Java爬虫系列二:使用HttpClient抓取页面HTML
爬虫要想爬取需要的信息,首先第一步就要抓取到页面html内容,然后对html进行分析,获取想要的内容。上一篇随笔《Java爬虫系列一:写在开始前》中提到了HttpClient可以抓取页面内容。
今天就来介绍下抓取html内容的工具:HttpClient。
围绕下面几个点展开:
什么是HttpClient
HttpClient入门实例
- 复杂应用
结束语
一、什么是HttpClient
度娘说:
HttpClient 是Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
以下列出的是 HttpClient 提供的主要的功能,要知道更多详细的功能可以参见 HttpClient 的官网:
(1)实现了所有 HTTP 的方法(GET,POST,PUT,HEAD 等)
(2)支持自动转向
(3)支持 HTTPS 协议
(4)支持代理服务器等
这里面提到了官网,那就顺便说下它官网上的一些东西。
根据百度给出的HomePage是这个:http://hc.apache.org/httpclient-3.x/,但是进入后你会发现有句话
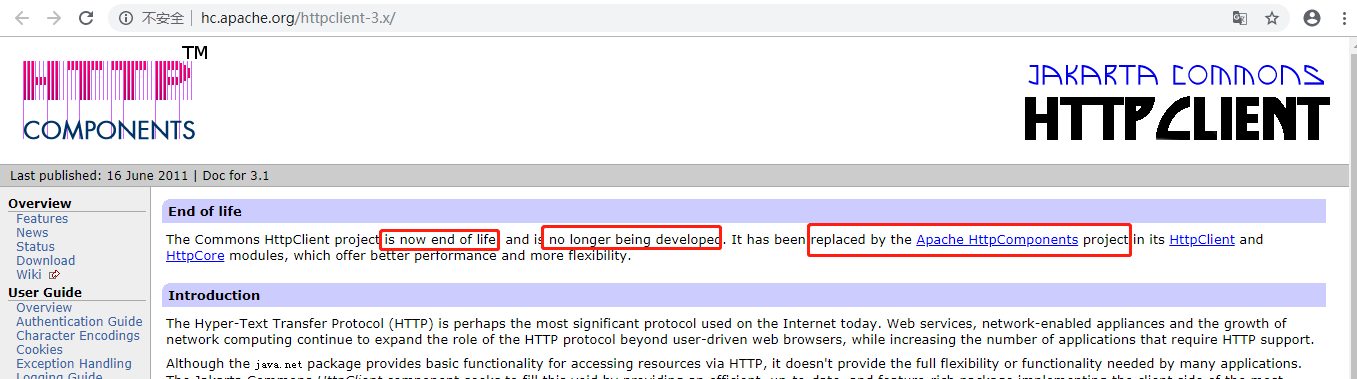
大意是:Commons HttpClient这个项目已经不再维护了,它已经被Apache HttpComponents替代了。也就是说我们以后要用的话就用新的。点这个Apache HttpComponents的链接进去能看到它最新的版本是4.5,而且有快速上手的例子和专业的说明文档。有兴趣并且英文好的朋友可以好好研究下哦 ~~
额~~那个~~我的英文不好,就不按照官网的来了,直接给出我自己在网上学的练习案例~~
二、HttpClient入门实例
- 新建一个普通的maven项目:名字随便起,我的叫:httpclient_learn
- 修改pom文件,引入依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.8</version>
</dependency> - 新建java类
package httpclient_learn; import java.io.IOException; import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils; public class HttpClientTest { public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request); //4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
} - 执行代码,我们会发现打印出来的其实就是首页完整的html代码
<!DOCTYPE html>
<html lang="zh-cn">
<head>
//Java开发老菜鸟备注:由于内容太多,具体不再贴出来了
</head>
<body>//Java开发老菜鸟备注:由于内容太多,具体内容不再贴出来了
</body> </html>
操作成功!
