第2章 CentOS7集群环境配置
2.1 关闭防火墙
【操作目的】
集群一般都是内网搭建的,如果内网内开启防火墙,内网集群通讯会容易出现很多问题。因此需要关闭集群中每个节点的防火墙。
【操作步骤】
执行以下命令进行关闭防火墙:
systemctl stop firewalld.service
然后执行以下命令,禁止防火墙开机启动:
systemctl disable firewalld.service
其它相关命令如下:
查看防火墙状态:
firewall-cmd --state
开启防火墙:
systemctl start firewalld.service
2.2 设置固定IP
【操作目的】
为了避免后续启动操作系统后,IP地址改变了,导致本地SSH连接不上,节点间无法访问,需要将操作系统设置为固定IP。
【操作步骤】
方法一:
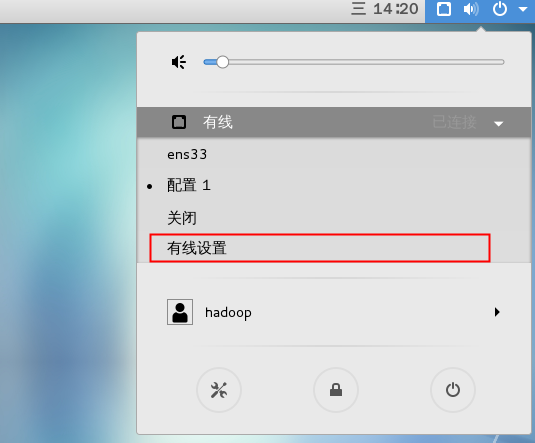
在系统桌面的右上角单击,在弹出的窗口中单击【有线设置】,如下图所示。
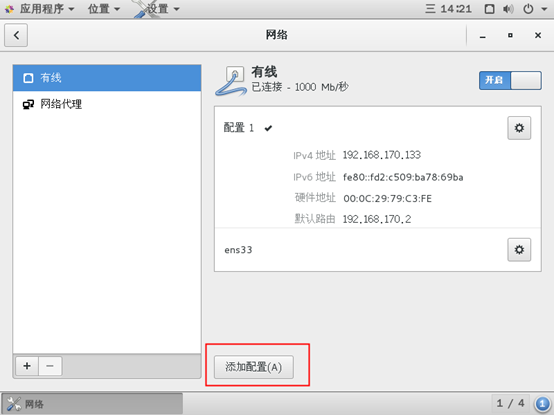
在有线设置窗口中单击【添加配置】按钮,如下图所示。
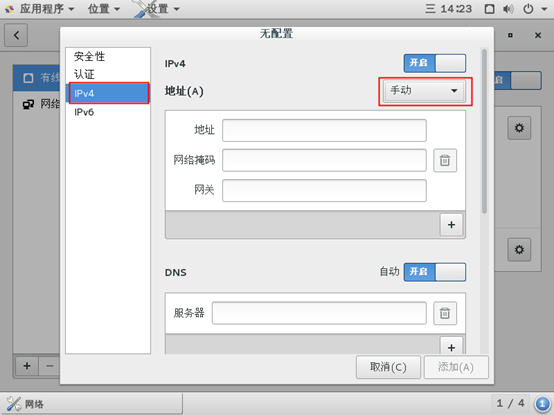
在IP配置窗口中,左侧选择【IPv4】,右侧的【地址】选择【手动】,如下图所示。
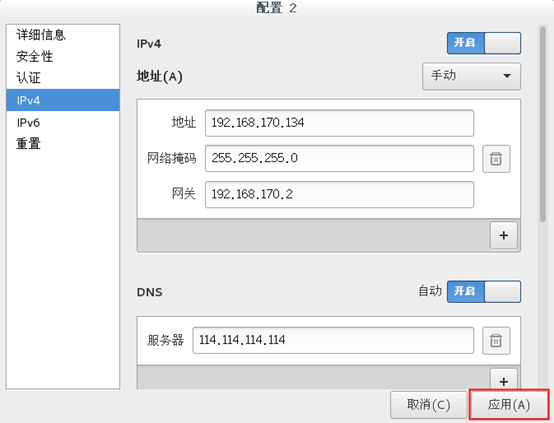
接着输入IP地址、网络掩码、网关和DNS服务器,输入完毕后单击【添加】按钮。如下图所示。
方法二:
执行以下命令,修改文件ifcfg-ens33:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改内容如下(修改标红处,没有的选项需要手动添加):
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.2.75
NETMASK=255.255.255.0
GATEWAY=192.168.2.2
DNS1=192.168.2.2
DNS2=114.114.114.114
需要修改的参数及解析如下::
BOOTPROTO:static表示静态IP,默认是DHCP,表示动态IP。
ONBOOT:yes表示开机启用本配置。
IPADDR:IP地址。
NETMASK:子网掩码。
GATEWAY:默认网关,虚拟机安装的话,通常是2,也就是VMnet8的网关设置。
DNS1:DNS 配置,虚拟机安装的话,与网关一样就行。若需要连接外网,需要配置DNS。
DNS2:网络运营商公众DNS,此处也可不用配置。
修改完成后重启网络服务:
service network restart
查看改动后的IP:
ip addr
2.3 修改主机名
【操作目的】
在分布式集群中,主机名用于区分不同的节点,并方便节点之间相互访问,因此需要修改主机的主机名。
【操作步骤】
(1)使用hadoop用户登录系统,进入系统的终端命令行,输入以下命令,查看主机名:
[hadoop@localhost ~]$ hostname
localhost.localdomain
可以看到,当前主机的默认主机名为localhost.localdomain。
(2)执行以下命令,设置主机名为centos01:
[hadoop@localhost ~]$ hostname centos01
hostname: you must be root to change the host name
此时提示需要root权限,执行su命令切换root用户:
[hadoop@localhost ~]$ su
密码:
[root@localhost hadoop]#
执行以下命令,重新设置主机名为centos01:
[root@localhost hadoop]# hostname centos01
以上设置只是在当前会话起作用,重启以后设置的主机名就不起作用了。要想完全改变主机名,需要修改hostname文件。执行以下命令,修改hostname文件,将其中的主机名改为centos01:
