R数据挖掘 第一篇:聚类分析(划分)
聚类是把一个数据集划分成多个子集的过程,每一个子集称作一个簇(Cluster),聚类使得簇内的对象具有很高的相似性,但与其他簇中的对象很不相似,由聚类分析产生的簇的集合称作一个聚类。在相同的数据集上,不同的聚类算法可能产生不同的聚类。
聚类分析用于洞察数据的分布,观察每个簇的特征,进一步分析特定簇的特征。由于簇是数据对象的子集合,簇内的对象彼此相似,而与其他簇的对象不相似,因此,簇可以看作数据集的“隐性”分类,聚类分析可能会发现数据集的未知分组。
聚类通过观察学习,不需要提供每个训练元素的隶属关系,属于无监督式学习(unspervised learning),无监督学习是指在没有标注的数据中寻找隐含的结构信息。数据的内部构造描绘了要分组的对象,并且决定了如何最佳地把数据对象分组。主要的聚类算法可以分为以下四类:
- 划分聚类(Partitioning Clustering)
- 层次聚类(Hierarchical clustering)
- 基于密度的方法
- 基于网格的方法
本文简单介绍最简单的划分聚类算法,划分聚类是指:给定一个n个对象的集合,划分方法构建数据的k个分组,其中,每个分区表示一个簇,并且 k<= n,也就是说,把数据划分为k个组,使得每个组至少包含一个对象,基本的划分方法采取互斥的簇划分,这使得每个对象都仅属于一个簇。为了达到全局最优,基于划分的聚类需要穷举所有可能的划分,计算量极大,实际上,常用的划分方法都采用了启发式方法,例如k-均值(k-means)、k-中心点(k-medoids),渐进地提高聚类质量,逼近局部最优解,启发式聚类方法比较适合发现中小规模的球状簇。
一,k-均值
k-均值(kmeans)是一种基于形心的计数,每一个数据元素的类型是数值型,k-均值算法把簇的形心定义为簇内点的均值,k-均值算法的过程:
输入: k(簇的数目),D(包含n个数据的数据集)
输出: k个簇的集合
算法:
- 从D中任意选择k个对象作为初始簇中心;
- repeat
- 根据cu中对象的均值,把每个对象分配到最相似的簇;
- 更新簇的均值,即重新计算每个簇中对象的均值;
- until 簇均值不再发生变化
不能保证k-均值方法收敛于全局最优解,但它常常终止于局部最优解,该算法的结果可能依赖于初始簇中心的随机选择。
k-均值方法不适用于非凸形的簇,或者大小差别很大的簇,此外,它对离群点敏感,因为少量的离群点能够对均值产生极大的影响,影响其他簇的分配。
R语言中,stats包中的kmeans()函数用于实现k-均值聚类分析:
kmeans(x, centers, iter.max = , nstart = ,
algorithm = c("Hartigan-Wong", "Lloyd", "Forgy","MacQueen"), trace=FALSE)
参数注释:
- x:数值型的向量或矩阵
- centers:簇的数量
- iter.max:重复的最大数量,默认值是10
- nstart:随机数据集的数量,默认值是1
- algorithm:算法的选择,默认值是Hartigan-Wong
函数返回的值:
- cluster :整数向量,整数值是从1到k,表示簇的编号
- centers:每个簇的中心,按照簇的编号排列
- size:每个簇包含的点的数量
二,k-中心点
k-中心点不使用簇内对象的均值作为参照点,而是挑选实际的数据对象p来代表簇,其余的每个对象被分配到与其最为相似的对象代表p所在的簇中。通常情况下,使用围绕中心点划分(Partitioning Around Medoids,PAM)算法实现k-中心点聚类。
PAM算法的实现过程:
输入: k(簇的数目),D(包含n个数据的数据集)
输出: k个簇的集合
算法:
- 从D中随机选择k个对象作为初始的代表对象或种子;
- repeat
- 把每个剩余的对象分配到最近的代表对象p所在的簇;
- 随机地选择一个非代表对象R
- 计算用R代替代表对象p的总代价S;
- if S<0 then 使用R代替p,形成新的k个代表对象的集合;
- until 代表对象不再变化
当存在离群点时,k-中心点方法比k-均值法更鲁棒(所谓“鲁棒性”,是指控制系统在一定(结构,大小)的参数摄动下,维持某些性能的特性),这是因为中心点不像均值法那样容易受到离群点或其他极端值的影响。但是,当n和k的值较大时,k-中心点计算的开销变得相当大,远高于k-均值法。
