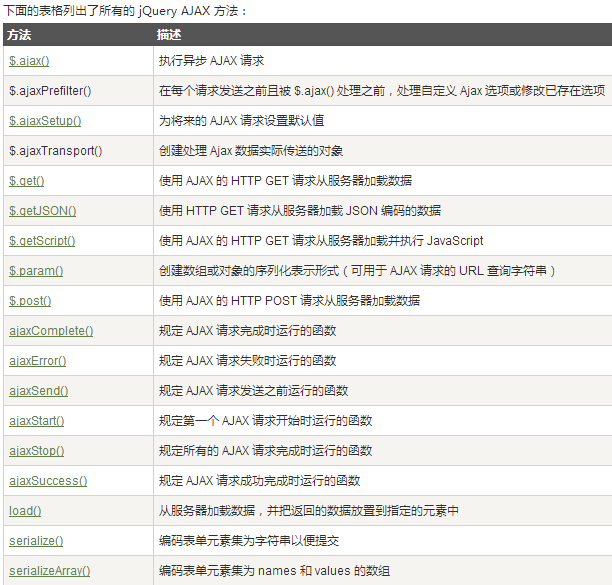
input屏蔽历史记录 ;function($,undefined) 前面的分号是什么用处 JSON 和 JSONP 两兄弟 document.body.scrollTop与document.documentElement.scrollTop兼容 URL中的# 网站性能优化 前端必知的ajax 简单理解同步与异步 那些年,我们被耍过的bug——has
input屏蔽历史记录
设置input的扩展属性autocomplete 为off即可
;function($,undefined) 前面的分号是什么用处
;(function($){$.extend($.fn...
现般在一些 JQuery 函数前面有分号,在前面加分号可以有多种用途:
1、防止多文件集成成一个文件后,高压缩出现语法错误。
2、这是一个匿名函数,一般js库都采用这种自执行的匿名函数来保护内部变量 (function(){})()。
3、因为undefined是window的属性,声明为局部变量之后,在函数中如果再有变量与undefined作比较的话,程序就可以不用搜索undefined到window,可以提高程序性能。
转自这里
JSON 和 JSONP 两兄弟
目录
项目中遇到这个新事物,转一篇不错的总结,原文
如今ajax威风凛凛
但说到AJAX就会不可避免的面临两个问题,第一个是AJAX以何种格式来交换数据?第二个是跨域的需求如何解决?
这两个问题目前都有不同的解决方案,比如数据可以用自定义字符串或者用XML来描述,跨域可以通过服务器端代理来解决。
但到目前为止最被推崇或者说首选的方案还是用JSON来传数据,靠JSONP来跨域。而这就是本文将要讲述的内容。
json与jsonp
json:一种数据交换格式
jsonp:一种依靠开发人员的聪明才智创造出的一种非官方跨域数据交互协议。
一个是描述信息的格式,一个是信息传递双方约定的方法。
json的优点
1、基于纯文本,跨平台传递极其简单;
2、Javascript原生支持,后台语言几乎全部支持;
3、轻量级数据格式,占用字符数量极少,特别适合互联网传递;
4、可读性较强,虽然比不上XML那么一目了然,但在合理的依次缩进之后还是很容易识别的;
5、容易编写和解析,当然前提是你要知道数据结构;
JSON的缺点当然也有,但在作者看来实在是无关紧要的东西,所以不再单独说明。
JSON的格式或者叫规则:
JSON能够以非常简单的方式来描述数据结构,XML能做的它都能做,因此在跨平台方面两者完全不分伯仲。
1、JSON只有两种数据类型描述符,大括号{}和方括号[],其余英文冒号:是映射符,英文逗号,是分隔符,英文双引号""是定义符。
2、大括号{}用来描述一组“不同类型的无序键值对集合”(每个键值对可以理解为OOP的属性描述),方括号[]用来描述一组“相同类型的有序数据集合”(可对应OOP的数组)。
3、上述两种集合中若有多个子项,则通过英文逗号,进行分隔。
4、键值对以英文冒号:进行分隔,并且建议键名都加上英文双引号”",以便于不同语言的解析。
5、JSON内部常用数据类型无非就是字符串、数字、布尔、日期、null 这么几个,字符串必须用双引号引起来,其余的都不用,日期类型比较特殊,这里就不展开讲述了,只是建议如果客户端没有按日期排序功能需求的话,那么把日期时间直接作为字符串传递就好,可以省去很多麻烦。
JSON实例

// 描述一个人
var person = {
"Name": "Bob",
"Age": 32,
"Company": "IBM",
"Engineer": true
}
// 获取这个人的信息
var personAge = person.Age;
// 描述几个人
var members = [
{
"Name": "Bob",
"Age": 32,
"Company": "IBM",
"Engineer": true
},
{
"Name": "John",
"Age": 20,
"Company": "Oracle",
"Engineer": false
},
{
"Name": "Henry",
"Age": 45,
"Company": "Microsoft",
"Engineer": false
}
]
// 读取其中John的公司名称
var johnsCompany = members[1].Company;
// 描述一次会议
var conference = {
"Conference": "Future Marketing",
"Date": "2012-6-1",
"Address": "Beijing",
"Members":
[
{
"Name": "Bob",
"Age": 32,
"Company": "IBM",
"Engineer": true
},
{
"Name": "John",
"Age": 20,
"Company": "Oracle",
"Engineer": false
},
{
"Name": "Henry",
"Age": 45,
"Company": "Microsoft",
"Engineer": false
}
]
}
// 读取参会者Henry是否工程师
var henryIsAnEngineer = conference.Members[2].Engineer;
JSONP
JSONP产生的原因
1. ajax直接请求普通文件时存在跨域无权限访问的额问题
2. web页面调用js文件时则不受是否跨域的影响(凡是拥有“src”这个属性的标签都有跨域的能力比如<script>、<img>、<iframe>)
3. 因此,如果想通过纯web端跨域访问数据只有一种可能,就是在远程服务器上设法把数据装进js格式的文件里
4. 已知json纯字符数据格式可以描述复杂数据,而且被js原生支持
5. 这样子解决方案就呼之欲出了,web客户端通过与调用脚本一模一样的方式,来调用跨域服务器上动态生成的js格式文件(一般以JSON为后缀),显而易见,服务器之所以要动态生成JSON文件,目的就在于把客户端需要的数据装入进去。
6. 客户端在对JSON文件调用成功之后,也就获得了自己所需的数据,剩下的就是按照自己需求进行处理和展现了,这种获取远程数据的方式看起来非常像AJAX,但其实并不一样。
7. 为了便于客户端使用数据,逐渐形成了一种非正式传输协议,人们把它称作JSONP,该协议的一个要点就是允许用户传递一个callback参数给服务端,然后服务端返回数据时会将这个callback参数作为函数名来包裹住JSON数据,这样客户端就可以随意定制自己的函数来自动处理返回数据了。
function getCitys() {
return $.ajax('http://api.miwifi.com/kujiale_proxy/get/openapi/city', {
dataType: 'jsonp',
success: function(rsp) {
if (rsp.code == 0) {
Cache.set('citys', rsp.data);
}
}
});
}
其他
1、ajax和jsonp这两种技术在调用方式上“看起来”很像,目的也一样,都是请求一个url,然后把服务器返回的数据进行处理,因此jquery和ext等框架都把jsonp作为ajax的一种形式进行了封装;
2、但ajax和jsonp其实本质上是不同的东西。ajax的核心是通过XmlHttpRequest获取非本页内容,而jsonp的核心则是动态添加<script>标签来调用服务器提供的js脚本。
3、所以说,其实ajax与jsonp的区别不在于是否跨域,ajax通过服务端代理一样可以实现跨域,jsonp本身也不排斥同域的数据的获取。
4、还有就是,jsonp是一种方式或者说非强制性协议,如同ajax一样,它也不一定非要用json格式来传递数据,如果你愿意,字符串都行,只不过这样不利于用jsonp提供公开服务。
document.body.scrollTop与document.documentElement.scrollTop兼容
项目中遇到这个小问题,看到有前辈总结,借来用一下
document.body.scrollTop与document.documentElement.scrollTop兼容
这两天在写一个JS的网页右键菜单,在实现菜单定位的时候发现了这个问题:chrome居然不认识document.documentElement.scrollTop!
看前辈们的文章,纷纷表示如果有文档声明(即网页第一句的docType)的情况下,标准浏览器是只认识documentElement.scrollTop的,但chrome虽然我感觉比firefox还标准,但却不认识这个,在有文档声明时,chrome也只认识document.body.scrollTop.
由于在不同情况下,document.body.scrollTop与document.documentElement.scrollTop都有可能取不到值,那到底网页的scrollTop值怎么得到呢?难道又要用javascript进行判断?