[root@localhost hadoop]# vi /etc/hostname
(3)重启系统使修改生效。
注意:修改主机名需要重启才能生效。
2.4 添加用户
本例中使用安装操作系统时新建的hadoop用户即可,若想使用其他用户,则按照下面的步骤新建用户:
(1)使用root登录系统,新增用户tom:
adduser tom
(2)修改用户tom的密码:
passwd tom
(3)设置用户权限,操作方法见下一小节。
2.5 修改用户权限
【操作目的】
使普通用户可以使用root权限。本例以修改hadoop用户为例进行讲解。
【操作步骤】
使用su命令切换为root用户,然后修改文件sudoers:
[root@centos01 hadoop]# vi /etc/sudoers
在文本root ALL=(ALL) ALL的下方加入以下代码,将hadoop用户加入sudo组,使其可以使用sudo执行命令。
hadoop ALL=(ALL) ALL
默认5分钟后sudo密码过期,下次使用sudo需要重新输入密码,如果觉得在sudo的时候输入密码麻烦,把上方的输入换成如下内容即可:
hadoop ALL=(ALL) NOPASSWD:ALL
此时使用root权限的命令只需要在命令前面加入sudo即可,无需输入密码。
[hadoop@centos01 ~]$ cat /etc/sudoers
cat: /etc/sudoers: 权限不够
[hadoop@centos01 ~]$ sudo cat /etc/sudoers
2.6 新建目录
在/opt下创建目录softwares、modules、data,分别用于存放软件安装包、软件安装数据和其它数据:
[hadoop@centos01 ~]$ sudo mkdir /opt/softwares
[hadoop@centos01 ~]$ sudo mkdir /opt/modules
[hadoop@centos01 ~]$ sudo mkdir /opt/data
修改目录权限为hadoop用户:
[hadoop@centos01 opt]$ sudo chown -R hadoop:hadoop /opt/*
查看目录权限是否修改成功:
[hadoop@centos01 opt]$ ll
总用量 0
drwxr-xr-x. 2 hadoop hadoop 6 3月 8 09:56 data
drwxr-xr-x. 2 hadoop hadoop 6 3月 8 09:55 modules
drwxr-xr-x. 2 hadoop hadoop 6 3月 26 2015 rh
drwxr-xr-x. 2 hadoop hadoop 231 3月 8 09:07 softwares
2.7 安装JDK
【操作目的】
Hadoop集群的运行依赖于Java环境,因此在安装Hadoop之前需要安装好JDK。
【操作步骤】
JDK的安装步骤如下:
1.卸载系统自带的JDK
执行以下命令,查询系统已安装的Java:
[hadoop@localhost ~]$ rpm -qa|grep java
java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
tzdata-java-2016g-2.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
执行以下命令,删除以上查询出的系统自带JDK:
sudo rpm -e --nodeps
java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64 tzdata-java-2016g-2.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
2.安装JDK
上传安装包jdk-8u101-linux-x64.tar.gz到目录/opt/softwares中,然后进入目录/opt/softwares,解压jdk-8u101-linux-x64.tar.gz到目录/opt/modules中,解压命令如下:
