node爬虫(简版)
做node爬虫,首先像如何的去做这个爬虫,首先先想下思路,我这里要爬取一个页面的数据,要调取网页的数据,转换成页面格式(html+div)格式,然后提取里面独特的属性值,再把你提取的值,传送给你的页面上,在你前端页面显示,或者让你的前端页面能够去调取这些返回的值。
首先要安装以下的依赖
// 调取
npm install --save request-promise
// 转换成页面格式
npm install --save cheerio
// 打开node使用
npm install --save express
// 安装依赖
npm install --save request
然后在代码中去使用依赖东西,来转换页面格式调取页面值
// 把网址转换成页面格式
let result = await request(URI)
$ = cheerio.load(result)
// 获取表头文本
let name = $('#activity-name').text()
name = name.replace(/\ +/g,"")
name = name.replace(/[\r\n]/g,"");
name = `<h1>${name}</h1>`
// 获取内容文本
let test = $('#js_content').text()
test = test.replace(/[\r\n]/g,"");
test = `<p>${test}</p>`
在页面中获取页面值上面的代码是没有问题的,重点事爬取图片
在普通的浏览器页面上爬取图片的时候,直接获取他的src就可以,但是有些很是特殊的,下面的代码爬取普通的浏览器图片
// 获取图片
let add = $('p img')
let att =[]
for ( let i=0;i<add.length;i++){
let imgPath = add.eq(i).attr("src")
att.push(imgPath)
}
在页面上显示(访问自己定的接口)
app.listen(3000, () => {//启动一个3000端口的server服务
console.log('Listening on port 3000')
})
打开localhost:3000查看效果

样式我这里没有调,只加了两个语义化标签。给上段完整代码吧
const request = require('request-promise')
const cheerio = require('cheerio')
let express = require('express')
let app = express()
const URI = 'https://mp.weixin.qq.com/s/MWvlJHu7ptHQMLBpA0u9oA'
app.get('/', async (req, res) => {
// 把网址转换成页面格式
let result = await request(URI)
$ = cheerio.load(result)
// 获取表头文本
let name = $('#activity-name').text()
name = name.replace(/\ +/g,"")
name = name.replace(/[\r\n]/g,"");
name = `<h1>${name}</h1>`
// 获取内容文本
let test = $('#js_content').text()
test = test.replace(/[\r\n]/g,"");
test = `<p>${test}</p>`
// 获取图片
let add = $('p img')
let att =[]
for ( let i=0;i<add.length;i++){
let imgPath = add.eq(i).attr("data-src")
imgPath = imgPath.split('?')[0]
att.push(imgPath)
}
let img =att.map(el => {
let a = `<img src='${el}'>`
console.log(a)
return a
})
// let data = []
// data.push(name,test,att)
let data = ''
data = name + test + img
res.send(data)
})
app.listen(3000, () => {//启动一个3000端口的server服务
console.log('Listening on port 3000')
})
接下来说下获取图片的特殊情况,那就是获取微信公众号文章图片的时候
当你把微信公众号地址转换成代码的时候,他图片转化出来的是一个方法,导致你把页面加载完了,但是图片没有加载出来。(根本就没有src)
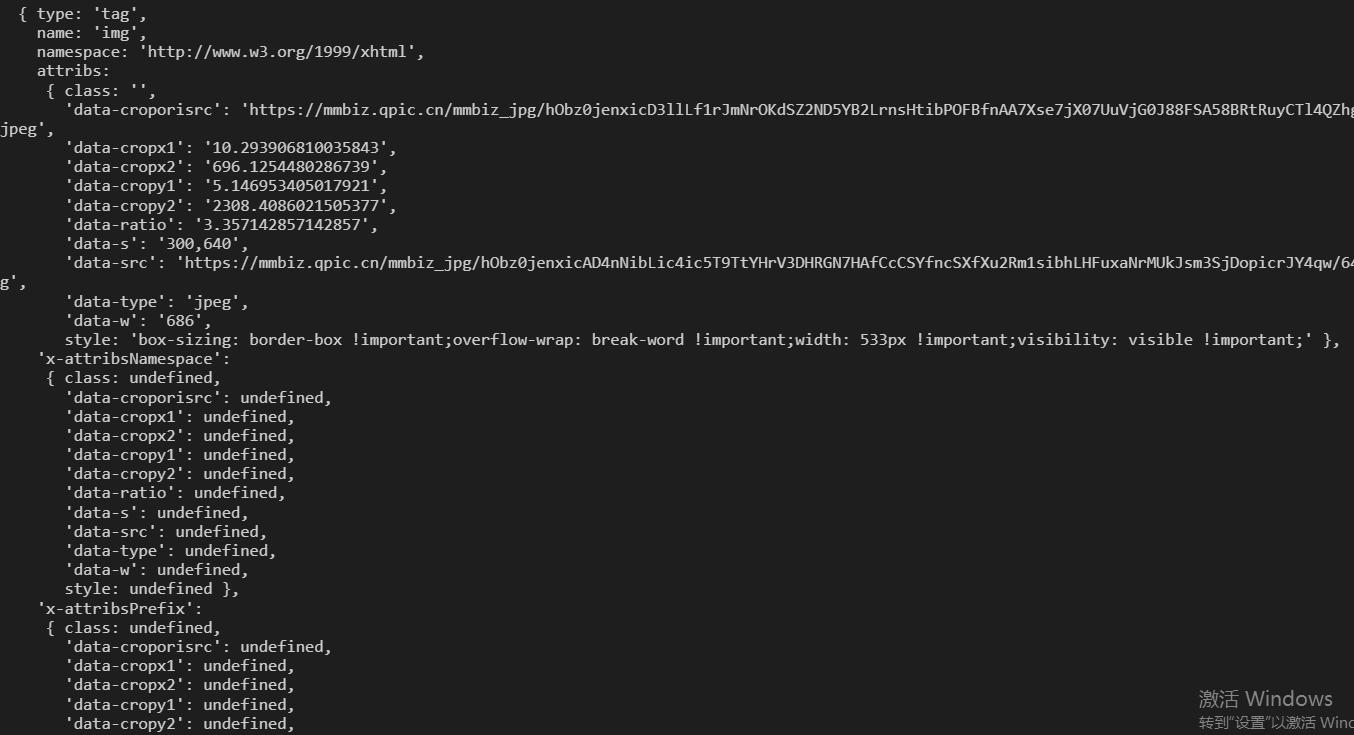
我们应该获取的事这个img的src但是他调取页面转换成代码的时候,这个加载图片的事件没有走完,导致src事underfunded

有谁能解决这个问题吗?帮忙解答一下,困扰我好长时间了!!!!
