javascript 大数据处理方法
随着前端的飞速发展,在浏览器端完成复杂的计算,支配并处理大量数据已经屡见不鲜。那么,如何在最小化内存消耗的前提下,高效优雅地完成复杂场景的处理,越来越考验开发者功力,也直接决定了程序的性能。
本文展现了一个完全在控制台就能模拟体验的实例,通过一步步优化,实现了生产并操控多个1000000(百万级别)对象的场景。
导读:这篇文章涉及到 javascript 中 数组各种操作、原型原型链、ES6、classes 继承、设计模式、控制台分析 等内容。
要求阅读者具有 js 面向对象扎实的基础知识。如果你是初级前端开发者,很容易被较为复杂的逻辑绕的云里雾里,“从入门到放弃”,不过建议先收藏。如果你是“老司机”,本文提供的解决思路希望对你有所启发,抛砖引玉。
场景和初级感知
具体来说,我们需要一个构造函数,或者说类似 factory 模式,实例化1000000个以上对象实例。
先来感知一下具体实现:
Step1
打开你的浏览器控制台,仔细观察并复制粘贴以下代码,触发执行。
a = new Array(1e6).fill(0);
我们创建了一个长度为1000000的数组,数组的每一项元素都为0。
Step2
在数组 a 的基础上,再生产一个长度为1000000的数组 b,数组的每一项元素都是一个普通 javascript object,拥有 id 属性,并且其 id 属性值为其在元素中的 index 值;
b = a.map((val, ix) => ({id: ix}))
Step3
接下来,在 b 的基础上,再生产一个长度为1000000的数组 c ,类似于 b,同时我们增加一些其它属性,使得数组元素对象更加复杂一些:
c = a.map((val, ix) => ({id: ix, shape: 'square', size: 10.5, color: 'green'}))
语义上,我们可以更直观的理解:c 就是包含了1000000个元素的数组,每一项都是一个绿色的、size 为10.5的小方块。
如果你按照指示做了下来,控制台上会有以下内容:
深层探究
你也许会想,这么大的数据量,内存占用会是什么样的情况呢?
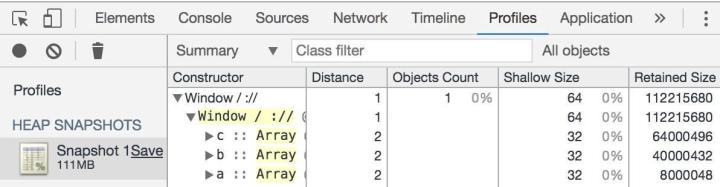
好,我来带你看看,点击控制台 Profiles,选择 Take Shapshot。在Window->Window 目录下,根据内存进行筛选,你会得到:

很明显,我们看到:
- a数组:8MB;
- b数组:40MB;
- c数组:64MB
也许在实际场景中,除了1000000个绿色的、size为10.5的小方块,我们还需要很多不同颜色,不同 size 的形状。之前,这样“变态”的需求常见于游戏应用中。但是现在,复杂项目中类似场景,也许距离你并不遥远。
ES6 Classes处理需求
简单“热身”之后,我们了解了实际需求。接下来,我们考察一下 ES6 Classes 处理这个问题的情况。请重新刷新浏览器 tab,复制执行以下代码。
class Shape {
constructor (id, shape = 'square', size = 10.5, color = 'green') {
this.x = x; // 坐标x轴
this.y = y; // 坐标y轴
Object.assign(this, {id, shape, size, color})
}
}
a = new Array(1e6).fill(0);
b = a.map((val, ix) => new Shape(ix));
我们使用了ES6 Classes,并扩充了每个形状的坐标信息。 此时,再来看一下内存占用情况:

很明显,此时 b 数组由100000个形状组成,占据内存:80MB,超过了先前数组的内存消耗。也许这并不出乎意料,此时的b数组毕竟又多了两个属性。
优化设计:Two-Headed Classes
我们先来分析一下上面的实现,熟悉原型链、原型概念的同学也许会明白,之前的方案产生的实例,顺着原型链上溯,具有三层原型属性:
第一层:[id, shape, size, color, x, y]; 这一层属性的 hasOwnproperty 为 true; 属性存在于实例本身。
第二层:[Shape]; 顺着原型链上溯,这一层 instance.proto === Constructor.prototype; ( proto 左右两边 __ 被编辑器吃掉了,请见谅,下同)
第三层:[Object]; 这一层: instance.proto.__proto__ === Object.prototype; 如果在向上追溯,就为 null 了。
这样的情况下,实际业务数据层只有一层,即为第一层。
但是,请仔细思考,如果有大量的不同颜色,不同size,不同形状的情况下。单一数据层,是难以满足我们需求的。 我们需要,再添加一层数据层,构成所谓的 Two-Headed Classes!同时,还需要对于默认的属性,实现共享,以节省内存的占用。
什么什么?没听明白,那就请看具体操作吧。
如何实现?