R语言中,cluster包中的pam()函数用于实现k-中心点聚类分析:
pam(x, k, diss = inherits(x, "dist"),metric = c("euclidean", "manhattan"), medoids = NULL, stand = FALSE, ... )
参数注释:
- diss:逻辑值,默认值是TRUE,当diss为TRUE时,x参数被认为是相异矩阵(dissimilarity matrix);当diss为FALSE时,x参数被认为是包含变量的观测矩阵
- metric:字符类型,用于指定用于在两个观测之间计算差异的度量(mertic),有效值是"euclidean" 和"manhattan",分别用于计算欧几里德距离和曼哈顿距离,如果diss参数为TRUE,那么该参数会被忽略。
- medoids:默认值是NULL,用于指定聚类的初始的中心点。
- stand:逻辑值,默认值是FALSE。如果设置为TRUE,那么在对x计算相异度量之前,按照列对x进行标准化(无量纲化处理),也就是说,对每列的数据进行标准化。标准化操作算法是:通过减去变量的平均值并除以变量的平均绝对偏差,对每个变量(列)进行标准化测量。 如果x已经是相异矩阵,则该参数将被忽略。
函数返回的对象:
- medoids:每个簇的中心点
- clustering:向量,用于表示每个观测所属于的簇
- silinfo:轮廓数据,包括每个观测的轮廓系数,每个簇的平均轮廓系数,整个数据集的平均轮廓系数。
三,聚类评估
当我们再数据集上试用一种聚类方法时,如何评估聚类的结果的好坏?一般来说,聚类评估主要包括以下任务:
- 估计聚类趋势:仅当数据中存在非随机数据时,聚类分析才是有意义的,因此,评估数据集是否存在随机数据。
- 确定数据集中的簇数:在使用聚类算法之前,需要估计簇数
- 测定聚类质量:在数据集上使用聚类方法之后,需要评估簇的质量。
1,估计聚类趋势
聚类要求数据是非均匀分布的,霍普金斯统计量是一种空间统计量,用于检验空间分布的变量的空间随机性。
comato包中有一个Hopkins.index()函数,用于计算霍普金斯指数,如果数据分布是均匀的,则该值接近于0.5,如果数据分布是高度倾斜的,则该值接近于1。
library(comato)
Hopkins.index(data)
要使用Hopkins.index()评估数据的空间随机性,需要对数据进行无量纲化处理。
2,确定最佳的簇数
通常情况下,使用肘方法(elbow)以确定聚类的最佳的簇数,肘方法之所以是有效的,是基于以下观察:增加簇数有助于降低每个簇的簇内方差之和,给定k>0,计算簇内方差和var(k),绘制var关于k的曲线,曲线的第一个(或最显著的)拐点暗示正确的簇数。
sjPlot包中sjc.elbow()函数实现了肘方法,可以用于确定k-均值聚类的簇的数目:
library(sjPlot)
sjc.elbow(data, steps = , show.diff = FALSE)
参数注释:
- steps:最大的肘值的数量
- show.diff:默认值是FALSE,额外绘制一个图,连接每个肘值,用于显示各个肘值之间的差异,改图有助于识别“肘部”,暗示“正确的”簇数。
sjc.elbow()函数用于绘制k-均值聚类分析的肘值,该函数在指定的数据框计算k-均值聚类分析,产生两个图形:一个图形具有不同的肘值,另一个图形是连接y轴上的每个“步”,即在相邻的肘值之间绘制连线,第二个图中曲线的拐点可能暗示“正确的”簇数。
绘制k均值聚类分析的肘部值。 该函数计算所提供的数据帧上的k均值聚类分析,并产生两个图:一个具有不同的肘值,另一个图绘制在y轴上的每个“步”(即在肘值之间)之间的差异。 第二个图的增加可能表明肘部标准。
library(effects)
library(sjPlot)
library(ggplot2) sjc.elbow(mtcars,show.diff = FALSE)
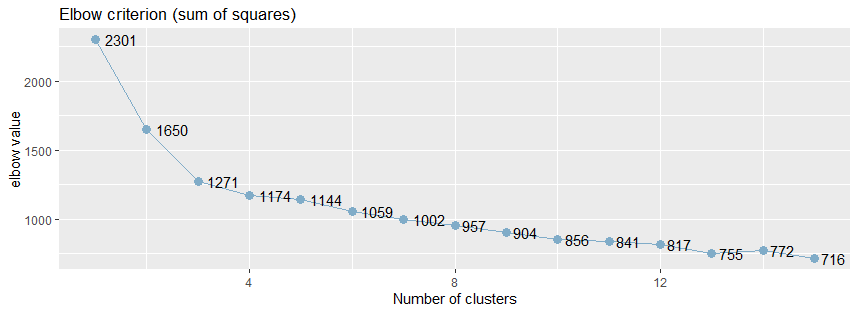
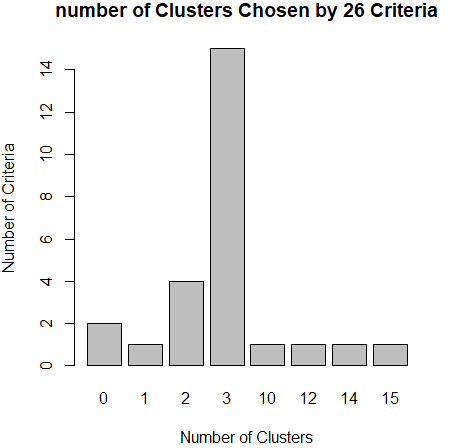
