TensorFlow高层封装:从入门到喷这本书
TensorFlow高层封装:从入门到喷这本书
0. 写在前面
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
划重点
从今天开始(20190505-1521),我的博客都用Markdown语法来编写啦,也不知道以后的自己会不会被人所知,会不会有大佬来看过去的我,给我挖坟呢。想想就有点期待呢!希望自己还能更加努力!更加优秀吧!
1. TensorFlow高层封装总览
目前比较主流的TensorFlow高层封装有4个,分别是TensorFlow-Slim、TFLearn、Keras和Estimator。
首先,这里介绍先用TensorFlow-Slim在MNIST数据集上实现LeNet-5模型。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: slim_learn.py
@time: 2019/4/22 10:53
@desc: 使用TensorFlow-Slim在MNIST数据集上实现LeNet-5模型。
"""
import tensorflow as tf
import tensorflow.contrib.slim as slim
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 通过TensorFlow-Slim来定义LeNet-5的网络结构
def lenet5(inputs):
# 将输入数据转化为一个4维数组。其中第一维表示batch大小,另三维表示一张图片。
inputs = tf.reshape(inputs, [-1, 28, 28, 1])
# 定义第一层卷积层。从下面的代码可以看到通过TensorFlow-Slim定义的网络结构
# 并不需要用户去关心如何声明和初始化变量,而只需要定义网络结构即可。下一行代码中
# 定义了一个卷积层,该卷积层的深度为32,过滤器的大小为5x5,使用全0补充。
net = slim.conv2d(inputs, 32, [5, 5], padding='SAME', scope='layer1-conv')
# 定义一个最大池化层,其过滤器大小为2x2,步长为2.
net = slim.max_pool2d(net, 2, stride=2, scope='layer2-max-pool')
# 类似的定义其他网络层结构
net = slim.conv2d(net, 64, [5, 5], padding='SAME', scope='layer3-conv')
net = slim.max_pool2d(net, 2, stride=2, scope='layer4-max-pool')
# 直接使用TensorFlow-Slim封装好的flatten函数将4维矩阵转为2维,这样可以
# 方便后面的全连接层的计算。通过封装好的函数,用户不再需要自己计算通过卷积层之后矩阵的大小。
net = slim.flatten(net, scope='flatten')
# 通过TensorFlow-Slim定义全连接层,该全连接层有500个隐藏节点。
net = slim.fully_connected(net, 500, scope="layer5")
net = slim.fully_connected(net, 10, scope="output")
return net
# 通过TensorFlow-Slim定义网络结构,并使用之前章节中给出的方式训练定义好的模型。
def train(mnist):
# 定义输入
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# 使用TensorFLow-Slim定义网络结构
y = lenet5(x)
# 定义损失函数和训练方法
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1)) # 1 means axis=1
loss = tf.reduce_mean(cross_entropy)
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
# 训练过程
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(10000):
xs, ys = mnist.train.next_batch(100)
_, loss_value = sess.run([train_op, loss], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (i, loss_value))
def main(argv=None):
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
train(mnist)
if __name__ == '__main__':
main()
OK!运行吧皮卡丘!
第一个例子都报错。。。(ValueError: Rank mismatch: Rank of labels (received 1) should equal rank of logits minus 1 (received 4).)
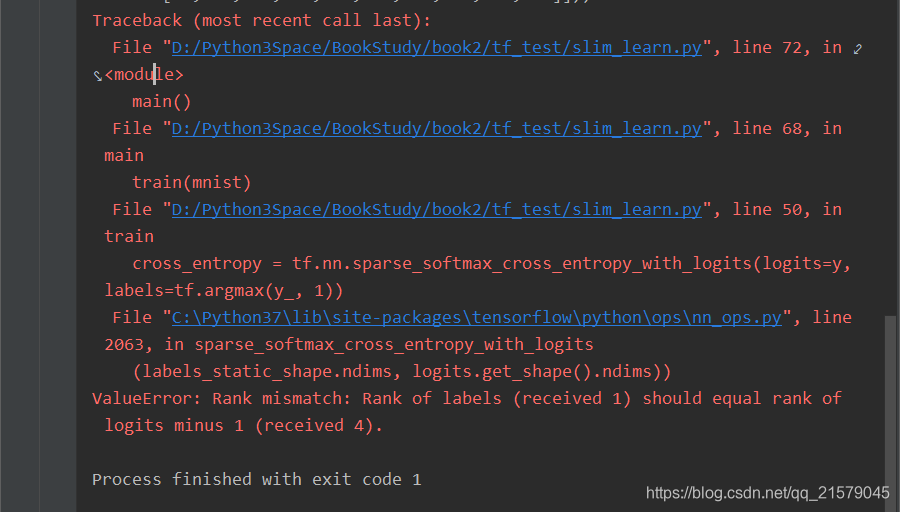
我哭了!找了我半天错误,才发现少写了一句。
net = slim.flatten(net, scope='flatten')
可把我愁坏了,整了半天才弄好。。。
网上都是什么神仙回答,解释的有板有眼的,都说这本书是垃圾,害得我差点立刻在我对这本书评价的博客上再加上几句芬芳。
好歹是学到了知识了。对logits和labels加深了印象了。
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))logits:是计算得到的结果
labels:是原来的数据标签。
千万不要记混了!
