Java做爬虫也很方便
首先我们封装一个Http请求的工具类,用HttpURLConnection实现,也可以用HttpClient, 或者直接用Jsoup来请求。
工具类实现比较简单,就一个get方法,读取请求地址的响应内容,这边我们用来抓取网页的内容,没有使用代理,在真正的抓取过程中,当你大量请求某个网站的时候,对方会有一系列的策略来禁用你的请求,这个时候代理就排上用场了,通过代理设置不同的IP来抓取数据。
- public class HttpUtils {
- public static String get(String url) {
- try {
- URL getUrl = new URL(url);
- HttpURLConnection connection = (HttpURLConnection) getUrl.openConnection();
- connection.setRequestMethod("GET");
- connection.setRequestProperty("Accept", "*/*");
- connection.setRequestProperty(
- "User-Agent",
- "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA)");
- connection.setRequestProperty("Accept-Language", "zh-cn");
- connection.connect();
- BufferedReader reader = new BufferedReader(
- new InputStreamReader(connection.getInputStream(), "utf-8"));
- String line;
- StringBuffer result = new StringBuffer();
- while ((line = reader.readLine()) != null){
- result.append(line);
- }
- reader.close();
- return result.toString();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return null;
- }
- }
接下来我们随便找一个有图片的网页,来试试抓取功能
- public static List<String> getImageSrc(String html) {
- // 获取img标签正则
- String IMGURL_REG = "<img.*src=(.*?)[^>]*?>";
- // 获取src路径的正则
- String IMGSRC_REG = "http:\"?(.*?)(\"|>|\\s+)";
- Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
- List<String> listImgUrl = new ArrayList<>();
- while (matcher.find()) {
- Matcher m = Pattern.compile(IMGSRC_REG).matcher(matcher.group());
- while (m.find()) {
- listImgUrl.add(m.group().substring(0, m.group().length() - 1));
- }
- }
- return listImgUrl;
- }
- public static void main(String[] args) {
- String url = "http://coder520.com/";
- String html = HttpUtils.get(url);
- List<String> imgUrls = getImageSrc(html);
- for (String imgSrc : imgUrls) {
- System.out.println(imgSrc);
- }
- }
首先将网页的内容抓取下来,然后用正则的方式解析出网页的标签,再解析img的地址。
执行程序我们可以得到下面的内容:
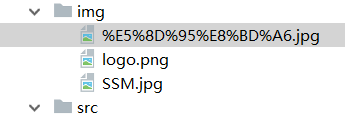
- http://ophdr3ukd.bkt.clouddn.com/logo.png
- http://ophdr3ukd.bkt.clouddn.com/SSM.jpg
- http://ophdr3ukd.bkt.clouddn.com/%E5%8D%95%E8%BD%A6.jpg
通过上面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方法:
- public static void main(String[] args) throws IOException {
- String url = "http://coder520.com/";
- String html = HttpUtils.get(url);
- List<String> imgUrls = getImageSrc(html);
- File dir = new File("img");
- if (!dir.exists()) {
- dir.mkdir();
- }
- for (String imgSrc : imgUrls) {
- System.out.println(imgSrc);
- String fileName = imgSrc.substring(imgSrc.lastIndexOf("/") + 1);
- Files.copy(new URL(imgSrc).openStream(), Paths.get("img/" + fileName));
- }
- }
运行程序图片就被下载下来了
这样就很简单的实现了一个抓取并且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给大家介绍一种更简单的方式,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
- <dependency>
- <groupId>org.jsoup</groupId>
- <artifactId>jsoup</artifactId>
- <version>1.11.3</version>
- </dependency>
使用jsoup之后提取的代码只需要简单的几行即可:
- public static void main(String[] args) throws IOException {
- // String url = "http://coder520.com/";
- // String html = HttpUtils.get(url);
- // List<String> imgUrls = getImageSrc(html);
- //
