Bag of word based image retrieval
主要参考维基百科Bag of Word
在DLP领域里,bow(bag of word)是一个稀疏的向量,向量的每个元素记录词的出现次数,相当于对每篇文章都关于词典做词的直方图统计。同样的道理用在computer vision领域,图像由一些基础的特征构成,每幅图像就是对这些特征的一个统计分布,在做图像分类时会假设相似图像他们的特征统计分布也符合一定的模型。于是从这句话里就可以把以bow模型的图像分类问题分解成以下几步:
1.1 特征检测; 1.2 特征描述;1.3 码本生成(bow向量)
2.1 生成模型(Generative model)2.2 判别模型(Discriminate model)
1. 基于BoW模型的图像表达
在这里可以给bow进行一个简单的定义:图像独立特征的统计表达。【Histogram representation based on independent features】
1.1 特征检测
Content based image indexing and retrieval(CBIR)对特征提取进行了详细的介绍,这里需要指出的是特征检测是一个很初级的概念,得到具有区别性的区域,我们通常能写出显示形式的特征已经涉及到了特征表达部分。
1.2 特征表达
对于特征区域进行描述的方法称为特征表达,一个好的描述子应该具有强度/旋转/尺度/放射变化不变性。比较出名的就是SIFT算子,将每个特征块转换为128维的特征向量,而每幅图像就是一系列SIFT特征向量的集合。
1.3 码本生成
在BoW最后一步就是把SIFT特征向量用一个码元表示,就像是一个word。由于特征向量128维度,每个维度哪怕量化为8bit,最后的马元组合数也是8的128次方,过于巨大,所以一般的方式是对所有图像的SIFT特征进行K-means聚类,K即是最后的码本集合大小,码元就是聚类的中心,图像上的SIFT采用最近邻的方式映射到聚类中心。最后整幅图像就被表达为SIFT聚类中心(码元)的统计分布。
- 关于聚类这一点,在NLP也有一定的体现,只是不是用k-means的方法,而是stemming word得到一个词干作为码元,进行词干的统计。
- 以单个单词构成的码本维度大概是170,000个,去掉废弃词统计为100,000左右,但stem后应该只有10K左右吧(根据自己实验里遇到的情况,不一定正确)。
- 图像的BoW可以自己人工设定,一般在1K量级,视情况而定。
2. 基于BoW模型的分离器学习和识别
在我们得到一幅图像的表达后,就会考虑其在这种特征空间下具有什么样的分布特性,并根据分布特性设计分类器实现分类和识别。对应BoW模型的分类方法主要分为生成模型和判别模型两大主流。
2.1 生成模型
朴素贝叶斯模型,因为其简单有效,常常被用来作为baseline的方法。
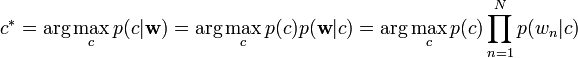
层次贝叶斯模型
由于朴素贝叶斯在一副图像包含了几个不同主题的情况下不能取得很好的效果,于是提出其他拓展,如潜语义分析 Probabilistic latent semantic analysis (pLSA)和主题模型 latent Dirichlet allocation (LDA)是比较著名的用作出来多主题的方法。
2.2 判别模型
由于图像被表达为BoW,所以适合适用于文档的判别模型都可以用来对图像的BoW进行分类。常见的有SVM和AdaBoost.
下一篇见BoW(SIFT/SURF/...)+SVM/KNN的OpenCV 实现
Bag of word based image retrieval的更多相关文章
- 基于内容的图片检索CBIR(Content Based Image Retrieval)简介
传统的图像检索过程,先通过人工对图像进行文字标注,再利用关键字来检索图像,这种依据图像描述的字符匹配程度提供检索结果的方法,简称“以字找图”,既耗时又主观多义.基于内容的图像检索客服“以字找图”方式的 ...
