nginx 多进程 + io多路复用 实现高并发
一、nginx 高并发原理
简单介绍:nginx 采用的是多进程(单线程) + io多路复用(epoll)模型 实现高并发
二、nginx 多进程
- 启动nginx

解析初始化配置文件后会 创建(fork)一个master进程 之后 这个进程会退出
master 进程会 变为孤儿进程 由init进程托管。(可以通过python 或php 启动后创建子进程,然后杀死父进程得见子进程会由init进程托管)
如下图可以看到nginx master 进程由init(ppid 为1 )进程管理。
.png)
- master进程和worker进程
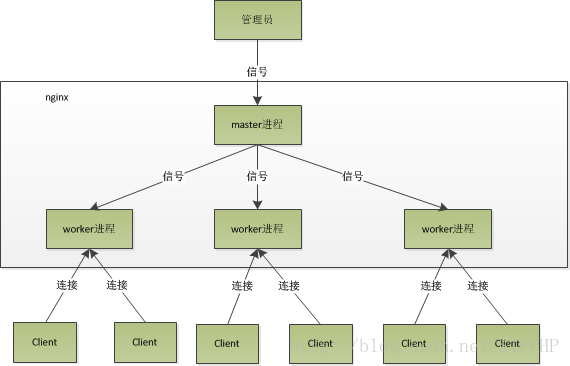
1、master
首先nginx 创建一个master 进程,通过socket() 创建一个sock文件描述符用来监听(sockfd)
绑定端口(bind) 开启监听(listen)。
nginx 一般监听80(http) 或 443 (https)端口
(fork 多个子进程后,master 会监听worker进程,和等待信号)
2、worker
然后 创建(fork)多个 worker子进程(复制master 进程的数据),
此时所有的worker进程 继承了sockfd(socket文件描述符),
当有连接进来之后 worker进程就可以accpet()创建已连接描述符,
然后通过已连接描述符与客户端通讯
- 惊群现象
由于worker进程 继承了master进程的sockfd,当连接进来是,所有的子进程都将收到通知并“争着”与
它建立连接,这就叫惊群现象。大量的进程被激活又挂起,最后只有一个进程accpet() 到这个连接,这会消耗系统资源
(等待通知,进程被内核全部唤醒,只有一个进程accept成功,其他进程又休眠。这种浪费现象叫惊群)
- nginx 对惊群现象的处理
原因:
多个进程监听同一个端口引发的。
解决:
如果可以同一时刻只能有一个进程监听端口,这样就不会发生“惊群”了,此时新连接事件只能唤醒正在监听的唯一进程。
如何保持一个时刻只能有一个worker进程监听端口呢?nginx设置了一个accept_mutex锁,在使用accept_mutex锁是,
只有进程成功调用了ngx_trylock_accept_mutex方法获取锁后才可以监听端口
(linux 内核2.6 之后 不会出现惊群现象,只会有一个进程被唤醒)
- 代码简单理解
.png)
三、worker进程
- worker进程做了什么事
从上图中,我们可以看到worker进程做了
1、accept() 与客户端建立连接
2、recv()接收客户端发过来的数据
3、send() 向客户端发送数据
4、close() 关闭客户端连接
- 如果不使用io多路复用 会是什么样的
首先 等待客户端有连接进来
accpet() 与客户端建立连接后
recv() 一直等待客户的发送过来数据(此时处于io阻塞状态)
如果此时又有客户端过来建立连接,那么只能等待,需要一直等待close() 之后才可以建立连接
也就是说这个worker进程会因为recv() 而处于阻塞状态,而不能处理与其他客户端建立连接,
这段时间不能做任何事,这是对性能了浪费。
(进程 和线程的切换也是需要消耗 时间的。)
- 能不能利用io堵塞的时间 accept,recv
nginx 采用了io多路复用技术实现了
四、io多路复用
- 什么是io复用
IO复用解决的就是并发行的问题,比如多个用户并发访问一个WEB网站,对于服务端后台而言就会产生多个请求,处理多个请求对于中间件就会产生多个IO流对于系统的读写。那么对于IO流请求操作系统内核有并行处理和串行处理的概念,串行处理的方式是一个个处理,前面的发生阻塞,就没办法完成后面的请求。这个时候我们必须考虑并行的方式完成整个IO流的请求来实现最大的并发和吞吐,这时候就是用到IO复用技术。IO复用就是让一个Socket来作为复用完成整个IO流的请求。
当然实现整个IO流的请求多线程的方式就是其中一种。
(一个socket作为复用来完成整个io流的请求连接建立(accept),而处理请求(recv,send,close)则采用多线程)
- io复用之多线程处理
# -*- coding:utf-8 -*-
import socket
from threading import Thread
def comm(conn):
data = conn.recv(1024)
conn.send(data)
conn.close()
