ufunc函数

无灯可看。雨水从教正月半。探茧推盘。探得千秋字字看。
铜驼故老。说著宣和似天宝。五百年前。曾向杭州看上元。
ufunc是universal function的缩写,他是一种对数组的每个元素进行运算的函数。NumPy的内置许多函数都是用C语言实现的因此,他们的计算速度十分的快。
>>> x = np.linspace(0,2*np.pi,10)
>>> x
array([ 0. , 0.6981317 , 1.3962634 , 2.0943951 , 2.7925268 ,
3.4906585 , 4.1887902 , 4.88692191, 5.58505361, 6.28318531])
>>> y = np.sin(x)
>>> y
array([ 0.00000000e+00, 6.42787610e-01, 9.84807753e-01,
8.66025404e-01, 3.42020143e-01, -3.42020143e-01,
-8.66025404e-01, -9.84807753e-01, -6.42787610e-01,
-2.44929360e-16])
可以查看函数的使用方法,得到使用方法。
下面我们比较一下np.sin()和math.sin()的时间复杂度。
#coding:utf-8
import math
import datetime
import numpy as np x = np.array([i* 0.001 for i in range(3000000)]) def sin_math(x):
beg = datetime.datetime.now()
for i,t in enumerate(x): # 返回下标和元素。
x[i] = math.sin(t)
end = datetime.datetime.now()
return end-beg def sin_np(x):
beg = datetime.datetime.now()
np.sin(x,x)
end = datetime.datetime.now()
return end-beg print(sin_math(x),sin_np(x))
最后得到的结构大概 np.sin()的速度比math.sin()快5倍。这得益于np.sin()的C语言级别的计算。
实际上标准的Python中可以用列表推导式的方法得到比for循环更快的计算效果。x = [math.sin(t) for t in x] ,但是列表推导式将产生一个新的列表,而不是修改原来的列表,相当于用 空间换了时间。
四则运算
NumPy提供了许多的ufunc函数,例如计算两个数组之和的add()函数。
>>> a+b
array([ 5, 7, 9, 11])
>>> a = np.arange(0,4)
>>> b = np.arange(5,9)
>>> a+b
array([ 5, 7, 9, 11])
>>> np.add(a,b)
array([ 5, 7, 9, 11])
add()将返回一个数组,这个同样可以指定out参数,如果没有指定则创建一个新的数组来保存计算结果。
>>> np.add(a,b,a)
array([ 5, 7, 9, 11])
>>> a
array([ 5, 7, 9, 11])
NumPy位数组定义了各种数学运算操作符,因此计算两个数组想家可以简单的写成a+b而,而np.add(a,b,a)则可以用a += b来表示。下标列出了数组的运算符,以及与之对应的ufunc

数组对象支持操作符,极大地简化了算式的编写,但是需要注意,如果算式很复杂,要产生大量的中间结果这样就会降低程序的运算速度,例如堆a,b,c,三个数组采用算法进行 x = a * b + c 它相当于
t = a * b
x = t + c
del t
我们可以通过分解算式来将上述的一句话,变成两句话,且减少一次内存分配。
x = a * b
x += c
使用比较运算符堆两个数组进行运算的时候,将返回一个Bool 数组, 他的每个元素值都是两个数组对应元素的比较结果 eg:
>>> np.array([1,2,3,4]) < np.array([4,3,2,1])
array([ True, True, False, False], dtype=bool)
每个比较运算符都有一个ufunc 函数对应, 表2-2是比较运算符与ufunc 函数的对照表。

因为Python中的布尔运算使用,and,or和not等关键字,他们无法被重载,因此数组的布尔运算只能通过相应的ufunc函数进行,这些函数都以logical_开头,可以通过自动补齐来找到相应函数。

>>> a = np.arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> b = np.arange(4,-1,-1)
>>> b