我们可以使用 Object.create 方法,这样使得生产得到的实例的 proto 指向 b 数组的元素,然后在最顶层设计一个 id 属性。
也许这样说过于晦涩,那就直接参考代码吧,请注意,这是本篇文章最难以理解的地方,请务必仔细揣摩:
two = Object.create(b[0]);
// two.__proto__ === b[0]
two.id = 1;
还记得 b 数组是什么嘛?参考上文,它由
b = a.map((val, ix) => new Shape(ix));
得到。
这样子的话,对于每一个实例,我们有如下关系:
第一层:[id]; 这一层实例的 hasOwnproperty 为 true;
第二层:[id, shape, size, color, x, y]; 这一层 instance.proto === Constructor.prototype;
第三层:[Shape];
第四层:[Object]; 这一层的再顶层,就为null了。
我们将 Shape 的一个实例作为一个新的 object 的原型,并复写了 id 属性,原有的 id 属性将作为默认 id。
当然,上边的代码只是“个案”,我们进行“生产化”:
proto = new Shape(0);
function newTwoHeaded (ix) {
const obj = Object.create(proto);
obj.id = ix;
return obj
}
c = a.map((val, ix) => newTwoHeaded(ix));
这么做多加入了一个数据层,那么有什么“收获”呢?我们来看一下b和c的内存占用情况吧:

这表明:我们从80MB的b,优化得到了64MB的c! 原因当然就在于虽然多加了一层原型结构,但是第二层变成了“共享”。
当然,如果到这里你还没有晕的话,可能要问:那第二层诸如 shape, size, color 这些属性变成共享的之后,存在互相干扰怎么破解呢?
好问题,我先不解答,先给大家看一下最后的 final product:
class ShapeMaker {
constructor () {
Object.assign(this, ShapeMaker.defaults())
}
static defaults () {
return {
id: null,
x: 0,
y: 0,
shape: 'square',
size: 0.5,
color: 'red',
strokeColor: 'yellow',
hidden: false,
label: null,
labelOffset: [0, 0],
labelFont: '10px sans-serif',
labelColor: 'black'
}
}
newShape (id, x, y) {
const obj = Object.create(this);
return Object.assign(obj, {id, x, y})
}
setDefault (name, value) {
this[name] = value;
}
getDefault (name) {
return this[name]
}
}
在实例化的时候,我们便可以这样使用:
shapeProto = new ShapreMaker();
d = a.map((val, ix) => shapeProto.newShape(ix, ix/10, -ix/10))
就像上面所说的,初始化实例时,我们初始化了 id, x, y 这么三个参数。作为该实例本身的数据层。这个实例的原型上,也有类似的参数,来保证默认值。这些原型上的属性,对于实例数组中的每个实例,都是共享的。
为了更好的对比,如果设计是这样子:
function fatShape (id, x, y) {
const a = new shapeMaker();
return Object.assign(a, {id, x, y})
}
e = a.map((val, ix) => fatShape(ix, ix/10, -ix/10))
那么所有属性无法共享,而是各自拷贝了一份。在内存的占用上,将是我们给出方案的三倍之多!

阿喀琉斯之踵
阿喀琉斯,是凡人珀琉斯和美貌仙女忒提斯的宝贝儿子。忒提斯为了让儿子炼成“金钟罩”,在他刚出生时就将其倒提着浸进冥河,遗憾的是,乖儿被母亲捏住的脚后跟却不慎露在水外,全身留下了惟一一处“死穴”。后来,阿喀琉斯被帕里斯一箭射中了脚踝而死去。 后人常以“阿喀琉斯之踵”譬喻这样一个道理:即使是再强大的英雄,他也有致命的死穴或软肋。
就像我们刚才提的到解决方案一样,也有一些“不足”。问题其实在之前我也已经抛出:“第二层诸如:shape, size, color 这些属性变成共享的之后,存在互相干扰怎么破解呢?”
