centos 7( linux )下搭建elasticsearch踩坑记
原文:https://blog.csdn.net/an88411980/article/details/83150380
概述
公司最近在做全文检索的项目,发现elasticsearch踩了不少坑,百度点进去又是坑,在此记录一下自己的踩坑历程。
本文旨在单机版的elasticsearch环境搭建踩坑记录,后续会把整个全文检索涉及到的项目和技术分享出来.
上一篇博文记录了elasticsearch安装方式 ,RPM安装简单,坑点少,但自由度低,本人生产使用的tar包安装方式,本文主要记录tar包踩坑记
如有错误或者更好的方案,欢迎批评指正
环境准备
全新最小化安装的centos 7.5
elasticsearch 6.4.0
elasticsearch配置
elasticsearch安装方式 中tar包安装方式配置文件在 /opt/apps/elasticsearch-6.4.0/config/ 下
elasticsearch配置文件主要是 es配置文件elasticsearch.yml 和 es jvm配置文件jvm.options两个
jvm.options
内存大小配置
jvm.options配置文件首先是内存大小内存,es默认内存大小配置为1G,此配置需要根据实际数据大小进行配置,建议最大分配内存为机器可用内存大小的一半,最大不超过32G,因为es自身有个压缩功能在32G以内会启用,修改此配置项操作如下:
vim /opt/apps/elasticsearch-6.4.0/config/jvm.options

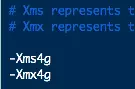
将以上默认配置项修改为4G,本人机器内存9G,数据大小为1.8G
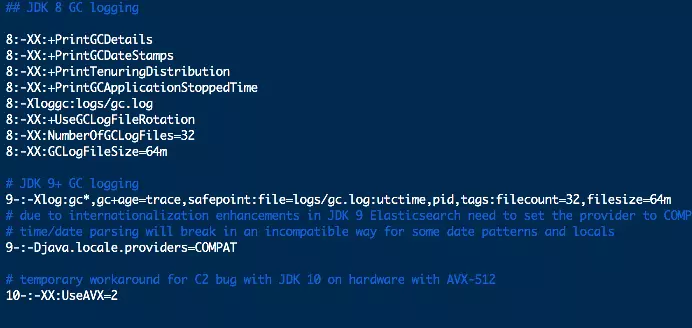
GC配置
gc配置如下图: 每行最前面的数字是指jdk的版本,8代表jdk1.8,本人这里使用了默认配置不变
elasticsearch.yml
elasticsearch.yml配置文件主要包含集群配置,节点配置,数据以及日志路径配置,启动内存配置,网络配置
集群相关配置
vim /opt/apps/elasticsearch-6.4.0/config/elasticsearch.yml cluster.name: test-cluster
node.name: node-1 network.host: 172.16.0.1
http.port: 9200 discovery.zen.ping.unicast.hosts: ["172.16.0.100", "172.16.0.101","172.16.0.102"]
discovery.zen.minimum_master_nodes: 2
配置详解:
cluster.name: es集群的名称
node.name: 当前es节点名称,主要区分集群中哪个节点
network.host: 当前节点(服务器)的IP地址,此项必须配置,否则其他服务器无法访问到es
http.port: es服务的端口,默认就是9200
discovery.zen.ping.unicast.hosts: 集群每个节点的IP地址,同样可以配置可解析的域名,单机环境可以忽略此配置
discovery.zen.minimum_master_nodes: 集群节点存活最少数,建议配置为集群机器数/2+1 ,单机环境可以忽略
路径配置
为了规避对es打包到其他机器继续使用时把数据和日志也打包进去,建议将数据和日志保存到非es安装目录的其他目录下,
如果改变数据和日志路径需要提前创建好存放目录,本文存放目录如下:
mkdir -p /data/es/data
mkdir -p /var/log/es
vim /opt/apps/elasticsearch-6.4.0/config/elasticsearch.yml
path.data: /data/es/data
path.logs: /var/log/es
配置详解:
path.data: es数据存放路径
path.logs: es日志存放路径
启动踩坑记
es后台启动命令如下:
/opt/apps/elasticsearch-6.4.0/bin/elasticsearch -d -p pid
root用户启动失败
本人使用root用户执行启动命令后,发现没有es进程,开始查看es日志:
tail -fn 500 /var/log/es/elasticsearch.log