其实不必。因为document.body.scrollTop与document.documentElement.scrollTop两者有个特点,就是同时只会有一个值生效。比如document.body.scrollTop能取到值的时候,document.documentElement.scrollTop就会始终为0;反之亦然。所以,如果要得到网页的真正的scrollTop值,可以这样:
varsTop=document.body.scrollTop+document.documentElement.scrollTop;
这两个值总会有一个恒为0,所以不用担心会对真正的scrollTop造成影响。一点小技巧,但很实用。
URL中的#
作者:阮一峰 http://www.ruanyifeng.com/blog/2011/03/url_hash.html
一、#的涵义
#代表网页中的一个位置。其右面的字符,就是该位置的标识符。比如,
http://www.example.com/index.html#print
就代表网页index.html的print位置。浏览器读取这个URL后,会自动将print位置滚动至可视区域。
为网页位置指定标识符,有两个方法。一是使用锚点,比如<a name="print"></a>,二是使用id属性,比如<div id="print" >。
二、HTTP请求不包括#
#是用来指导浏览器动作的,对服务器端完全无用。所以,HTTP请求中不包括#。
比如,访问下面的网址,
http://www.example.com/index.html#print
浏览器实际发出的请求是这样的:
GET /index.html HTTP/1.1
Host: www.example.com
可以看到,只是请求index.html,根本没有"#print"的部分。
三、#后的字符
在第一个#后面出现的任何字符,都会被浏览器解读为位置标识符。这意味着,这些字符都不会被发送到服务器端。
比如,下面URL的原意是指定一个颜色值:
http://www.example.com/?color=#fff
但是,浏览器实际发出的请求是:
GET /?color= HTTP/1.1
Host: www.example.com
可以看到,"#fff"被省略了。只有将#转码为%23,浏览器才会将其作为实义字符处理。也就是说,上面的网址应该被写成:
http://example.com/?color=%23fff
四、改变#不触发网页重载
单单改变#后的部分,浏览器只会滚动到相应位置,不会重新加载网页。
比如,从
http://www.example.com/index.html#location1
改成
http://www.example.com/index.html#location2
浏览器不会重新向服务器请求index.html。
五、改变#会改变浏览器的访问历史
每一次改变#后的部分,都会在浏览器的访问历史中增加一个记录,使用"后退"按钮,就可以回到上一个位置。
这对于ajax应用程序特别有用,可以用不同的#值,表示不同的访问状态,然后向用户给出可以访问某个状态的链接。
值得注意的是,上述规则对IE 6和IE 7不成立,它们不会因为#的改变而增加历史记录。
六、window.location.hash读取#值
window.location.hash这个属性可读可写。读取时,可以用来判断网页状态是否改变;写入时,则会在不重载网页的前提下,创造一条访问历史记录。
七、onhashchange事件
这是一个HTML 5新增的事件,当#值发生变化时,就会触发这个事件。IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+支持该事件。
它的使用方法有三种:
window.onhashchange = func;
<body onhashchange="func();">
window.addEventListener("hashchange", func, false);
对于不支持onhashchange的浏览器,可以用setInterval监控location.hash的变化。
八、Google抓取#的机制
默认情况下,Google的网络蜘蛛忽视URL的#部分。
但是,Google还规定,如果你希望Ajax生成的内容被浏览引擎读取,那么URL中可以使用"#!",Google会自动将其后面的内容转成查询字符串_escaped_fragment_的值。
比如,Google发现新版twitter的URL如下:
http://twitter.com/#!/username
就会自动抓取另一个URL:
http://twitter.com/?_escaped_fragment_=/username
通过这种机制,Google就可以索引动态的Ajax内容。
网站性能优化
目录
- 1. 尽量减少HTTP请求次数
- 2. 减少DNS查找次数
- 3. 避免跳转
- 4. 可缓存的AJAX
- 5. 推迟加载内容
- 6. 预加载
- 7. 减少DOM元素数量
- 8. 根据域名划分页面内容
- 9. 使iframe的数量最小
- 10. 不要出现404错误
- 11. 使用内容分发网络
- 12. 为文件头指定Expires或Cache-Control
- 13. Gzip压缩文件内容
- 14. 配置ETag
- 15. 尽早刷新输出缓冲
- 16. 使用GET来完成AJAX
- 17. 把样式表置于顶部
- 18. 避免使用CSS表达式
- 19. 使用外部JavaScript和CSS
- 20. 削减JavaScript和CSS
- 21. 用代替@import
- 22. 避免使用滤镜
- 23. 把脚本置于页面底部
- 24. 剔除重复脚本
- 25. 减少DOM访问
- 26. 开发智能事件处理程序
- 27. 减小Cookie体积
- 28. 对于页面内容使用无coockie域名
- 29. 优化图像
- 30. 优化CSS Spirite
- 31. 不要在HTML中缩放图像
- 32. favicon.ico要小而且可缓存
- 33. 保持单个内容小于25K
- 34. 打包组件成复合文本
1. 尽量减少HTTP请求次数
终端用户响应的时间中,有80%用于下载各项内容。这部分时间包括下载页面中的图像、样式表、脚本、Flash等。通过减少页面中的元素可以减少HTTP请求的次数。这是提高网页速度的关键步骤。
减少页面组件的方法其实就是简化页面设计。
那么有没有一种方法既能保持页面内容的丰富性又能达到加快响应时间的目的呢?这里有几条减少HTTP请求次数同时又可能保持页面内容丰富的技术。
- 合并文件是通过把所有的脚本放到一个文件中来减少HTTP请求的方法,如可以简单地把所有的CSS文件都放入一个样式表中。当脚本或者样式表在不同页面中使用时需要做不同的修改,这可能会相对麻烦点,但即便如此也要把这个方法作为改善页面性能的重要一步。
- CSS Sprites是减少图像请求的有效方法。把所有的背景图像都放到一个图片文件中,然后通过CSS的background-image和background-position属性来显示图片的不同部分;
- 图片地图是把多张图片整合到一张图片中。虽然文件的总体大小不会改变,但是可以减少HTTP请求次数。
图片地图只有在图片的所有组成部分在页面中是紧挨在一起的时候才能使用,如导航栏。确定图片的坐标和可能会比较繁琐且容易出错,同时使用图片地图导航也不具有可读性,因此不推荐这种方法; - 内联图像是使用data:URL scheme的方法把图像数据加载页面中。这可能会增加页面的大小。把内联图像放到样式表(可缓存)中可以减少HTTP请求同时又避免增加页面文件的大小。
但是内联图像现在还没有得到主流浏览器的支持。
减少页面的HTTP请求次数是你首先要做的一步。这是改进首次访问用户等待时间的最重要的方法。如同Tenni Theurer的他的博客Browser Cahe Usage – Exposed!中所说,HTTP请求在无缓存情况下占去了40%到60%的响应时间。让那些初次访问你网站的人获得更加快速的体验吧!
2. 减少DNS查找次数
域名系统(DNS)提供了域名和IP的对应关系,就像电话本中人名和他们的电话号码的关系一样。
当你在浏览器地址栏中输入[url]www.wangjishun.com[/url]时,DNS解析服务器就会返回这个域名对应的IP地址。DNS解析的过程同样也是需要时间的。一般情况下返回给定域名对应的IP地址会花费20到120毫秒的时间。而且在这个过程中浏览器什么都不会做直到DNS查找完毕。
缓存DNS查找可以改善页面性能。这种缓存需要一个特定的缓存服务器,这种服务器一般属于用户的ISP提供商或者本地局域网控制,但是它同样会在用户使用的计算机上产生缓存。DNS信息会保留在操作系统的DNS缓存中(微软Windows系统中DNS Client Service)。大多数浏览器有独立于操作系统以外的自己的缓存。由于浏览器有自己的缓存记录,因此在一次请求中它不会受到操作系统的影响。
Internet Explorer默认情况下对DNS查找记录的缓存时间为30分钟,它在注册表中的键值为DnsCacheTimeout。Firefox对DNS的查找记录缓存时间为1分钟,它在配置文件中的选项为network.dnsCacheExpiration(Fasterfox把这个选项改为了1小时)。
当客户端中的DNS缓存都为空时(浏览器和操作系统都为空),DNS查找的次数和页面中主机名的数量相同。这其中包括页面中URL、图片、脚本文件、样式表、Flash对象等包含的主机名。减少主机名的数量可以减少DNS查找次数。
减少主机名的数量还可以减少页面中并行下载的数量。减少DNS查找次数可以节省响应时间,但是减少并行下载却会增加响应时间。我的指导原则是把这些页面中的内容分割成至少两部分但不超过四部分。这种结果就是在减少DNS查找次数和保持较高程度并行下载两者之间的权衡了。
3. 避免跳转
跳转是使用301和302代码实现的。下面是一个响应代码为301的HTTP头:
HTTP/1.1 301 Moved Permanently Location: [url]http://example.com/newuri[/url] Content-Type: text/html
浏览器会把用户指向到Location中指定的URL。头文件中的所有信息在一次跳转中都是必需的,内容部分可以为空。不管他们的名称,301和302响应都不会被缓存除非增加一个额外的头选项,如Expires或者Cache-Control来指定它缓存。<meat />元素的刷新标签和JavaScript也可以实现URL的跳转,但是如果你必须要跳转的时候,最好的方法就是使用标准的3XXHTTP状态代码,这主要是为了确保“后退”按钮可以正确地使用。
但是要记住跳转会降低用户体验。在用户和HTML文档中间增加一个跳转,会拖延页面中所有元素的显示,因为在HTML文件被加载前任何文件(图像、Flash等)都不会被下载。
有一种经常被网页开发者忽略却往往十分浪费响应时间的跳转现象。这种现象发生在当URL本该有斜杠(/)却被忽略掉时。例如,当我们要访问[url]http://www.wangjishun.com[/url] 时,实际上返回的是一个包含301代码的跳转,它指向的是[url]http://www.wangjishun.com/[/url] (注意末尾的斜杠)。在Apache服务器中可以使用Alias 或者 mod_rewrite或者the DirectorySlash来避免。
连接新网站和旧网站是跳转功能经常被用到的另一种情况。这种情况下往往要连接网站的不同内容然后根据用户的不同类型(如浏览器类型、用户账号所属类型)来进行跳转。使用跳转来实现两个网站的切换十分简单,需要的代码量也不多。尽管使用这种方法对于开发者来说可以降低复杂程度,但是它同样降低用户体验。一个可替代方法就是如果两者在同一台服务器上时使用Alias和mod_rewrite和实现。如果是因为域名的不同而采用跳转,那么可以通过使用Alias或者mod_rewirte建立CNAME(保存一个域名和另外一个域名之间关系的DNS记录)来替代。
4. 可缓存的AJAX
Ajax经常被提及的一个好处就是由于其从后台服务器传输信息的异步性而为用户带来的反馈的即时性。但是,使用Ajax并不能保证用户不会在等待异步的JavaScript和XML响应上花费时间。在很多应用中,用户是否需要等待响应取决于Ajax如何来使用。
例如,在一个基于Web的Email客户端中,用户必须等待Ajax返回符合他们条件的邮件查询结果。记住一点,“异步”并不异味着“即时”,这很重要。
为了提高性能,优化Ajax响应是很重要的。提高Ajxa性能的措施中最重要的方法就是使响应具有可缓存性,具体的讨论可以查看Add an Expires or a Cache-Control Header。其它的几条规则也同样适用于Ajax:
- Gizp压缩文件
- 减少DNS查找次数
- 精简JavaScript
- 避免跳转
- 配置ETags
让我们来看一个例子:一个Web2.0的Email客户端会使用Ajax来自动完成对用户地址薄的下载。如果用户在上次使用过Email web应用程序后没有对地址薄作任何的修改,而且Ajax响应通过Expire或者Cacke-Control头来实现缓存,那么就可以直接从上一次的缓存中读取地址薄了。必须告知浏览器是使用缓存中的地址薄还是发送一个新的请求。这可以通过为读取地址薄的Ajax URL增加一个含有上次编辑时间的时间戳来实现,例如,&t=11900241612等。如果地址薄在上次下载后没有被编辑过,时间戳就不变,则从浏览器的缓存中加载从而减少了一次HTTP请求过程。如果用户修改过地址薄,时间戳就会用来确定新的URL和缓存响应并不匹配,浏览器就会重要请求更新地址薄。
即使你的Ajxa响应是动态生成的,哪怕它只适用于一个用户,那么它也应该被缓存起来。这样做可以使你的Web2.0应用程序更加快捷。
5. 推迟加载内容
你可以仔细看一下你的网页,问问自己“哪些内容是页面呈现时所必需首先加载的?哪些内容和结构可以稍后再加载?
