Spark DAGSheduler生成Stage过程分析实验
RDD.Action触发SparkContext.run,这里举最简单的例子rdd.count()
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
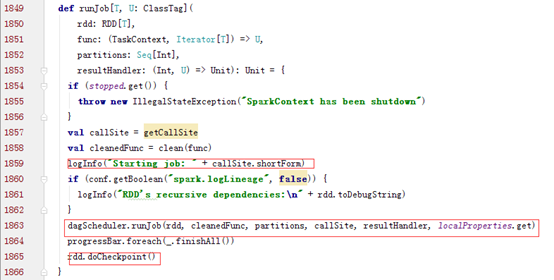
Spark Action会触发SparkContext类的runJob,而runJob会继续调用DAGSchduler类的runJob

DAGSchduler类的runJob方法调用submitJob方法,并根据返回的completionFulture的value判断Job是否完成。
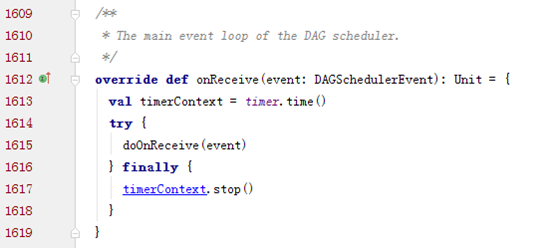
onReceive用于DAGScheduler不断循环的处理事件,其中submitJob()会产生JobSubmitted事件,进而触发handleJobSubmitted方法。

正常情况下会根据finalStage创建一个ActiveJob。而finalStage就是由spark action对应的finalRDD生成的,而该stage要确认所有依赖的stage都执行完,才可以执行。也就是通过getMessingParentStages方法判断的。

这个方法用一个栈来实现递归的切分stage,然后返回一个宽依赖的HashSet,如果是宽依赖类型就会调用
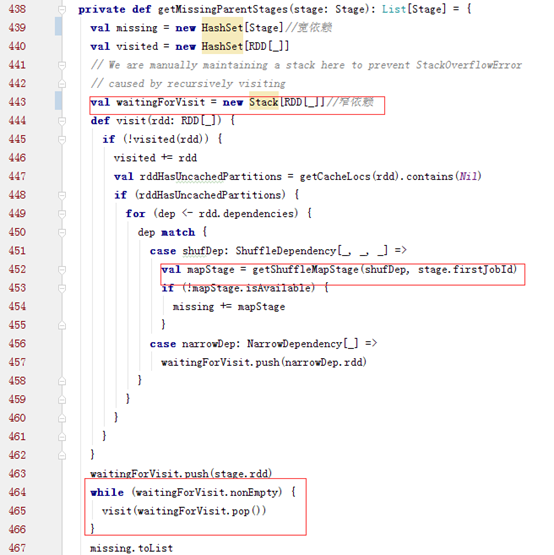
之后提交stage,根据missingStage执行各个stage。划分DAG结束