obj = socket.socket(socket.AF_INET,socket.SOCK_STREAM) # sockfd (socket 文件描述符,这个描述符是用来监听的--监听socket)
obj.bind(('127.0.0.1',8082)) # 绑定地址
obj.listen(5) # 开启监听
while True:
conn,addr = obj.accept() // 每建立一个 连接 就交由线程处理
t = Thread(target=comm,args=(conn,)) // 创建线程对象
t.start() // 启动
// 这样就可以处理多个io请求,不会因为一个没处理完而导致的堵塞
- io 多路复用
多个描述符(监听描述符,已连接描述符) 的io 操作都能在一个线程内并发交替顺序完成,这就叫io多路复用,
这里的复用指的是复用同一个线程
io 多路复用的三种机制 select poll epoll
- select
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
//参数nfds是需要监听的最大的文件描述符值+1
//rdset,wrset,exset分别对应需要检测的可读文件描述符的集合,
//可写文件描述符的集合集异常文件描述符的集合
//参数timoout为结构timeval,用来设置select()的等待时间
1、用户将自己所关心的文件描述符添加进描述符集中,并且明确关心的是读,写,还是异常事件
2、select 通过轮询的方式不断扫码所有被关心的文件描述符,具体时间由参数timeout决定的
3、执行成功则返回文件描述符已改变的个数
4、具体哪一个或哪几个文件描述符就绪,则需要文件描述符集传出,它既是输入型参数,又是输出型参数
5、fd_set 是用位图存储文件描述符的,因为文件描述符是唯一且递增的整数
特点:
1、可关心的文件描述符数量是有上限的,取决于fd_set(文件描述符集)的大小
2、每次的调用select 前,都要把文件描述符重新添加进fd_set(文件描述符集)中,因为fd_set也是输出型参数
在函数返回后,fd_set中只有就绪的文件描述符
3、通常我们要关心的文件描述符不止一个,所有首先用数组保存文件描述符,每次调用select前再通过遍历数逐个添加进去缺点:
1、每次调用select都需要手动设置fd_Set
2、每次调用select 需要遍历fd_set 集合,而且要将fd_set 集合从用户态拷贝到内核态,如何fd很多时,开销会很大
3、select 支持的文件描述符数量太少 32- 1024 64 -2048
- poll
#include <sys/poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
// 第一个参数是指向一个结构数组的第一个元素的指针
// 第二个参数是要监听的文件描述符的个数
// 第三个参数意义与select相同 //pollfd结构
struct pollfd{
int fd;
short events;
short revents;
};
//events 是我们要关心的事件,revents是调用后操作系统设置的参数,
//也就是表明该文件描述符是否就绪
首先创建一个pollfd结构体变量数组fd_list,然后将我们然后将我们关心的fd(文件描述符)放置在数组中的结构变量中,
并添加我们所关系的事件,调用poll函数,函数返回后我们再通过遍历的方式去查看数组中那些文件描述符上的事件就绪了。
特点(相对于select)
1、每次调用poll之前不需要手动设置文件描述符集
2、poll将用户关系的实际和发生的实际进程分离
3、支持的文件描述符数量理论上是无上限的,其实也有,
因为一个进程能打开的文件数量是有上限的 ulimit -n 查看进程可打开的最大文件数
1、poll 返回后,也需要轮询pollfd 来获取就绪的描述符
2、同时连接的大量客户端,可能只有很少的处于就绪状态,因此随着监事的描述符数量的增长,其效率也会线性下降
- select poll 的共同点
都做了很多 无效的 轮询检测描述符是否就绪的操作
- epoll
- 代码
#include <sys/epoll.h>
int epoll_create(int size); // 在内核里,一切皆文件。所以,epoll向内核注册了一个文件系统,
//epoll_create的作用是创建一个epoll模型,该模型在底层建立了->
//**红黑树,就绪队列,回调机制**
//size可以被忽略,不做解释 int epoll_ctl(int epfd, int op, int fd, struct epoll_events *event);