把整个过程按照onload事件分隔成两部分,JavaScript是一个理想的选择。例如,如果你有用于实现拖放和动画的JavaScript,那么它就以等待稍后加载,因为页面上的拖放元素是在初始化呈现之后才发生的。其它的例如隐藏部分的内容(用户操作之后才显现的内容)和处于折叠部分的图像也可以推迟加载
工具可以节省你的工作量:
YUI Image Loader可以帮你推迟加载折叠部分的图片,YUI Get utility是包含JS和 CSS的便捷方法。比如你可以打开Firebug的Net选项卡看一下Yahoo的首页。
当性能目标和其它网站开发实践一致时就会相得益彰。这种情况下,通过程序提高网站性能的方法告诉我们,在支持JavaScript的情况下,可以先去除用户体验,不过这要保证你的网站在没有JavaScript也可以正常运行。在确定页面运行正常后,再加载脚本来实现如拖放和动画等更加花哨的效果。
6. 预加载
预加载和后加载看起来似乎恰恰相反,但实际上预加载是为了实现另外一种目标。预加载是在浏览器空闲时请求将来可能会用到的页面内容(如图像、样式表和脚本)。使用这种方法,当用户要访问下一个页面时,页面中的内容大部分已经加载到缓存中了,因此可以大大改善访问速度。
下面提供了几种预加载方法:
- 无条件加载:触发onload事件时,直接加载额外的页面内容。以Google.com为例,你可以看一下它的spirit image图像是怎样在onload中加载的。这个spirit image图像在google.com主页中是不需要的,但是却可以在搜索结果页面中用到它。
- 有条件加载:根据用户的操作来有根据地判断用户下面可能去往的页面并相应的预加载页面内容。在search.yahoo.com中你可以看到如何在你输入内容时加载额外的页面内容。
- 有预期的加载:载入重新设计过的页面时使用预加载。这种情况经常出现在页面经过重新设计后用户抱怨“新的页面看起来很酷,但是却比以前慢”。问题可能出在用户对于你的旧站点建立了完整的缓存,而对于新站点却没有任何缓存内容。因此你可以在访问新站之前就加载一部内容来避免这种结果的出现。在你的旧站中利用浏览器的空余时间加载新站中用到的图像的和脚本来提高访问速度。
7. 减少DOM元素数量
一个复杂的页面意味着需要下载更多数据,同时也意味着JavaScript遍历DOM的效率越慢。比如当你增加一个事件句柄时在500和5000个DOM元素中循环效果肯定是不一样的。
大量的DOM元素的存在意味着页面中有可以不用移除内容只需要替换元素标签就可以精简的部分。你在页面布局中使用表格了吗?你有没有仅仅为了布局而引入更多的<div>元素呢?也许会存在一个适合或者在语意是更贴切的标签可以供你使用。
YUI CSS utilities可以给你的布局带来巨大帮助:
grids.css可以帮你实现整体布局,font.css和reset.css可以帮助你移除浏览器默认格式。它提供了一个重新审视你页面中标签的机会,比如只有在语意上有意义时才使用<div>,而不是因为它具有换行效果才使用它。
DOM元素数量很容易计算出来,只需要在Firebug的控制台内输入:
document.getElementsByTagName(‘*’).length
那么多少个DOM元素算是多呢?这可以对照有很好标记使用的类似页面。比如Yahoo!主页是一个内容非常多的页面,但是它只使用了700个元素(HTML标签)。
8. 根据域名划分页面内容
把页面内容划分成若干部分可以使你最大限度地实现平行下载。由于DNS查找带来的影响你首先要确保你使用的域名数量在2个到4个之间。例如,你可以把用到的HTML内容和动态内容放在[url]www.example.org[/url]上,而把页面各种组件(图片、脚本、CSS)分别存放在statics1.example.org和statics.example.org上。
你可在Tenni Theurer和Patty Chi合写的文章Maximizing Parallel Downloads in the Carpool Lane找到更多相关信息。
9. 使iframe的数量最小
ifrmae元素可以在父文档中插入一个新的HTML文档。了解iframe的工作理然后才能更加有效地使用它,这一点很重要。
<iframe>优点:
- 解决加载缓慢的第三方内容如图标和广告等的加载问题
- Security sandbox
- 并行加载脚本
<iframe>的缺点:
- 即时内容为空,加载也需要时间
- 会阻止页面加载
- 没有语意
10. 不要出现404错误
HTTP请求时间消耗是很大的,因此使用HTTP请求来获得一个没有用处的响应(例如404没有找到页面)是完全没有必要的,它只会降低用户体验而不会有一点好处。
有些站点把404错误响应页面改为“你是不是要找***”,这虽然改进了用户体验但是同样也会浪费服务器资源(如数据库等)。最糟糕的情况是指向外部JavaScript的链接出现问题并返回404代码。首先,这种加载会破坏并行加载;其次浏览器会把试图在返回的404响应内容中找到可能有用的部分当作JavaScript代码来执行。
11. 使用内容分发网络
用户与你网站服务器的接近程度会影响响应时间的长短。把你的网站内容分散到多个、处于不同地域位置的服务器上可以加快下载速度。但是首先我们应该做些什么呢?