很幸运的看到了错误提示: Caused by: java.lang.RuntimeException: can not run elasticsearch as root
提示的很明显,es不能使用root用户启动,此刻本人的内心在呐喊:"瓦特?",呐喊完毕后,还是要屈服于它,开始创建es启动用户elasticsearch:
# groupadd elasticsearch
# useradd -g elasticsearch -d /usr/local/elasticsearch -m -n elasticsearch
# ./elasticsearch
再次启动将会遇到各种账号权限问题,此时需要给用户elasticsearch分配es的权限:
切换到root账号执行以下命令,需要切换到具有管理员权限的用户下,当然也可以分配用户elasticsearch为管理员以及免密码等配置(具体配置自行百度)
# chown -R elasticsearch:elasticsearch /opt/apps/elasticsearch-6.4.0
# chown -R elasticsearch:elasticsearch /var/log/es
# chown -R elasticsearch:elasticsearch /data/es/data
# chown -R elasticsearch:elasticsearch /usr/local/elasticsearch
权限分配完毕后,切换到elasticsearch用户下继续执行启动命令,查看es日志,就会发现新的错误提示: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
此错误意思也很明显es启动进程要求文件描述符最小为65536, 但是目前系统配置的最大为4096,继续填坑
切换到root用户,修改elasticsearch文件描述符,第一列的elasticsearch是指的启动es的用户
# vim /etc/security/limits.conf 在文件末尾添加:
elasticsearch hard nofile 65536
elasticsearch soft nofile 65536
切换到用户elasticsearch继续启动,查看es日志会发现新的错误: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
错误的意思是es启动内存权限最低 262144,继续填坑, 切换到root用户,修改配置:
# vim /etc/sysctl.conf 在最后一行添加如下内容:
vm.max_map_count=262144 # sysctl -p
可以查看到如下内容:
vm.max_map_count=262144
ok,切换到elasticsearch用户,继续执行启动命令,查看es日志,就可以如下内容:
以上日志无任何错误,通过浏览器访问: http://172.16.0.1:9200 ,可以看到下图内容:
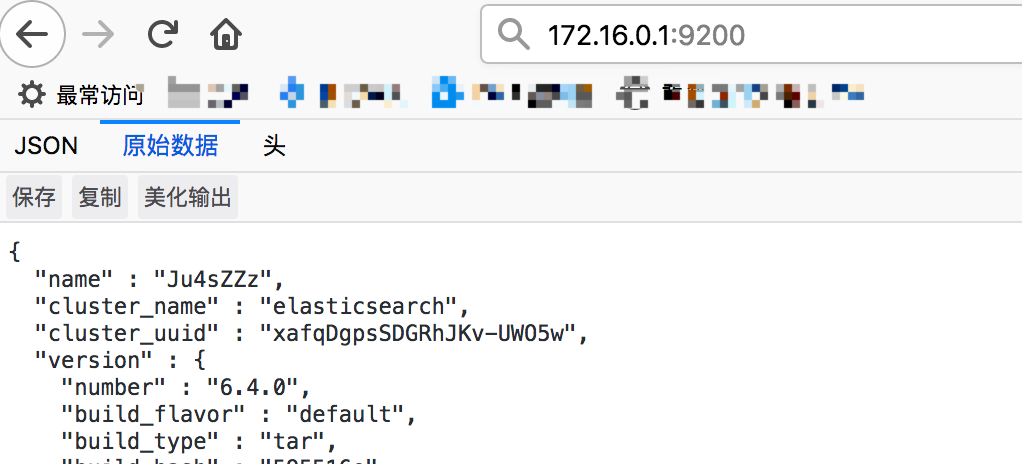
再次就说明es正式启动完成,可以正常使用了,如果url无法访问需要检查服务器防火墙端口是否已经开放
centos7 防火墙使用的firewall,基于本文开放端口方式为,切换到root用户,执行以下命令:
# firewall-cmd --zone=public --add-port=9200/tcp --permanent
# firewall-cmd --zone=public --add-port=9300/tcp --permanent
# firewall-cmd --reload
centos 7( linux )下搭建elasticsearch踩坑记的更多相关文章
- CentOS 7.4 下搭建 Elasticsearch 6.3 搜索群集
上个月 13 号,Elasticsearch 6.3 如约而至,该版本和以往版本相比,新增了很多新功能,其中最令人瞩目的莫过于集成了 X-Pack 模块.而在最新的 X-Pack 中 Elastics ...
- linux下安装node踩坑总结
1.在node官网下载linux二进制文件(确定文件的类型)本文以二进制文件为例 2.放入linux的对应目录下之后: tar -xvf node-v10.15.3-linux-x64.tar.xz ...
- Linux下pcstat安装踩坑教程
首先安装golang 1.进入官方链接下载对应自己系统版本的Golang安装包:https://dl.google.com/go/go1.13.4.linux-amd64.tar.gz root@ub ...