[hadoop@centos01 softwares]$ tar -zxf jdk-8u101-linux-x64.tar.gz -C /opt/modules/
修改文件/etc/profile,配置JDK环境变量:
[hadoop@centos01 softwares]$ sudo vi /etc/profile
在文件末尾加入以下内容:
export JAVA_HOME=/opt/modules/jdk1.8.0_101
export PATH=$JAVA_HOME/bin:$PATH
刷新profile文件,使修改生效。
source /etc/profile
执行java -version命令,查看是否能成功输出JDK版本信息,信息如下:
[hadoop@centos01 softwares]$ java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
到此,JDK安装成功。
2.8 克隆虚拟机
【操作目的】
由于集群环境需要多个节点,当我们一个节点配置完毕后,可以通过VMware的克隆功能,将配置好的节点进行完整克隆,而不需要重新新建虚拟机和安装操作系统。
【操作步骤】
克隆之前,需先关闭操作系统。然后在VMware左侧的虚拟机列表中右键单击centos01虚拟机,选择【管理】/【克隆】,会出现【克隆虚拟机向导】窗口,直接单击【下一步】按钮即可。如下图所示。
在【克隆源】新窗口中,选择【虚拟机中的当前状态】选项,然后单击【下一步】按钮。如下图所示。

在【克隆类型】新窗口中,选择【创建完整克隆】选项,然后单击【下一步】按钮。如下图所示。

在新窗口中,【虚拟机名称】一栏填写为“centos02”,并单击【浏览】按钮,修改新虚拟机的存储位置,然后单击【完成】按钮。如下图所示。



克隆完成后,继续克隆虚拟机centos01,将克隆后的虚拟机名称改为centos03。
到此,centos02与centos03两台虚拟机就搭建完成了。
2.9 配置主机IP映射
【操作目的】
通过修改各节点的主机IP映射,可以方便的通过主机名访问集群中的其它主机。
【操作步骤】
(1)依次启动三台虚拟机,将主机centos02的主机名改为centos02,将主机centos03的主机名改为centos03。
(2)使用ifconfig命令查看三台虚拟机的IP,并将centos02与centos03的IP分别改为固定IP。本例三台主机IP分别为:
192.168.170.133
192.168.170.134
192.168.170.135
(3)在各个节点上分别执行以下命令,修改hosts文件:
sudo vi /etc/hosts
在hosts文件中加入以下内容:
192.168.170.133 centos01
192.168.170.134 centos02
192.168.170.135 centos03
注意:每个节点的hosts文件中都要加入同样的内容,这样可以保证每个节点都可以通过主机名访问到其它节点。
(4)配置完后,使用ping命令检查是否配置成功,如下:
ping centos01
ping centos02
ping centos03
(5)最后,配置一下本地Windows系统的主机IP映射,方便本地通过主机名直接访问虚拟机。进入Windows操作系统的目录C:\Windows\System32\drivers\etc编辑hosts文件,加入以下内容:
192.168.170.133 centos01
192.168.170.134 centos02
192.168.170.135 centos03
原创文章,转载请注明出处!!
第2章 CentOS7集群环境配置的更多相关文章
- CentOS7集群环境Elastic配置
CentOS7集群环境Elastic配置 (首先去官网下载elasticsearch的source code并解压到/usr/soft目录下) (以下默认root账户) 1.更改配置文件 文件路径:/ ...