- // File dir = new File("img");
- // if (!dir.exists()) {
- // dir.mkdir();
- // }
- //
- // for (String imgSrc : imgUrls) {
- // System.out.println(imgSrc);
- // String fileName = imgSrc.substring(imgSrc.lastIndexOf("/") + 1);
- // Files.copy(new URL(imgSrc).openStream(), Paths.get("img/" + fileName));
- // }
- String url = "http://coder520.com/";
- String html = HttpUtils.get(url);
- File dir = new File("img");
- if (!dir.exists()) {
- dir.mkdir();
- }
- Document doc = Jsoup.parse(html);
- // 提取img标签
- Elements imgs = doc.getElementsByTag("img");
- for (Element img : imgs) {
- // 提取img标签的src属性
- String imgSrc = img.attr("src");
- if (imgSrc.startsWith("//")) {
- imgSrc = "http:" + imgSrc;
- }
- System.out.println(imgSrc);
- String fileName = imgSrc.substring(imgSrc.lastIndexOf("/") + 1);
- Files.copy(new URL(imgSrc).openStream(), Paths.get("img/" + fileName));
- }
- }
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方法提取出所有的图片标签,循环遍历,通过attr方法获取图片的src属性,然后下载图片。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按钮,然后把图片自动下载下来,我们可以用swing写界面。
- public class App {
- public static void main(String[] args) {
- JFrame frame = new JFrame();
- frame.setResizable(false);
- frame.setSize(425,400);
- frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
- frame.setLayout(null);
- frame.setLocationRelativeTo(null);
- JTextField jTextField = new JTextField();
- jTextField.setBounds(100, 44, 200, 30);
- frame.add(jTextField);
- JButton jButton = new JButton("提取");
- jButton.setBounds(140, 144, 100, 30);
- frame.add(jButton);
- frame.setVisible(true);
- jButton.addActionListener(new ActionListener() {
- @Override
- public void actionPerformed(ActionEvent e) {
- String url = jTextField.getText();
- if (url == null || url.equals("")) {
- JOptionPane.showMessageDialog(null, "请填写抓取地址");
- return;
- }
- File dir = new File("img");
- if (!dir.exists()) {
- dir.mkdir();
- }
- String html = HttpUtils.get(url);
- Document doc = Jsoup.parse(html);
- Elements imgs = doc.getElementsByTag("img");
- for (Element img : imgs) {
- String imgSrc = img.attr("src");
- if (imgSrc.startsWith("//")) {
- imgSrc = "http:" + imgSrc;
- }
- try {
- System.out.println(imgSrc);
- String fileName = imgSrc.substring(imgSrc.lastIndexOf("/") + 1);
- Files.copy(new URL(imgSrc).openStream(), Paths.get("img/" + fileName));
- } catch (MalformedURLException e1) {
- e1.printStackTrace();
- } catch (IOException e1) {
- e1.printStackTrace();
- }
- }
- JOptionPane.showMessageDialog(null, "抓取完成");
- }
- });
- }
- }
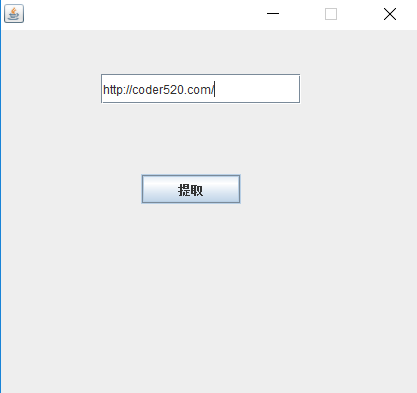
输入地址,点击提取按钮即可下载图片。
Java做爬虫也很方便的更多相关文章
- java网络爬虫基础学习(一)
刚开始接触java爬虫,在这里是搜索网上做一些理论知识的总结 主要参考文章:gitchat 的java 网络爬虫基础入门,好像要付费,也不贵,感觉内容对新手很友好. 一.爬虫介绍 网络爬虫是一个自动提 ...
- 学 Java 网络爬虫,需要哪些基础知识?
说起网络爬虫,大家想起的估计都是 Python ,诚然爬虫已经是 Python 的代名词之一,相比 Java 来说就要逊色不少.有不少人都不知道 Java 可以做网络爬虫,其实 Java 也能做网络爬 ...
- Java网络爬虫笔记
Java网络爬虫笔记 HttpClient来代替浏览器发起请求. select找到的是元素,也就是elements,你想要获取具体某一个属性的值,还是要用attr("")方法.标签 ...
- java正则表达式之java小爬虫
这个java小爬虫, 功能很简单,只有一个,抓取网上的邮箱.用到了javaI/O,正则表达式. public static void main(String[] args) throws IOExce ...