好了,到这里就完成了一个简单的小例子。
爬一个网站不过瘾,再来一打。接下来我们换个网站:https://www.tuicool.com/,你会发现结果是这样的:
返回状态不是200
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<body>
<p>系统检测亲不是真人行为,因系统资源限制,我们只能拒绝你的请求。如果你有疑问,可以通过微博 http://weibo.com/tuicool2012/ 联系我们。</p>
</body>
</html>
爬虫程序被识别了,怎么办呢? 别着急,慢慢往下看
三、复杂应用
第二个网站访问不了,是因为网站有反爬虫的处理,怎么绕过他呢?
1.最简单的是对请求头进行伪装,看代码,加上红框里面的内容后再执行
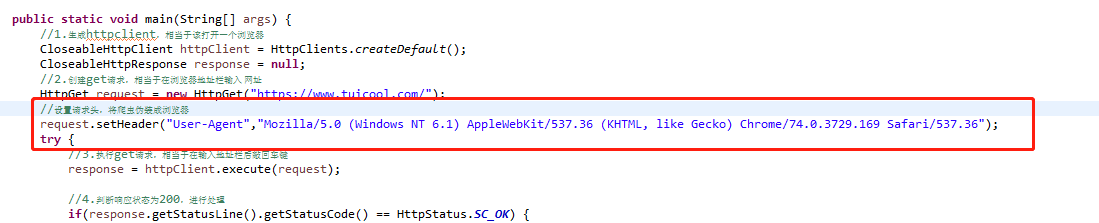
你会发现返回结果变了,有真内容了(红字警告先不管它,我们起码获取到了html内容)
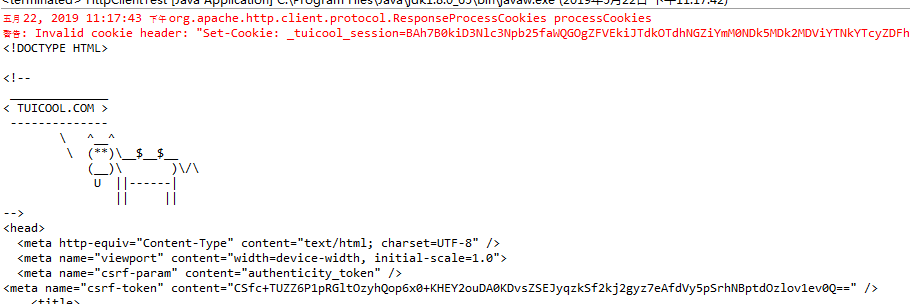
那代码中新加的那段内容是哪里来的呢?
请打开谷歌浏览器的F12,对就是这里了:

当然我们还可以设置请求的其他头信息,如cookie等
2.上面说的是伪装成浏览器,其实如果你伪装了之后,如果短时间内一直多次访问的话,网站会对你的ip进行封杀,这个时候就需要换个ip地址了,使用代理IP
网上有一些免费的代理ip网站,比如xici

我们选择那些存活时间久并且刚刚被验证的ip,我这里选择了“112.85.168.223:9999”,代码如下
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.tuicool.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
HttpHost proxy = new HttpHost("112.85.168.223", 9999);
RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
request.setConfig(config);
执行代码,能正常返回html结果。如果代理ip刚好不能用的话,会报错,如下显示连接超时,这个时候需要更换一个新的代理ip
3.另外,程序被识别出来很大原因是短时间内做了太多访问,这个是正常人不会有的频率,因此我们也可以放慢爬取的速度,让程序sleep一段时间再爬下一个也是一种反 反爬虫的简单方法。
四、结束语
这篇简单介绍了下httpclient和它的官网,并用代码说明了如何使用它,也提到了如果遇到反爬虫的话我们还可以用一些简单的反反爬虫方法进行应对。
对于其他复杂的反反爬虫的方法我还没有研究过,就是用这几种结合使用。 比如在爬取了一段时间后,网站需要输入验证码来验证是人在操作,我没有去管如何突破验证码的事儿,而是获取代理ip池然后在遇到验证码的时候逐个换新的ip,这样就可以躲过了验证码。如果有其他方法,欢迎留言哦
Java爬虫系列二:使用HttpClient抓取页面HTML的更多相关文章
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- Java爬虫系列四:使用selenium-java爬取js异步请求的数据
在之前的系列文章中介绍了如何使用httpclient抓取页面html以及如何用jsoup分析html源文件内容得到我们想要的数据,但是有时候通过这两种方式不能正常抓取到我们想要的数据,比如看如下例子. ...