按地域布置网站内容的第一步并不是要尝试重新架构你的网站让他们在分发服务器上正常运行。根据应用的需求来改变网站结构,这可能会包括一些比较复杂的任务,如在服务器间同步Session状态和合并数据库更新等。要想缩短用户和内容服务器的距离,这些架构步骤可能是不可避免的。
要记住,在终端用户的响应时间中有80%到90%的响应时间用于下载图像、样式表、脚本、Flash等页面内容。这就是网站性能黄金守则。和重新设计你的应用程序架构这样比较困难的任务相比,首先来分布静态内容会更好一点。这不仅会缩短响应时间,而且对于内容分发网络来说它更容易实现。
内容分发网络(Content Delivery Network,CDN)是由一系列分散到各个不同地理位置上的Web服务器组成的,它提高了网站内容的传输速度。用于向用户传输内容的服务器主要是根据和用户在网络上的靠近程度来指定的。例如,拥有最少网络跳数(network hops)和响应速度最快的服务器会被选定。
一些大型的网络公司拥有自己的CDN,但是使用像Akamai Technologies,Mirror Image Internet, 或者Limelight Networks这样的CDN服务成本却非常高。对于刚刚起步的企业和个人网站来说,可能没有使用CDN的成本预算,但是随着目标用户群的不断扩大和更加全球化,CDN就是实现快速响应所必需的了。以Yahoo来说,他们转移到CDN上的网站程序静态内容节省了终端用户20%以上的响应时间。使用CDN是一个只需要相对简单地修改代码实现显著改善网站访问速度的方法。
12. 为文件头指定Expires或Cache-Control
这条守则包括两方面的内容:
- 对于静态内容:设置文件头过期时间Expires的值为“Never expire”(永不过期)
- 对于动态内容:使用恰当的Cache-Control文件头来帮助浏览器进行有条件的请求
网页内容设计现在越来越丰富,这就意味着页面中要包含更多的脚本、样式表、图片和Flash。第一次访问你页面的用户就意味着进行多次的HTTP请求,但是通过使用Expires文件头就可以使这样内容具有缓存性。它避免了接下来的页面访问中不必要的HTTP请求。Expires文件头经常用于图像文件,但是应该在所有的内容都使用他,包括脚本、样式表和Flash等。
浏览器(和代理)使用缓存来减少HTTP请求的大小和次数以加快页面访问速度。Web服务器在HTTP响应中使用Expires文件头来告诉客户端内容需要缓存多长时间。下面这个例子是一个较长时间的Expires文件头,它告诉浏览器这个响应直到2010年4月15日才过期。
Expires: Thu, 15 Apr 2010 20:00:00 GMT
如果你使用的是Apache服务器,可以使用ExpiresDefault来设定相对当前日期的过期时间。下面这个例子是使用ExpiresDefault来设定请求时间后10年过期的文件头:
ExpiresDefault “access plus 10 years”
要切记,如果使用了Expires文件头,当页面内容改变时就必须改变内容的文件名。依Yahoo!来说我们经常使用这样的步骤:在内容的文件名中加上版本号,如yahoo_2.0.6.js。
使用Expires文件头只有会在用户已经访问过你的网站后才会起作用。当用户首次访问你的网站时这对减少HTTP请求次数来说是无效的,因为浏览器的缓存是空的。因此这种方法对于你网站性能的改进情况要依据他们“预缓存”存在时对你页面的点击频率(“预缓存”中已经包含了页面中的所有内容)。Yahoo!建立了一套测量方法,我们发现所有的页面浏览量中有75~85%都有“预缓存”。通过使用Expires文件头,增加了缓存在浏览器中内容的数量,并且可以在用户接下来的请求中再次使用这些内容,这甚至都不需要通过用户发送一个字节的请求。
13. Gzip压缩文件内容
网络传输中的HTTP请求和应答时间可以通过前端机制得到显著改善。的确,终端用户的带宽、互联网提供者、与对等交换点的靠近程度等都不是网站开发者所能决定的。但是还有其他因素影响着响应时间。通过减小HTTP响应的大小可以节省HTTP响应时间。
从HTTP/1.1开始,web客户端都默认支持HTTP请求中有Accept-Encoding文件头的压缩格式:
Accept-Encoding: gzip, deflate
如果web服务器在请求的文件头中检测到上面的代码,就会以客户端列出的方式压缩响应内容。Web服务器把压缩方式通过响应文件头中的Content-Encoding来返回给浏览器。
Content-Encoding: gzip
Gzip是目前最流行也是最有效的压缩方式。这是由GNU项目开发并通过RFC 1952来标准化的。另外仅有的一个压缩格式是deflate,但是它的使用范围有限效果也稍稍逊色。
Gzip大概可以减少70%的响应规模。目前大约有90%通过浏览器传输的互联网交换支持gzip格式。如果你使用的是Apache,gzip模块配置和你的版本有关:Apache 1.3使用mod_zip,而Apache 2.x使用moflate。
浏览器和代理都会存在这样的问题:浏览器期望收到的和实际接收到的内容会存在不匹配的现象。幸好,这种特殊情况随着旧式浏览器使用量的减少在减少。Apache模块会通过自动添加适当的Vary响应文件头来避免这种状况的出现。
服务器根据文件类型来选择需要进行gzip压缩的文件,但是这过于限制了可压缩的文件。大多数web服务器会压缩HTML文档。对脚本和样式表进行压缩同样也是值得做的事情,但是很多web服务器都没有这个功能。实际上,压缩任何一个文本类型的响应,包括XML和JSON,都值得的。图像和PDF文件由于已经压缩过了所以不能再进行gzip压缩。如果试图gizp压缩这些文件的话不但会浪费CPU资源还会增加文件的大小。
Gzip压缩所有可能的文件类型是减少文件体积增加用户体验的简单方法。
14. 配置ETag
Entity tags(ETags)(实体标签)是web服务器和浏览器用于判断浏览器缓存中的内容和服务器中的原始内容是否匹配的一种机制(“实体”就是所说的“内容”,包括图片、脚本、样式表等)。增加ETag为实体的验证提供了一个比使用“last-modified date(上次编辑时间)”更加灵活的机制。Etag是一个识别内容版本号的唯一字符串。唯一的格式限制就是它必须包含在双引号内。原始服务器通过含有ETag文件头的响应指定页面内容的ETag。
HTTP/1.1 200 OK Last-Modified: Tue, 12 Dec 2006 03:03:59 GMT ETag: “10c24bc-4ab-457e1c1f” Content-Length: 12195
稍后,如果浏览器要验证一个文件,它会使用If-None-Match文件头来把ETag传回给原始服务器。在这个例子中,如果ETag匹配,就会返回一个304状态码,这就节省了12195字节的响应。
GET /i/yahoo.gif HTTP/1.1 Host: us.yimg.com If-Modified-Since: Tue, 12 Dec 2006 03:03:59 GMT If-None-Match: “10c24bc-4ab-457e1c1f” HTTP/1.1 304 Not Modified
ETag的问题在于,它是根据可以辨别网站所在的服务器的具有唯一性的属性来生成的。当浏览器从一台服务器上获得页面内容后到另外一台服务器上进行验证时ETag就会不匹配,这种情况对于使用服务器组和处理请求的网站来说是非常常见的。默认情况下,Apache和IIS都会把数据嵌入ETag中,这会显著减少多服务器间的文件验证冲突。
Apache 1.3和2.x中的ETag格式为inode-size-timestamp。即使某个文件在不同的服务器上会处于相同的目录下,文件大小、权限、时间戳等都完全相同,但是在不同服务器上他们的内码也是不同的。
IIS 5.0和IIS 6.0处理ETag的机制相似。IIS中的ETag格式为Filetimestamp:ChangeNumber。用ChangeNumber来跟踪IIS配置的改变。网站所用的不同IIS服务器间ChangeNumber也不相同。 不同的服务器上的Apache和IIS即使对于完全相同的内容产生的ETag在也不相同,用户并不会接收到一个小而快的304响应;相反他们会接收一个正常的200响应并下载全部内容。如果你的网站只放在一台服务器上,就不会存在这个问题。但是如果你的网站是架设在多个服务器上,并且使用Apache和IIS产生默认的ETag配置,你的用户获得页面就会相对慢一点,服务器会传输更多的内容,占用更多的带宽,代理也不会有效地缓存你的网站内容。即使你的内容拥有Expires文件头,无论用户什么时候点击“刷新”或者“重载”按钮都会发送相应的GET请求。
如果你没有使用ETag提供的灵活的验证模式,那么干脆把所有的ETag都去掉会更好。Last-Modified文件头验证是基于内容的时间戳的。去掉ETag文件头会减少响应和下次请求中文件的大小。微软的这篇支持文稿讲述了如何去掉ETag。在Apache中,只需要在配置文件中简单添加下面一行代码就可以了:
FileETag none
15. 尽早刷新输出缓冲
当用户请求一个页面时,无论如何都会花费200到500毫秒用于后台组织HTML文件。在这期间,浏览器会一直空闲等待数据返回。在PHP中,你可以使用flush()方法,它允许你把已经编译的好的部分HTML响应文件先发送给浏览器,这时浏览器就会可以下载文件中的内容(脚本等)而后台同时处理剩余的HTML页面。这样做的效果会在后台烦恼或者前台较空闲时更加明显。
输出缓冲应用最好的一个地方就是紧跟在<head />之后,因为HTML的头部分容易生成而且头部往往包含CSS和JavaScript文件,这样浏览器就可以在后台编译剩余HTML的同时并行下载它们。 例子:
… <!– css, js –> </head> <?php flush(); ?> <body> … <!– content –>
为了证明使用这项技术的好处,Yahoo!搜索率先研究并完成了用户测试。
16. 使用GET来完成AJAX
请求Yahoo!Mail团队发现,当使用XMLHttpRequest时,浏览器中的POST方法是一个“两步走”的过程:首先发送文件头,然后才发送数据。因此使用GET最为恰当,因为它只需发送一个TCP包(除非你有很多cookie)。IE中URL的最大长度为2K,因此如果你要发送一个超过2K的数据时就不能使用GET了。
一个有趣的不同就是POST并不像GET那样实际发送数据。根据HTTP规范,GET意味着“获取”数据,因此当你仅仅获取数据时使用GET更加有意义(从语意上讲也是如此),相反,发送并在服务端保存数据时使用POST。
17. 把样式表置于顶部
在研究Yahoo!的性能表现时,我们发现把样式表放到文档的<head />内部似乎会加快页面的下载速度。这是因为把样式表放到<head />内会使页面有步骤的加载显示。
注重性能的前端服务器往往希望页面有秩序地加载。同时,我们也希望浏览器把已经接收到内容尽可能显示出来。这对于拥有较多内容的页面和网速较慢的用户来说特别重要。向用户返回可视化的反馈,比如进程指针,已经有了较好的研究并形成了正式文档。在我们的研究中HTML页面就是进程指针。当浏览器有序地加载文件头、导航栏、顶部的logo等对于等待页面加载的用户来说都可以作为可视化的反馈。这从整体上改善了用户体验。
把样式表放在文档底部的问题是在包括Internet Explorer在内的很多浏览器中这会中止内容的有序呈现。浏览器中止呈现是为了避免样式改变引起的页面元素重绘。用户不得不面对一个空白页面。
HTML规范清楚指出样式表要放包含在页面的<head />区域内:“和<a />不同,<link />只能出现在文档的<head />区域内,尽管它可以多次使用它”。无论是引起白屏还是出现没有样式化的内容都不值得去尝试。最好的方案就是按照HTML规范在文档<head />内加载你的样式表。
18. 避免使用CSS表达式
CSS表达式是动态设置CSS属性的强大(但危险)方法。Internet Explorer从第5个版本开始支持CSS表达式。下面的例子中,使用CSS表达式可以实现隔一个小时切换一次背景颜色:
如上所示,expression中使用了JavaScript表达式。CSS属性根据JavaScript表达式的计算结果来设置。expression方法在其它浏览器中不起作用,因此在跨浏览器的设计中单独针对Internet Explorer设置时会比较有用。
表达式的问题就在于它的计算频率要比我们想象的多。不仅仅是在页面显示和缩放时,就是在页面滚动、乃至移动鼠标时都会要重新计算一次。给CSS表达式增加一个计数器可以跟踪表达式的计算频率。在页面中随便移动鼠标都可以轻松达到10000次以上的计算量。
一个减少CSS表达式计算次数的方法就是使用一次性的表达式,它在第一次运行时将结果赋给指定的样式属性,并用这个属性来代替CSS表达式。如果样式属性必须在页面周期内动态地改变,使用事件句柄来代替CSS表达式是一个可行办法。如果必须使用CSS表达式,一定要记住它们要计算成千上万次并且可能会对你页面的性能产生影响。
19. 使用外部JavaScript和CSS
很多性能规则都是关于如何处理外部文件的。但是,在你采取这些措施前你可能会问到一个更基本的问题:JavaScript和CSS是应该放在外部文件中呢还是把它们放在页面本身之内呢?
