WeakhashMap源码1
弱引用(WeakReference)的特性是:当gc线程发现某个对象只有弱引用指向它,那么就会将其销毁并回收内存。WeakReference也会被加入到引用队列queue中。
它的特殊之处在于 WeakHashMap 里的entry可能会被GC自动删除,即使程序员没有调用remove()或者clear()方法。
可能发生如下情况:
- 调用两次size()方法返回不同的值;
- 两次调用isEmpty()方法,第一次返回false,第二次返回true;
- 两次调用containsKey()方法,第一次返回true,第二次返回false,尽管两次使用的是同一个key;
- 两次调用get()方法,第一次返回一个value,第二次返回null,尽管两次使用的是同一个对象。
WeekHashMap 的这个特点特别适用于需要缓存的场景。
GC判断某个对象是否可被回收的依据是,是否有有效的引用指向该对象。
这里的“有效引用”并不包括弱引用。也就是说,虽然弱引用可以用来访问对象。
将一对key, value放入到 WeakHashMap 里并不能避免该key对应的内存区域被GC回收。
既然有 WeekHashMap,是否有 WeekHashSet 呢?答案是没有,不过Java Collections工具类给出了解决方案,
// 将WeakHashMap包装成一个Set
Set<Object> weakHashSet = Collections.newSetFromMap(new WeakHashMap<Object, Boolean>());
如果存放在WeakHashMap中的key都存在强引用,那么WeakHashMap就会退化为HashMap。
使用WeakHashMap可以忽略容量问题,提升缓存容量。只是当容量不够时,不会OOM,内部数据会被GC回收。命中率好像没有办法,容我掉一片头发换来深度思考后给出方案。
观察WeakHashMap源码可以发现,它是线程不安全的,所以在多线程场景该怎么办嘞?
WeakHashMap<String, String> weakHashMapintsmaze=new WeakHashMap<String, String>();
Map<String, String> intsmaze=Collections.synchronizedMap(weakHashMapintsmaze);
public class Test11 {
private static final int _1MB = 1024 * 1024;// 设置大小为1MB
public static void main(String[] args) throws InterruptedException {
Object value = new Object();
WeakHashMap<Object, Object> map = new WeakHashMap<Object, Object>();
for (int i = 0; i < 100; i++) {
byte[] bytes = new byte[_1MB];
// bytes和value构成Entry,bytes是弱引用,没有别人指向,就回去回收这个Entry。
map.put(bytes, value);
} // 其实当我们在循环100次添加数据时,就已经开始回收弱引用了,因此我们会看到第一次打印的size是13,而不是100,一旦GC发生,那么弱引用就会被清除,导致WeakHashMap的大小为0。
//
while (true) {
System.gc();// 建议系统进行GC
Thread.sleep(500);
System.out.println(map.size());// 13 0 0 0 0
}
}
}
//WeakHashMap里面EntrySet的iterator()方法返回new EntryIterator(),
//EntryIterator的next和hashNext方法是对WeakHashMap的table做的遍历。
//所以new EntrySet(),就返回WeakHashMap的table的所有元素。 public class eee {
@SuppressWarnings("rawtypes")
public static void main(String[] args) {
Collection c = new eee().entrySet();//[6, 5, 4, 3, 2, 1]
Iterator iter = c.iterator();
while (iter.hasNext()) {
String entry = (String) iter.next();
System.out.println(entry);
}
}
String[] table = new String[]{"1","2","3","4","5","6"};
String[] table1 = new String[]{"11","21","31","41","51","61"};
private transient Set<String> entrySet; public Set<String> entrySet() {
Set<String> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());//是根据hasNext()和next()方法来确定集合元素的。
}
private class EntrySet extends AbstractSet<String> {
public Iterator<String> iterator() {
return new EntryIterator(); //return null 那么new EntrySet()就没有元素了。
}
@Override
public int size() {
return 0;
}
}
private class EntryIterator<String> implements Iterator<String> {
private int index;
EntryIterator() {
index = table.length;
// index = table1.length;
}
public boolean hasNext() {
if (index > 0) return true;
else return false;
}