这个问题的答案其实也隐藏在上面的代码中,很简单,就是我们在实例的自身属性上,进行复写,而避免更改原型上的属性造成污染。
如果你看的云里雾里,不要紧,马上看一下我下面的代码说明:
d.every((item) => item.shape === 'square') // true
打印为 true,是因为 d 数组中的每个实例的 shape 属性,都在原型上,且初始值都为'square';
现在我们调用 setDefault 方法,实现对默认 shape 的改写。
shapeProto.setDefault('shape', 'circle');
d.every((item) => item.shape === 'square'); // false
因为此时所有实例的 shape 都在原型上,并共享这个原型。更改之后,我们有:
d.every((item) => item.shape === 'circle'); // true
但是,我只想把第一个实例的 shape 设置为 triangle,其他的不变,该怎么办呢?只需要在第一个实例上,增加一个 shape 属性,进行重写:
d[0].shape = 'triangle';
d.every((item) => item.shape === 'circle'); // false
好吧,尝试完毕之后,我们在变回来。
d[0].shape = 'circle';
这时候,自然有:
d.every((item) => item.shape === 'circle'); // true
同时,再折腾一下:
d[0].shape = 'triangle';
d.every((item) => item.shape === 'triangle'); // false
相信下面的也不难理解了:
shapeProto.setDefault('shape', 'triangle');
d.every((item) => item.shape === 'triangle'); // true
这种模式其实比单纯使用ES6 Classes要灵活的多,同时也节省了内存。所有的静态属性都是共享的,但是共享的静态属性又都是可变的,可复写的。
总结
这篇文章,我们在开头部分了解到了在大量数据的情况下,内存的占用是如何一步一步变的沉重。同时,我们提供了一种,在传统的 Classes 之上增加一个数据层的方法,有效地解决了这个问题。解决方案充分利用了 Object.create 等手段。
当然,理解这些内容并不简单,需要读者有比较扎实的 javascript 基础。在您阅读过程当中,有任何问题,欢迎与我讨论。
---恢复内容结束---
<head>
<link rel="stylesheet" href="http://apps.bdimg.com/libs/animate.css/3.1.0/animate.min.css">
<style type="text/css">
#pay_pic{
overflow: hidden;
width: 200px;
margin: 0 auto;
}
</style>
</head>
<body>
<div id="pay_area" style="padding: 10px;border-radius: 5px;background-color:#EDDCBE;text-align:center;font-size: 15px;color: #272822;cursor:pointer;margin: 10px;">
<div id="pay_pic" align="center" class="">
<img src="http://images.cnblogs.com/cnblogs_com/hngdlxy143/1219034/o_in.png" width="200px">
</div>
<div align="center">微信扫一扫打赏支持</div>
<div align="center">Q群交流<span style="border-bottom:1px solid #B82525;font-weight: bold;">651176910</span></div>
<div align="center">共<span style="font-weight: bold; color: #B82525">69</span>人支持!!!</div>
</div>
<script type="text/javascript" src=" http://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js"></script>
<script type="text/javascript">
alert();
currentDiggType = 0;
$("#pay_pic").hover(
function () {
$(this).addClass("animated swing");
},
function () {
$(this).removeClass("animated swing");
}
);
</script>
</body>
随着前端的飞速发展,在浏览器端完成复杂的计算,支配并处理大量数据已经屡见不鲜。那么,如何在最小化内存消耗的前提下,高效优雅地完成复杂场景的处理,越来越考验开发者功力,也直接决定了程序的性能。
本文展现了一个完全在控制台就能模拟体验的实例,通过一步步优化,实现了生产并操控多个1000000(百万级别)对象的场景。
导读:这篇文章涉及到 javascript 中 数组各种操作、原型原型链、ES6、classes 继承、设计模式、控制台分析 等内容。
要求阅读者具有 js 面向对象扎实的基础知识。如果你是初级前端开发者,很容易被较为复杂的逻辑绕的云里雾里,“从入门到放弃”,不过建议先收藏。如果你是“老司机”,本文提供的解决思路希望对你有所启发,抛砖引玉。
场景和初级感知
具体来说,我们需要一个构造函数,或者说类似 factory 模式,实例化1000000个以上对象实例。
先来感知一下具体实现:
Step1
打开你的浏览器控制台,仔细观察并复制粘贴以下代码,触发执行。
a = new Array(1e6).fill(0);
我们创建了一个长度为1000000的数组,数组的每一项元素都为0。
Step2
在数组 a 的基础上,再生产一个长度为1000000的数组 b,数组的每一项元素都是一个普通 javascript object,拥有 id 属性,并且其 id 属性值为其在元素中的 index 值;
b = a.map((val, ix) => ({id: ix}))
Step3
接下来,在 b 的基础上,再生产一个长度为1000000的数组 c ,类似于 b,同时我们增加一些其它属性,使得数组元素对象更加复杂一些:
c = a.map((val, ix) => ({id: ix, shape: 'square', size: 10.5, color: 'green'}))
语义上,我们可以更直观的理解:c 就是包含了1000000个元素的数组,每一项都是一个绿色的、size 为10.5的小方块。
如果你按照指示做了下来,控制台上会有以下内容:
深层探究
你也许会想,这么大的数据量,内存占用会是什么样的情况呢?