在实际应用中使用外部文件可以提高页面速度,因为JavaScript和CSS文件都能在浏览器中产生缓存。内置在HTML文档中的JavaScript和CSS则会在每次请求中随HTML文档重新下载。这虽然减少了HTTP请求的次数,却增加了HTML文档的大小。从另一方面来说,如果外部文件中的JavaScript和CSS被浏览器缓存,在没有增加HTTP请求次数的同时可以减少HTML文档的大小。
关键问题是,外部JavaScript和CSS文件缓存的频率和请求HTML文档的次数有关。虽然有一定的难度,但是仍然有一些指标可以一测量它。如果一个会话中用户会浏览你网站中的多个页面,并且这些页面中会重复使用相同的脚本和样式表,缓存外部文件就会带来更大的益处。
许多网站没有功能建立这些指标。对于这些网站来说,最好的坚决方法就是把JavaScript和CSS作为外部文件引用。比较适合使用内置代码的例外就是网站的主页,如Yahoo!主页和My Yahoo!。主页在一次会话中拥有较少(可能只有一次)的浏览量,你可以发现内置JavaScript和CSS对于终端用户来说会加快响应时 间。
对于拥有较大浏览量的首页来说,有一种技术可以平衡内置代码带来的HTTP请求减少与通过使用外部文件进行缓存带来的好处。其中一个就是在首页中内置JavaScript和CSS,但是在页面下载完成后动态下载外部文件,在子页面中使用到这些文件时,它们已经缓存到浏览器了。
20. 削减JavaScript和CSS
精简是指从去除代码不必要的字符减少文件大小从而节省下载时间。消减代码时,所有的注释、不需要的空白字符(空格、换行、tab缩进)等都要去掉。在JavaScript中,由于需要下载的文件体积变小了从而节省了响应时间。精简JavaScript中目前用到的最广泛的两个工具是JSMin和YUI Compressor。YUI Compressor还可用于精简CSS。
混淆是另外一种可用于源代码优化的方法。这种方法要比精简复杂一些并且在混淆的过程更易产生问题。在对美国前10大网站的调查中发现,精简也可以缩小原来代码体积的21%,而混淆可以达到25%。尽管混淆法可以更好地缩减代码,但是对于JavaScript来说精简的风险更小。
除消减外部的脚本和样式表文件外,<script>和<style>代码块也可以并且应该进行消减。即使你用Gzip压缩过脚本和样式表,精简这些文件仍然可以节省5%以上的空间。由于JavaScript和CSS的功能和体积的增加,消减代码将会获得益处。
21. 用<link>代替@import
前面的最佳实现中提到CSS应该放置在顶端以利于有序加载呈现。
在IE中,页面底部@import和使用<link>作用是一样的,因此最好不要使用它。
22. 避免使用滤镜
IE独有属性AlphaImageLoader用于修正7.0以下版本中显示PNG图片的半透明效果。这个滤镜的问题在于浏览器加载图片时它会终止内容的呈现并且冻结浏览器。在每一个元素(不仅仅是图片)它都会运算一次,增加了内存开支,因此它的问题是多方面的。
完全避免使用AlphaImageLoader的最好方法就是使用PNG8格式来代替,这种格式能在IE中很好地工作。如果你确实需要使用AlphaImageLoader,请使用下划线_filter又使之对IE7以上版本的用户无效。
23. 把脚本置于页面底部
脚本带来的问题就是它阻止了页面的平行下载。HTTP/1.1 规范建议,浏览器每个主机名的并行下载内容不超过两个。如果你的图片放在多个主机名上,你可以在每个并行下载中同时下载2个以上的文件。但是当下载脚本时,浏览器就不会同时下载其它文件了,即便是主机名不相同。
在某些情况下把脚本移到页面底部可能不太容易。比如说,如果脚本中使用了document.write来插入页面内容,它就不能被往下移动了。这里可能还会有作用域的问题。很多情况下,都会遇到这方面的问题。
一个经常用到的替代方法就是使用延迟脚本。DEFER属性表明脚本中没有包含document.write,它告诉浏览器继续显示。不幸的是,Firefox并不支持DEFER属性。在Internet Explorer中,脚本可能会被延迟但效果也不会像我们所期望的那样。如果脚本可以被延迟,那么它就可以移到页面的底部。这会让你的页面加载的快一点。
24. 剔除重复脚本
在同一个页面中重复引用JavaScript文件会影响页面的性能。你可能会认为这种情况并不多见。对于美国前10大网站的调查显示其中有两家存在重复引用脚本的情况。有两种主要因素导致一个脚本被重复引用的奇怪现象发生:团队规模和脚本数量。如果真的存在这种情况,重复脚本会引起不必要的HTTP请求和无用的JavaScript运算,这降低了网站性能。
在Internet Explorer中会产生不必要的HTTP请求,而在Firefox却不会。在Internet Explorer中,如果一个脚本被引用两次而且它又不可缓存,它就会在页面加载过程中产生两次HTTP请求。即时脚本可以缓存,当用户重载页面时也会产生额外的HTTP请求。
除增加额外的HTTP请求外,多次运算脚本也会浪费时间。在Internet Explorer和Firefox中不管脚本是否可缓存,它们都存在重复运算JavaScript的问题。
一个避免偶尔发生的两次引用同一脚本的方法是在模板中使用脚本管理模块引用脚本。在HTML页面中使用<script />标签引用脚本的最常见方法就是:
<script type=”text/javascript” src=”menu_1.0.17.js”></script>
在PHP中可以通过创建名为insertScript的方法来替代:
<?php insertScript(“menu.js”) ?>
为了防止多次重复引用脚本,这个方法中还应该使用其它机制来处理脚本,如检查所属目录和为脚本文件名中增加版本号以用于Expire文件头等。
25. 减少DOM访问
使用JavaScript访问DOM元素比较慢,因此为了获得更多的应该页面,应该做到:
- 缓存已经访问过的有关元素
- 线下更新完节点之后再将它们添加到文档树中
- 避免使用JavaScript来修改页面布局
有关此方面的更多信息请查看Julien Lecomte在YUI专题中的文章“高性能Ajax应该程序”。
26. 开发智能事件处理程序
有时候我们会感觉到页面反应迟钝,这是因为DOM树元素中附加了过多的事件句柄并且些事件句病被频繁地触发。这就是为什么说使用event delegation(事件代理)是一种好方法了。如果你在一个div中有10个按钮,你只需要在div上附加一次事件句柄就可以了,而不用去为每一个按钮增加一个句柄。事件冒泡时你可以捕捉到事件并判断出是哪个事件发出的。
你同样也不用为了操作DOM树而等待onload事件的发生。你需要做的就是等待树结构中你要访问的元素出现。你也不用等待所有图像都加载完毕。
你可能会希望用DOMContentLoaded事件来代替onload,但是在所有浏览器都支持它之前你可使用YUI 事件应用程序中的onAvailable方法。
27. 减小Cookie体积
HTTP coockie可以用于权限验证和个性化身份等多种用途。coockie内的有关信息是通过HTTP文件头来在web服务器和浏览器之间进行交流的。因此保持coockie尽可能的小以减少用户的响应时间十分重要。
有关更多信息可以查看Tenni Theurer和Patty Chi的文章“When the Cookie Crumbles”。这们研究中主要包括:
- 去除不必要的coockie
- 使coockie体积尽量小以减少对用户响应的影响
- 注意在适应级别的域名上设置coockie以便使子域名不受影响
- 设置合理的过期时间。较早地Expire时间和不要过早去清除coockie,都会改善用户的响应时间。
28. 对于页面内容使用无coockie域名
当浏览器在请求中同时请求一张静态的图片和发送coockie时,服务器对于这些coockie不会做任何地使用。因此他们只是因为某些负面因素而创建的网络传输。所有你应该确定对于静态内容的请求是无coockie的请求。创建一个子域名并用他来存放所有静态内容。
如果你的域名是[url]www.example.org[/url],你可以在static.example.org上存在静态内容。但是,如果你不是在[url]www.example.org上而是在顶级域名example.org[/url]设置了coockie,那么所有对于static.example.org的请求都包含coockie。在这种情况下,你可以再重新购买一个新的域名来存在静态内容,并且要保持这个域名是无coockie的。Yahoo!使用的是ymig.com,YouTube使用的是ytimg.com,Amazon使用的是images-anazon.com等等。
使用无coockie域名存在静态内容的另外一个好处就是一些代理(服务器)可能会拒绝对coockie的内容请求进行缓存。一个相关的建议就是,如果你想确定应该使用example.org还是[url]www.example.org[/url]作为你的一主页,你要考虑到coockie带来的影响。忽略掉www会使你除了把coockie设置到*.example.org(*是泛域名解析,代表了所有子域名译者dudo注)外没有其它选择,因此出于性能方面的考虑最好是使用带有www的子域名并且在它上面设置coockie。
29. 优化图像
设计人员完成对页面的设计之后,不要急于将它们上传到web服务器,这里还需要做几件事:
你可以检查一下你的GIF图片中图像颜色的数量是否和调色板规格一致。 使用imagemagick中下面的命令行很容易检查:
identify -verbose image.gif
如果你发现图片中只用到了4种颜色,而在调色板的中显示的256色的颜色槽,那么这张图片就还有压缩的空间。
尝试把GIF格式转换成PNG格式,看看是否节省空间。大多数情况下是可以压缩的。由于浏览器支持有限,设计者们往往不太乐意使用PNG格式的图片,不过这都是过去的事情了。现在只有一个问题就是在真彩PNG格式中的alpha通道半透明问题,不过同样的,GIF也不是真彩格式也不支持半透明。因此GIF能做到的,PNG(PNG8)同样也能做到(除了动画)。下面这条简单的命令可以安全地把GIF格式转换为PNG格式:
convert image.gif image.png
“我们要说的是:给PNG一个施展身手的机会吧!”