public String next() {
return (String) table[--index];
// return (String) table1[--index];
}
}
}
当一个键对象被垃圾回收,那么相应的值对象的引用会从Map中删除。WeakHashMap能够节约存储空间,可用来缓存那些非必须存在的数据。
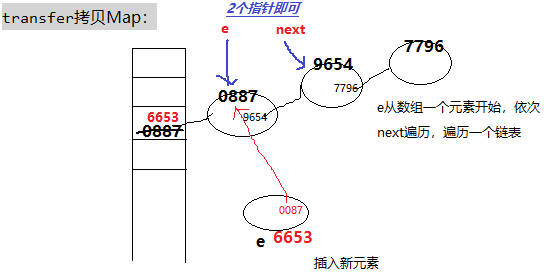
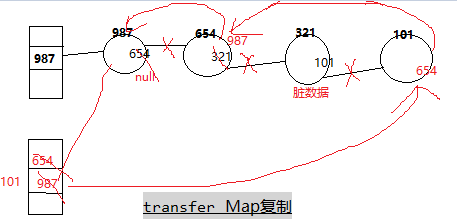
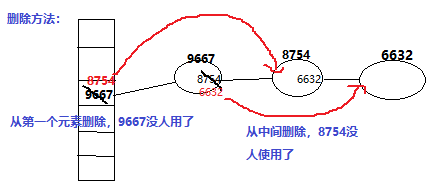
get,put,size,isEmpty,containsKey,getEntry,resize,拷贝,putAll,remove,containsValue,containsNullValue,forEach都会清理脏数据。
keySet,values,entrySet不会清理脏数据。
WeakHashMap是不同步的。可以使用 Collections.synchronizedMap 方法来构造同步的 WeakHashMap。
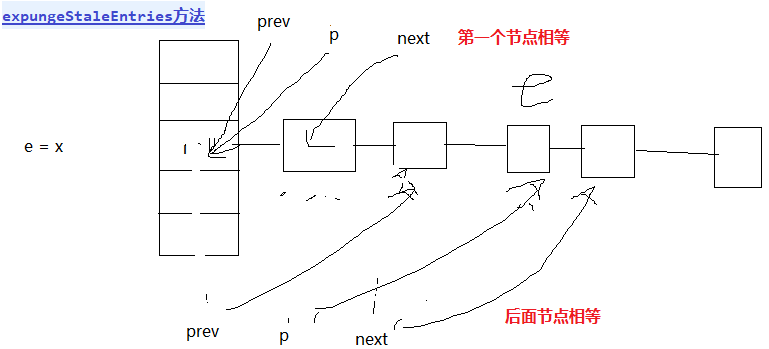
WeakHashMap的Key是弱引用,Value不是。WeakHashMap不会自动释放失效的弱引用table中 Entry,仅当包含了expungeStaleEntries()的共有方法被调用的时候才会释放。
WeakHashMap没有实现Clone和Serializable接口,所以不具有克隆和序列化的特性。
WeakHashMap因为gc的时候会把没有强引用的key回收掉,所以注定了它里面的元素不会太多,因此也就不需要像HashMap那样元素多的时候转化为红黑树来处理了。
WeakHashmap将会移除一些死的(dread)的entry,避免持有过多死的弱引用。
ReferenceQuene能够轻易的追踪这些死掉的弱引用。可以讲ReferenceQuene传入WeakHashmap的构造方法(constructor)中,这样,一旦这个弱引用里面的对象成为垃圾,这个弱引用将加入ReferenceQuene中。
public static void main(String args[]) {
WeakHashMap<String, String> map = new WeakHashMap<String, String>();
map.put(new String("1"), "1");
map.put("2", "2");
String s = new String("3");
map.put(s, "3");
while (map.size() > 0) {
try {
Thread.sleep(500);
} catch (InterruptedException ignored) {
}
System.out.println("Map Size:" + map.size());
System.out.println(map.get("1"));
System.out.println(map.get("2"));
System.out.println(map.get("3"));
System.gc();
}
}
}
运行结果(一直循环当中):
Map Size:3 1 2 3
Map Size:2 null 2 3
根据String的特性,
元素“1”的key已经没有地方引用了,所以进行了回收。
元素“2”是被放在常量池中的,所以没有被回收。
元素“3”因为还有变量s的引用,所以也没有进行回收。
public class ss {
public static void main(String[] args) {
System.out.println(test());//cde
}
private static String test(){
String a = new String("a");
System.out.println(a);//a
WeakReference<String> b = new WeakReference<String>(a);
System.out.println(b.get());//a
WeakHashMap<String, Integer> weakMap = new WeakHashMap<String, Integer>();
weakMap.put(b.get(), 1);//{a=1}
a = null;
System.out.println("GC前b.get():"+b.get());//a
System.out.println("GC前weakMap:"+weakMap);//{a=1}
System.gc();
System.out.println("GC后"+b.get());//null,a=null; System.gc()后,b!=null,b中的a也被系统回收了,
System.out.println("GC后"+weakMap);//{}
String c = "";
try{
c = b.get().replace("a", "b");//b.get()为null,会抛出异常。
System.out.println("C:"+c);
return c;
}catch(Exception e){
//finally有renturn,从finally退出。finally没有renturn,从try退出。
//try 换成 catch 去理解就 OK 了
c = "c";
System.out.println("Exception");
return c;
}finally{
c += "d";
return c + "e";
}
}
}
public class WeakHashMapTest {
public static void main(String[] args) {
WeakHashMap w= new WeakHashMap();
//三个key-value中的key 都是匿名对象,没有强引用指向该实际对象
w.put(new String("语文"),new String("优秀"));
w.put(new String("数学"), new String("及格"));
w.put(new String("英语"), new String("中等"));
//增加一个字符串的强引用
w.put("java", new String("特别优秀"));