array([4, 3, 2, 1, 0])
>>> print (a == b)
[False False True False False]
>>> print(a>b)
[False False False True True]
>>> print(np.logical_and(a,b))
[False True True True False]
>>> print(a == b,a>b)
[False False True False False] [False False False True True]
自定义ufunc函数
通过NumPy提供的标准ufunc函数,可以组合出复杂的表达式,在C语言级别堆数组的每个元素进行计算。但是这种表达式不易编写,而对元素进行计算的程序却很容易用Python实现,这时候可以通过frompyfunc()将计算单个元素的函数转换成ufunc函数,这样就可以很方便的用所产生的ufunc函数对数组进行计算了。
例如我们可以通过一个分段函数描述三角波,三角波的形状如图所示,它分为三段:上升段,下降段和平坦段。
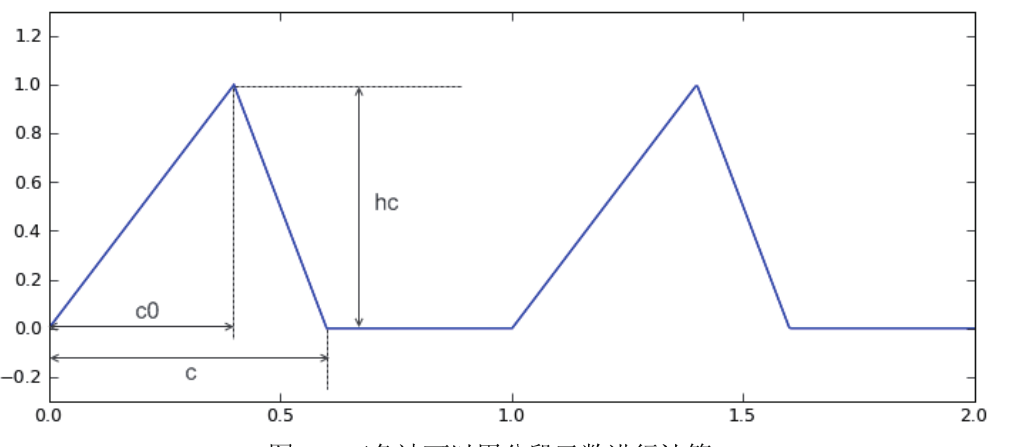
根据图2-5,我们可以很容易的写出计算三角波上某点的Y坐标函数,显然triangle_wave()只能计算单个数值,不能直接堆数组进行处理。
import numpy as np
import matplotlib.pyplot as plt def triangle_wave(x,c,c0,hc):
x = x - int(x) #三角波的周期位1,因此只取x坐标的小数部分进行计算。
if x > c:
r = 0.0
elif x < c0:
r = x / c0 * hc
else:
r = (c - x)/(c - c0) * hc return r x = np.linspace(0,2,1000)
y1 = np.array([triangle_wave(t,0.6,0.4,1.0) for t in x]) plt.plot(x,y1)
plt.show()

通过frompyfunc()可以将计算单个值的函数转换为能对数组的每个元素进行计算的ufunc函数。frompyfunc的调用格式为:
frompyfunc(func,nin,nout)
其中func是计算单个元素的函数,nin是func的输入参数的个数,nout是func的返回值的个数。下面的程序使用frompyfunc()将triangle_wave()转换为ufunc函数对象triangle_ufunc1:
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 14 13:24:50 2017 @author: x-power
"""
import numpy as np
import matplotlib.pyplot as plt def triangle_wave(x,c,c0,hc):
x = x - int(x) #三角波的周期位1,因此只取x坐标的小数部分进行计算。
if x > c:
r = 0.0
elif x < c0:
r = x / c0 * hc
else:
r = (c - x)/(c - c0) * hc return r x = np.linspace(0,2,1000)
y1 = np.array([triangle_wave(t,0.6,0.4,1.0) for t in x]) triangle_ufunc = np.frompyfunc(triangle_wave,4,1)
y2 = triangle_ufunc(x,0.6,0.3,1) print("y1的类型是:" + str(y1.dtype)) print("y2的类型是:" + str(y2.dtype)) y2 = y2.astype(np.float) print("转换之后的y2类型是:" + str(y2.dtype)) print("如果使用np.frompyfunc的话,返回值的类型是object很尴尬,如果需要方便的使用的话,需要转换类型。") #plt.plot(x,y1)
#plt.plot(x,y2)
#
#plt.show()
广播
当使用ufunc函数堆两个数组进行计算的时候,ufunc函数会对这两个数组的对应元素进行计算,因此其要求两个数组的shape相同,不同的话会进行广播处理( broadcasting )处理:
1)让所有的输入数组都向其中维数最多的数组看齐,shape属性中不足的部分都通过向前面加1 的当时补齐。
2)输出的数组的shape属性是输入数组的shape属性的各个轴上的最大值。
3)如果输入数组的某个轴长度为 1 时,沿着此轴运算时都用此轴上的第一组值。
talk is cheap , show me your code !