好,我来带你看看,点击控制台 Profiles,选择 Take Shapshot。在Window->Window 目录下,根据内存进行筛选,你会得到:
很明显,我们看到:
- a数组:8MB;
- b数组:40MB;
- c数组:64MB
也许在实际场景中,除了1000000个绿色的、size为10.5的小方块,我们还需要很多不同颜色,不同 size 的形状。之前,这样“变态”的需求常见于游戏应用中。但是现在,复杂项目中类似场景,也许距离你并不遥远。
ES6 Classes处理需求
简单“热身”之后,我们了解了实际需求。接下来,我们考察一下 ES6 Classes 处理这个问题的情况。请重新刷新浏览器 tab,复制执行以下代码。
class Shape {
constructor (id, shape = 'square', size = 10.5, color = 'green') {
this.x = x; // 坐标x轴
this.y = y; // 坐标y轴
Object.assign(this, {id, shape, size, color})
}
}
a = new Array(1e6).fill(0);
b = a.map((val, ix) => new Shape(ix));
我们使用了ES6 Classes,并扩充了每个形状的坐标信息。 此时,再来看一下内存占用情况:
很明显,此时 b 数组由100000个形状组成,占据内存:80MB,超过了先前数组的内存消耗。也许这并不出乎意料,此时的b数组毕竟又多了两个属性。
优化设计:Two-Headed Classes
我们先来分析一下上面的实现,熟悉原型链、原型概念的同学也许会明白,之前的方案产生的实例,顺着原型链上溯,具有三层原型属性:
第一层:[id, shape, size, color, x, y]; 这一层属性的 hasOwnproperty 为 true; 属性存在于实例本身。
第二层:[Shape]; 顺着原型链上溯,这一层 instance.proto === Constructor.prototype; ( proto 左右两边 __ 被编辑器吃掉了,请见谅,下同)
第三层:[Object]; 这一层: instance.proto.__proto__ === Object.prototype; 如果在向上追溯,就为 null 了。
这样的情况下,实际业务数据层只有一层,即为第一层。
但是,请仔细思考,如果有大量的不同颜色,不同size,不同形状的情况下。单一数据层,是难以满足我们需求的。 我们需要,再添加一层数据层,构成所谓的 Two-Headed Classes!同时,还需要对于默认的属性,实现共享,以节省内存的占用。
什么什么?没听明白,那就请看具体操作吧。
如何实现?
我们可以使用 Object.create 方法,这样使得生产得到的实例的 proto 指向 b 数组的元素,然后在最顶层设计一个 id 属性。
也许这样说过于晦涩,那就直接参考代码吧,请注意,这是本篇文章最难以理解的地方,请务必仔细揣摩:
two = Object.create(b[0]);
// two.__proto__ === b[0]
two.id = 1;
还记得 b 数组是什么嘛?参考上文,它由
b = a.map((val, ix) => new Shape(ix));
得到。
这样子的话,对于每一个实例,我们有如下关系:
第一层:[id]; 这一层实例的 hasOwnproperty 为 true;
第二层:[id, shape, size, color, x, y]; 这一层 instance.proto === Constructor.prototype;
第三层:[Shape];
第四层:[Object]; 这一层的再顶层,就为null了。
我们将 Shape 的一个实例作为一个新的 object 的原型,并复写了 id 属性,原有的 id 属性将作为默认 id。
当然,上边的代码只是“个案”,我们进行“生产化”:
proto = new Shape(0);
function newTwoHeaded (ix) {
const obj = Object.create(proto);
obj.id = ix;
return obj
}
c = a.map((val, ix) => newTwoHeaded(ix));
这么做多加入了一个数据层,那么有什么“收获”呢?我们来看一下b和c的内存占用情况吧:
这表明:我们从80MB的b,优化得到了64MB的c! 原因当然就在于虽然多加了一层原型结构,但是第二层变成了“共享”。
当然,如果到这里你还没有晕的话,可能要问:那第二层诸如 shape, size, color 这些属性变成共享的之后,存在互相干扰怎么破解呢?