在所有的PNG图片上运行pngcrush(或者其它PNG优化工具)。例如:
pngcrush image.png -rem alla -reduce -brute result.png
在所有的JPEG图片上运行jpegtran。这个工具可以对图片中的出现的锯齿等做无损操作,同时它还可以用于优化和清除图片中的注释以及其它无用信息(如EXIF信息):
jpegtran -copy none -optimize -perfect src.jpg dest.jpg
30. 优化CSS Spirite
在Spirite中水平排列你的图片,垂直排列会稍稍增加文件大小;
Spirite中把颜色较近的组合在一起可以降低颜色数,理想状况是低于256色以便适用PNG8格式;
便于移动,不要在Spirite的图像中间留有较大空隙。这虽然不大会增加文件大小但对于用户代理来说它需要更少的内存来把图片解压为像素地图。100×100的图片为1万像素,而1000×1000就是100万像素。
31. 不要在HTML中缩放图像
不要为了在HTML中设置长宽而使用比实际需要大的图片。如果你需要:
<img width=”100″ height=”100″ src=”mycat.jpg” alt=”My Cat” />
那么你的图片(mycat.jpg)就应该是100×100像素而不是把一个500×500像素的图片缩小使用。
32. favicon.ico要小而且可缓存
favicon.ico是位于服务器根目录下的一个图片文件。它是必定存在的,因为即使你不关心它是否有用,浏览器也会对它发出请求,因此最好不要返回一个404 Not Found的响应。由于是在同一台服务器上,它每被请求一次coockie就会被发送一次。这个图片文件还会影响下载顺序,例如在IE中当你在onload中请求额外的文件时,favicon会在这些额外内容被加载前下载。
因此,为了减少favicon.ico带来的弊端,要做到:
文件尽量地小,最好小于1K
在适当的时候(也就是你不要打算再换favicon.ico的时候,因为更换新文件时不能对它进行重命名)为它设置Expires文件头。你可以很安全地把Expires文件头设置为未来的几个月。你可以通过核对当前favicon.ico的上次编辑时间来作出判断。
Imagemagick可以帮你创建小巧的favicon。
33. 保持单个内容小于25K
这条限制主要是因为iPhone不能缓存大于25K的文件。注意这里指的是解压缩后的大小。由于单纯gizp压缩可能达不要求,因此精简文件就显得十分重要。
查看更多信息,请参阅Wayne Shea和Tenni Theurer的文件“Performance Research, Part 5: iPhone Cacheability – Making it Stick”。
34. 打包组件成复合文本
把页面内容打包成复合文本就如同带有多附件的Email,它能够使你在一个HTTP请求中取得多个组件(切记:HTTP请求是很奢侈的)。当你使用这条规则时,首先要确定用户代理是否支持(iPhone就不支持)
前端必知的ajax
简介
异步交互
此篇只介绍部分方法,想了解更多就猛戳这里
1. load( url, [data], [callback] ) :载入远程 HTML 文件代码并插入至 DOM 中。
url (String) : 请求的HTML页的URL地址。
data (Map) : (可选参数) 发送至服务器的 key/value 数据。
callback (Callback) : (可选参数) 请求完成时(不需要是success的)的回调函数。
这个方法默认使用 GET 方式来传递的,如果[data]参数有传递数据进去,就会自动转换为POST方式的。jQuery 1.2 中,可以指定选择符,来筛选载入的 HTML 文档,DOM 中将仅插入筛选出的 HTML 代码。语法形如 "url #some > selector"。
这个方法可以很方便的动态加载一些HTML文件,例如表单。
2. jQuery.get( url, [data], [callback] ):使用GET方式来进行异步请求
参数:
url (String) : 发送请求的URL地址.
data (Map) : (可选) 要发送给服务器的数据,以 Key/value 的键值对形式表示,会做为QueryString附加到请求URL中。
callback (Function) : (可选) 载入成功时回调函数(只有当Response的返回状态是success才是调用该方法)。
这是一个简单的 GET 请求功能以取代复杂 $.ajax 。请求成功时可调用回调函数。如果需要在出错时执行函数,请使用 $.ajax。示例代码:
$.get("./Ajax.aspx", {Action:"get",Name:"lulu"}, function (data, textStatus){
//返回的 data 可以是 xmlDoc, jsonObj, html, text, 等等.
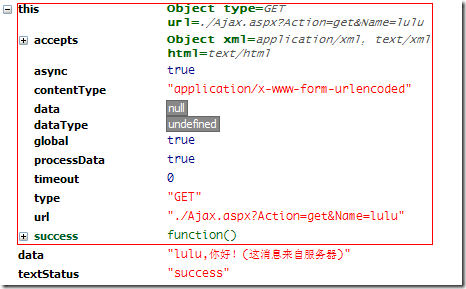
this; // 在这里this指向的是Ajax请求的选项配置信息,请参考下图
alert(data);
//alert(textStatus);//请求状态:success,error等等。
当然这里捕捉不到error,因为error的时候根本不会运行该回调函数
//alert(this);
});
点击发送请求:
jQuery.get()回调函数里面的 this ,指向的是Ajax请求的选项配置信息:
3. jQuery.post( url, [data], [callback], [type] ) :使用POST方式来进行异步请求
参数:
url (String) : 发送请求的URL地址.