//epfd:epoll_create()的返回值(epoll的句柄,本质上也是一个文件描述符)
//op:表示动作,用三个宏来表示
// EPOLL_CTL_ADD:注册新的fd到epfd中
// EPOLL_CTL_MOD:修改已经注册的fd的监听事件
// EPOLL_CTL_DEL:从epfd中删除一个事件
//fd:需要监听的文件描述符
//event:具体需要在该文件描述符上监听的事件 int epoll_wait(int epfd, struct epoll_event *events, int maxevents,
int timeout);
//函数调用成功,返回文件描述符就绪的个数,也就是就绪队列中文件描述符的个数,
//返回0表示超时,小于0表示出错 //epoll_event结构体
struct epoll_event{
uint32_t events; /* Epoll events */
epoll_data_t data;/* User data variable */
}__EPOLL_PACKED;
//events可以是一堆宏的集合,这里介绍几个常用的
// EPOLLIN:表示对应的文件描述符可以读(包括对端socket正常关闭)
// EPOLLOUT:表示对应的文件描述符可以写
// EPOLLET:将EPOLL设为边缘触发(Edge Triggered)模式,
// 默认情况下epoll为水平触发(Level Triggered)模式
typedef union epoll_data{
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
}epoll_data_t;
//联合体里通常只需要填充fd就OK了,其他参数暂时可以不予理会
- 工作原理
1、创建一个epoll 对象,向epoll 对象中添加文件描述符以及我们所关心的在在该文件描述符上发生的事件
2、通过epoll_ctl 向我们需要关心的文件描述符中注册事件(读,写,异常等),
操作系统将该事件和对象的文件描述符作为一个节点插入到底层建立的红黑树中
3、添加到文件描述符上的实际都会与网卡建立回调机制,也就是实际发生时会自主调用一个回调方法,
将事件所在的文件描述符插入到就绪队列中
4、引用程序调用epoll_wait 就可以直接从就绪队列中将所有就绪的文件描述符拿到,可以说时间复杂度O(1)
- 水平触发工作方式(LT)
处理socket时,即使一次没将数据读完,下次调用epoll_wait时该文件描述符也会就绪,可以继续读取数据
- 边沿触发工作方式(ET)
处理socket时没有一次将数据读完,那么下次再调用epoll_wait该文件描述符将不再显示就绪,除非有新数据写入 在该工作方式,当一个文件描述符就绪是,我们要一次性的将数据读完
- 隐患问题
当我们调用read读取缓冲去数据时,如果已经读取完了,对端没有关系蟹段,read就会堵塞,影响后续逻辑 解决方式就是讲文件描述符,设置成非堵塞的,当没有数据的时候,read也不会被堵塞,
可以处理后续逻辑(读取其他的fd或者继续wait) ET 的性能要好与LT,因为epoll_wait返回的次数比较少,ninx中默认采用ET模式使用epoll
- 特点
1、采用了回调机制,与轮询区别看待
2、底层采用红黑树结构管理已经注册的文件描述符
3、采用就绪队列保存已经就绪的文件描述符
- 优点
1、文件描述符数目无上限:通过epoll_ctl 注册一个文件描述符后,底层采用红黑树结构管理所有需要监控的文件描述符
2、基于实际的就绪通知方式:每当有文件描述符就绪时,该响应事件会调用回调方法将该文件描述符插入到就绪队列中,
不需要内核每次去轮询式的查看每个被关心的文件描述符
3、维护就绪队列:当文件描述符就绪的时候,就会被放到内核中的一个就绪队列中,
调用epoll_wait可以直接从就绪队列中获取就绪的文件描述符,时间复杂度是O(1)
四、总结
nginx 通过 多进程 + io多路复用(epoll) 实现了高并发
采用多个worker 进程实现对 多cpu 的利用
通过eopll 对 多个文件描述符 事件回调机制和就绪描述符的处理 实现单线程io复用
从而实现高并发
nginx 多进程 + io多路复用 实现高并发的更多相关文章
- nginx + uWSGI 为 django 提供高并发
django 的并发能力真的是令人担忧,这里就使用 nginx + uwsgi 提供高并发 nginx 的并发能力超高,单台并发能力过万(这个也不是绝对),在纯静态的 web 服务中更是突出其优越的地 ...
