Power Network (最大流增广路算法模板题)
| Time Limit: 2000MS | Memory Limit: 32768K | |
| Total Submissions: 20754 | Accepted: 10872 |
Description
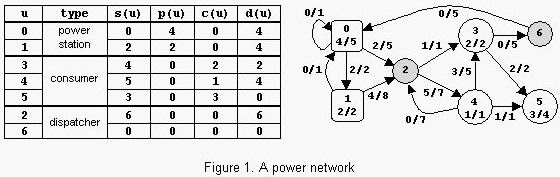
An example is in figure 1. The label x/y of power station u shows that p(u)=x and pmax(u)=y. The label x/y of consumer u shows that c(u)=x and cmax(u)=y. The label x/y of power transport line (u,v) shows that l(u,v)=x and lmax(u,v)=y. The power consumed is Con=6. Notice that there are other possible states of the network but the value of Con cannot exceed 6.
Input
Output
Sample Input
2 1 1 2 (0,1)20 (1,0)10 (0)15 (1)20
7 2 3 13 (0,0)1 (0,1)2 (0,2)5 (1,0)1 (1,2)8 (2,3)1 (2,4)7
(3,5)2 (3,6)5 (4,2)7 (4,3)5 (4,5)1 (6,0)5
(0)5 (1)2 (3)2 (4)1 (5)4
Sample Output
15
6
Hint
#include<stdio.h>
#include<string.h>
#include<queue>
using namespace std; const int MAX = ;
const int INF = 0x3f3f3f3f;
int n,np,nc,m,mf,s,t;
int cap[MAX][MAX],flow[MAX][MAX],a[MAX];
int pre[MAX];
char str[];
queue <int> que;
void maxflow()
{
memset(flow,,sizeof(flow));//初始化,所有的边的流量初始为0;
mf = ;//记录最大流
for(;;)
{
memset(a,,sizeof(a));//s到每个节点路径上的最小残量
a[s] = INF;
que.push(s);
//bfs找增广路
while(!que.empty())
{
int u = que.front();
que.pop();
for(int v = ; v <= n+; v++)
{
if(!a[v] && cap[u][v] > flow[u][v])//找到新的节点v
{
pre[v] = u;//记录前驱并加入队列
que.push(v);
if(a[u] < cap[u][v]-flow[u][v])
a[v] = a[u];
else a[v] = cap[u][v]-flow[u][v];//s到v路径上的最小残量
}
}
}
if(a[t] == ) break;//找不到最小残量,当前流已经是最大流;
for(int u = t; u!= s;u = pre[u])//从汇点往回走
{
flow[pre[u]][u] += a[t];//更新正向流量
flow[u][pre[u]] -= a[t];//更新反向流量
}
mf += a[t];//更新从s流出的总流量
}
} int main()
{
int u,v,z;
while(~scanf("%d %d %d %d",&n,&np,&nc,&m))
{
memset(cap,,sizeof(cap));
while(m--)
{
scanf("%s",str);
sscanf(str,"(%d,%d)%d",&u,&v,&z);
cap[u][v] = z;
} while(np--)//有多个起点
{
scanf("%s",str);
sscanf(str,"(%d)%d",&v,&z);
cap[n][v] = z;//将多个起点连接到一个新的顶点作为起点;
} while(nc--)//有多个终点
{
scanf("%s",str);
sscanf(str,"(%d)%d",&u,&z);
cap[u][n+] = z;//将多个终点连接到一个新的终点作为终点;
}
s = n;
t = n+;
maxflow();
printf("%d\n",mf);
}
return ;
}
Power Network (最大流增广路算法模板题)的更多相关文章
- hdu 3549 Flow Problem【最大流增广路入门模板题】
题目:http://acm.hdu.edu.cn/showproblem.php?pid=3549 Flow Problem Time Limit: 5000/5000 MS (Java/Others ...
- HDU3549 Flow Problem(网络流增广路算法)
题目链接. 分析: 网络流增广路算法模板题.http://www.cnblogs.com/tanhehe/p/3234248.html AC代码: #include <iostream> ...
