可分离滤波器设计高斯滤波 CUDA程序优化, 实验记录
环境:RTX2060 ,1920X1080p ,循环10次, kernal_size=8
一 、测试前128个线程拷贝到dst数据的性能 ,只测试行卷积, block=(128+2r)X1
1. 使用中间128个线程拷贝 : (36.37+37.11+36.32)/3 = 36.6 GB
2. 改为前128个线程拷贝出数据: (38.89+39.53+39.74)/3 = 39.39GB
实验结果:使用前128个线程拷贝会快10.7%
二 、 测试const 变量对性能的影响 ,只测试行卷积 block =(128+2r)X1
1. radius 为局部变量(函数传入) 40.1 GB
2. radius 为__constant__ 变量 , 40.2GB
实验结果 __constant__ 和 局部变量 的性能实际上差不多
三、 测试block 线程数对性能的影响, 只测试行卷积
1. block = (64+2r)X1 37.10GB
2. block = (128+2r)X1 40.33GB
3. block = (256+2r)X1 37.75GB
4. block = (512+2r)X1 28.31GB
5. block = (128)X1 37.3GB
6. block=(320+2r)X1 34.26GB
7. block=320X1 39GB
8.block=160X1 38.57GB
9.block=(160+2r)X1 39.04GB
10 block=(640+2r)X1 30.34GB
11 block=640X1 27.96GB
实验结果 : block并不是越大越好, 选择 block = (128+2r)X1 可能好一点吧~
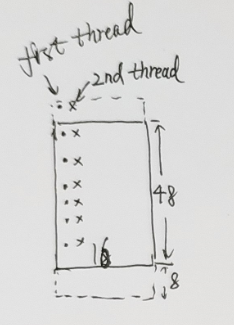
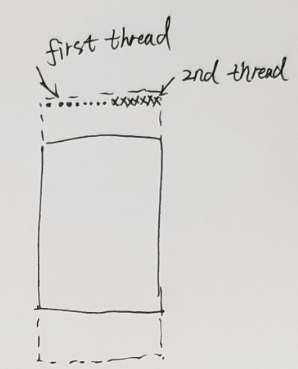
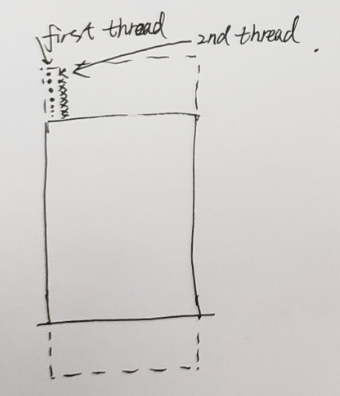
四、列卷积时候, 测试连续copy 和 跳步copy性能,只测试列卷积,行卷积注释掉
1. 跳步copy :45.11GB
2. 行连续copy:36.98GB
3 列连续copy:47.31GB
下图分别是1,2,3的拷贝过程示意图
实验结果: 使用第三种拷贝方式会加速4.9%
五、 使用单列拷贝 ,只测试列卷积
1. block=(128+2r)X1 18.89GB
实验结果: 使用单列进行计算会很慢
六 、 测试IMUL对性能的影响
1. 无IMUL 28.30GB
2. IMUL 28.38GB
实验结果 IMUL对实验结果无影响
七 、测试float4 对性能的影响,只测试行卷积
1. 无float4
2. float4
八 、列卷积时候, 测试连续计算 和 跳步计算性能,行卷积没有注释
连续计算 23.7GB
跳步计算 28.7 GB
实验结果: 跳步计算要快一些
可分离滤波器设计高斯滤波 CUDA程序优化, 实验记录的更多相关文章
- opencv 源码分析 CUDA可分离滤波器设计 ( 发现OpenCV的cuda真TM慢 )
1. 主函数 void SeparableLinearFilter::apply(InputArray _src, OutputArray _dst, Stream& _stream) { G ...
- 学习 opencv---(7) 线性邻域滤波专场:方框滤波,均值滤波,高斯滤波
本篇文章中,我们一起仔细探讨了OpenCV图像处理技术中比较热门的图像滤波操作.图像滤波系列文章浅墨准备花两次更新的时间来讲,此为上篇,为大家剖析了"方框滤波","均值滤 ...