System.out.println(w); //{java=特别优秀, 数学=及格, 英语=中等, 语文=优秀}
//通知垃圾回收机制来进行回收
System.gc();
System.runFinalization();
//再次输出w
System.out.println("第二次输出:"+w); //第二次输出:{java=特别优秀}
}
}
spliterator是java1.8引入的一种并行遍历的机制,Iterator提供也提供了对集合数据进行遍历的能力,但一个是顺序遍历,一个是并行遍历。
OfInt sInt = Arrays.spliterator(arr, 2, 5);//下标,包头不包尾。截取。
public static Spliterator.OfInt spliterator(int[] array, int startInclusive, int endExclusive) {
return Spliterators.spliterator(array, startInclusive, endExclusive,
Spliterator.ORDERED | Spliterator.IMMUTABLE);
}
public static Spliterator.OfInt spliterator(int[] array, int fromIndex, int toIndex,
int additionalCharacteristics) {
checkFromToBounds(Objects.requireNonNull(array).length, fromIndex, toIndex);
return new IntArraySpliterator(array, fromIndex, toIndex, additionalCharacteristics);
}
public IntArraySpliterator(int[] array, int origin, int fence, int additionalCharacteristics) {
this.array = array;
this.index = origin;
this.fence = fence;
this.characteristics = additionalCharacteristics | Spliterator.SIZED | Spliterator.SUBSIZED;
}
public boolean tryAdvance(IntConsumer action) {//对分割后的数组依次调用函数
if (action == null)
throw new NullPointerException();
if (index >= 0 && index < fence) {
action.accept(array[index++]);
return true;
}
return false;
}
public OfInt trySplit() {//返回分割的数组
int lo = index, mid = (lo + fence) >>> 1;
return (lo >= mid)
? null
: new IntArraySpliterator(array, lo, index = mid, characteristics);
}
public void forEachRemaining(IntConsumer action) {
int[] a; int i, hi; // 每个元素执行给定的操作
if (action == null)
throw new NullPointerException();
if ((a = array).length >= (hi = fence) &&
(i = index) >= 0 && i < (index = hi)) {
do { action.accept(a[i]); } while (++i < hi);
}
}
public interface IntConsumer {
void accept(int value);
default IntConsumer andThen(IntConsumer after) {
Objects.requireNonNull(after);
return (int t) -> { accept(t); after.accept(t); };
}
}
andThen方法是由IntConsumer 对象调用的,返回值是IntConsumer 类型:一个函数,首先调用 调用andThen方法的对象的accept()方法,然后调用after的accept方法。
public boolean tryAdvance(IntConsumer action) {
if (action == null)
throw new NullPointerException();
if (index >= 0 && index < fence) {
action.accept(array[index++]);
return true;
}
return false;
}
public class ffff {
public static void main(String[] args) {
int[] arr = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
OfInt sInt = Arrays.spliterator(arr, 2, 5);// 返回3 4 5
IntConsumer consumer = new IntConsumer() {
public void accept(int value) {
System.out.println(value);
}
};
sInt.tryAdvance(consumer.andThen(new IntConsumer() {//先调用consumer的accept方法,在调用new IntConsumer()匿名内部类的accept方法,
public void accept(int value) {
System.out.println("i am after");
}
}));
sInt.tryAdvance(consumer.andThen(new IntConsumer() {
public void accept(int value) {
System.out.println("i am after");