data (Map) : (可选) 要发送给服务器的数据,以 Key/value 的键值对形式表示。
callback (Function) : (可选) 载入成功时回调函数(只有当Response的返回状态是success才是调用该方法)。
type (String) : (可选)官方的说明是:Type of data to be sent。其实应该为客户端请求的类型(JSON,XML,等等)
这是一个简单的 POST 请求功能以取代复杂 $.ajax 。请求成功时可调用回调函数。如果需要在出错时执行函数,请使用 $.ajax。
4. jQuery.getScript( url, [callback] ) : 通过 GET 方式请求载入并执行一个 JavaScript 文件。
参数
url (String) : 待载入 JS 文件地址。
callback (Function) : (可选) 成功载入后回调函数。
jQuery 1.2 版本之前,getScript 只能调用同域 JS 文件。 1.2中,您可以跨域调用 JavaScript 文件。注意:Safari 2 或更早的版本不能在全局作用域中同步执行脚本。如果通过 getScript 加入脚本,请加入延时函数。
这个方法可以用在例如当只有编辑器focus()的时候才去加载编辑器需要的JS文件.下面看一些示例代码:
加载并执行 test.js。
jQuery 代码:
$.getScript("test.js");
加载并执行 AjaxEvent.js ,成功后显示信息。
jQuery 代码:
$.getScript("AjaxEvent.js", function(){
alert("AjaxEvent.js 加载完成并执行完成.你再点击上面的Get或Post按钮看看有什么不同?");
});
jQuery.ajax( options ) : 通过 HTTP 请求加载远程数据
这个是jQuery 的底层 AJAX 实现。简单易用的高层实现见 $.get, $.post 等。
$.ajax() 返回其创建的 XMLHttpRequest 对象。大多数情况下你无需直接操作该对象,但特殊情况下可用于手动终止请求。
注意: 如果你指定了 dataType 选项,请确保服务器返回正确的 MIME 信息,(如 xml 返回 "text/xml")。错误的 MIME 类型可能导致不可预知的错误。见 Specifying the Data Type for AJAX Requests 。
当设置 datatype 类型为 'script' 的时候,所有的远程(不在同一个域中)POST请求都回转换为GET方式。
$.ajax() 只有一个参数:参数 key/value 对象,包含各配置及回调函数信息。详细参数选项见下。
jQuery 1.2 中,您可以跨域加载 JSON 数据,使用时需将数据类型设置为 JSONP。使用 JSONP 形式调用函数时,如 "myurl?callback=?" jQuery 将自动替换 ? 为正确的函数名,以执行回调函数。数据类型设置为 "jsonp" 时,jQuery 将自动调用回调函数。(这个我不是很懂)
参数列表:
| 参数名 | 类型 | 描述 |
| url | String | (默认: 当前页地址) 发送请求的地址。 |
| type | String | (默认: "GET") 请求方式 ("POST" 或 "GET"), 默认为 "GET"。注意:其它 HTTP 请求方法,如 PUT 和 DELETE 也可以使用,但仅部分浏览器支持。 |
| timeout | Number | 设置请求超时时间(毫秒)。此设置将覆盖全局设置。 |
| async | Boolean | (默认: true) 默认设置下,所有请求均为异步请求。如果需要发送同步请求,请将此选项设置为 false。注意,同步请求将锁住浏览器,用户其它操作必须等待请求完成才可以执行。 |
| beforeSend | Function | 发送请求前可修改 XMLHttpRequest 对象的函数,如添加自定义 HTTP 头。XMLHttpRequest 对象是唯一的参数。
function (XMLHttpRequest) {
this; // the options for this ajax request
}
|
| cache | Boolean | (默认: true) jQuery 1.2 新功能,设置为 false 将不会从浏览器缓存中加载请求信息。 |
| complete | Function | 请求完成后回调函数 (请求成功或失败时均调用)。参数: XMLHttpRequest 对象,成功信息字符串。
function (XMLHttpRequest, textStatus) {
this; // the options for this ajax request
}
|
| contentType | String | (默认: "application/x-www-form-urlencoded") 发送信息至服务器时内容编码类型。默认值适合大多数应用场合。 |
| data | Object, String |
发送到服务器的数据。将自动转换为请求字符串格式。GET 请求中将附加在 URL 后。查看 processData 选项说明以禁止此自动转换。必须为 Key/Value 格式。如果为数组,jQuery 将自动为不同值对应同一个名称。如 {foo:["bar1", "bar2"]} 转换为 '&foo=bar1&foo=bar2'。 |
| dataType | String |
预期服务器返回的数据类型。如果不指定,jQuery 将自动根据 HTTP 包 MIME 信息返回 responseXML 或 responseText,并作为回调函数参数传递,可用值: "xml": 返回 XML 文档,可用 jQuery 处理。 "html": 返回纯文本 HTML 信息;包含 script 元素。 "script": 返回纯文本 JavaScript 代码。不会自动缓存结果。 "json": 返回 JSON 数据 。 "jsonp": JSONP 格式。使用 JSONP 形式调用函数时,如 "myurl?callback=?" jQuery 将自动替换 ? 为正确的函数名,以执行回调函数。 |
| error | Function | (默认: 自动判断 (xml 或 html)) 请求失败时将调用此方法。这个方法有三个参数:XMLHttpRequest 对象,错误信息,(可能)捕获的错误对象。
function (XMLHttpRequest, textStatus, errorThrown) {
// 通常情况下textStatus和errorThown只有其中一个有值
this; // the options for this ajax request
}
|
| global | Boolean | (默认: true) 是否触发全局 AJAX 事件。设置为 false 将不会触发全局 AJAX 事件,如 ajaxStart 或 ajaxStop 。可用于控制不同的Ajax事件 |
| ifModified | Boolean | (默认: false) 仅在服务器数据改变时获取新数据。使用 HTTP 包 Last-Modified 头信息判断。 |
| processData | Boolean | (默认: true) 默认情况下,发送的数据将被转换为对象(技术上讲并非字符串) 以配合默认内容类型 "application/x-www-form-urlencoded"。如果要发送 DOM 树信息或其它不希望转换的信息,请设置为 false。 |
| success | Function | 请求成功后回调函数。这个方法有两个参数:服务器返回数据,返回状态
function (data, textStatus) {
// data could be xmlDoc, jsonObj, html, text, etc...
this; // the options for this ajax request
}
|
这里有几个Ajax事件参数:beforeSend ,success ,complete ,error 。我们可以定义这些事件来很好的处理我们的每一次的Ajax请求。注意一下,这些Ajax事件里面的 this 都是指向Ajax请求的选项信息的(请参考说 get() 方法时的this的图片)。
本文参考来源http://www.cnblogs.com/yeer/archive/2009/07/23/1529460.html
简单理解同步与异步
何谓同步
一句话总结:必须一件一件事做,等前一件做完了才能做下一件事
进程同步:就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回,这时程序是出于阻塞的,只有接收到返回的值或消息后才往下执行其他的命令。
例子
就是实时处理(如打电话),比如服务器一接收客户端请求,马上响应,这样客户端可以在最短的时间内得到结果,但是如果多个客户端,或者一个客户端发出的请求很频繁,服务器无法同步处理,就会造成涌塞。
同步如打电话,通信双方不能断(我们是同时进行,同步),你一句我一句,这样的好处是,对方想表达的信息我马上能收到,但是,我在打着电话,我无法做别的事情。
何谓异步
一句话总结:发布事情命令就行,完事自行通知
当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
例子
就是分时处理(如收发短信),服务器接收到客户端请求后并不是立即处理,而是等待服务器比较空闲的时候加以处理,可以避免涌塞。
异步如收发收短信,对比打电话,打电话我一定要在电话的旁边听着,保证双方都在线,而收发短信,对方不用保证此刻我一定在手机旁,同时,我也不用时刻留意手机有没有来短信。这样的话,我看着视频,然后来了短信,我就处理短信(也可以不处理),接着再看视频。
其他解释
同步和异步的区别
举个例子:普通B/S模式(同步)AJAX技术(异步)
同步:提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能干任何事
异步: 请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕
总之:
同步在一定程度上可以看做是单线程,这个线程请求一个方法后就待这个方法给他回复,否则他不往下执行(死心眼)。
异步在一定程度上可以看做是多线程的(废话,一个线程怎么叫异步),请求一个方法后,就不管了,继续执行其他的方法。
如有高见,欢迎留言~
本文参考http://blog.csdn.net/tennysonsky/article/details/45111623
那些年,我们被耍过的bug——haslayout
目录
你被IE的bug耍过几次了?
IE,这个令所有网站设计人员讨厌,但又不得不为它工作的浏览器。不论是6、7还是8,它们都有一个共同的渲染标准haslayout,所以haslayout 是一个非常有必要彻底弄清除的概念。大多 数IE下的显示错误,就是源于它。
什么是Layout呢?