- 第十讲_图像检索 Image Retrieval
第十讲_图像检索 Image Retrieval 刚要 主要是图像预处理和特征提取+相似度计算 相似颜色检索 算法结构 颜色特征提取:统计图片的颜色成分 颜色特征相似度计算 色差距离 发展:欧式距离- ...
- 【Paper Reading】Deep Supervised Hashing for fast Image Retrieval
what has been done: This paper proposed a novel Deep Supervised Hashing method to learn a compact si ...
- SpringBoot集成文件 - 如何基于POI-tl和word模板导出庞大的Word文件?
前文我们介绍了通过Apache POI通过来导出word的例子:那如果是word模板方式,有没有开源库通过模板方式导出word呢?poi-tl是一个基于Apache POI的Word模板引擎,也是一个 ...
- {ICIP2014}{收录论文列表}
This article come from HEREARS-L1: Learning Tuesday 10:30–12:30; Oral Session; Room: Leonard de Vinc ...
- ### Paper about Event Detection
Paper about Event Detection. #@author: gr #@date: 2014-03-15 #@email: forgerui@gmail.com 看一些相关的论文. 1 ...
- (转) Awesome Deep Learning
Awesome Deep Learning Table of Contents Free Online Books Courses Videos and Lectures Papers Tutori ...
- 自然语言19_Lemmatisation
QQ:231469242 欢迎喜欢nltk朋友交流 https://en.wikipedia.org/wiki/Lemmatisation Lemmatisation (or lemmatizatio ...
- word2vec代码解释
以前看的国外的一篇文章,用代码解释word2vec训练过程,觉得写的不错,转过来了 原文链接 http://nbviewer.jupyter.org/github/dolaameng/tutorial ...
随机推荐
- JAVA 学习笔记 - 基础语法 2
---恢复内容开始--- 1.数组的申明和应用 数据类型 数组名称[] = null; //在堆栈中申明变量名称 数组名称 = new 数据类型[10]; // ...
- HDU_1207_汉诺塔2
汉诺塔II Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submi ...
- Crash (computing)
In computing, a crash (or system crash) occurs when a computer program, such as a software applicati ...
- 计算机网络(二)--HTTP详解
Web相关内容都是存储在Web服务器上,Web服务器上使用的是http协议,因此也被成为http服务器.http的client.server构成了万维网的 基本组件 一.资源 1.URI: 统一资源标 ...
- 11Java Server Pages 动作
Java Server Pages 动作 JSP标准动作 分类 JSP标准动作 存取JavaBean相关 <jsp:useBean> <jsp:setProperty> < ...
- Eigen库笔记整理(二)
Eigen/Geometry 模块提供了各种旋转和平移的表示 旋转矩阵直接使用 Matrix3d 或 Matrix3f Eigen::Matrix3d rotation_matrix = Eigen: ...
- Gym - 101670A Amusement Anticipation(CTU Open Contest 2017 签到题)
题目&题意: 倒着找处于最后位置的等差数列的开头的位置. 例: 1 5 3 4 5 6 3 4 5 6是等差数列,它的开头的位置是3 PS: 读题真的很重要!!!!多组输入,上来就读错了!! ...
- Linux 安装 Tomcat 详解
说明:安装的 tomcat 为解压版(即免安装版):apache-tomcat-8.5.15.tar.gz (1)使用 root 用户登录虚拟机,在根目录下的 opt 文件夹新建一个 software ...
- VM 安装ubuntu16.04简易方法
在已经安装好VM10虚拟机后 首先文件—>新建虚拟机—>典型(标准) 选择稍后安装操作系统,后续要使用的是已经下载好的ubuntu16.04镜像 选择操作系统是linux ,版本是ub ...
- LINUX-JPS工具
JPS工具 jps(Java Virtual Machine Process Status Tool)是JDK 1.5提供的一个显示当前所有java进程pid的命令,简单实用,非常适合在linux/u ...