- 滤波器——BoxBlur均值滤波及其快速实现
个人博客地址:滤波器--BoxBlur均值滤波及其快速实现 动机:卷积核.滤波器.卷积.相关 在数字图像处理的语境里,图像一般是二维或三维的矩阵,卷积核(kernel)和滤波器(filter)通常指代 ...
- matlab做gaussian高斯滤波
原文链接:https://blog.csdn.net/humanking7/article/details/46826105 核心提示 在Matlab中高斯滤波非常方便,主要涉及到下面两个函数: 函数 ...
- CUDA性能优化----warp深度解析
本文转自:http://blog.163.com/wujiaxing009@126/blog/static/71988399201701224540201/ 1.引言 CUDA性能优化----sp, ...
- SIFT四部曲之——高斯滤波
本文为原创作品,未经本人同意,禁止转载 欢迎关注我的博客:http://blog.csdn.net/hit2015spring和http://www.cnblogs.com/xujianqing/ 或 ...
- 一步步做程序优化-讲一个用于OpenACC优化的程序(转载)
一步步做程序优化[1]讲一个用于OpenACC优化的程序 分析下A,B,C为三个矩阵,A为m*n维,B为n*k维,C为m*k维,用A和B来计算C,计算方法是:C = alpha*A*B + beta* ...
- Java 程序优化 (读书笔记)
--From : JAVA程序性能优化 (葛一鸣,清华大学出版社,2012/10第一版) 1. java性能调优概述 1.1 性能概述 程序性能: 执行速度,内存分配,启动时间, 负载承受能力. 性能 ...
- Atitit 图像处理 平滑 也称 模糊, 归一化块滤波、高斯滤波、中值滤波、双边滤波)
Atitit 图像处理 平滑 也称 模糊, 归一化块滤波.高斯滤波.中值滤波.双边滤波) 是一项简单且使用频率很高的图像处理方法 用途 去噪 去雾 各种线性滤波器对图像进行平滑处理,相关OpenC ...
随机推荐
- SSM项目的搭建
本文示例在如下环境下搭建一个Maven+Druid+SSM+Shiro+Mysql+PageHelper以及Mybatis Generator反向生成代码的项目 附上GitHub地址:https:// ...
- Deep High-Resolution Representation Learning for Human Pose Estimation
Deep High-Resolution Representation Learning for Human Pose Estimation 2019-08-30 22:05:59 Paper: CV ...
- Typescript 开发环境的最佳实践
Typescript 开发环境的最佳实践 0️⃣ git init(略) 1️⃣️️ 初始化:$ yarn add -D ts-node typescript 2️⃣ 生成 tsconfig.json ...
- java8新特性一图整理
可以右键在新选项卡打开查看大图 原图地址:https://www.processon.com/view/5abb31abe4b027675e42cebc#map
- h5开发安卓机型点击输入框调起输入法,输入框被键盘遮挡的解决方法
前言: 从以前的项目中找一个问题的解决方案,顺带找到了这个安卓机型调起输入法,页面没有自动上滑导致输入框被弹起的键盘遮挡的解决方案.这个问题只有安卓机型页面中的输入框处于底部(也就是底部键盘区域)的时 ...
- ABS函数 去掉金额字段值为负数问题
)) from OrderDetail
- 转 : 请问mysql如何确定一个库是主库还是从库。
select user,host from mysql.user;SELECT Repl_slave_priv,Repl_client_priv,super_priv,host FROM mysql. ...
- [LeetCode] 750. Number Of Corner Rectangles 边角矩形的数量
Given a grid where each entry is only 0 or 1, find the number of corner rectangles. A corner rectang ...
- 【视频开发】RTSP SERVER(基于live555)详细设计
/* *本文基于LIVE555的嵌入式的RTSP流媒体服务器一个设计文档,个中细节现剖于此,有需者可参考指正,同时也方便后期自己查阅.(本版本是基于2011年的live555) 作者:llf_17@q ...
- Alpha版本2发布
0.日常开头 这个作业属于哪个课程 <课程的链接> 这个作业要求在哪里 <https://www.cnblogs.com/harry240/p/11524162.html> 团 ...