从肘值图中,可以看到曲线的拐点是3,还可以使用NbClust包种的NbClust()函数,该函数提供了26个不同的指标来帮助确定簇的最终数目。
library(NbClust) nc <- NbClust(df,min.nc = ,max.nc = ,method = "kmeans")
barplot(table(nc$Best.nc[,]),xlab="Number of Clusters",ylab="Number of Criteria",main="number of Clusters Chosen by 26 Criteria")
从条形图种,可以看到支持簇数为3的指标(Criteria)的数量是最多的,因此,基本上可以确定,k-均值聚类的簇数目是3。
3,测定聚类质量
如何比较不同聚类算法产生的聚类?一般而言,根据是否有基准可用,把测定聚类质量的方法分为两类:外在方法和内在方法。
基准是一种理想的聚类,通常由专家构建。如果有可用的基准,那么可以把聚类和基准进行比较,这种方法叫做外在方法。如果没有基准可用,那么通过考虑簇的分离情况来评估簇的好坏,这种方法叫做内在方法。
(1)外在方法
当有基准可用时,使用BCubed 精度(precision)和召回率(recall)来评估聚类的质量。
BCubed根据基准,对给定数据集上聚类中每个对象评估精度(precision)和召回率(recall)。一个对象的精度是指同一簇中有多少个其他对象与该对象同属于一个类别;一个对象的召回率反映有多少同一类别的对象被分配到相同的簇中。
(2)内在方法
当没有数据集的基准可用时,必须使用内在方法来评估聚类的质量。一般而言,内在方法通过考察簇的分离情况和簇的紧凑情况来评估聚类,通常的内在方法都使用数据集的对象之间的相似性度量来实现。
轮廓系数(silhouette coefficient)就是这种相似性度量,轮廓系数的值在-1和1之间,该值越接近于1,簇越紧凑,聚类越好。当轮廓系数接近1时,簇内紧凑,并远离其他簇。
如果轮廓系数sil 接近1,则说明样本聚类合理;如果轮廓系数sil 接近-1,则说明样本i更应该分类到另外的簇;如果轮廓系数sil 近似为0,则说明样本i在两个簇的边界上。所有样本的轮廓系数 sil的均值称为聚类结果的轮廓系数,是该聚类是否合理、有效的度量。
包fpc中实现了计算聚类后的一些评价指标,其中就包括了轮廓系数:avg.silwidth(平均的轮廓宽度)
library(fpc)
result <- kmeans(data,k)
stats <- cluster.stats(dist(data)^2, result$cluster)
sli <- stats$avg.silwidth
包cluster中也包括计算轮廓系数的函数silhouette():
library (cluster)
library (vegan) #pam
dis <- vegdist(data)
res <- pam(dis,)
sil <- silhouette (res$clustering,dis) #kmeans
dis <- dist(data)^
res <- kmeans(data,)
sil <- silhouette (res$cluster, dis)
四,k-均值聚类分析实践
有效的聚类分析是一个多步骤的过程,其中每一次决策都可能影响聚类结果的质量和有效性,我们使用k-均值聚类来处理葡萄酒中13种化学成分的数据集wine,这个数据集可以通过rattle包获得,
install.packages("rattle")
data(wine,package="rattle")
head(wine)
Type Alcohol Malic Ash Alcalinity Magnesium Phenols Flavanoids Nonflavanoids Proanthocyanins Color Hue Dilution Proline
14.23 1.71 2.43 15.6 2.80 3.06 0.28 2.29 5.64 1.04 3.92
13.20 1.78 2.14 11.2 2.65 2.76 0.26 1.28 4.38 1.05 3.40
13.16 2.36 2.67 18.6 2.80 3.24 0.30 2.81 5.68 1.03 3.17
