python - 操作RabbitMQ
python - 操作RabbitMQ
介绍
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
应用场景:
RabbitMQ无疑是目前最流行的消息队列之一,对各种语言环境的支持也很丰富,作为一个.NET developer有必要学习和了解这一工具。消息队列的使用场景大概有3种:
1、系统集成,分布式系统的设计。各种子系统通过消息来对接,这种解决方案也逐步发展成一种架构风格,即“通过消息传递的架构”。
2、当系统中的同步处理方式严重影响了吞吐量,比如日志记录。假如需要记录系统中所有的用户行为日志,如果通过同步的方式记录日志势必会影响系统的响应速度,当我们将日志消息发送到消息队列,记录日志的子系统就会通过异步的方式去消费日志消息。
3、系统的高可用性,比如电商的秒杀场景。当某一时刻应用服务器或数据库服务器收到大量请求,将会出现系统宕机。如果能够将请求转发到消息队列,再由服务器去消费这些消息将会使得请求变得平稳,提高系统的可用性。
安装
安装RabbitMQ

基础环境:
内核
3.10.0-327.el7.x86_64
系统版本
CentOS Linux release 7.2.1511 (Core)
安装配置epel源
# rpm -ivh http://mirrors.neusoft.edu.cn/epel/7/x86_64/e/epel-release-7-7.noarch.rpm
安装erlang
# yum install erlang
下载RabbitMQ 3.6.1
# wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.1/rabbitmq-server-3.6.1-1.noarch.rpm
安装rabbitmq-server
# rpm -ivh rabbitmq-server-3.6.1-1.noarch.rpm
生成配置文件
# cp /usr/share/doc/rabbitmq-server-3.6.1/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
启动RabbitMQ
# rabbitmq-server start
安装Python API
# pip3 install pika
or
# easy_install pika
Python 操作RabbitMQ
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
1.生产者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
import pika
# ######################### 生产者 #########################
credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
#创建频道
channel = connection.channel()
# 声明消息队列,消息将在这个队列中进行传递。如果将消息发送到不存在的队列,rabbitmq将会自动清除这些消息。如果队列不存在,则创建
channel.queue_declare(queue='hello')
#exchange -- 它使我们能够确切地指定消息应该到哪个队列去。
#向队列插入数值 routing_key是队列名 body是要插入的内容 channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print("开始队列")
#缓冲区已经flush而且消息已经确认发送到了RabbitMQ中,关闭链接
connection.close()
2.消费者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping import pika # ########################## 消费者 ##########################
credentials = pika.PlainCredentials('admin', 'admin')
# 连接到rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel() # 声明消息队列,消息将在这个队列中进行传递。如果队列不存在,则创建
channel.queue_declare(queue='wzg') # 定义一个回调函数来处理,这边的回调函数就是将信息打印出来。
def callback(ch, method, properties, body):
print(" [x] Received %r" % body) # 告诉rabbitmq使用callback来接收信息
channel.basic_consume(callback,
queue='hello',
no_ack=True)
# no_ack=True表示在回调函数中不需要发送确认标识 print(' [*] Waiting for messages. To exit press CTRL+C') # 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理。按ctrl+c退出。
channel.start_consuming()
RabbitMQ持久化
1、acknowledgment 消息不丢失的方法
生效方法:channel.basic_consume(consumer_callback, queue, no_ack=False, exclusive=False, consumer_tag=None, arguments=None)
即no_ack=False(默认为False,即必须有确认标识),在回调函数consumer_callback中,未收到确认标识,那么,RabbitMQ会重新将该任务添加到队列中。
生产者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
import pika