- IO多路复用丶基于IO多路复用+socket实现并发请求丶协程
一丶IO多路复用 IO多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作 IO多路复用作用: 检测多个socket是否已经发生变 ...
- nginx简介(轻量级开源高并发web服务器:大陆使用者百度、京东、新浪、网易、腾讯、淘宝等)(并发量5w)(一般网站apache够用了,而且稳定)
nginx简介(轻量级开源高并发web服务器:大陆使用者百度.京东.新浪.网易.腾讯.淘宝等)(并发量5w)(一般网站apache够用了,而且稳定) 一.总结 1.在连接高并发的情况下,Nginx是A ...
- 【分享】我们用了不到200行代码实现的文件日志系统,极佳的IO性能和高并发支持,附压力测试数据
很多项目都配置了日志记录的功能,但是,却只有很少的项目组会经常去看日志.原因就是日志文件生成规则设置不合理,将严重的错误日志跟普通的错误日志混在一起,分析起来很麻烦. 其实,我们想要的一个日志系统核心 ...
- Nginx优化具体,应对高并发
nginx指令中的优化(配置文件) worker_processes 8; nginx进程数,建议依照cpu数目来指定.一般为它的倍数. worker_cpu_affinity 00000001 ...
- nginx安装lua模块实现高并发
nginx安装lua扩展模块 1.下载安装LuaJIT-2.0.4.tar.gz wget -c http://luajit.org/download/LuaJIT-2.0.4.tar.gz tar ...
- nginx、swoole高并发原理初探
阅前热身 为了更加形象的说明同步异步.阻塞非阻塞,我们以小明去买奶茶为例. 同步与异步 同步与异步的重点在消息通知的方式上,也就是调用结果通知的方式. 同步:当一个同步调用发出去后,调用者要一直等待调 ...
- 第15章 高并发服务器编程(2)_I/O多路复用
3. I/O多路复用:select函数 3.1 I/O多路复用简介 (1)通信领域的时分多路复用 (2)I/O多路复用(I/O multiplexing) ①同一线程,通过“拨开关”方式,来同时处理多 ...
- java的高并发IO原理,阻塞BIO同步非阻塞NIO,异步非阻塞AIO
原文地址: IO读写的基础原理 大家知道,用户程序进行IO的读写,依赖于底层的IO读写,基本上会用到底层的read&write两大系统调用.在不同的操作系统中,IO读写的系统调用的名称可能不完 ...
随机推荐
- thinkphp整合系列之微信公众号支付
<?phperror_reporting(E_ALL);ini_set('display_errors', '1');// 定义时区ini_set('date.timezone','Asia/S ...
- springboot 集成日志 yml配置
原文:https://www.cnblogs.com/bigben0123/p/7895696.html
- hdu 4033 状态压缩枚举
/* 看别人的的思路 搜索搜不出来我太挫了 状态压缩枚举+好的位置 */ #include<stdio.h> #include<string.h> #define N 20 i ...
- bzoj1007 [HNOI2008]水平可见直线 - 几何 - hzwer.com
Description Input 第一行为N(0 < N < 50000),接下来的N行输入Ai,Bi Output 从小到大输出可见直线的编号,两两中间用空格隔开,最后一个数字后面也必 ...
- rsync远程文件传输
[root@rhel5 ~]# rsync -a log.tar.gz root@192.168.124.129:/tmp root@192.168.124.129's password: Permi ...
- Parent and son
Give you a tree with N vertices and N‐ 1 edges, and then ask you Q queries on “which vertex is Y's s ...
- JVM(五):探究类加载过程-上
JVM(五):探究类加载过程-上 本文我们来研究一个Java字节码文件(Class文件)是如何加载入内存中的,在這個过程中涉及类加载过程中的加载,验证,准备,解析(连接),初始化,使用,销毁过程,并探 ...
- Eclipse完成Maven + Spring Boot + Mybatis + jsp
Spring Boot 完成WEB项目开发 开发工具:eclipse 框架:Maven:Spring Boot:Mybatis 界面:jsp:javascript:css 前言: 在SpringBoo ...
- Ext-js使用指南(总结)
一.获取元素(Getting Elements) 1.Ext.get var el = Ext.get('myElementId');//获取元素,等同于document.getElementById ...
- Python学习系列之内置函数
数学相关 abs(a):求取绝对值 max(list):求取list最大值 min(list):求取list最小值 sum(list):求取list元素的和 sorted(list):排序,返回排序后 ...