- 网络流初步:<最大流>——核心(增广路算法)(模板)
增广路的核心就是引入了反向边,使在进行道路探索选择的时候增加了类似于退路的东西[有一点dp的味道??] 具体操作就是:1.首先使用结构体以及数组链表next[ MAXN ]进行边信息的存储 2.[核心 ...
- hdu 3549 Flow Problem(增广路算法)
题目:http://acm.hdu.edu.cn/showproblem.php?pid=3549 模板题,白书上的代码... #include <iostream> #include & ...
- 最大流增广路(KM算法) HDOJ 2255 奔小康赚大钱
题目传送门 /* KM:裸题第一道,好像就是hungary的升级版,不好理解,写点注释 KM算法用来解决最大权匹配问题: 在一个二分图内,左顶点为X,右顶点为Y,现对于每组左右连接Xi,Yj有权w(i ...
- 最大流增广路(KM算法) HDOJ 1533 Going Home
题目传送门 /* 最小费用流:KM算法是求最大流,只要w = -w就可以了,很经典的方法 */ #include <cstdio> #include <cmath> #incl ...
- 最大流增广路(KM算法) HDOJ 1853 Cyclic Tour
题目传送门 /* KM: 相比HDOJ_1533,多了重边的处理,还有完美匹配的判定方法 */ #include <cstdio> #include <cmath> #incl ...
- 网络最大流增广路模板(EK & Dinic)
EK算法: int fir[maxn]; int u[maxm],v[maxm],cap[maxm],flow[maxm],nex[maxm]; int e_max; int p[maxn],q[ma ...
- 网络流——增广路算法(dinic)模板 [BeiJing2006]狼抓兔子
#include<iostream> #include<cstring> #include<algorithm> #include<cmath> #in ...
随机推荐
- SafeNet推出行业首款白盒password软件保护解决方式
数据保护领域的全球率先企业SafeNet公司日前宣布,推出行业首款採用白盒安全技术的的软件保护方案.SafeNet 圣天诺 软件授权与保护解决方式如今纳入了新的功能,可在"白盒" ...
- OpenGL中glPushMatrix和glPopMatrix的原理
glPushMatrix.glPopMatrix操作事实上就相当于栈里的入栈和出栈. 很多人不明确的可能是入的是什么,出的又是什么. 比如你当前的坐标系原点在你电脑屏幕的左上方.如今你调用glPush ...
- DBMS_RLS包实现数据库表中的行级安全控制
DBMS_RLS 实现一个数据库表为行级安全控制,该套餐包括细粒度的访问控制管理界面,此接口是用来实现VPD(Virtual Private Database),虚拟专用数据库.DBMS_RLS仅仅能 ...
- 洛谷P1993 小 K 的农场(查分约束)
/* 加深一下对查分约束的理解 建图的时候为了保证所有点联通 虚拟一个点 它与所有点相连 权值为0 然后跑SPFA判负环 这题好像要写dfs的SPFA 要不超时 比较懒 改了改重复进队的条件~ */ ...
- jQuery中在当前页面弹出一个新的界面
W.$.dialog({ content:'url:wswgrkbillController.do?snh&id='+b+'&bh='+c+'&ck='+d+'&sl= ...
- @ManyToMany 两个表多对多关联
两个表属于多对多关系 如 Teacher <=> Student 表teacher 主键 id 表student 主键id 中间关联表 teacher_student 两个字段 t_id ...
- Gradle命令详解与导入第三方包
Android Studio + Gradle的组合用起来非常方便,很多第三方开源项目也早都迁移到了Studio,为此今天就来介绍下查看.编译并导入第三方开源项目的方法. Sublime + Term ...
- 哥的第一个Jquery程序
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.aspx.cs& ...
- 使用GitBook编写文档
GitBook 简介 GitBook 是一个通过 Git 和 Markdown 来撰写书籍的工具,最终可以生成 3 种格式: 静态站点:包含了交互功能(例如搜索.书签)的站点 PDF:PDF 格式的文 ...
- 3.题目:求s=a+aa+aaa+aaaa+aa...a的值,其中a是一个数字。例如2+22+222+2222+22222(此时共有5个数相加),几个数相加有键盘控制。
public static void main(String[] args) { Scanner scanner=new Scanner(System.in); ...