import numpy as np
import matplotlib.pyplot as plt a = np.arange(0,60,10).reshape(-1,1)
b = np.arange(0,5) c = a + b print("a的形状是:" + str(a.shape))
print(a) print("b的形状是:" + str(b.shape))
print(a) print("c的形状是:" + str(c.shape))
print(c)
a的形状是:(6, 1)
[[ 0]
[10]
[20]
[30]
[40]
[50]]
b的形状是:(5,)
[[ 0]
[10]
[20]
[30]
[40]
[50]]
c的形状是:(6, 5)
[[ 0 1 2 3 4]
[10 11 12 13 14]
[20 21 22 23 24]
[30 31 32 33 34]
[40 41 42 43 44]
[50 51 52 53 54]]
由于a和b的维数不同,根据规则1),需要让b的shape属性向a 对齐,于是在b的 shape属性前 加 1,补齐位(1,5).相当于做了如下计算:
b.shape = 1,5
这样加法运算的两个输入数组的shape属性分别为(6,1)和(1,5),根据规则2)输出数组的各个轴的长度位输入数组的各个轴长度的最大值,可知输出数组的shape属性为(6,5)。
由于b的第0轴长度为1,而a的第0轴长度为6,为了让他们在第0轴上能够相加,需要将b的第0轴的长度扩展为6,这相当于:
b
Out[16]: array([[0, 1, 2, 3, 4]]) b = b.repeat(6,0) b
Out[18]:
array([[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]])
这里的repeat()方法沿着axis参数指定的轴复制数组中的各个元素的值。由于a的第 1 轴的长度为 1 而b的第1轴的长度为5,为了能够让他们相加,需要将a的第一轴的长度扩展为5 这相当于:
a
Out[19]:
array([[ 0],
[10],
[20],
[30],
[40],
[50]]) a = a.repeat(5,1) a
Out[21]:
array([[ 0, 0, 0, 0, 0],
[10, 10, 10, 10, 10],
[20, 20, 20, 20, 20],
[30, 30, 30, 30, 30],
[40, 40, 40, 40, 40],
[50, 50, 50, 50, 50]])
经过上述处理就可以让 a 和 b进行相加计算了。可是这样不是很浪费内存么?由于这种广播计算使用频率比较高,所以一定是要有解决办法的。因此NumPy提供了ogrid对象,用于创建广播运算用的数组。
x,y = np.ogrid[:5,:5]
print(x)
print(y)
[[0]
[1]
[2]
[3]
[4]]
[[0 1 2 3 4]]
此外,NumPy还提供了mgrid对象,它的用法和ogrid对象类似,但是它所返回的是进行广播之后的数组:
x,y = np.mgrid[:5,:5]
print(x)
print(y)
[[0 0 0 0 0]
[1 1 1 1 1]