labels=tf.argmax(y_, 1)labels输入的是[0, 0, 0, 1, 0, 0, 0, 0, 0, 0](以MNIST为例),
而在tf.nn.sparse_softmax_cross_entropy_with_logits函数中
labels的输入格式需要是[3],也就是说,是类别的编号。
诶!问题来了!
logits=ylogits的格式与labels一样吗?
不一样!
logits的格式与labels转换前的一样,也就是
[0.2, 0.3, 0.1, 0.9, 0.1, 0.1, 0.2, 0.2, 0.4, 0.6]
如果不转换labels的话,可以用tf.nn.softmax_cross_entropy_with_logits达到同样的效果。
诶?那为什么非要转换一下labels呢?
我也没看懂,非要骚一下吧。。。
好了正确的运行结果出来了:
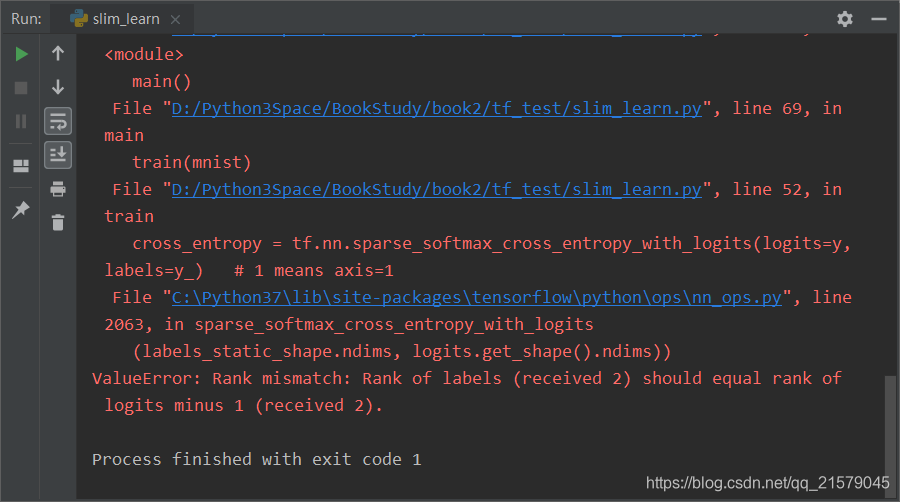
如果我们把刚才说的那句代码改为:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_)
试试看?
哇哦~正常运行了有没有!!!
所以呢?所以为什么这里要非要用有sparse的这个函数呢?
反正我是没看懂(摊手┓( ´∀` )┏)。。。
与TensorFlow-Slim相比,TFLearn是一个更加简洁的高层封装。
因为TFLearn并没有集成在TensorFlow中,所以首先是用pip安装。
安装完后,下面是用TFLearn在MNIST数据集上实现LeNet-5模型。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tflearn_learn.py
@time: 2019/5/5 16:53
@desc: 使用TFLearn在MNIST数据集上实现LeNet-5模型。
"""
import tflearn
from tflearn.layers.core import input_data, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
import tflearn.datasets.mnist as mnist
# 读取mnist数据
trainX, trainY, testX, testY = mnist.load_data(data_dir="D:/Python3Space/BookStudy/book2/MNIST_data", one_hot=True)
# 将图像数据reshape成卷积神经网络输入的格式
trainX = trainX.reshape([-1, 28, 28, 1])
testX = testX.reshape([-1, 28, 28, 1])
# 构建神经网络,这个过程和TensorFlow-Slim比较类似。input_data定义了一个placeholder来接入输入数据。
net = input_data(shape=[None, 28, 28, 1], name='input')
# 通过TFLearn封装好的API定义一个深度为5,过滤器为5x5,激活函数为ReLU的卷积层
net = conv_2d(net, 32, 5, activation='relu')
# 定义一个过滤器为2x2的最大池化层
net = max_pool_2d(net, 2)
# 类似地定义其他的网络结构。
net = conv_2d(net, 64, 5, activation='relu')
net = max_pool_2d(net, 2)
net = fully_connected(net, 500, activation='relu')
net = fully_connected(net, 10, activation='softmax')
# 使用TFLearn封装好的函数定义学习任务。指定优化器为sgd,学习率为0.01,损失函数为交叉熵。
net = regression(net, optimizer='sgd', learning_rate=0.01, loss='categorical_crossentropy')
# 通过定义的网络结构训练模型,并在指定的验证数据上验证模型的效果。
# TFLearn将模型的训练过程封装到了一个类中,这样可以减少非常多的冗余代码。
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(trainX, trainY, n_epoch=20, validation_set=([testX, testY]), show_metric=True)
个人感相较于Slim,TFLearn好用太多了吧。。。特别是model.fit真的是给我眼前一亮的感觉,这也太帅了吧,瞧这交叉熵小黄字,瞧这epoch,瞧这step。。。封装万岁!!!(对我这种菜鸡而言,不要跟我谈底层,我!不!够!格!)
