分别有ziplist(压缩链表)、LinkedList(双向链表)两种实现方式。
1.ziplist
如下图所示,它是基于连续内存实现(类似数组)。当然,它的每一个entry的大小可能不是一致的,这就需要特殊的控制手段去解决,所以才叫压缩表。那么数组有的特性它都会有,比如在lpush、lpop的时候就会有数据的搬移,时间复杂度是O(n)。所以,一般在数据元素较少时使用ziplist结构实现。
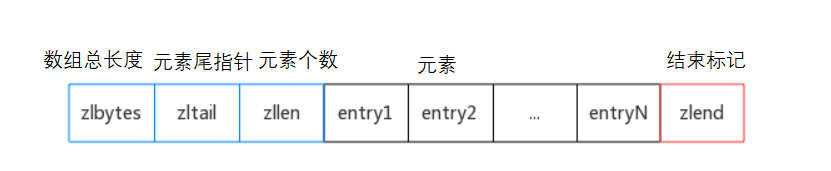
2.LinkedList
则与我们日常所学的双向链表相差无异,同样也保留则头尾指针、数据长度等数据,这里就不再详细说明,需要了解的去读一读Java的LInkedList源码也不错。
2.实际应用
- 消息队列。使用lpush,brpop两个命令可以模拟一个消息队列。其中brpop key time为阻塞式弹出,当队列中为空时会阻塞当前操作,该操作需要添加超时参数,单位为秒。
- 有限集合。使用ltrim key start end操作可以获取一个固定位置的数据,可以快速实现一个有限的集合。
Hash
1.实现结构
首先,Hash的特性我们可以想象为Java集合中的HashMap,一个hash中可以有多个field:value(键值对)。关于hash的实现同样有两种情况。一种是基于ZipList,一种是基于HashTable实现。
1.ZipList
这里的的ZipList与List当中的ZipList其实是相差无几的,唯一的特点就是Hash存储的时候,它的entry数量是成对增加的,同时也是成对存在的,所以它的长度一定是2的整数倍。filed值放在前面,value放在后面的形式存放。当然采用ZipList操作时,它的查找删改查的时间复杂度就会变为O(n),所以ZipList适合在数据较少的情况下使用。
2.HashTable
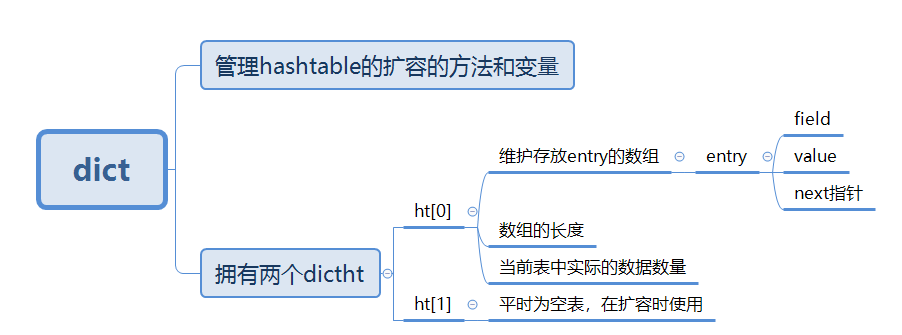
虽然说Hash与Java中的HashMap功能类似,但在HashTable这个结构上还是有一定的不同点的。要想了解HashTable的实现,需要了解三个结构。它们分别是:dict、dictht、entry。entry和前面list中提到的类似,下面列出前面两个结构的定义:
// 哈希表(字典)数据结构,Redis 的所有键值对都会存储在这里。其中包含两个哈希表。
typedef struct dict {
// 哈希表的类型,包括哈希函数,比较函数,键值的内存释放函数
dictType *type;
// 存储一些额外的数据
void *privdata;
// 两个哈希表
dictht ht[];
// 哈希表重置下标,指定的是哈希数组的数组下标
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 绑定到哈希表的迭代器个数
int iterators; /* number of iterators currently running */
} dict; typedef struct dictht {
//槽位数组
dictEntry **table;
//槽位数组长度
unsigned long size;
//用于计算索引的掩码,可以理解为hash函数
unsigned long sizemask;
//真正存储的键值对数量
unsigned long used;
} dictht;
关系可以总结为下面这幅图:
2.实际应用
- 存放对象Object。你可能会发现,从宏观上来说,这种一个key , field1 : value1 ,field2 : value2 一个键值对应多个字段field的格式非常适合用于描写一个对象。所以,hash一般会用于描述一个对象,但其实我们在实际中也有可能会用一个Json格式的字符串来描述一个对象。那么这两种方法都可行的情况下,会有什么优缺点呢?利用hash描述一个对象:可以做到序列化开销小,可以单独修改某一个字段而不用读出全部数据,但是使用比较复杂。而使用json描述对象,使用简单但需要耗费额外的序列化开销。需要使用什么形式,具体情况需要具体分析。
- 结合Json描述对象的集合。例如,在商城应用中,可以利用Hash的key来描述一个用户的id,而field用于描述用户的购物车列表中的一个物品的详细信息。
Set
Set是一个不允许重复的,无顺序的数据集合。值得注意的是,这里说的无顺序其实还是有一点歧义的,那么到底是怎么回事呢?接下来的博文就会有提到这个差异。
1.实现结构
1.IntSet。
这里的IntSet是一种在满足特定情况下所使用的数据结构。这种情况就是当全部value都为整型时,redis会使用IntSet这种结构。在这个情况下它是有序的。这是为什么呢?先从结构开始说起,为了平衡空间的性能的消耗,Redis在数据都为整型的时候使用了一种基于动态数组的结构体,同时在存放元素时保正元素的大小顺序,这样就可以使用二分查找以时间复杂度O(logn)来完成增删改查的操作。这样就节省了很多空间。至于增和删操作,同样会涉及到数组的数据搬移操作。下面为它的结构体代码:
typedef struct intset {
// 编码方式
uint32_t enconding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
2.HashTable
当存在非整型数据的时候,Redis会自动把IntSet转换为HashTable的结构存放数据,但HashTable不能转换为IntSet。这里的HashTable与上面Hash结构提到的HashTable没有太大的差别。唯一的差别就在于Set存放在HashTable中只有Key值,没有value值,所以在HashTable的Entry中,Enrty的value永远为null。
2.实际应用
- 记录唯一的事物。如ip值,身份证等。
- 随机用户抽奖。通过srandmember key 随机返回一个set中的数据。
- 用户标签。当用户在使用某个产品的时候,后台可能会记录该用户对某个东西的喜好,从而在该标签中记录该用户。同时,可以利用sinter key1 key2、sunion、sdiff返回标签中的交集、并集、差集。这样就可以轻松得出用户的共同喜好、所有喜好、非共同喜好等数据。
SortSet
SortSet是一个实现了数据有序且唯一的键值对集合。其中,Entry的键为string类型,值为整型或浮点型,表示权值score。其中SortSet的顺序就是通过Score的值来确定的。
1.实现结构
SortSet的实现结构同样有两种,一种是ZipList结构实现,适用于较少数据的情况。另一种是SkipList+HashTable的形式,使用与数据较多的情况,其中SkipList是在保证有序的情况下优化范围查找的时间复杂度,而HashTable则是优化增删改查的时间复杂度。
1.ZipList
SortSet的ZipList和Hash中的数据结构类似,同样也是存放键值对,但是它维护了基于Score的有序性(默认从小到大),这里就不再赘述。
2.SkipList+HashTable
首先来说明主要的SkipList(跳表),跳表是一种基于有序链表,通过建立多层索引,以空间换时间的方式实现平均查找效率为O(logn)复杂度的一种数据结构。下面给出一个跳表的基本形式图:

可以看到在根据数据的权值Score进行查找的时候,从最顶层的索引开始查找。当找到数据在某个范围后,在往下一层的索引查找,然后就这样一路缩小查找的范围。看上去是不是有点像二分查找?至于跳表的具体介绍和实现,可以参考这篇文章:为什么Redis要用跳表实现有序集合?
上面可以看到,基于跳表的实现的有序集合可以完成增删改查实现O(logn)的时间复杂度,那么有没有更加快的方式来实现O(1)的时间复杂度呢?通常说起O(1)的时间复杂度都会想起HashTable这个数据结构。Redis就利用HashTable+SkipList的组合数据结构,HashTable来实现增删改查的时间复杂度为O(1)的同时SkipList保证数据的有序性,可以方便的获取一个范围的数据。
至于HashTable的实现与前面谈到的一致,下面用一张图来说明两个数据结构结合是什么样子的。
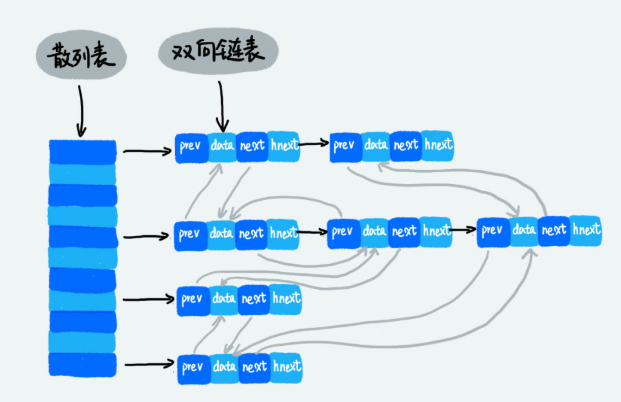
上图中,每一个节点可以看成一个跳表的节点同时也是HashTable中的一个节点。
- 在看跳表的时候,我们需要忽略hnext指针,每个节点通过双向链表来保证有序性。
- 在看HashTable的时候,可以忽略prev指针和next指针。看上去就是一个用拉链法解决冲突的HashTable,而hnext就是指向下一节点的指针。
这样,当我们需要增删改查的时候,利用HashTable的特性实现时间复杂度为1的操作,当我们需要基于权值Score进行范围查找的时候可以通过SkipList进行时间复杂度为O(logn)的查找。
2.实际应用
- 排行榜。使用zrange key start end。根据热度、积分、评论等可以衡量的权值Score进行排行,其中score排序为从小到大,用ZREVRANGE实现从大到小排序。
- 获取某个权值范围的用户。例如在应用中获取积分为80到100的用户,可以使用ZRANGEBYSCORE key 80 100 WITHSCORES来输出score在80到100间的用户。
总结
太多东西记不住?来张思维导图帮你记忆一下。

Redis五大数据类型详解的更多相关文章
- Redis扩展数据类型详解
在Redis中有5种基本数据类型,分别是String, List, Hash, Set, Zset.除此之外,Redis中还有一些实用性很高的扩展数据类型,下面来介绍一下这些扩展数据类型以及它们的使用 ...