[2 2 2 2 2]
[3 3 3 3 3]
[4 4 4 4 4]]
[[0 1 2 3 4]
[0 1 2 3 4]
[0 1 2 3 4]
[0 1 2 3 4]
[0 1 2 3 4]]
ogrid是一个很有趣的对象,它像是多维数组一样,用切片元祖作为下标,返回的是一组可以用来广播计算的数组,其切片下标有两种形式:
- 开始值:结束值:步长,和np.arange(开始,结束,步长)类似
- 开始值:结束值:长度j,当第三个参数为虚数的时候,它表示所返回数组的长度和np.linspace(开始值,结束值,长度)类似。
x = np.arange(0,1,0.1)
y = np.linspace(0,1,10)
print(x)
print(y)
x,y = np.ogrid[:1:4j,:1:3j]
print(x)
print(y)
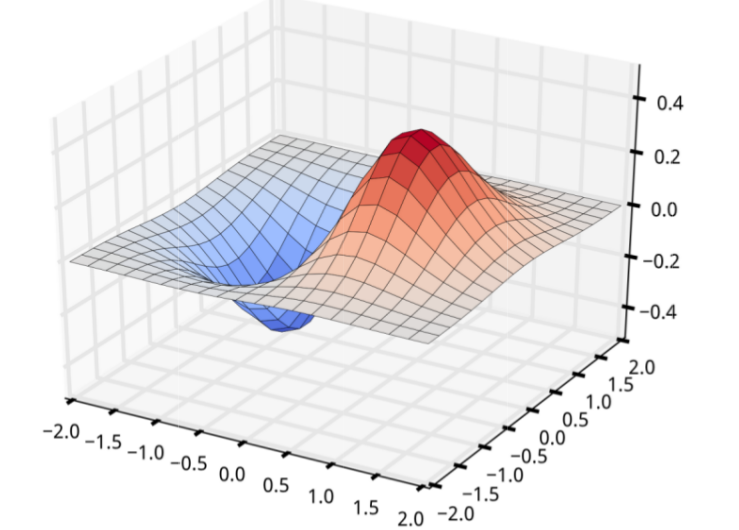
x,y = np.ogrid[-2:2:20j,-2:2:20j]
z = x + np.exp(-x**2 - y**2)
下图则位使用ogrid()函数,计算二元函数在等间隔网格上的值,下面是绘制三维曲面(x,y)= xex^2-y^2的图形。
为了充分利用ufunc的广播功能,我们经常需要调整数组的形状,因此数组支持特殊的下标对象None,它表示在None对应的位置创建一个长度为1的新轴。例如堆一维数组a,a[None,:]和a.reshape(1,-1)等效,而a[:,None]和a.shape(-1,1)等效:
a = np.arange(4)
print(a[:,None])
print("\n\n\n")
print(a[None,:])
runfile('/home/x-power/untitled0.py', wdir='/home/x-power')
[[0]
[1]
[2]
[3]]
[[0 1 2 3]]
下面的例子以None作为下标,实现广播运算。
x = np.array([0,1,4,10])
y = np.array([2,3,8])
print(x[None,:])
print(y[:,None])
print(x[None,:]+y[:,None])
[[ 0 1 4 10]]
[[2]
[3]
[8]]
[[ 2 3 6 12]
[ 3 4 7 13]
[ 8 9 12 18]]
真正的英雄都是在最后力挽狂澜的,这句话说的真他么的对,狗日的。
x = np.array([0,1,4,10])
y = np.array([2,3,8])
gy,gx = np.ix_(y,x)
print(gy + gx)
[[ 2 3 6 12]
[ 3 4 7 13]
[ 8 9 12 18]]
在上面的例子中,通过ix_()将数组x和y转换成能进行广播运算的二维数组,注意数组y对应广播运算结果中的0轴,而数组x与第1轴相对应。
ufunc函数的更多相关文章
- 『Numpy』高级函数_np.nditer()&ufunc运算
1.np.nditer():numpy迭代器 默认情况下,nditer将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值得修改,必须指定op_flags=[' ...