# ######################### 生产者 #########################
credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
#创建频道
channel = connection.channel()
# 声明消息队列,消息将在这个队列中进行传递。如果将消息发送到不存在的队列,rabbitmq将会自动清除这些消息。如果队列不存在,则创建
channel.queue_declare(queue='hello')
#exchange -- 它使我们能够确切地指定消息应该到哪个队列去。
#向队列插入数值 routing_key是队列名 body是要插入的内容 channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print("开始队列")
#缓冲区已经flush而且消息已经确认发送到了RabbitMQ中,关闭链接
connection.close()
消费者代码:
import pika
credentials = pika.PlainCredentials('admin', 'admin')
# 链接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
# 创建频道
channel = connection.channel()
# 如果生产者没有运行创建队列,那么消费者创建队列
channel.queue_declare(queue='hello') def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
'ok'
ch.basic_ack(delivery_tag=method.delivery_tag) # 主要使用此代码 channel.basic_consume(callback,
queue='hello',
no_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
2、消息持久化存储(Message durability)
虽然有了消息反馈机制,但是如果rabbitmq自身挂掉的话,那么任务还是会丢失。所以需要将任务持久化存储起来。声明持久化存储
channel.queue_declare(queue='wzg', durable=True) # 声明队列持久化
Ps: 但是这样程序会执行错误,因为‘wzg’这个队列已经存在,并且是非持久化的,rabbitmq不允许使用不同的参数来重新定义存在的队列。因此需要重新定义一个队列
channel.queue_declare(queue='test_queue', durable=True) # 声明队列持久化
注意:如果仅仅是设置了队列的持久化,仅队列本身可以在rabbit-server宕机后保留,队列中的信息依然会丢失,如果想让队列中的信息或者任务保留,还需要做以下设置:
channel.basic_publish(exchange='',
routing_key="test_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # 使消息或任务也持久化存储
))
消息队列持久化包括3个部分:
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode=> 2(1是非持久化) 如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。
发布与订阅
RabbitMQ的发布与订阅,借助于交换机(Exchange)来实现。
交换机的工作原理:消息发送端先将消息发送给交换机,交换机再将消息发送到绑定的消息队列,而后每个接收端(consumer)都能从各自的消息队列里接收到信息。
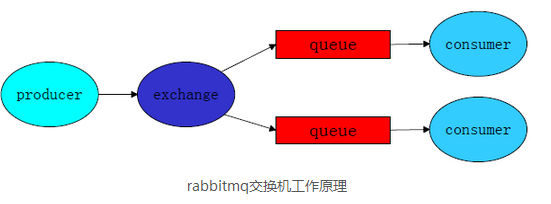
Exchange有三种工作模式,分别为:Fanout, Direct, Topic
模式1 Fanout
任何发送到Fanout Exchange的消息都会被转发到与该Exchange绑定(Binding)的所有Queue上
1.可以理解为路由表的模式
2.这种模式不需要routing_key(即使指定,也是无效的)
3.这种模式需要提前将Exchange与Queue进行绑定,一个Exchange可以绑定多个Queue,一个Queue可以同多个Exchange进行绑定。
4.如果接受到消息的Exchange没有与任何Queue绑定,则消息会被抛弃。
注意:这个时候必须先启动消费者,即订阅者。因为随机队列是在consumer启动的时候随机生成的,并且进行绑定的。producer仅仅是发送至exchange,并不直接与随机队列进行通信。
生产者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
# rabbitmq 发布者
import pika credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel()
# 定义交换机,exchange表示交换机名称,type表示类型
channel.exchange_declare(exchange='logs_fanout',
type='fanout') message = 'Hello Python'
# 将消息发送到交换机
channel.basic_publish(exchange='logs_fanout', # 指定exchange
routing_key='', # fanout下不需要配置,配置了也不会生效
body=message)
print(" [x] Sent %r" % message)
connection.close()
消费者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping # rabbitmq 订阅者
import pika credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel() # 定义交换机,进行exchange声明,exchange表示交换机名称,type表示类型
channel.exchange_declare(exchange='logs_fanout',