"Layout" 是IE特有的一个属性,并不是W3C标准,很多的ie下的css bug都与其息息相关。它决定了一个对象(就是一个标签div、li等)在内容中如何显示、与周围对象的位置关系、以及怎样响应程序或用户产生的事件。
这个属性可以被一些css强制激活。一些HTML标签默认具有haslayout。
PS:一个对象的layout属性被激活,它的具体表现就是haslayout=true。我们可以用IE Developer Toolbar工具看到被激活的对象带有"haslayout = -1"的属性。
特别注意的是,hasLayout 在 IE 8 及之后的 IE 版本中已经被抛弃,所以在实际开发中只需针对 IE 8 以下的浏览器为某些元素触发 hasLayout 。
一个元素触发 hasLayout 会影响一个元素的尺寸和定位,这样会消耗更多的系统资源,因此 IE 设计者默认只为一部分的元素触发 hasLayout (即默认有部分元素会触发 hasLayout ,这与 BFC 基本完全由开发者通过特定 CSS 触发并不一样),这部分元素如下:
<html>, <body> <table>, <tr>, <th>, <td> <img> <hr> <input>, <button>, <select>, <textarea>, <fieldset>, <legend> <iframe>, <embed>, <object>, <applet> <marquee>
很多情况下,我们把 hasLayout的状态改成true 就可以解决很大部分ie下显示的bug。
hasLayout属性不能直接设定,你只能通过设定一些特定的css属性来触发并改变 hasLayout 状态。下面列出可以触发hasLayout的一些CSS属性值。
-------------------------------------
display
启动haslayout的值:inline-block
取消hasLayout的值:其他值
--------------------------------------
width/height
启动hasLayout的值:除了auto以外的值
取消hasLayout的值:auto
---------------------------------------
position
启动hasLayout的值:absolute
取消hasLayout的值:static
----------------------------------------
float
启动hasLayout的值:left或right
取消hasLayout的值:none
---------------------------------------
zoom
启动hasLayout的值:有值
取消hasLayout的值:narmal或者空值
(zoom是微软IE专有属性,可以触发hasLayout但不会影响页面的显示效果。zoom: 1常用来除错,不过 ie 5 对这个属性不支持。)
----------------------------------------
writing-mode: tb-rl
这也是微软专有的属性。
ie7还有一些额外的属性可以触发该属性(不完全列表):
min-height: (任何值)
max-height: (任何值除了none)
min-width: (任何值)
max-width: (任何值除了none)
overflow: (任何值除了visible)
overflow-x: (任何值除了visible)
overflow-y: (任何值除了visible)5
position: fixed
重置haslayout
在没有其它属性激活layout的情况下,使用下面的css可以重置haslayout属性:
- width, height (设为 "auto")
- max-width, max-height (设为 "none")(在 IE 7 中)
- position (设为 "static")
- float (设为 "none")
- overflow (设为 "visible") (在 IE 7 中)
- zoom (设为 "normal")
- writing-mode (从 "tb-rl" 设为 "lr-t")
display 属性的不同:当用"inline-block"激活了haslayout 属性时,就算在一条独立的规则中覆盖这个属性为"block"或"inline",haslayout 这个标志位也不会被重置为 false。
把 mid-width, mid-height 设为它们的默认值"0"仍然会赋予 hasLayout,但是 IE 7 却可以接受一个不合法的属性"auto"来重置 hasLayout。
haslayout 问题引起的常见 bug
IE6 及更低版本的双空白边浮动 bug
bug 修复: display:inline;
IE5-6/win 的 3 像素偏移 bug
bug 修复: _height:1%;
IE6 的躲躲猫(peek-a-boo) bug
bug 修复: _height:1%;
这里列出触发 hasLayout 元素的一些效果
1.阻止外边距折叠
两个相连的 div 在垂直上的外边距会发生叠加,而触发 hasLayout 的元素之间则不会有这种情况发生,如下图:

也可以查看 Demo 。
上图的例子中,三个 div 各包含一个 p 元素,三个 div 及其包含的 p 元素都有顶部和底部的外边距,但只有第三个 div 的边距没有与它的子元素 p 的外边距折叠。这是因为第三个 div 使用 zoom: 1 触发了 hasLayout ,阻止了它与它的子元素的外边距折叠。
另外,例子中也使用了 overflow: hidden 触发元素的 BFC ,这利用了 BFC 阻止外边距折叠的特性达到元素在 IE 与现代浏览器下的表现统一。
2.可以包含浮动的子元素,即计算高度时包括其浮动子元素
效果如图:

上图的例子中,有两个 div ,它们各包含一个设置了浮动的 p 元素,但第一个 div 实际被浏览器判断为没有高度和宽度,即高度为 0 ,上下边框重叠在一起。而第二个 div 使用 zoom: 1 触发了 hasLayout ,可以包含浮动元素,因此能正确表现出高度,其边框位置也正常了。
本例子中也使用了 overflow: hidden 触发 BFC ,跟上例相似,这利用了 BFC 可以包含浮动子元素的特性达到元素在 IE 与现代浏览器下的表现统一。
3.背景图像显示问题
元素背景图不能正确显示是网页重构中最常见的问题之一了,在 IE 7 及以下的 IE 版本中,没有设置高度、宽度的元素往往不能显示出背景图(背景色则显示正常),这实际上与 hasLayout 有关。实际的情况是,没有触发 hasLayout 的元素不能显示背景图,上面有说过,触发 hasLayout 也就是使到元素拥有布局,换句话说,拥有布局的元素才能正确显示背景图。如下图:

也可以看 Demo (在 IE 7 或更低版本的 IE 下查看以观察背景图问题)。
上图两个 div 都设置了背景图,但只有使用 zoom: 1 触发了 hasLayout 的第二个 div 才能正确显示背景图。
本例子中没有触发元素的 BFC ,这是因为在现代浏览器中,元素本身并没有背景图显示问题。
可以看出,上面的第一、二个例子中,为了使到元素在 IE (包括低版本 IE 以及较新版本的 IE)和现代浏览器中表现尽量统一同时触发了 hasLayout 和 BFC ,而第三个例子中的问题因为只在低版本 IE 中出现,所以只需为低版本 IE 触发 hasLayout ,这些技巧在实际项目中需要特别注意。
上面也有说道,hasLayout 与很多 IE 下的显示 bugs 都有关,实际上很多莫名奇妙的 bugs 都因 hasLayout 而起,因此只要适当的触发元素的 hasLayout ,很多 IE bugs 往往就能解决。
input屏蔽历史记录 ;function($,undefined) 前面的分号是什么用处 JSON 和 JSONP 两兄弟 document.body.scrollTop与document.documentElement.scrollTop兼容 URL中的# 网站性能优化 前端必知的ajax 简单理解同步与异步 那些年,我们被耍过的bug——has的更多相关文章
- 前端必知的ajax
简介 异步交互 此篇只介绍部分方法,想了解更多就猛戳这里 1. load( url, [data], [callback] ) :载入远程 HTML 文件代码并插入至 DOM 中. url (Stri ...
- ;function($,undefined) 前面的分号是什么用处
;function($,undefined) 前面的分号是什么用处 ;(function($){$.extend($.fn...现般在一些 JQuery 函数前面有分号,在前面加分号可以有多种用途:1 ...
- JavaScript:彻底理解同步、异步和事件循环(Event Loop) (转)
原文出处:https://segmentfault.com/a/1190000004322358 一. 单线程 我们常说"JavaScript是单线程的". 所谓单线程,是指在JS ...
- JavaScript:彻底理解同步、异步和事件循环(Event Loop)
一. 单线程 我们常说"JavaScript是单线程的". 所谓单线程,是指在JS引擎中负责解释和执行JavaScript代码的线程只有一个.不妨叫它主线程. 但是实际上还存在其他 ...
- [转] JavaScript:彻底理解同步、异步和事件循环(Event Loop)
一. 单线程 我们常说“JavaScript是单线程的”. 所谓单线程,是指在JS引擎中负责解释和执行JavaScript代码的线程只有一个.不妨叫它主线程. 但是实际上还存在其他的线程.例如:处理A ...
- js中请求数据的$post和$ajax区别(同步和异步问题)
$.post和$.Ajax都为页面上向后台发送请求,请求数据 1.post 因为post默认为异步请求,可是有时候我们会发现,本来要求请求马上出现,可是异步会导致后面突然再执行,这样就出很多问题 2. ...
- ajax对象。同步与异步及ajax发送请求
ajax对象的属性.方法 属性 readyState: Ajax状态码 * 0:表示对象已建立,但未初始化,只是 new 成功获取了对象,但是未调用open方法 1:表示对象已初始化,但未发送,调用了 ...
- NIO学习笔记,从Linux IO演化模型到Netty—— 究竟如何理解同步、异步、阻塞、非阻塞
我的观点 首先,分开各自理解. 1. 同步:描述两个(或者多个)个体之间的协调关系. 比如,单线程中,methodA调用了methodB,methodB返回后,methodA才往下执行,那么称A同步调 ...
- Adobe AIR中使用Flex连接Sqlite数据库(1)(创建数据库和表,以及同步和异步执行模式)
系列文章导航 Adobe AIR中使用Flex连接Sqlite数据库(1)(创建数据库和表) Adobe AIR中使用Flex连接Sqlite数据库(2)(添加,删除,修改以及语句参数) Adobe ...
随机推荐
- Centos 开机自动联网
默认情况下,Centos不是自动连接上网的,要点击右上角有个电脑图标,选择system eth0进行连接, 可以修改开机启动配置只需修改:/etc/sysconfig/network-scripts/ ...
- js中关于string转date类型的转换
var date_up = input.split("-");//input表示string类型(时间例如:2017-11-12 10:07:36.653) var date_do ...
- Python学习日记之练习代码
# -*- coding:utf-8 -*- number = 23 test=True while test: guess=int(raw_input('输入数字')) if guess==numb ...
- 联想 S5 Pro(L78041)免解锁BL 免rec 保留数据 ROOT Magisk Xposed 救砖 ZUI 5.0.123
>>>重点介绍<<< 第一:本刷机包可卡刷可线刷,刷机包比较大的原因是采用同时兼容卡刷和线刷的格式,所以比较大第二:[卡刷方法]卡刷不要解压刷机包,直接传入手机后用 ...
- "HybridDB · 性能优化 · Count Distinct的几种实现方式” 读后感
原文地址:HybridDB · 性能优化 · Count Distinct的几种实现方式 HybridDB是阿里基于GreenPlum开发的一款MPP分析性数据库,而GreenPlum本身基于Post ...
- [Windows Server 2008] MySQL单数据库迁移方法
★ 欢迎来到[护卫神·V课堂],网站地址:http://v.huweishen.com ★ 护卫神·V课堂 是护卫神旗下专业提供服务器教学视频的网站,每周更新视频. ★ 本节我们将带领大家:MySQL ...
- PHP 在表单POST提交后数据分页实现,非GET,解决只有第一页显示正确的问题
//PHP 在表单POST提交后数据分页实现,非GET,使用SESSION,分页代码部分不在详述,主要为POST后的 除第一页之外的显示问题 //以下为ACTION页面 内容,仅为事例,当判断到页面未 ...
- JAVA程序员面试笔试宝典4
1.HTTP中GET与POST方法有什么区别? GET方法上传数据时,数据添加在URL后面.同时,数据大小有限制,通常在1024Byte左右.POST方法传递数据是通过HTTP请求的附件进行的,传递的 ...
- js识别手机访问自动跳转到相应页面
/* * 智能机浏览器版本信息: * */ var browser={ versions:function(){ var u = navigator.userAgent, app = navigato ...
- NOIP 2006 金明的预算方案(洛谷P1064,动态规划递推,01背包变形,滚动数组)
一.题目链接:P1064 金明的预算方案 二.思路 1.一共只有五种情况 @1.不买 @2.只买主件 @3.买主件和附件1(如果不存在附件也要运算,只是这时附件的数据是0,也就是算了对标准的结果也没影 ...