14.37 1.95 2.50 16.8 3.85 3.49 0.24 2.18 7.80 0.86 3.45
13.24 2.59 2.87 21.0 2.80 2.69 0.39 1.82 4.32 1.04 2.93
14.20 1.76 2.45 15.2 3.27 3.39 0.34 1.97 6.75 1.05 2.85
1,选择合适的变量
第一个变量Type是类型,可以忽略,其他13个变量是葡萄酒的13总化学成分,选择这13个变量进行聚类分析。由于变量值变化很大,所以需要在聚类之前对其进行标准化处理。
2,标准化数据
使用scale()函数对数据进行无量纲化处理,
df <- scale(wine[,-])
3,评估聚类的趋势
变量df的变量值是无量纲的,可以直接使用函数Hopkins.index()计算数据的空间分布的随机性,得出的结果越接近于1,说明数据的空间分布高度倾斜,空间随机性越高。
install.packages("comato")
library(comato)
Hopkins.index(df)
[] 0.7412846
4,确定聚类的簇数
使用sjPlot包中的sjc.elbow()函数计算肘值,曲线的拐点出现3左右,这说明,使用k-均值法进行聚类分析时,可以设置的簇数大概是3。
install.packages("effects")
install.packages("sjplot")
library(effects)
library(sjPlot)
library(ggplot2)
sjc.elbow(df,show.diff = FALSE)
从肘值图中,可以看到曲线的拐点是3,还可以使用NbClust包种的NbClust()函数,该函数提供了26个不同的指标来帮助确定簇的最终数目。
install.packages("NbClust")
library(NbClust)
nc <- NbClust(df,min.nc = ,max.nc = ,method = "kmeans")
barplot(table(nc$Best.nc[,]),xlab="Number of Clusters",ylab="Number of Criteria",main="number of Clusters Chosen by 26 Criteria")
从条形图种,可以看到支持簇数为3的指标(Criteria)的数量是最多的,因此,基本上可以确定,k-均值聚类的簇数目是3。
5,测定聚类的质量
使用轮廓系数测定聚类的质量,轮廓系数的值在-1和1之间,该值越接近于1,簇越紧凑,聚类越好。当轮廓系数接近1时,簇内紧凑,并远离其他簇。
install.packages("fpc")
library(fpc)
for(k in :){
result <- kmeans(df,k)
stats <- cluster.stats(dist(df)^, result$cluster)
sli <- stats$avg.silwidth
print(paste0(k,'-',sli))
}
当簇数目为3时,聚类的轮廓系数0.45是最好的。
[] "2-0.425791262898175"
[] "3-0.450837233419168"
[] "4-0.35109709657011"
[] "5-0.378169006474844"
[] "6-0.292436629924875"
[] "7-0.317163857046711"
[] "8-0.229405778112672"
[] "9-0.291438101137107"
参考文档:
R数据挖掘 第一篇:聚类分析(划分)的更多相关文章
- R数据挖掘 第二篇:基于距离评估数据的相似性和相异性
聚类分析根据对象之间的相异程度,把对象分成多个簇,簇是数据对象的集合,聚类分析使得同一个簇中的对象相似,而与其他簇中的对象相异.相似性和相异性(dissimilarity)是根据数据对象的属性值评估的 ...
- R数据分析 第一篇:温习概率论
概率论是人们在长期实践中发现的理论,是客观存在的.自然界和社会上发生的现象是多种多样的,有一类现象,在一定条件下必然发生,称作确定性现象,而概率论研究的现象是不确定性现象,嗯嗯,醒醒,概率论研究的对象 ...