}
}));
sInt.tryAdvance(consumer.andThen(new IntConsumer() {
public void accept(int value) {
System.out.println("i am after");
}
}));
sInt.tryAdvance(consumer.andThen(new IntConsumer() {
public void accept(int value) {
System.out.println("i am after");
}
}));
//3 i am after,4 i am after,5 i am after
}
public static void main3(String[] args) {
int[] arr ={ 1, 2, 3, 4, 5, 6 };
IntConsumer consumer = new IntConsumer() {// IntConsumer的accept参数只能是int
@Override
public void accept(int value) {
System.out.println(value);
}
};
OfInt sInt = Arrays.spliterator(arr);// sInt = {1,2,3,4,5,6}
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);// 1,2,3,4,5,6
OfInt sInt1 = sInt.trySplit();// sInt1是sInt的前一半{1,2,3},sInt是后一半{4,5,6}
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);// 只有4 5 6
sInt1.tryAdvance(consumer);
sInt1.tryAdvance(consumer);
sInt1.tryAdvance(consumer);
sInt1.tryAdvance(consumer);
sInt1.tryAdvance(consumer);
sInt1.tryAdvance(consumer);// 只有1 2 3
}
public static void main2(String[] args) {
int[] arr = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
OfInt sInt = Arrays.spliterator(arr, 2, 5);// 下标,包头不包尾。截取。
IntConsumer consumer = new IntConsumer() {
@Override
public void accept(int value) {
System.out.println(value);
}
};
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
/*
if (index >= 0 && index < fence) { consumer.accept(array[index++]);
index和fence是sInt的属性
*/
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);// 只输出3 4 5 ,遍历截取后的元素。
}
public static void main1(String[] args) {
int[] arr = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
OfInt sInt = Arrays.spliterator(arr);
IntConsumer consumer = new IntConsumer() {
@Override
public void accept(int value) {
System.out.println(value);
}
};
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);
sInt.tryAdvance(consumer);// 输出 1, 2, 3, 4, 5, 6, 7, 8, 9
}
}
Spliterator就是为了并行遍历元素而设计的一个迭代器,jdk1.8中的集合框架中的数据结构都默认实现了spliterator,可以和iterator顺序遍历迭代器一起看。
Spliterator(splitable iterator可分割迭代器)接口是Java为了并行遍历数据源中的元素而设计的迭代器,这个可以类比最早Java提供的顺序遍历迭代器Iterator,但一个是顺序遍历,一个是并行遍历
第一个方法tryAdvance就是顺序处理每个元素,类似Iterator,如果还有元素要处理,则返回true,否则返回false
第二个方法trySplit,这就是为Spliterator专门设计的方法,区分与普通的Iterator,该方法会把当前元素划分一部分出去创建一个新的Spliterator作为返回,两个Spliterator变会并行执行,如果元素个数小到无法划分则返回null。二分法。
第三个方法estimateSize,该方法用于估算还剩下多少个元素需要遍历
第四个方法characteristics,其实就是表示该Spliterator有哪些特性,用于可以更好控制和优化Spliterator的使用,具体属性你可以随便百度到,这里就不再赘言
从最早Java提供顺序遍历迭代器Iterator时,那个时候还是单核时代,但现在多核时代下,顺序遍历已经不能满足需求了...如何把多个任务分配到不同核上并行执行,才是能最大发挥多核的能力,所以Spliterator应运而生啦
对于Spliterator接口的设计思想,应该要提到的是Java7的Fork/Join(分支/合并)框架,总得来说就是用递归的方式把并行的任务拆分成更小的子任务,然后把每个子任务的结果合并起来生成整体结果。带着这个理解来看看Spliterator接口提供的方法
WeakhashMap源码1的更多相关文章
- Java WeakHashMap 源码解析
前面把基于特定数据结构的Map介绍完了,它们分别利用了相应数据结构的特点来实现特殊的目的,像HashMap利用哈希表的快速插入.查找实现O(1)的增删改查,TreeMap则利用了红黑树来保证key的有 ...