- Linux系统搭建GitLab---阿里云Centos7搭建Gitlab踩坑
一.简介 GitLab,是一个利用 Ruby on Rails 开发的开源应用程序,实现一个自托管的Git项目仓库,可通过Web界面进行访问公开的或者私人项目安装. 它拥有与GitHub类似的功能,能 ...
- MongoDB学习笔记—Linux下搭建MongoDB环境
1.MongoDB简单说明 a MongoDB是由C++语言编写的一个基于分布式文件存储的开源数据库系统,它的目的在于为WEB应用提供可扩展的高性能数据存储解决方案. b MongoDB是一个介于关系 ...
- Linux下搭建个人网站
前不久在阿里买了一个服务器,然后开始第一次尝试搭建自己的个人网站.前端采用了bootstrap框架,后端采用的是PHP,数据库使用的是Mysql.新手第一次在linux下搭建遇见很多问题,在这里分享一 ...
- 记录Linux下安装elasticSearch时遇到的一些错误
记录Linux下安装elasticSearch时遇到的一些错误 http://blog.sina.com.cn/s/blog_c90ce4e001032f7w.html (2016-11-02 22: ...
- CentOS 6.2下搭建Web服务器
1Centos 6.2下搭建web服务器 如今,Linux在Web应用越来越广,许多企业都采用Linux来搭建Web服务器,这样即节省了购买正版软件的费用,而且还能够提高服务器的安全性. 之前我们介绍 ...
- ubuntu 下安装docker 踩坑记录
ubuntu 下安装docker 踩坑记录 # Setp : 移除旧版本Docker sudo apt-get remove docker docker-engine docker.io # Step ...
随机推荐
- 解决solr 请求参数过长报错too many boolean clauses Exception
booleanClauses属性的意义 貌似是查询条件有几个逻辑判断而不是参数长度. 如下面两种情况 a:1 OR b:2 AND C:3那么此时booleanClauses=3 id(1 2 3 4 ...
- thinkPHP5如何使用rabbitmq
thinkPHP5如何使用rabbitmq? 安装好 tp5 的 rabbitmq 扩展后,在项目根目录文件添加文件 rabbitmq.php 引导启动 rabbitmq. <?php defi ...
- Ladon内网渗透扫描器PowerShell版
程序简介 Ladon一款用于大型网络渗透的多线程插件化综合扫描神器,含端口扫描.服务识别.网络资产.密码爆破.高危漏洞检测以及一键GetShell,支持批量A段/B段/C段以及跨网段扫描,支持URL. ...
- pychram 激活码
转自博客:https://blog.csdn.net/may_ths/article/details/84032217 激活码到期时间: 2020.06 K6IXATEF43-eyJsaWNlbnNl ...
- Scala Collection Method
接收一元函数 map 转换元素,主要应用于不可变集合 (1 to 10).map(i => i * i) (1 to 10).flatMap(i => (1 to i).map(j =&g ...
- 『Tree nesting 树形状压dp 最小表示法』
Tree nesting (CF762F) Description 有两个树 S.T,问 S 中有多少个互不相同的连通子图与 T 同构.由于答案 可能会很大,请输出答案模 1000000007 后的值 ...
- ftp搭建后外网无法连接和访问阿里云服务器(非软件)
阿里云服务器由于性价比高,是不少企业建站朋友们的首选.而在购买阿里云服务器后,不少客户反映其在搭建FTP后出现外网无法访问的问题,这里特意搜集整理了关于ftp搭建后外网无法连接和访问的问题,提供以下解 ...
- asp.net core 系列之允许跨域访问2之测试跨域(Enable Cross-Origin Requests:CORS)
这一节主要讲如何测试跨域问题 你可以直接在官网下载示例代码,也可以自己写,我这里直接使用官网样例进行演示 样例代码下载: Cors 一.提供服务方,这里使用的是API 1.创建一个API项目.或者直接 ...
- Windows 查看端口占用进程并关闭
当我们在运行一些软件需要特定软件(如tomcat)时,有可能会碰上端口被占用的情况,这时候我们可能就需要更改端口或把占用端口的进程结束掉,因为更换端口可能会导致当前环境产生一些的问题或是需要重新配置其 ...
- (原创)对比组态软件,使用C#开发的服务器和客户端软件的优势
在当前经济形势和市场环境下,中小企业面对萧条的消费市场,恶化的外部贸易环境,刚性支出高成本人工和生产要素,通货膨胀,隐性的腐化支出等各种因素的作用导致企业生存艰难,企业需要在各方面削减支出,拓展市场寻 ...