xpath选择器
一、xpath中节点关系
父(Parent):每个元素以及属性都有一个父
子(Children):元素节点可有零个、一个或多个子
同胞(Sibling):拥有相同的父的节点
先辈(Ancestor):某节点的父、父的父
后代(Descendant):某个节点的子,子的子
二、xpath中选取节点的路径表达式
/ 绝对路径
// 相对路径
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
三、xpath中“谓语”
放在[]中的几种查找方式写法如下:
//ul/li[1] , 表示选择 ul多个li子元素中的第一个
//ul/li[last()], 表示选择ul子元素中的最后一个li元素
//ul/li[last()-1], 表示选择ul子元素中的倒数第二个li元素
//ul/li[position()<3],表示选取最前面2个属于ul元素的li子元素
//a[@href] ,表示选取只要含有href属性的a元素
//a[@href='http://www.cnblogs.com/jenniferhuang'] ,属性值完全匹配
//input[contains(@id,'quantityTextBox')], 当属性值部分匹配时,插入函数的写法
四、xpath函数
函数被分成四类
节点集函数: last(), position(),
字符串函数: contains(), substring(@class,'abc')="", substring-before(), substring-after(), string-length()
布尔函数:
数字函数:
reference : http://www.cnblogs.com/cxd4321/archive/2007/09/24/903869.html SearchKkeyword: "核心函数库"
五、xpath轴
|
轴名称 |
结果 |
|
ancestor |
选取当前节点的所有先辈(父、祖父等) |
|
ancestor-or-self |
选取当前节点的所有先辈(父、祖父等)以及当前节点本身 |
|
descendant |
选取当前节点的所有后代元素(子、孙等) |
|
descendant-or-self |
选取当前节点的所有后代元素(子、孙等)以及当前节点本身 |
|
parent |
选取当前节点的父节点 |
|
child |
选取当前节点的所有子元素 |
|
following |
选取文档中当前节点的结束标签之后的所有节点 |
|
preceding |
选取文档中当前节点的开始标签之前的所有节点 |
|
preceding-sibling |
选取当前节点之前的所有同级节点 |
|
attribute |
选取当前节点的所有属性 |
|
namespace |
选取当前节点的所有命名空间节点 |
|
self |
选取当前节点 |
六、应用举例
1、定位某个节点,该节点包含有一已知的特定后代节点
//table[contains(@class,'orderHistoryBox') and descendant::dd[text()='11132789']]
2、定位一已知节点的某一先辈节点
//dd[text()='11132789']//ancestor::table[contains(@class,'orderHistoryBox')](与1效果相同)
3、不包含的写法
//table[@id='wizards-ivrKeyPressAssignment-extSelectorForm-mailbox-field']/tbody/tr[not(contains(@class,'x-hidden'))][5]
4、注意class的取用:
//*[contains(@id,'userCallForwarding/rules-hoursSelector-tabBar-root-item') and contains(@class,'textTabButtonSelected')]
该class可以不是当前id''userCallForwarding/rules-hoursSelector-tabBar-root-item'' 下的class,可以是其包含标签内其他元素的class,例如下面对应的xpath结构
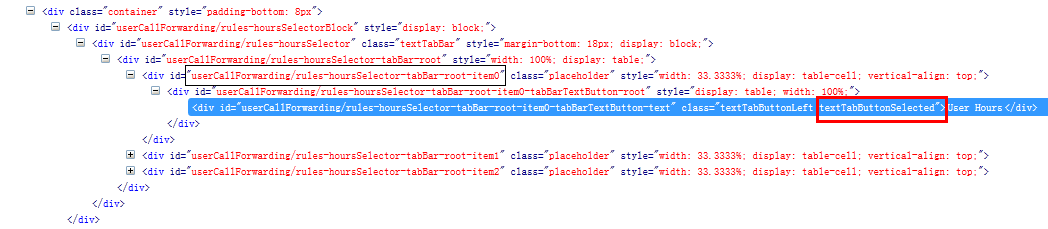
//*[contains(@id,'userCallForwarding/rules-hoursSelector-tabBar-root-item') and contains(@class,'textTabButtonSelected')]@id
可以取到Attribute"userCallForwarding/rules-hoursSelector-tabBar-root-item0-tabBarTextButton-text"
5、xpath拆分法可以增强稳定性
例如:
public TabBar(String id) {
super(id);
rootLocator = locator + PropertyReader.getProperty("Controls.TabBar.root");
itemLocator = rootLocator + PropertyReader.getProperty("Controls.TabBar.item");
}
6、xpath带有变量
例如:
extensionDescription.xpath=//tbody[@id='system-extensions-usersGrid-tbody']//div[@class='system-extensions-title' and text()='$VALUE']/../../following-sibling::*[1]
真正要取列表中哪个Description:
extensionDescription.getxPath().replace("$VALUE",groupName)
7、取属性值
id=entry-settings-phoneSystem-departments@class
或者 //*[@id='entry-settings-phoneSystem-departments']@class
http://www.51testing.com/?uid-79191-action-spacelist-type-blog-itemtypeid-25252
WebElement label = driver.findElement(By.xpath("//label[text()='User Name:' and not(contains(@style,'display:none'))]"))
More examples:
http://www.zvon.org/xxl/XPathTutorial/General_chi/examples.html
xpath选择器的更多相关文章
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
- 常用xpath选择器和css选择器总结
xpath选择器 表达式 说明 article 选取所有article元素的所有子节点 /article 选取根元素article article/a 选取所有属于article的子元素的a元素 // ...