- Java爬虫系列三:使用Jsoup解析HTML
在上一篇随笔<Java爬虫系列二:使用HttpClient抓取页面HTML>中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取 ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- 爬虫系列(二) Chrome抓包分析
在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析,更加深入的了解网络爬虫的本质与内涵 1.测试环境 浏览器:Chrome 浏览器 浏览器版本:67.0.33 ...
- HttpClient(一)HttpClient抓取网页基本信息
一.HttpClient简介 HttpClient 是 Apache Jakarta Common 下的子项目,可以用来提供高效的.最新的.功能丰富的支持 HTTP 协议的客户端编程工具包, 并且它支 ...
- Java爬虫系列一:写在开始前
最近在研究Java爬虫,小有收获,打算一边学一边跟大家分享下,在干货开始前想先跟大家啰嗦几句. 一.首先说下为什么要研究Java爬虫 Python已经火了很久了,它功能强大,其中很擅长的一个就是写爬虫 ...
- java爬虫系列第一讲-爬虫入门
1. 概述 java爬虫系列包含哪些内容? java爬虫框架webmgic入门 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页.电影下载地址等信息) 使用web ...
- 爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图: 1.网页分析 (1)初步分析 原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程 ...
随机推荐
- 19.Yii2.0框架模型删除记录
目录 //删除记录 //http://yii.com/?r=home/del public function actionDel() { //查出要删除的记录行 // 方法一:(查一行,删一行) // ...
- leetcode-13-basic-binaryTree
101. Symmetric Tree 解题思路: 递归的方法如下.分几种情况考虑,如果左子树和右子树都是空,那么返回true:如果不同时为空,返回false:如果都不为空,则 判断其值是否相等,不相 ...
- 关于sizeof,对空指针sizeof(*p)可以吗?
C/C++的sizeof在动态分配内存时经常用到,但之前一直没怎么关注它的具体机制.今天在为一个复杂声明的指针分配内存时,想起来要了解一下sizeof到底是什么? 先抛个问题: 程序运行过程中对空指针 ...
- 由浅入深学习PBR的原理和实现
目录 一. 前言 1.1 本文动机 1.2 PBR知识体系 1.3 本文内容及特点 二. 初阶:PBR基本认知和应用 2.1 PBR的基本介绍 2.1.1 PBR概念 2.1.2 与物理渲染的差别 2 ...
- navicat for mysql 在win7下设置定时计划之导出数据处理
navicat for mysql 在win7下设置定时计划之导出数据处理 博客分类: mysql navitcatmysql定时任务导出 前两篇记录了,navicat for mysql计划的入门 ...
- verilog写的LCD1602 显示
在读本文之前,请先阅读 LCD1602 的 datasheet(百度到处都是) ,熟悉有关的11条指令集. LCD1602的11个指令集链接 http://www.cnblogs.com/aslmer ...
- 装箱I(01背包)
描述 给两个有一定容量的箱子,往里面装宝石(宝石总容量不能超过箱子容量),不同的宝石有不同的容量和价值.求两个箱子里最大宝石的价值. 输入 line 1: Input n; n:表示宝石数量 ...
- 突然想看单纯形 BZOJ3265 志愿者招募加强版
本来的版本是可以差分之后建图利用网络流,这个题是板子题,就当存个板子,嘻嘻嘻 讲解可以到卿学姐的算法讲堂 https://www.bilibili.com/video/av7847726?from=s ...
- 【mysql优化 2】索引条件下推优化
原文地址:Index Condition Pushdown Optimization 索引条件下推(ICP:index condition pushdown)是mysql中一个常用的优化,尤其是当my ...
- 九度oj 题目1184:二叉树遍历
题目描述: 编一个程序,读入用户输入的一串先序遍历字符串,根据此字符串建立一个二叉树(以指针方式存储). 例如如下的先序遍历字符串:ABC##DE#G##F###其中“#”表示的是空格,空格字符代表空 ...