selenium原理解析
相信很多测试小伙伴儿都听过或者使用过web自动化selenium,那您有没有研究过selenium的原理呢?为什么要使用webdriver.exe,webdriver.exe是干啥用的?selenium.common.exceptions.WebDriverException: Message: 'xxxdriver' executable needs to be in PATH如何解决的 ?今天和大家一起分析下selenium整体运行原理,有一个直观的认识。
以python为例
此处省略环境搭建和安装过程了,不知道的小伙伴儿可以自行百度。
大家都知道在使用selenium时,需要先要导入webdriver,通过webriver模块实例化driver对象
from selenium import webdriver
chrome = webdriver.Chrome()
webdriver.Chrome()都做了什么?
通过跟踪Chrome类的__init__方法发现,在初始化时调用了Service类的start方法
# WebDriver初始化方法,executable_path为chromedriver
def __init__(self, executable_path="chromedriver", port=0,
options=None, service_args=None,
desired_capabilities=None, service_log_path=None,
chrome_options=None, keep_alive=True) # Service类初始化和调用start方法
from .service import Service
self.service = Service(
executable_path,
port=port,
service_args=service_args,
log_path=service_log_path)
self.service.start()
继续跟踪Service类中start方法
cmd = [self.path]
cmd.extend(self.command_line_args())
self.process = subprocess.Popen(cmd, env=self.env,
close_fds=platform.system() != 'Windows',
stdout=self.log_file,
stderr=self.log_file,
stdin=PIPE)
cmd列表的第一个参数是传入的executable_path="chromedriver"
cmd列表的第二个参数是可用的端口号
# class Service(object)中的方法,说明该方法需要子类重写
def command_line_args(self):
raise NotImplemented("This method needs to be implemented in a sub class") # 子类class Service(service.Service)
def command_line_args(self):
return ["--port=%d" % self.port] + self.service_args # self.port 属性在子类Service未声明,说明是在父类中声明的
# 父类中的__init__方法中
self.port = port
if self.port == 0:
self.port = utils.free_port()
# 由此可知port是调用utils.free_port获取一个可用端口,这就是为什么每次运行端口都不一样的原因所在
从上面分析可以得到cmd的参数为
cmd = ['chromedriver', '--port=52857']
端口是随机可用的
即start方法实际是使用subprocess中的Popen方法执行cmd中的命令chromedriver --port=52857
我们在dos窗口中执行该命令

貌似是起了一个服务,在浏览器输入 localhost:52857试试

可以访问,那关掉该cmd窗口再进行访问呢?
无法访问了,可以看出subprocess.Popen(cmd)实际是启动了一个服务,那cmd命令中chromewebdrive是什么呢?
通过命令where chromewebdriver,发现 chromewebdriver就是我们添加到path路径的浏览器驱动

双击运行chromewebdriver.exe 发现,和subprocess.Popen(cmd)是惊人的相似,只是端口不同而已,也是可以通过浏览器访问

再执行完subprocess.Popen(cmd),紧接着执行RemoteWebDriver的初始化方法,代码如下:
# RemoteWebDriver类的初始化方法
RemoteWebDriver.__init__(
self,
command_executor=ChromeRemoteConnection(
remote_server_addr=self.service.service_url,
keep_alive=keep_alive),
desired_capabilities=desired_capabilities)
通过对代码进行跟踪,RemoteWebDriver.__init__实际就是通过http的形式向webdriverserver获取一个session
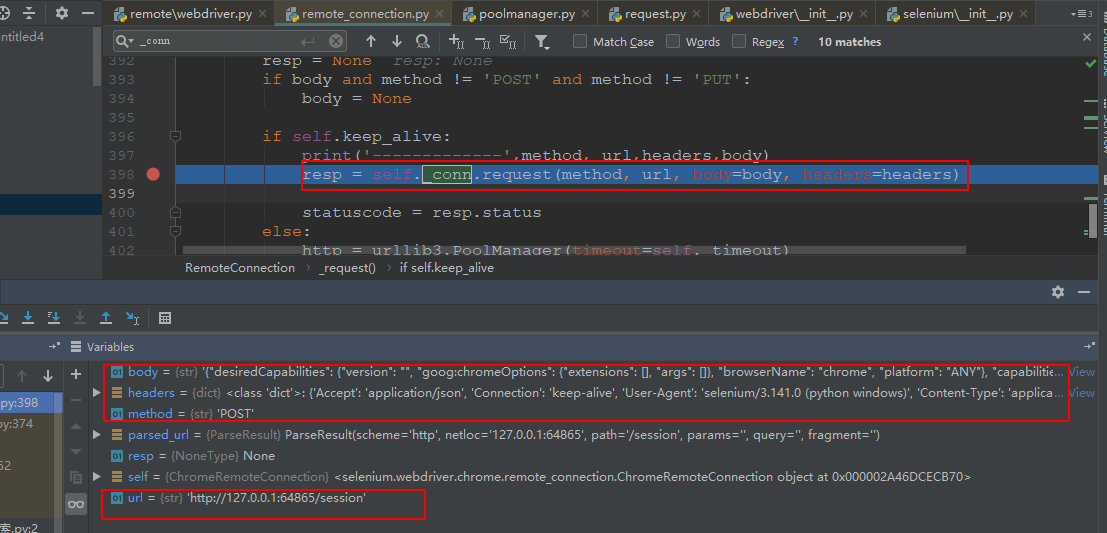
综上webdriver.Chrome()其实就是启动了一个本地服务,并通过http获取一个新的session
接下来继续分析chrome.get('http://www.baidu.com')都做什么?
def get(self, url):
"""
Loads a web page in the current browser session.
"""
self.execute(Command.GET, {'url': url}) # 都是调用的 self._request发起http请求
def execute(self, command, params):
return self._request(command_info[0], url, body=data)
通过print或者debug,get方法本质也是向webdriver server 发起一次http请求,session/${session}/url
为了验证上说结论我们用接口的形式是否可以打开chrome浏览器
步骤:
1、本地双击webdriver.exe 启动一个一个webdriver 服务,端口9515
2、通过接口localhost:9515/session, 获取session
3、通过接口localhost:9515/session/${session}/url,打开浏览器
接口1
localhost:9515/session
method:
POST
params:
{"desiredCapabilities": {"version": "", "platform": "ANY", "goog:chromeOptions": {"args": [], "extensions": []}, "browserName": "chrome"}, "capabilities": {"alwaysMatch": {"goog:chromeOptions": {"args": [], "extensions": []}, "platformName": "any", "browserName": "chrome"}, "firstMatch": [{}]}}
接口2
session/${session}/url
method: POST
params: { "url": "http://www.baidu.com", "sessionId": "${session}" }
在jmeter中运行上述接口,启动了Chrome浏览器比打开百度首页
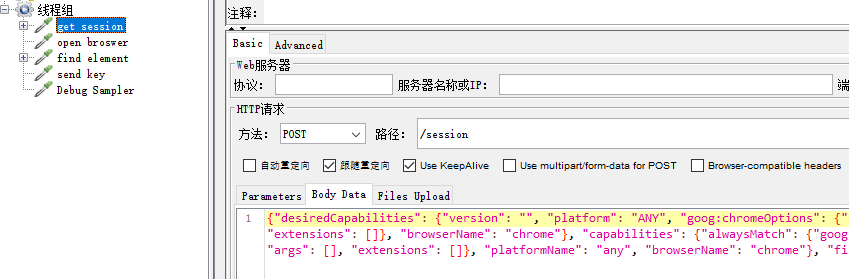
综上可以得出selenium的整个交互过程了,下面就是selenium的运行原理,写得不对的欢迎板砖