- python数据挖掘第一篇:正则表达式
正则表达式 re 模块 re.match(pattern,string[,flag]) match方法 从首字母开始匹配,如果包含pattern字符串,则匹配成功,返回match对象,失败则返回Non ...
- SAS数据挖掘实战篇【四】
SAS数据挖掘实战篇[四] 今天主要是介绍一下SAS的聚类案例,希望大家都动手做一遍,很多问题只有在亲自动手的过程中才会有发现有收获有心得. 1 聚类分析介绍 1.1 基本概念 聚类就是一种寻找数据之 ...
- SAS数据挖掘实战篇【二】
SAS数据挖掘实战篇[二] 从SAS数据挖掘实战篇[一]介绍完目前的数据挖掘基本概念之外,对整个数据挖掘的概念和应用有初步的认识和宏观的把握之后,我们来了解一下SAS数据挖掘实战篇[二]SAS工具的应 ...
- SAS数据挖掘实战篇【一】
SAS数据挖掘实战篇[一] 1数据挖掘简介 1.1数据挖掘的产生 需求是一切技术之母,管理和计算机技术的发展,促使数据挖掘技术的诞生.随着世界信息技术的迅猛发展,信息量也呈几何指数增长,如何从巨量.复 ...
- SAS数据挖掘实战篇【六】
SAS数据挖掘实战篇[六] 6.3 决策树 决策树主要用来描述将数据划分为不同组的规则.第一条规则首先将整个数据集划分为不同大小的 子集,然后将另外的规则应用在子数据集中,数据集不同相应的规则也不同 ...
- 从0开始搭建SQL Server AlwaysOn 第一篇(配置域控)
从0开始搭建SQL Server AlwaysOn 第一篇(配置域控) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www.cnb ...
- Android基础学习第一篇—Project目录结构
写在前面的话: 1. 最近在自学Android,也是边看书边写一些Demo,由于知识点越来越多,脑子越来越记不清楚,所以打算写成读书笔记,供以后查看,也算是把自己学到所理解的东西写出来,献丑,如有不对 ...
随机推荐
- Kibana插件开发
当前开发环境 Kibana版本:7.2 elasticsearch版本:7.2 开发环境安装可参考:https://github.com/elastic/kibana/blob/master/CONT ...
- vue打包后刷新页面报错:Unexpected token <
前言 今天遇到了一个很怪的问题,在vue-cli+webpack的项目中,刷新特定页面后页面会变空白,报错为index.html文件中Unexpected token <. 怪点一是开发环境没有 ...
- SQLAlchemy(1)
介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取 ...
- Flask框架整理及配置文件
阅读目录 Flask目录结构(蓝图) pro_flask包的init.py文件, 用于注册所有的蓝图 manage.py文件,作为整个项目的启动文件 views包中的blog.py,必须要通过sess ...
- 怎么安装python3
解压 这个压缩包 2.把解压后的python文件夹所在的路径配置到环境变量 3.鼠标移动到计算机上---右键---属性----高级系统设置---环境变量,打开如下界面 4.在系统变量里选择pa ...
- 常用开窗函数总结(hive、sparkSQL可执行)
一:根据某个字段排序 测试数据: SQL> select * from sscore; NAME SCORE ---------- ----- aa 99 bb ...
- Java高级-反射
1.如何创建Class的实例 1.1过程:源文件经过编译(javac.exe)以后,得到一个或者多个.class文件..class文件经过运行(java.exe)这步,就需要进行类的加载(通过JVM的 ...
- 【转载】Innodb中的事务隔离级别和锁的关系
前言 我们都知道事务的几种性质,数据库为了维护这些性质,尤其是一致性和隔离性,一般使用加锁这种方式.同时数据库又是个高并发的应用,同一时间会有大量的并发访问,如果加锁过度,会极大的降低并发处理能力.所 ...
- Django项目中出现的错误及解决办法(ValueError: Dependency on app with no migrations: customuser)
写项目的时候遇到了类似的问题,其实就是没有生成迁移文件,执行一下数据库迁移命令就好了 ValueError: Dependency on app with no migrations: customu ...
- EventBus事件总线(牛x版)
事件总线: public interface IEventBus { void Trigger<TEvent>(TEvent eventData, string topic = null) ...