spark源码学习-withScope
以前的sparkUI中只有stage的执行情况,也就是说我们不可以看到上个RDD到下个RDD的具体信息。于是为了在
sparkUI中能展示更多的信息。所以把所有创建的RDD的方法都包裹起来,同时用RDDOperationScope 记录 RDD 的操作历史和关联,就能达成目标。下面就是一张WordCount的DAG visualization on SparkUI
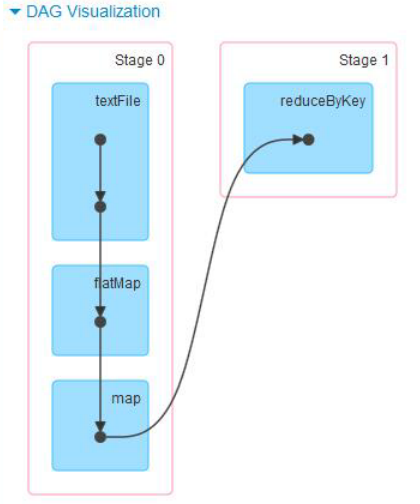
记录关系的RDDOperationScope源码如下:
/**
* A general, named code block representing an operation that instantiates RDDs.
*
* All RDDs instantiated in the corresponding code block will store a pointer to this object.
* Examples include, but will not be limited to, existing RDD operations, such as textFile,
* reduceByKey, and treeAggregate.
*
* An operation scope may be nested in other scopes. For instance, a SQL query may enclose
* scopes associated with the public RDD APIs it uses under the hood.
*
* There is no particular relationship between an operation scope and a stage or a job.
* A scope may live inside one stage (e.g. map) or span across multiple jobs (e.g. take).
*/
@JsonInclude(Include.NON_NULL)
@JsonPropertyOrder(Array("id", "name", "parent"))
private[spark] class RDDOperationScope(
val name: String,
val parent: Option[RDDOperationScope] = None,
val id: String = RDDOperationScope.nextScopeId().toString) { def toJson: String = {
RDDOperationScope.jsonMapper.writeValueAsString(this)
} /**
* Return a list of scopes that this scope is a part of, including this scope itself.
* The result is ordered from the outermost scope (eldest ancestor) to this scope.
*/
@JsonIgnore
def getAllScopes: Seq[RDDOperationScope] = {
parent.map(_.getAllScopes).getOrElse(Seq.empty) ++ Seq(this)
} override def equals(other: Any): Boolean = {
other match {
case s: RDDOperationScope =>
id == s.id && name == s.name && parent == s.parent
case _ => false
}
} override def hashCode(): Int = Objects.hashCode(id, name, parent) override def toString: String = toJson
} /**
* A collection of utility methods to construct a hierarchical representation of RDD scopes.
* An RDD scope tracks the series of operations that created a given RDD.
*/
private[spark] object RDDOperationScope extends Logging {
private val jsonMapper = new ObjectMapper().registerModule(DefaultScalaModule)
private val scopeCounter = new AtomicInteger() def fromJson(s: String): RDDOperationScope = {
jsonMapper.readValue(s, classOf[RDDOperationScope])
} /** Return a globally unique operation scope ID. */
def nextScopeId(): Int = scopeCounter.getAndIncrement /**
* Execute the given body such that all RDDs created in this body will have the same scope.
* The name of the scope will be the first method name in the stack trace that is not the
* same as this method's.
*
* Note: Return statements are NOT allowed in body.
*/
private[spark] def withScope[T](
sc: SparkContext,
allowNesting: Boolean = false)(body: => T): T = {
val ourMethodName = "withScope"
val callerMethodName = Thread.currentThread.getStackTrace()
.dropWhile(_.getMethodName != ourMethodName)
.find(_.getMethodName != ourMethodName)
.map(_.getMethodName)
.getOrElse {
// Log a warning just in case, but this should almost certainly never happen
logWarning("No valid method name for this RDD operation scope!")
"N/A"
}
withScope[T](sc, callerMethodName, allowNesting, ignoreParent = false)(body)
} /**
* Execute the given body such that all RDDs created in this body will have the same scope.
*
* If nesting is allowed, any subsequent calls to this method in the given body will instantiate
* child scopes that are nested within our scope. Otherwise, these calls will take no effect.
*
* Additionally, the caller of this method may optionally ignore the configurations and scopes
* set by the higher level caller. In this case, this method will ignore the parent caller's
* intention to disallow nesting, and the new scope instantiated will not have a parent. This
* is useful for scoping physical operations in Spark SQL, for instance.
*
* Note: Return statements are NOT allowed in body.