思考:
selenium web UI自动化能否可以向接口自动化那些来编写web UI自动化呢?这样有什么好处和不足
selenium原理解析的更多相关文章
- Selenium原理初步--Android自动化测试学习历程
章节:自动化基础篇——Selenium原理初步(第五讲) 注:其实所有的东西都是应该先去用,但是工具基本都一样,底层都是用的最基础的内容实现的,测试应该做的是: (1)熟练使用工具,了解各个工具的利弊 ...
- APPcrawler基础原理解析及使用
一.背景 一年前,我们一直在用monkey进行Android 的稳定性测试 ,主要目的就是为了测试app 是否会产生Crash,是否会有ANR,页面错误等问题,在monkey测试过程中,实现了脱离Ca ...
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- Web APi之过滤器创建过程原理解析【一】(十)
前言 Web API的简单流程就是从请求到执行到Action并最终作出响应,但是在这个过程有一把[筛子],那就是过滤器Filter,在从请求到Action这整个流程中使用Filter来进行相应的处理从 ...
- GeoHash原理解析
GeoHash 核心原理解析 引子 一提到索引,大家脑子里马上浮现出B树索引,因为大量的数据库(如MySQL.oracle.PostgreSQL等)都在使用B树.B树索引本质上是对索引字段 ...
- alibaba-dexposed 原理解析
alibaba-dexposed 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49821413 原理参考地址: htt ...
- 支付宝Andfix 原理解析
支付宝Andfix 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49802429 原理参考地址: http://blo ...
随机推荐
- 收藏单词TOEFL备份托福英语
TOEFL托福词汇串讲(文本) alchemy(chem-化学)n. 炼金术 chemistry 化学 alder 赤杨树 联想:older 老人坐在赤杨树下 sloth 树懒 algae n.海藻 ...
- jdbc 简单示例和优缺点
一个使用JDBC的例子: Class.forName("com.mysql.cj.jdbc.Driver"); //加载驱动 Connection connection = Dri ...
- pytest_pytest-html生成html报告
前言 pytest-HTML是一个插件,pytest用于生成测试结果的HTML报告.兼容Python 2.7,3.6 pytest-html 1.github上源码地址[https://github. ...
- go ---变量数据结构调试利器 go-spew
我们在使用Golang(Go语言)开发的过程中,会通过经常通过调试的方式查找问题的原因,解决问题,尤其是当遇到一个很棘手的问题的时候,就需要知道一段代码在执行的过程中,其上下文的变量对应的数据,以便进 ...
- C#月份和日期转大写和C#集合分组
//日转化为大写 private static string DaytoUpper(int day, string type) { if (day < 20) { return MonthtoU ...
- swagger list Could not resolve reference because of: Could not resolve point
swagger list Could not resolve reference because of: Could not resolve point controller的参数要加 @Requ ...
- dump net core lldb 安装
原文https://www.cnblogs.com/calvinK/p/9263696.html centos7下安装lldb,dotnet netcore 进程生成转储文件,并使用lldb进行分析 ...
- 2019 钢银java面试笔试题 (含面试题解析)
本人3年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条. 钢银等公司offer,岗位是Java后端开发,最终选择去了 钢银. 面试了很多家公司,感觉大部分公司考察的点都差 ...
- python多任务的实现:线程,进程,协程
什么叫“多任务”呢?简单地说,就是操作系统可以同时运行多个任务.打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行.还有很多任务悄悄地在后 ...
- ResourceDictionary文件排序方法
默认生成的ResourceDictionary文件是根据主键的hashcode排序生成的,如果想按主键排序生成是不可能的. 可以使用Xml的处理方法来生成ResourceDictionary文件. 1 ...