- 死磕 java集合之WeakHashMap源码分析
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 简介 WeakHashMap是一种弱引用map,内部的key会存储为弱引用,当jvm gc的时 ...
- WeakHashMap源码解读
1. 简介 本文基于JDK8u111的源码分析WeakHashMap的一些主要方法的实现. 2. 数据结构 就数据结构来说WeakHashMap与HashMap原理差不多,都是拉链法来解决哈希冲突. ...
- WeakHashMap源码分析
WeakHashMap是一种弱引用map,内部的key会存储为弱引用, 当jvm gc的时候,如果这些key没有强引用存在的话,会被gc回收掉, 下一次当我们操作map的时候会把对应的Entry整个删 ...
- WeakhashMap源码2
public class WeakHashMapIteratorTest { @SuppressWarnings({ "rawtypes", "unchecked&quo ...
- WeakHashMap 源码分析
WeakHashMap WeakHashMap 能解决什么问题?什么时候使用 WeakHashMap? 1)WeakHashMap 是基于弱引用键实现 Map 接口的哈希表.当内存紧张,并且键只被 W ...
- Java 集合系列13之 WeakHashMap详细介绍(源码解析)和使用示例
概要 这一章,我们对WeakHashMap进行学习.我们先对WeakHashMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用WeakHashMap.第1部分 WeakHashMap介绍 ...
- JDK源码分析(9)之 WeakHashMap 相关
平时我们使用最多的数据结构肯定是 HashMap,但是在使用的时候我们必须知道每个键值对的生命周期,并且手动清除它:但是如果我们不是很清楚它的生命周期,这时候就比较麻烦:通常有这样几种处理方式: 由一 ...
- WeakHashMap,源码解读
概述 WeakHashMap也是Map接口的一个实现类,它与HashMap相似,也是一个哈希表,存储key-value pair,而且也是非线程安全的.不过WeakHashMap并没有引入红黑树来尽量 ...
随机推荐
- mvc5中webapi的路由
1.Global.asax中路由的注册 public class WebApiApplication : System.Web.HttpApplication { protected void App ...
- Python文件属性模块Os.path
Python文件属性模块Os.path介绍 os.path模块主要用于文件属性获取和判断,在编程中会经常用到,需要熟练掌握.以下是该模块的几种常用方法. os.path官方文档:http://docs ...
- 攻防世界-web -高手进阶区-PHP2
题目 首先发现源码泄露 /index.phps 查看源代码 即: <?php if("admin"===$_GET[id]) { echo("<p>no ...
- js中的原型,原型链和继承
在传统的基于Class的语言如Java.C++中,继承的本质是扩展一个已有的Class,并生成新的Subclass. 由于这类语言严格区分类和实例,继承实际上是类型的扩展.但是,JavaScript最 ...
- Android开发之EditText多行文本输入
<EditText android:id="@+id/add_content" android:layout_width="fill_parent" an ...
- day 46
目录 CSS样式操作 给字体设置长宽 字体颜色 语义 背景图片 边框 display 盒子模型 浮动(**************) 浮动带来的影响 clear overflow溢出属性 定位 位置的 ...
- 景点API支持查询携程旅游门票景点详情
门票景点详情,景点api支持查询携程旅游门票景点详情. 接口名称:景点api 接口平台:开放api 接口地址:http://api2.juheapi.com/xiecheng/senicspot/ti ...
- mysql--日志文件
1 选择常规查询日志和慢查询日志输出目标 1.1 log_output查看.定义 所谓的输出目标就是日志写入到哪里,mysql中用系统变量 log_output来指定输出目标,log_output的 ...
- (原+修改)ubuntu上离线安装pytorch
转载请注明出处: https://www.cnblogs.com/darkknightzh/p/12000809.html 参考网址: https://blog.csdn.net/qq_4193655 ...
- 树莓派初入门(1):SSH远程登录与VNC远程桌面
前言: 本文主要讲解,对于一个无树莓派显示屏,无键盘,无鼠标,手边只有手机,电脑和一个已烧录好raspbian-stretch系统的树莓派3B+的玩家,如何进行远程登录,进而可以进程桌面的连接. 工具 ...