- redis入门到精通系列(七):redis高级数据类型详解(BitMaps,HyperLogLog,GEO)
高级数据类型和五种基本数据类型不同,并非新的数据结构.高级数据类型往往是用来解决一些业务场景. (一)BitMaps (1.1) BitMaps概述 在应用场景中,有一些数据只有两个属性,比如是否是学 ...
- redis详解(二)-- 数据类型详解
Redis常用数据类型详解 1,Redis最为常用的数据类型主要有以下: String Hash List Set Sorted set pub/sub Transactions 在具体描述这几种数据 ...
- Redis 配置文件 redis.conf 项目详解
Redis.conf 配置文件详解 # [Redis](http://yijiebuyi.com/category/redis.html) 配置文件 # 当配置中需要配置内存大小时,可以使用 1k, ...
- Redis配置参数详解
Redis配置参数详解 /********************************* GENERAL *********************************/ // 是否作为守护进 ...
- 探索Redis设计与实现6:Redis内部数据结构详解——skiplist
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- 探索Redis设计与实现5:Redis内部数据结构详解——quicklist
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- 探索Redis设计与实现4:Redis内部数据结构详解——ziplist
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- 【转】Redis内部数据结构详解——ziplist
本文是<Redis内部数据结构详解>系列的第四篇.在本文中,我们首先介绍一个新的Redis内部数据结构--ziplist,然后在文章后半部分我们会讨论一下在robj, dict和zipli ...
随机推荐
- 了解html表单
html表单 表单的根标签:form form标签属性 action:处理表单业务的后台代码的位置(URL) method:提交方式 post get 默认值 enctype:encode type ...
- web框架--tornado自定义分页
1.tornado_main.py #!/usr/bin/env python # -*- coding: utf-8 -*- import tornado.web import tornado.io ...
- Thread笔记
Thread笔记 Thread——fork:https://www.cnblogs.com/noonjuan/diary/2019/08/03/11296217.html Thread——multip ...
- [RN] React Native 错误 Module does not exist in the module map
React Native 错误 Module does not exist in the module map 代码如下: import Login from 'login' import Index ...
- Web协议详解与抓包实战:HTTP1协议-如何管理跨代理服务器的长短连接?(4)
一.HTTP 连接的常见流程 二.从 TCP 编程上看 HTTP 请求处理 三.短连接与长连接 四.Connection 仅针对当前连接有效 五.代理服务器对长连接的支持 未设置代理服务器 设置代理 ...
- DP问题(1) : hdu 2577
题目转自hdu 2577,题目传送门 题目大意: 现给你n个区分大小写的字符串,大小写可用Caps Lock和shift切换(学过计算机的都知道) 但是有一点需要注意(shift是切换,若现在是大写锁 ...
- oracle--报错 ORA-01003,ORA-09817,ORA-01075
磁盘满了,删除旧文件,即可保证登入成功
- 应用层协议:HTTP
1. HTTP定义 HyperText Transfer Protocol,超文本传输协议,是一个基于请求与响应,无状态的,应用层的协议,常基于TCP/IP协议传输数据,互联网上应用最为广泛的一种网络 ...
- 用欧拉计划学Rust语言(第17~21题)
最近想学习Libra数字货币的MOVE语言,发现它是用Rust编写的,所以先补一下Rust的基础知识.学习了一段时间,发现Rust的学习曲线非常陡峭,不过仍有快速入门的办法. 学习任何一项技能最怕没有 ...
- 【More Effective C++ 条款2】最好使用C++转型操作符
C的转型方式存在以下两个缺点: 1)几乎允许你将任何类型转化为任何类型,不能精确的指明转型意图,这样很不安全 如将一个pointer-to-base-class-object转型为一个pointer- ...