type='fanout') # 随机创建队列
result = channel.queue_declare(exclusive=True) # exclusive=True表示建立临时队列,当consumer关闭后,该队列就会被删除
queue_name = result.method.queue
# 将队列与exchange进行绑定
channel.queue_bind(exchange='logs_fanout',
queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r" % body) # 从队列获取信息
channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
模式2 Direct
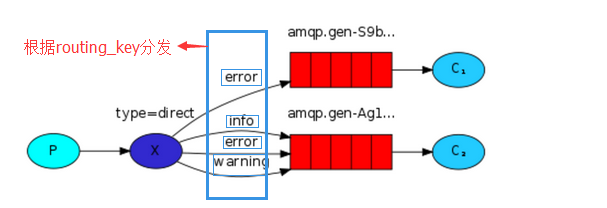
路由键的工作原理:每个接收端的消息队列在绑定交换机的时候,可以设定相应的路由键。发送端通过交换机发送信息时,可以指明路由键 ,交换机会根据路由键把消息发送到相应的消息队列,这样接收端就能接收到消息了。
任何发送到Direct Exchange的消息都会被转发到routing_key中指定的Queue:
1.一般情况可以使用rabbitMQ自带的Exchange:”” (该Exchange的名字为空字符串), 也可以自定义Exchange
2.这种模式下不需要将Exchange进行任何绑定(bind)操作。当然也可以进行绑定。可以将不同的routing_key与不同的queue进行绑定,不同的queue与不同exchange进行绑定
3.消息传递时需要一个“routing_key”
4.如果消息中中不存在routing_key中绑定的队列名,则该消息会被抛弃。
如果一个exchange 声明为direct,并且bind中指定了routing_key,那么发送消息时需要同时指明该exchange和routing_key.
消费者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
# 消费者
import pika credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel()
# 定义exchange和类型
channel.exchange_declare(exchange='direct_test',
type='direct') # 生成随机队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = ['error', ]
# 将随机队列与routing_key关键字以及exchange进行绑定
for severity in severities:
channel.queue_bind(exchange='direct_test',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) # 接收消息
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
生产者
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
# 发布者
import pika credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel()
# 定义交换机名称及类型
channel.exchange_declare(exchange='direct_test',
type='direct') severity = 'info'
message = '123'
# 发布消息至交换机direct_test,且发布的消息携带的关键字routing_key是info
channel.basic_publish(exchange='direct_test',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
当接收端正在运行时,可以使用rabbitmqctl list_bindings来查看绑定情况。
模式3 Topic
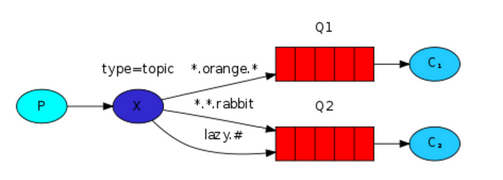
路由键模糊匹配,其实是路由键(routing_key)的扩展,就是可以使用正则表达式,和常用的正则表示式不同,这里的话“#”表示所有、全部的意思;“*”只匹配到一个词。
任何发送到Topic Exchange的消息都会被转发到所有关心routing_key中指定话题的Queue上
1.这种模式较为复杂,简单来说,就是每个队列都有其关心的主题,所有的消息都带有一个“标题”(routing_key),Exchange会将消息转发到所有关注主题能与 routing_key模糊匹配的队列。
2.这种模式需要routing_key,也许要提前绑定Exchange与Queue。
3.在进行绑定时,要提供一个该队列关心的主题,如“#.log.#”表示该队列关心所有涉及log的消息(一个routing_key为”MQ.log.error”的消息会被转发到该队列)。
4.“#”表示0个或若干个关键字,“*”表示一个关键字。如“log.*”能与“log.warn”匹配,无法与“log.warn.timeout”匹配;但是“log.#”能与上述两者匹配。
5.同样,如果Exchange没有发现能够与routing_key匹配的Queue,则会抛弃此消息。
具体代码这里不在多余写,参照第二种模式的就可以,唯一变动的地方就是exchange type的声明,以及进行绑定和发送的时候routing_key使用正则模式即可。
至此,利用Python操作RabbitMQ,以及一些简单用法,在这里介绍完毕。
参考http://www.cnblogs.com/jishuweiwang
python - 操作RabbitMQ的更多相关文章
- Python操作RabbitMQ
RabbitMQ介绍 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从“生产者”接收消息并传递消 ...