- 【转】44款Java 网络爬虫开源软件
原帖地址 http://www.oschina.net/project/lang/19?tag=64&sort=time 极简网络爬虫组件 WebFetch WebFetch 是无依赖极简网页 ...
- 用HttpClient和用HttpURLConnection做爬虫发现爬取的代码少了的问题
最近在学习用java来做爬虫但是发现不管用那种方式都是爬取的代码比网页的源码少了很多在网上查了很多都说是inputStream的缓冲区太小而爬取的网页太大导致读取出来的网页代码不完整,但是后面发现并不 ...
- Java基础-爬虫实战之爬去校花网网站内容
Java基础-爬虫实战之爬去校花网网站内容 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 爬虫这个实现点我压根就没有把它当做重点,也没打算做网络爬虫工程师,说起爬虫我更喜欢用Pyt ...
- java做web项目比较多
WEB就是轻量级:如果要炫,FLEX或即将普及的html5.0都能做到像C/S那样. java做web项目比较多:如果是桌面程序,还是走C/S比较成熟. 如果是B/S架构的,后台还是JAVA,前台可以 ...
- 【转】Java做服务器开发语言
版权声明:本文为博主原创文章,未经博主允许不得转载. 随着游戏市场的兴起,特别是网页游戏.手机游戏的崛起,对游戏开发技术的需求越来越多.网络游戏开发是一个庞大的体系,总体来说是客户端与服务器端.客户端 ...
随机推荐
- JAVA基础之字节流与字符流
个人理解: IO流就是将数据进行操作的方式,因为编码的不同,所以对文件的操作就产生两种.最好用字节流,为了方便看汉字等,(已经确定文字的话)可以使用字符流.每个流派也就分为输入和输出,这样就可以产生复 ...
- Android GreenDao操作外部DB数据库文件
1.背景 所谓外部数据库文件此处指的就是一个在外部单独创建的db文件,假设有这么一个场景,我们项目中有一些本地数据,不需要接口去获取的(不需要进行网络操作),写死的数据,比如全国各个省各个市的一些基本 ...
- ios uilabel 根据文字 计算宽度 高度
//根据宽度求高度 + (CGFloat)getLabelHeightWithText:(NSString *)text width:(CGFloat)width font: (CGFl ...
- hdfs校验和
hdfs完整性:用户希望储存和处理数据的时候,不会有任何损失或者损坏.所以提供了两种校验: 1.校验和(常用循环冗余校验CRC-32). 2.运行后台进程来检测数据块. 校验和: a.写入数据节点验证 ...
- LR脚本示例之常用函数
1.变量和参数的设置 //将IP地址和端口放入到参数中lr_save_string("127.0.0.1:1080","ip"); //退出脚本建议使用lr_e ...
- WAMP安装提示缺少 msvcr100.dll文件解决方法
WAMP安装提示缺少wamp msvcr100.dll文件解决方法 因为wamp基于vs c++2010开发,需要提前安装这个组件才可以正常运行 微软官方组件下载地址: 32位:http://www. ...
- 重温Javascript(一)-基本概念
工作中要用到JavaScript,一组复习笔记. 一些看法 1. 想想JavaScript目前最常用的宿主环境,浏览器或者服务端V8,都是单线程,所以不用过多的考虑并发的问题,如果是协程来实现异步的方 ...
- 如何真正解决“ UWP DEP0700: 应用程序注册失败。[0x80073CF9] 另一个用户已安装此应用的未打包版本。当前用户无法将该...”的问题
http://www.cnblogs.com/hupo376787/p/8267796.html 谈到了解决该问题的临时方案,那如何真正的解决该问题 目测可以开启设备门户来删除包
- codeforce Gym 100342H Hard Test (思考题)
题意:构造让Dijkstra单源最短路算法有效松弛次数最多的数据... 题解:构造,题意换种说法就是更新晚的路径要比更新早的路径短.因为所有点都会更新一次,那么按照更新时间形成一条链,即到最后一个点的 ...
- 认识CoreData—初识CoreData
http://www.cocoachina.com/ios/20160729/17245.html 这段时间公司一直比较忙,和组里小伙伴一起把公司项目按照之前逻辑重写了一下.由于项目比较大,还要兼顾之 ...