好问题,我先不解答,先给大家看一下最后的 final product:
class ShapeMaker {
constructor () {
Object.assign(this, ShapeMaker.defaults())
}
static defaults () {
return {
id: null,
x: 0,
y: 0,
shape: 'square',
size: 0.5,
color: 'red',
strokeColor: 'yellow',
hidden: false,
label: null,
labelOffset: [0, 0],
labelFont: '10px sans-serif',
labelColor: 'black'
}
}
newShape (id, x, y) {
const obj = Object.create(this);
return Object.assign(obj, {id, x, y})
}
setDefault (name, value) {
this[name] = value;
}
getDefault (name) {
return this[name]
}
}
在实例化的时候,我们便可以这样使用:
shapeProto = new ShapreMaker();
d = a.map((val, ix) => shapeProto.newShape(ix, ix/10, -ix/10))
就像上面所说的,初始化实例时,我们初始化了 id, x, y 这么三个参数。作为该实例本身的数据层。这个实例的原型上,也有类似的参数,来保证默认值。这些原型上的属性,对于实例数组中的每个实例,都是共享的。
为了更好的对比,如果设计是这样子:
function fatShape (id, x, y) {
const a = new shapeMaker();
return Object.assign(a, {id, x, y})
}
e = a.map((val, ix) => fatShape(ix, ix/10, -ix/10))
那么所有属性无法共享,而是各自拷贝了一份。在内存的占用上,将是我们给出方案的三倍之多!
阿喀琉斯之踵
阿喀琉斯,是凡人珀琉斯和美貌仙女忒提斯的宝贝儿子。忒提斯为了让儿子炼成“金钟罩”,在他刚出生时就将其倒提着浸进冥河,遗憾的是,乖儿被母亲捏住的脚后跟却不慎露在水外,全身留下了惟一一处“死穴”。后来,阿喀琉斯被帕里斯一箭射中了脚踝而死去。 后人常以“阿喀琉斯之踵”譬喻这样一个道理:即使是再强大的英雄,他也有致命的死穴或软肋。
就像我们刚才提的到解决方案一样,也有一些“不足”。问题其实在之前我也已经抛出:“第二层诸如:shape, size, color 这些属性变成共享的之后,存在互相干扰怎么破解呢?”
这个问题的答案其实也隐藏在上面的代码中,很简单,就是我们在实例的自身属性上,进行复写,而避免更改原型上的属性造成污染。
如果你看的云里雾里,不要紧,马上看一下我下面的代码说明:
d.every((item) => item.shape === 'square') // true
打印为 true,是因为 d 数组中的每个实例的 shape 属性,都在原型上,且初始值都为'square';
现在我们调用 setDefault 方法,实现对默认 shape 的改写。
shapeProto.setDefault('shape', 'circle');
d.every((item) => item.shape === 'square'); // false
因为此时所有实例的 shape 都在原型上,并共享这个原型。更改之后,我们有:
d.every((item) => item.shape === 'circle'); // true
但是,我只想把第一个实例的 shape 设置为 triangle,其他的不变,该怎么办呢?只需要在第一个实例上,增加一个 shape 属性,进行重写:
d[0].shape = 'triangle';
d.every((item) => item.shape === 'circle'); // false
好吧,尝试完毕之后,我们在变回来。
d[0].shape = 'circle';
这时候,自然有:
d.every((item) => item.shape === 'circle'); // true
同时,再折腾一下:
d[0].shape = 'triangle';
d.every((item) => item.shape === 'triangle'); // false
相信下面的也不难理解了:
shapeProto.setDefault('shape', 'triangle');
d.every((item) => item.shape === 'triangle'); // true
这种模式其实比单纯使用ES6 Classes要灵活的多,同时也节省了内存。所有的静态属性都是共享的,但是共享的静态属性又都是可变的,可复写的。
总结
这篇文章,我们在开头部分了解到了在大量数据的情况下,内存的占用是如何一步一步变的沉重。同时,我们提供了一种,在传统的 Classes 之上增加一个数据层的方法,有效地解决了这个问题。解决方案充分利用了 Object.create 等手段。
当然,理解这些内容并不简单,需要读者有比较扎实的 javascript 基础。在您阅读过程当中,有任何问题,欢迎与我讨论。
javascript 大数据处理方法的更多相关文章
- 大数据处理之道(实验方法<二>)
一:交叉验证(crossvalidation)(附实验的三种方法)方法简单介绍 (1) 定义:交叉验证(Cross-validation)主要用于建模应用中,比如PCR(Principal Com ...