node爬虫(简版)的更多相关文章
- node爬虫进阶版
手写了一个方便爬虫的小库: const url = require('url') const glib = require('zlib') //默认头部 const _default_headers ...
- typescript 简版跳一跳
typescript 简版跳一跳 学习typescript,第一步应该是学习官方文档,理解最基础的语法.第二步开始用typescript实现一些js+css 或者canvas类型的游行.现在开始我们用 ...
- node爬虫的几种简易实现方式
说到爬虫大家可能会觉得很NB的东西,可以爬小电影,羞羞图,没错就是这样的.在node爬虫方面,我也是个新人,这篇文章主要是给大家分享几种实现node 爬虫的方式.第一种方式,采用node,js中的 s ...
- 继续node爬虫 — 百行代码自制自动AC机器人日解千题攻占HDOJ
前言 不说话,先猛戳 Ranklist 看我排名. 这是用 node 自动刷题大概半天的 "战绩",本文就来为大家简单讲解下如何用 node 做一个 "自动AC机&quo ...
- java语言实现简单接口工具--粗简版
2016注定是变化的一年,忙碌.网红.项目融资失败,现在有点时间整整帖子~~ 目标: 提高工作效率与质量,能支持平台全量接口回归测试与迭代测试也要满足单一接口联调测试. 使用人员: 测试,开发 工具包 ...
- Node爬虫
Node爬虫 参考 http://www.cnblogs.com/edwardstudy/p/4133421.html 所谓的爬虫就是发送请求,并将响应的数据做一些处理 只不过不用浏览器来发送请求 需 ...
- python练习_购物车(简版)
python练习_购物车(简版) 需求: 写一个python购物车可以输入用户初始化金额 可以打印商品,且用户输入编号,即可购买商品 购物时计算用户余额,是否可以购买物品 退出结算时打印购物小票 以下 ...
- 按行切割大文件(linux split 命令简版)
按行切割大文件(linux split 命令简版) #-*- coding:utf-8 -*- __author__ = 'KnowLifeDeath' ''' Linux上Split命令可以方便对大 ...
- Underscore源码阅读极简版入门
看了网上的一些资料,发现大家都写得太复杂,让新手难以入门.于是写了这个极简版的Underscore源码阅读. 源码: https://github.com/hanzichi/underscore-an ...
随机推荐
- Android NFC 整理
Android NFC基础(多篇) http://blog.csdn.net/think_soft/article/details/8169483
- JSP && Servlet | 上传图片到数据库
参考博客: https://blog.csdn.net/qiyuexuelang/article/details/8861300 Servlet+Jsp实现图片或文件的上传功能 https://blo ...
- 自定义UIButton 实现图片和文字 之间距离和不同样式
喜欢交朋友的加:微信号 dwjluck2013 1.UIButton+ImageTitleSpace.h #import <UIKit/UIKit.h> // 定义一个枚举(包含了四种类型 ...
- javascript 中not defined 和undefined有什么区别
概念上的解释:undefined是javascript语言中定义的五个原始类中的一个,换句话说,undefined并不是程序报错,而是程序允许的一个值.not defined是javascript在运 ...
- __contains__, __len__,__reversed__
__contains__():当使用in,not in 对象的时候 调用(not in 是在in完成后再取反,实际上还是in操作) class A(object): def __init__(self ...
- eclipse导入mavn工程报Failure to transfer org.apache.maven.plugins:maven-resources-plugin:pom:2.6 的解决办法
详细报错: Failure to transfer org.apache.maven.plugins:maven-resources-plugin:pom:2.6 from http://10.74. ...
- python入门之实例-购买商品
需求: 选择商品,结算所选的商品 #目前总资产 asset_all = 0 #所选商品总价 all_price = 0 #购物车列表,目前已选择商品 #每个元素的结构:"商品名": ...
- [译]Understanding ECMAScript6 迭代器与生成器(未完)
迭代器在许多编程语言中被作为一种更易处理数据集合的方式被使用.在ECMAScript6中,JavaScript添加了迭代器,将其作为此语言的一个重要特征.当再加上新的方法和新的集合类型(比如集合与映射 ...
- 《深入理解java虚拟机》笔记(1)运行时数据区域
1.Java与C++之间有一堵由内存动态分配和垃圾收集技术所围成的“高墙”,墙外面的人想进去,墙里面的人却想出来. 2.运行时数据区域划分 java虚拟机在执行java程序的过程中会把它所管理的内存划 ...
- TAIL and HEAD
TAIL and HEAD tail tail:将指定的文件的最后部分输出到标准设备,通常是终端,和cat以及more等显示文本的差别在于:假设该档案有更新,tail会自己主动刷新,确保你看到最新的档 ...