- Pandas的函数应用、层级索引、统计计算
1.Pandas的函数应用 1.apply 和 applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random ...
- NumPy-快速处理数据--ufunc运算--广播--ufunc方法
本文摘自<用Python做科学计算>,版权归原作者所有. 1. NumPy-快速处理数据--ndarray对象--数组的创建和存取 2. NumPy-快速处理数据--ndarray对象-- ...
- numpy的通用函数:快速的元素级数组函数
通用函数(ufunc)是对ndarray中的数据执行元素级运算的函数.可看作简单函数的矢量化包装. 一元ufunc sqrt对数组中的所有元素开平方 exp对数组中的所有元素求指数 In [93]: ...
- Python数据分析入门(六):Pandas的函数应用
apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) p ...
- 利用Python进行数据分析(6) NumPy基础: 矢量计算
矢量化指的是用数组表达式代替循环来操作数组里的每个元素. NumPy提供的通用函数(既ufunc函数)是一种对ndarray中的数据进行元素级别运算的函数. 例如,square函数计算各元素的平方,r ...
- 数据分析之Numpy基础:数组和适量计算
Numpy(Numerical Python)是高性能科学计算和数据分析的基础包. 1.Numpy的ndarray:一种多维数组对象 对于每个数组而言,都有shape和dtype这两个属性来获取数组的 ...
- [Python学习] python 科学计算库NumPy—矩阵运算
NumPy库的核心是矩阵及其运算. 使用array()函数可以将python的array_like数据转变成数组形式,使用matrix()函数转变成矩阵形式. 基于习惯,在实际使用中较常用array而 ...
- 《利用python进行数据分析》读书笔记--第四章 numpy基础:数组和矢量计算
http://www.cnblogs.com/batteryhp/p/5000104.html 第四章 Numpy基础:数组和矢量计算 第一部分:numpy的ndarray:一种多维数组对象 实话说, ...
随机推荐
- NYOJ 1067 Compress String(区间dp)
Compress String 时间限制:2000 ms | 内存限制:65535 KB 难度:3 描写叙述 One day,a beautiful girl ask LYH to help he ...
- [LeetCode] 038. Count and Say (Easy) (C++/Python)
索引:[LeetCode] Leetcode 题解索引 (C++/Java/Python/Sql) Github: https://github.com/illuz/leetcode 038. Cou ...
- java使用默认线程池踩过的坑(三)
云智慧(北京)科技有限公司 陈鑫 重新启动线程池 TaskManager public class TaskManager implements Runnable { -.. public TaskM ...
- POJ2251 Dungeon Master —— BFS
题目链接:http://poj.org/problem?id=2251 Dungeon Master Time Limit: 1000MS Memory Limit: 65536K Total S ...
- eclipse创建maven项目出现以下报错: org.apache.maven.archiver.MavenArchiver.getManifest (org.apache.maven.project.MavenProject,org.apache.mav en.archiver.MavenArchiveConfiguration)
解决方法: 更新eclipse中的maven插件 Help -> Install New Software -> add -> http://repo1.maven.org/ma ...
- html5--6-67 阶段练习8-弹性三列布局
html5--6-67 阶段练习8-弹性三列布局 学习要点 运用弹性盒子模型完成一个三列布局,加深对学过知识点的综合应用能力. 了解用百分比设置元素高度的方法. @charset="UTF- ...
- Extjs散记
在元素的后面添加文字,如 汇率:_____% { fieldLabel : '输入框', xtype : 'textfield', anchor : '80%', listeners: { ...
- Netty代码分析
转自:http://www.blogjava.net/BucketLi/archive/2010/12/28/332462.html Netty提供异步的.事件驱动的网络应用程序框架和工具,用以快速开 ...
- Echarts饼状图
<head> <meta charset="utf-8"> <title>ECharts</title> <script sr ...
- 创建app前的环境配置/AppIcon/启动图片
1.真机调试http://blog.csdn.net/tht2009/article/details/48580569 2.创建app前的环境配置