- xpath选择器简介及如何使用
xpath选择器简介及如何使用 一.总结 一句话总结:XPath 的全称是 XML Path Language,即 XML 路径语言,它是一种在结构化文档(比如 XML 和 HTML 文档)中定位信息 ...
- 在Scrapy中如何利用Xpath选择器从HTML中提取目标信息(两种方式)
前一阵子我们介绍了如何启动Scrapy项目以及关于Scrapy爬虫的一些小技巧介绍,没来得及上车的小伙伴可以戳这些文章: 手把手教你如何新建scrapy爬虫框架的第一个项目(上) 手把手教你如何新建s ...
- Selenium(九):Xpath选择器
1. Xpath选择器 1.1 Xpath语法简介 前面我们学习了CSS选择元素. 大家可以发现非常灵活.强大. 还有一种灵活.强大的选择元素的方式,就是使用Xpath表达式. XPath (XML ...
- 用Xpath选择器解析网页(lxml)
在<爬虫基础以及一个简单的实例>一文中,我们使用了正则表达式来解析爬取的网页.但是正则表达式有些繁琐,使用起来不是那么方便.这次我们试一下用Xpath选择器来解析网页. 首先,什么是XPa ...
- xpath选择器使用
简单说,xpath就是选择XML文件中节点的方法. 所谓节点(node),就是XML文件的最小构成单位,一共分成7种. - element(元素节点)- attribute(属性节点)- text ( ...
- 初始scrapy,简单项目创建和CSS选择器,xpath选择器(1)
一 安装 #Linux: pip3 install scrapy #Windows: a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu ...
- 使用 XPath 选择器
在前面的内容中,我们掌握了一些 CSS 选择器和它们的使用方法,以及 rvest 包中用于提取网页内容的函数.一般来说,CSS 选择器足够满足绝大部分的 HTML 节点匹配的需要.但是,当需要根据某些 ...
随机推荐
- eclipse简单注释规范
设置注释模板的入口: Window->Preference->Java->Code Style->Code Template Types/*** @ClassName: ${t ...
- shell 加法
shell 加法 i=$i+1 是在i的变量值后加上字符串'+1' 总结:其他语言中的$i++操作在shell中表示如下:#!/bin/bash n=1;echo -n "$n " ...
- vijosP1413 Valentine’s Present
vijosP1413 Valentine’s Present 链接:https://vijos.org/p/1413 [思路] 组合公式. 由题目知:每个箱子中的蛋糕要么与箱子颜色相同,要么指向一个蛋 ...
- MVC 5 第三章 HTML Helper
提及到HTML helper大家肯定不应该陌生, 因为在书写MVC View的时候肯定需要使用到它.一个HTML Help就是一个返回HTML字符串的方法,这个字符串表示你所期望的类型的内容.例如,你 ...
- 用BigDecimal类实现Fibonacci算法
Fibonacci(N)=Fibonacii(N-1)+Fibonacci(N-2) 其中 Fibonacci(0)=0;Fibonacci(1)=1 用循环或则递归实现Fibonacci算法很简单, ...
- suse安装软件命令
zypper se xxxxx 是搜索软件包 zypper in xxxxx 跟apt-get install xxxx等价 zypper rm xxxx 删除 zypper up xxxx 更新软件
- 使用VisualSVN Server搭建SVN服务器(转载)
转载于http://www.cnblogs.com/greywolf/archive/2013/01/28/2879952.html 使用 VisualSVN Server来实现主要的 SVN功能则要 ...
- cocos2d-x 屏幕适配新解
转自:http://blog.leafsoar.com/archives/2013/05-10-19.html 为了适应移动终端的各种分辨率大小,各种屏幕宽高比,在 cocos2d-x(当前稳定版:2 ...
- 【14】在资源管理类中小心copying行为
1.为什么要使用资源管理类? 资源管理类的思路就是,栈上的对象,封装堆上分配的资源,确保一定会释放资源.auto_ptr和shared_ptr就是资源管理类,行为上像指针. 2.auto_ptr和sh ...
- http://xss.heimaoseoer.com/TIqiri?1413093855
http://xss.heimaoseoer.com/TIqiri?1413093855 xss教程地址