submitStage会依次执行这个DAG中的stage,如果有父stage就先执行父stage,否则就提交这个stage,加入watingstages中。

示例:
scala> sc.makeRDD(Seq(1,2,3)).count
16/10/28 17:54:59 [INFO] [org.apache.spark.SparkContext:59] - Starting job: count at <console>:13
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Got job 0 (count at <console>:13) with 22 output partitions (allowLocal=false)
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Final stage: Stage 0(count at <console>:13)
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Parents of final stage: List()
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Missing parents: List()
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Submitting Stage 0 (ParallelCollectionRDD[0] at makeRDD at <console>:13), which has no missing parents
scala> sc.makeRDD(Seq(1,2,3)).map(l =>(l,1)).reduceByKey((v1,v2) => v1+v2).collect
16/10/28 18:00:07 [INFO] [org.apache.spark.SparkContext:59] - Starting job: collect at <console>:13
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Registering RDD 2 (map at <console>:13)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Got job 1 (collect at <console>:13) with 22 output partitions (allowLocal=false)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Final stage: Stage 2(collect at <console>:13)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Parents of final stage: List(Stage 1)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Missing parents: List(Stage 1)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Submitting Stage 1 (MappedRDD[2] at map at <console>:13), which has no missing parents
collect依赖于reduceByKey,reduceByKey依赖于map,而reduceByKey是一个Shuffle操作,故会先提交map (Stage 1 (MappedRDD[2] at map at <console>:13))
Spark DAGSheduler生成Stage过程分析实验的更多相关文章
- Spark2.2+ES6.4.2(三十一):Spark下生成测试数据,并在Spark环境下使用BulkProcessor将测试数据入库到ES
Spark下生成2000w测试数据(每条记录150列) 使用spark生成大量数据过程中遇到问题,如果sc.parallelize(fukeData, 64);的记录数特别大比如500w,1000w时 ...
- Spark 资源调度包 stage 类解析
spark 资源调度包 Stage(阶段) 类解析 Stage 概念 Spark 任务会根据 RDD 之间的依赖关系, 形成一个DAG有向无环图, DAG会被提交给DAGScheduler, DAGS ...
- spark job, stage ,task介绍。
1. spark 如何执行程序? 首先看下spark 的部署图: 节点类型有: 1. master 节点: 常驻master进程,负责管理全部worker节点. 2. worker 节点: 常驻wor ...
- Spark Streaming应用启动过程分析
本文为SparkStreaming源码剖析的第三篇,主要分析SparkStreaming启动过程. 在调用StreamingContext.start方法后,进入JobScheduler.start方 ...
- spark 中划分stage的思路
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为 一个父RDD的分区对应于一个子RDD的分区 两个父RDD的分区对应于一个子RDD 的分区. 宽依赖指子RDD的每个分区都要依赖于父RD ...
- spark中job stage task关系
1.1 例子,美国 1880 - 2014 年新生婴儿数据统计 目标:用美国 1880 - 2014 年新生婴儿的数据来做做简单的统计 数据源:https://catalog.data.gov 数据格 ...
- Spark Streaming和Flume-NG对接实验
Spark Streaming是一个新的实时计算的利器,而且还在快速的发展.它将输入流切分成一个个的DStream转换为RDD,从而可以使用Spark来处理.它直接支持多种数据源:Kafka, Flu ...
- Spark(四十八):Spark MetricsSystem信息收集过程分析
MetricsSystem信息收集过程 参考: <Apache Spark源码走读之21 -- WEB UI和Metrics初始化及数据更新过程分析> <Spark Metrics配 ...
- spark 笔记 8: Stage
Stage 是一组独立的任务,他们在一个job中执行相同的功能(function),功能的划分是以shuffle为边界的.DAG调度器以拓扑顺序执行同一个Stage中的task. /** * A st ...
随机推荐
- js的一些正则 整理 长期更新
1. 1-12的正整数:var day=/^[1-9]\d{0,12}$/;
- PHP unset()函数销毁变量 但没有实现释放内存
<?PHP $a = "hello";$b = &$a;unset( $b );echo $a; // 输出 helloecho $b; // 报错$b = &quo ...
- Asp.net中static变量和viewstate的使用方法(谨慎)
在.Net平台下进行CS软件开发时,我们经常遇到以后还要用到某些变量上次修改后的值,为了简单起见,很多人都习惯用static来定义这些变量,我也是.这样非常方便,下一次调用某个函数时该变量仍然保存的是 ...
- CS0103: The name ‘Scripts’ does not exist in the current context解决方法
转至:http://blchen.com/cs0103-the-name-scripts-does-not-exist-in-the-current-context-solution/ 更新:这个bu ...
- MySQL多表查询
第一种: select a.a1,a.a2,a.a3,b.b2,c.c2,d.d2 from a,b,c,d where a.a1=b.b1 and b.b1=c.c1 and c.c1=d.d1 第 ...
- 谈谈rem
用rem已久但是对于它的理解似乎一直都有偏差,使用的时候多采用的是html的font-size:62.5%;然后按照1rem=10px这样来使用.所以我一直不明白,这个rem到底哪里是相对单位了,也不 ...
- sass sourcemap详细使用
新发布的Sass 3.3版本,将Source Maps正式纳入了Sass中.这也成为Sass新版本的一大亮点,一大新功能.让广大Sass爱好者可以直接在浏览器中更容易调试自己的代码和Debug相关操作 ...
- TreeSet
一.TreeSet中的元素比较有两种方式 1.定义一个类,实现Comparable接口 复写的是comparato方法 2.定义一个类,实现Comparator接口,覆盖compara方法(此种方法 ...
- HDU2842 矩阵乘法
Chinese Rings Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tot ...
- 递归一题总结(OJ P1117倒牛奶)
题目: 农民约翰有三个容量分别是A,B,C升的桶,A,B,C分别是三个从1到20的整数,最初,A和B桶都是空的,而C桶是装满牛奶的.有时,约翰把牛奶从一个桶倒到另 ...