- 翻译-In-Stream Big Data Processing 流式大数据处理
相当长一段时间以来,大数据社区已经普遍认识到了批量数据处理的不足.很多应用都对实时查询和流式处理产生了迫切需求.最近几年,在这个理念的推动下,催生出了一系列解决方案,Twitter Storm,Yah ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- javaScript中eval()方法转换json对象
<script language="javascript"> var user = '{name:"张三",age:23,'+ 'address:{ ...
- 《Spark大数据处理:技术、应用与性能优化 》
基本信息 作者: 高彦杰 丛书名:大数据技术丛书 出版社:机械工业出版社 ISBN:9787111483861 上架时间:2014-11-5 出版日期:2014 年11月 开本:16开 页码:255 ...
- 0基础搭建Hadoop大数据处理-编程
Hadoop的编程可以是在Linux环境或Winows环境中,在此以Windows环境为示例,以Eclipse工具为主(也可以用IDEA).网上也有很多开发的文章,在此也参考他们的内容只作简单的介绍和 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】 下载
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
- Apache beam中的便携式有状态大数据处理
Apache beam中的便携式有状态大数据处理 目标: 什么是 apache beam? 状态 计时器 例子&小demo 一.什么是 apache beam? 上面两个图片一个是正面切图,一 ...
随机推荐
- MySQL: 打开binlog选项后无法重启MySQL
binlog目录权限不足导致,用chown mysql:mysql <log folder>即可解决此问题.
- 使用NDIS驱动监測以太网络活动
转载自: http://blog.csdn.net/ddtpower/article/details/656687 本论文提供了NDIS的主要的理解,应用程序怎样与驱动程序交互.发挥驱动程序最佳性 ...
- Cocos Code IDE + Lua初次使用FastTiledMap的坑
近期想玩玩Lua.又想玩玩Cocos Code IDE.更加想写一个即时战斗的.防守的.会动的.有迷雾的.要探索的(旁白:给我停!)跑地图游戏. 于是我就用Cocos Code IDE来写游戏了.挑战 ...
- Android 录制屏幕的实现方法
Android 录制屏幕的实现方法 Chrome 2017-02-15 15:32:01 发布 您的评价: 5.0 收藏 0收藏 长久以来,我一直希望能够直接从Androi ...
- 《转》OpenStack对象存储——Swift
OpenStack Object Storage(Swift)是OpenStack开源云计算项目的子项目之中的一个.被称为对象存储.提供了强大的扩展性.冗余和持久性.本文将从架构.原理和实践等几方面讲 ...
- nodejs初步
nodejs是啥? 看名字,很容易认为它是一种开发语言,实质上,它更像是一种WEB服务器,一种工具.因为nodejs的作用,在于在服务器端解释.运行javascript.node.js本身不是开发语言 ...
- 【bzoj1015】[JSOI2008]星球大战starwar
给定一个无向图,求联通块个数,以及k次每次摧毁一个点后的联通块个数 将边和摧毁的点全记录下来,反着做即可 注意被摧毁的点不能算作联通块 #include<algorithm> #inclu ...
- 杂项-JSP-Runoob:JSP 标准标签库(JSTL)
ylbtech-杂项-JSP-Runoob:JSP 标准标签库(JSTL) 1.返回顶部 1. JSP 标准标签库(JSTL) JSP标准标签库(JSTL)是一个JSP标签集合,它封装了JSP应用的通 ...
- Flink编程练习
目录 1.wordcount 2.双流警报EventTime 3.持续计数stateful + timer + SideOutputs 4.一定时间范围内的极值windowfunction + che ...
- 【USACO2002 Feb】奶牛自行车队
[USACO2002 Feb]奶牛自行车队 Time Limit: 1000 ms Memory Limit: 131072 KBytes Description N 头奶牛组队参加自行车赛.车队在比 ...