Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)
不多说,直接上干货!
特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择)。
VectorSlicer用于从原来的特征向量中切割一部分,形成新的特征向量,比如,原来的特征向量长度为10,我们希望切割其中的5~10作为新的特征向量,使用VectorSlicer可以快速实现。
理论,见
机器学习概念之特征选择(Feature selection)之VectorSlicer算法介绍
完整代码
VectorSlicer .scala
package zhouls.bigdata.DataFeatureSelection import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer//引入ml里的特征选择的VectorSlicer
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.StructType /**
* By zhouls
*/
object VectorSlicer extends App {
val conf = new SparkConf().setMaster("local").setAppName("VectorSlicer")
val sc = new SparkContext(conf) val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._ //构造特征数组
val data = Array(Row(Vectors.dense(-2.0, 2.3, 0.0))) //为特征数组设置属性名(字段名),分别为f1 f2 f3
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)
val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]]) //构造DataFrame
val dataRDD = sc.parallelize(data)
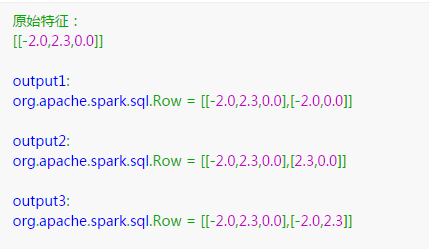
val dataset = sqlContext.createDataFrame(dataRDD, StructType(Array(attrGroup.toStructField()))) print("原始特征:")
dataset.take().foreach(println) //构造切割器
var slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features") //根据索引号,截取原始特征向量的第1列和第3列
slicer.setIndices(Array(,))
print("output1: ")
slicer.transform(dataset).select("userFeatures", "features").first() //根据字段名,截取原始特征向量的f2和f3
slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setNames(Array("f2","f3"))
print("output2: ")
slicer.transform(dataset).select("userFeatures", "features").first() //索引号和字段名也可以组合使用,截取原始特征向量的第1列和f2
slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setIndices(Array()).setNames(Array("f2"))
print("output3: ")
slicer.transform(dataset).select("userFeatures", "features").first() }
输出结果是
python语言来编写
from pyspark.ml.feature import VectorSlicer
from pyspark.ml.linalg import Vectors
from pyspark.sql.types import Row df = spark.createDataFrame([
Row(userFeatures=Vectors.sparse(, {: -2.0, : 2.3}),),
Row(userFeatures=Vectors.dense([-2.0, 2.3, 0.0]),)]) slicer = VectorSlicer(inputCol="userFeatures", outputCol="features", indices=[]) output = slicer.transform(df) output.select("userFeatures", "features").show()
Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)的更多相关文章
- Spark MLlib编程API入门系列之特征选择之卡方特征选择(ChiSqSelector)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). ChiSqSelector用于使用卡方检 ...
- Spark MLlib编程API入门系列之特征选择之R模型公式(RFormula)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). RFormula用于将数据中的字段通过R ...
- Spark MLlib编程API入门系列之特征提取之主成分分析(PCA)
不多说,直接上干货! 主成分分析(Principal Component Analysis,PCA), 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法. 参考 http://blo ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- Spark SQL 编程API入门系列之SparkSQL数据源
不多说,直接上干货! SparkSQL数据源:从各种数据源创建DataFrame 因为 spark sql,dataframe,datasets 都是共用 spark sql 这个库的,三者共享同样的 ...
- Spark SQL 编程API入门系列之Spark SQL的作用与使用方式
不多说,直接上干货! Spark程序中使用SparkSQL 轻松读取数据并使用SQL 查询,同时还能把这一过程和普通的Python/Java/Scala 程序代码结合在一起. CLI---Spark ...
- Spark SQL 编程API入门系列之SparkSQL的入口
不多说,直接上干货! SparkSQL的入口:SQLContext SQLContext是SparkSQL的入口 val sc: SparkContext val sqlContext = new o ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
随机推荐
- Oracle数据库案例整理-Oracle系统执行时故障-断电导致数据文件状态变为RECOVER
1.1 现象描写叙述异常断电.数据库数据文件的状态由ONLINE变为RECOVER. 系统显演示样例如以下信息:SQL>selectfile_name,tablespace_name, ...
- SDIO卡 了解
SDIO接口是在SD接口基础上发展起来的,SDIO接口兼容SD接口.SDIO协议又在SD卡协议之上添加了CMD52(一般用来访问寄存器)和CMD53(字节和块传输)命令.SDIO和SD卡规范间的一个重 ...
- 使用pt-query-digest进行日志分析
使用pt-query-digest sudo apt install percona-toolkit 也可以到官网 https://www.percona.com/downloads/percona- ...
- maven实战(6)-- pom.xml的编写
pom.xml中可以编写的东西确实挺多的,经常看到别人写的pom文件中出现了一些没见过plugin或properties等等,不知有何作用,其实很简单,只要参看maven的官方文档即可:http:// ...
- NIO知识摘录
在 JDK 1. 4 中 新 加入 了 NIO( New Input/ Output) 类, 引入了一种基于通道和缓冲区的 I/O 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个 ...
- CreateThread创建线程 互斥量锁
HANDLE CreateThread( LPSECURITY_ATTRIBUTES lpThreadAttributes,//SD:线程安全相关的属性,常置为NULL SIZE_T dwStackS ...
- Codeforces Round #421 (Div. 2)B. Mister B and Angle in Polygon(模拟+精度控制)
传送门 题意 给出正n多边形和一个数a,寻找与a最接近的角,输出角编号 分析 找出多边形上所有角,一一比对即可 trick 1.判断的时候注意精度,i.e.x-eps>0 2.double与do ...
- poj3176【简单DP】
其实就是简单递推对吧~ 贴一发记忆化搜索的- #include <iostream> #include <stdio.h> #include <string.h> ...
- Codeforces 2 A. Winner
哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈....... 先让我笑完................ 就是一道撒比题啊,一开始是题目看错= =.是,但是后面还是自己不仔细错的.....不存在题目坑这种情况 ...
- [转]Markdown语法参考
<< 访问 Wow!Ubuntu NOTE: This is Simplelified Chinese Edition Document of Markdown Syntax. If yo ...