*/
private[spark] def withScope[T](
sc: SparkContext,
name: String,
allowNesting: Boolean,
ignoreParent: Boolean)(body: => T): T = {
// Save the old scope to restore it later
val scopeKey = SparkContext.RDD_SCOPE_KEY
val noOverrideKey = SparkContext.RDD_SCOPE_NO_OVERRIDE_KEY
val oldScopeJson = sc.getLocalProperty(scopeKey)
val oldScope = Option(oldScopeJson).map(RDDOperationScope.fromJson)
val oldNoOverride = sc.getLocalProperty(noOverrideKey)
try {
if (ignoreParent) {
// Ignore all parent settings and scopes and start afresh with our own root scope
sc.setLocalProperty(scopeKey, new RDDOperationScope(name).toJson)
} else if (sc.getLocalProperty(noOverrideKey) == null) {
// Otherwise, set the scope only if the higher level caller allows us to do so
sc.setLocalProperty(scopeKey, new RDDOperationScope(name, oldScope).toJson)
}
// Optionally disallow the child body to override our scope
if (!allowNesting) {
sc.setLocalProperty(noOverrideKey, "true")
log.info("this is textFile1")
log.info("this is textFile2" )
//println("this is textFile3")
log.error("this is textFile4err")
log.warn("this is textFile5WARN")
log.debug("this is textFile6debug")
}
body
} finally {
// Remember to restore any state that was modified before exiting
sc.setLocalProperty(scopeKey, oldScopeJson)
sc.setLocalProperty(noOverrideKey, oldNoOverride)
}
}
}
spark源码学习-withScope的更多相关文章
- Spark源码学习1.2——TaskSchedulerImpl.scala
许久没有写博客了,没有太多时间,最近陆续将Spark源码的一些阅读笔记传上,接下来要修改Spark源码了. 这个类继承于TaskScheduler类,重载了TaskScheduler中的大部分方法,是 ...
- Spark源码学习1.1——DAGScheduler.scala
本文以Spark1.1.0版本为基础. 经过前一段时间的学习,基本上能够对Spark的工作流程有一个了解,但是具体的细节还是需要阅读源码,而且后续的科研过程中也肯定要修改源码的,所以最近开始Spark ...
- Spark源码学习2
转自:http://www.cnblogs.com/hseagle/p/3673123.html 在源码阅读时,需要重点把握以下两大主线. 静态view 即 RDD, transformation a ...
- Spark源码学习1.6——Executor.scala
Executor.scala 一.Executor类 首先判断本地性,获取slaves的host name(不是IP或者host: port),匹配运行环境为集群或者本地.如果不是本地执行,需要启动一 ...
- Spark源码学习1.5——BlockManager.scala
一.BlockResult类 该类用来表示返回的匹配的block及其相关的参数.共有三个参数: data:Iterator [Any]. readMethod: DataReadMethod.Valu ...
- Spark源码学习1.4——MapOutputTracker.scala
相关类:MapOutputTrackerMessage,GetMapOutputStatuses extends MapPutputTrackerMessage,StopMapOutputTracke ...
- Spark源码学习3
转自:http://www.cnblogs.com/hseagle/p/3673132.html 一.概要 本篇主要阐述在TaskRunner中执行的task其业务逻辑是如何被调用到的,另外试图讲清楚 ...
- Spark源码学习1
转自:http://www.cnblogs.com/hseagle/p/3664933.html 一.基本概念(Basic Concepts) RDD - resillient distributed ...
- Spark源码学习1.8——ShuffleBlockManager.scala
shuffleBlockManager继承于Logging,参数为blockManager和shuffleManager.shuffle文件有三个特性:shuffleId,整个shuffle stag ...
随机推荐
- CSS中:overflow:hidden的作用
功能1.隐藏溢出 在IE6下,当子容器的宽高超出父容器时,父容器就会被撑开来. 要想解决这个问题,在父容器中除定义宽和高的值以外,还必须写overflow:hidden,这样就能把子容器的其它内容隐 ...
- 10601 - Cubes(Ploya)
UVA 10601 - Cubes 题目链接 题意:给定正方体12条棱的颜色,要求用这些棱能组成多少不同的正方体 思路:利用ploya定理去求解,分类讨论,正方体一共24种旋转.相应的旋转方式有4种: ...
- 强连通分量+poj2186
强连通分量:两个点能够互相连通. 算法分解:第一步.正向dfs全部顶点,并后序遍历 第二步,将边反向,从最大边dfs,构成强连通分量 标号最大的节点属于DAG头部,cmp存一个强连通分量的拓扑序. p ...
- HDU 5044 Tree 树链剖分+区间标记
Tree Problem Description You are given a tree (an acyclic undirected connected graph) with N nodes. ...
- Lightoj 1024 - Eid
求n个数的最小公倍数. import java.math.*; import java.io.*; import java.util.*; import java.text.*; public cla ...
- 解决多次异步请求紊乱问题 - JavaScript
加入目前的需求这样的: 左边的菜单链接,点击后通过异步请求返回其HTML代码,然后innerHTML到右面的DIV中,加入切换菜单的速度非常快,最终会导致请求紊乱. 可以加入消息管理机制, ...
- Lucene dvd dvm文件便是docvalues文件——就是针对field value的列存储
public final class Lucene54DocValuesFormat extends DocValuesFormat Lucene 5.4 DocValues format. Enco ...
- 如何制作.a静态库?合成多架构静态库?
08_01静态库 08_02制作静态库 .a 1.新建项目com+shift+n:选择Framework&Library. 2.下一步. 项目名不能为中文. 3.编写代码之后.用真机运行.会自 ...
- SQL Server 日期转换成字符串
参考网址:http://wenku.baidu.com/view/970c6c1655270722192ef70e.html 下面是常用的几个 --返回06-27-13 ), ) --2013-06- ...
- Git学习三
一.准备Github远程仓库 1.github官网注册账户 2.ubuntu端创建SSH Key $ssh-keygen -t rsa -C "youremail@example.com&q ...