- Python之路【第九篇】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用 ...
- 文成小盆友python-num12 Redis发布与订阅补充,python操作rabbitMQ
本篇主要内容: redis发布与订阅补充 python操作rabbitMQ 一,redis 发布与订阅补充 如下一个简单的监控模型,通过这个模式所有的收听者都能收听到一份数据. 用代码来实现一个red ...
- Python之路第十二天,高级(4)-Python操作rabbitMQ
rabbitMQ RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列(M ...
- python操作RabbitMQ(不错)
一.rabbitmq RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列 ...
- Python菜鸟之路:Python基础-Python操作RabbitMQ
RabbitMQ简介 rabbitmq中文翻译的话,主要还是mq字母上:Message Queue,即消息队列的意思.rabbitmq服务类似于mysql.apache服务,只是提供的功能不一样.ra ...
- Python操作 RabbitMQ、Redis、Memcache
Python操作 RabbitMQ.Redis.Memcache Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数 ...
- Python 【第六章】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
- Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
随机推荐
- 我的前端之旅--SeaJs基础和spm编译工具运用[图文]
标签:seajs nodejs npm spm js 1. 概述 本文章来源于本人在项目的实际应用中写下的记录.因初期在安装和使用Seajs和SPM的时候,有点不知所措的经历.为此,我 ...
- UIWebView 自定义网页中的alert和confirm提示框风格
.h #import <UIKit/UIKit.h> @interface UIWebView (JavaScriptAlert) -(void)webView:(UIWebView *) ...
- nodejs广播
http://site.douban.com/185124/widget/notes/10805558/note/240909343/ http://t42dw.iteye.com/blog/1767 ...
- 【UVA10603】Fill (构图+最短路)
题目: Sample Input22 3 4 296 97 199 62Sample Output2 29859 62 题意: 有三个杯子它们的容量分别是a,b,c, 并且初始状态下第一个和第二个是空 ...
- AVOIR发票的三种作用
1. 开错了发票,应收多写了,应该抵消掉一部分应收2. 客户临时有变化,比如只买一部分产品,取消了另一部分,那么也是开AVOIR抵消了一部分应收3. 退钱给客户的时候,也要开一张AVOIR发票 注意, ...
- 集成activiti-modeler 到 自己的业务系统
本文目的: 将activit 5.12.1 的 modeler 流程设计器 集成到自己的工程中去 解决问题: 1. 复制相关资源文件到自己的工程中 2. 解决modeler的路径访问问题,迁移到非系统 ...
- quartz源码解析--转
quartz源码解析(一) . http://ssuupv.blog.163.com/blog//146156722013829111028966/ 任何个人.任何企业.任何行业都会有作业调度的需求 ...
- MySQL的备份与恢复
Linux下的mysql的备份与恢复 备份: 比如我们要备份mysql中已经存在的名为linux的数据库,要用到命令mysqldump 命令格式如下: [root@linuxsir01 root]# ...
- 【转】MFC中调试过程中查看输出信息 -- 不错
原文网址:http://blog.sina.com.cn/s/blog_4e24d9c501014o39.html 笔记&&方便查阅. ~~~~~~~~~~~~~~~~~~~~~~~~ ...
- iOS动态管理AutoLayout的约束NSLayoutConstraint
除了使用Storyboard之外,也可以使用使用代码的方式,动态的向指定的UIView,添加约束. 例如有两个UILabel:someLabel,otherLabel 首先用代码实例化,两个控件 se ...