- EHCache分布式缓存集群环境配置
EHCache分布式缓存集群环境配置 ehcache提供三种网络连接策略来实现集群,rmi,jgroup还有jms.同时ehcache可以可以实现多播的方式实现集群,也可以手动指定集群主机序列实现集群 ...
- Hive在集群环境配置
本文转载自:https://blog.csdn.net/hanjin7278/article/details/53035739 一.简介 hive是基于Hadoop的一个数据仓库工具,可以将结构化的数 ...
- Kafka集群环境配置
Kafka集群环境配置 1 环境准备 1.1 集群规划 Node02 Node03 Node04 zk zk zk kafka kafka kafka 1.2 jar包下载 安装包:kafka_2.1 ...
- RocketMQ的安装配置:配置jdk环境,配置RocketMQ环境,配置集群环境,配置rocketmq-console
RocketMQ的安装配置 演示虚拟机环境:Centos64-1 (D:\linuxMore\centos6_64) root / itcast : 固定IP 192.168.52.128 一,配置J ...
- HBase 学习之路(四)—— HBase集群环境配置
一.集群规划 这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的 ...
- HBase 系列(四)—— HBase 集群环境配置
一.集群规划 这里搭建一个 3 节点的 HBase 集群,其中三台主机上均为 Regin Server.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoo ...
- SpringBoot系列教程之Redis集群环境配置
之前介绍的几篇redis的博文都是基于单机的redis基础上进行演示说明的,然而在实际的生产环境中,使用redis集群的可能性应该是大于单机版的redis的,那么集群的redis如何操作呢?它的配置和 ...
- redis集群环境配置
为什么需要集群 redis是一个开源的 key->value 高速存储系统,但是由于redis单线程运行,在系统中,只能利用单核的性能 当redis的调用越来越频繁时,可能会出现redis过于繁 ...
随机推荐
- (转)Linux最常用指令及快捷键 Linux学习笔记
Linux最常用指令及快捷键 Linux学习笔记 原文:http://blog.csdn.net/yanghongche/article/details/50827478 [摘自 鸟叔的私房菜]--转 ...
- 示例1-苏宁每日自动登录打卡-结合Au3
public class SuningAutoClock { public static void AutoClock() throws IOException, InterruptedExcepti ...
- 《nginx 一》dns解析 nginx安装
DNS域名解析 整个过程大体描述如下,其中前两个步骤是在本机完成的,后8个步骤涉及到真正的域名解析服务器:1.浏览器会检查缓存中有没有这个域名对应的解析过的IP地址,如果缓存中有,这个解析过程就结束. ...
- java CountDownLatch 等待多线程完成
CountDownLatch允许一个或多个线程等待其他线程完成操作. package com.test; import java.util.concurrent.CountDownLatch; pub ...
- 使用nasm和clang
nasm编译 nasm -f macho64 --prefix _ demo.asm # --prefix是为gobal的标签添加前缀, 链接时根据的都是以_开头的 clang编译 clang tes ...
- SpringBoot | 第九章:Mybatis-plus的集成和使用
前言 本章节开始介绍数据访问方面的相关知识点.对于后端开发者而言,和数据库打交道是每天都在进行的,所以一个好用的ORM框架是很有必要的.目前,绝大部分公司都选择MyBatis框架作为底层数据库持久化框 ...
- Android中渐变图片失真的解决方案
在android开发(尤其是android游戏开发)中有一个很严重的问题就是带有渐变效果的png图片会出现严重的banding(色带),鉴于这种情况,有几种可行的解决方法: 1.如果Activit ...
- 在ActionBar中,即便设置showAsAction="always",items仍然在overflow中显示的问题
今天很是苦恼,明明设置了android:showAsAction="always",但是所有的items全部都显示在overflow中,然后在官网发现了答案. 如果你为了兼容 An ...
- 关于dependencies和devDependencies的理解
npm install 会下载dependencies和devDependencies中的模块,当使用npm install --production或者注明NODE_ENV变量值为productio ...
- JSP开发过程遇到的中文乱码问题及解决方案
对于程序猿来说,乱码问题真的很头疼,下面列举几种常见的乱码. 1.数据库编码不一致导致乱码 解决方法: 首先查看数据库编码,输入: show variables like "%char%&q ...