运行结果:

2. Keras介绍
2.1 Keras基本用法
下面是用原生态的Keras在MNIST数据集上实现LeNet-5模型。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_learn.py
@time: 2019/5/5 17:42
@desc: 使用Keras在MNIST数据集上实现LeNet-5模型。
"""
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from keras import backend as K
num_calsses = 10
img_rows, img_cols = 28, 28
# 通过Keras封装好的API加载MNIST数据。其中trainX就是一个60000x28x28的数组,
# trainY是每一张图片对应的数字。
(trainX, trainY), (testX, testY) = mnist.load_data()
# 因为不同的底层(TensorFlow或者MXNet)对输入的要求不一样,所以这里需要根据对图像
# 编码的格式要求来设置输入层的格式。
if K.image_data_format() == 'channels_first':
trainX = trainX.reshape(trainX.shape[0], 1, img_rows, img_cols)
testX = testX.reshape(trainX.shape[0], 1, img_rows, img_cols)
# 因为MNIST中的图片是黑白的,所以第一维的取值为1
input_shape = (1, img_rows, img_cols)
else:
trainX = trainX.reshape(trainX.shape[0], img_rows, img_cols, 1)
testX = testX.reshape(testX.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# 将图像像素转化为0到1之间的实数。
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
# 将标准答案转化为需要的格式(One-hot编码)。
trainY = keras.utils.to_categorical(trainY, num_calsses)
testY = keras.utils.to_categorical(testY, num_calsses)
# 使用Keras API定义模型
model = Sequential()
# 一层深度为32,过滤器大小为5x5的卷积层
model.add(Conv2D(32, kernel_size=(5, 5), activation='relu', input_shape=input_shape))
# 一层过滤器大小为2x2的最大池化层。
model.add(MaxPooling2D(pool_size=(2, 2)))
# 一层深度为64, 过滤器大小为5x5的卷积层。
model.add(Conv2D(64, (5, 5), activation='relu'))
# 一层过滤器大小为2x2的最大池化层。
model.add(MaxPooling2D(pool_size=(2, 2)))
# 将卷积层的输出拉直后作为下面全连接的输入。
model.add(Flatten())
# 全连接层,有500个节点。
model.add(Dense(500, activation='relu'))
# 全连接层,得到最后的输出。
model.add(Dense(num_calsses, activation='softmax'))
# 定义损失函数、优化函数和测评的方法。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy'])
# 类似TFLearn中的训练过程,给出训练数据,batch大小、训练轮数和验证数据,Keras可以自动完成模型的训练过程。
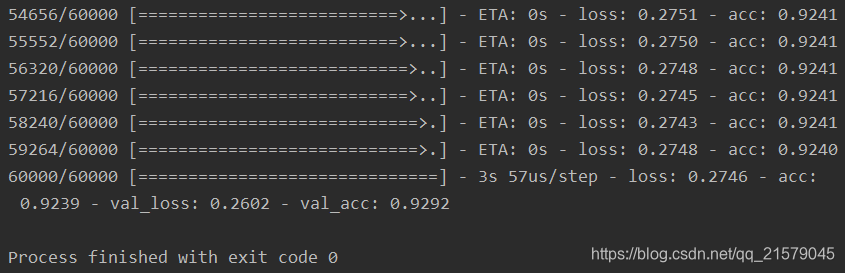
model.fit(trainX, trainY, batch_size=128, epochs=20, validation_data=(testX, testY))
# 在测评数据上计算准确率
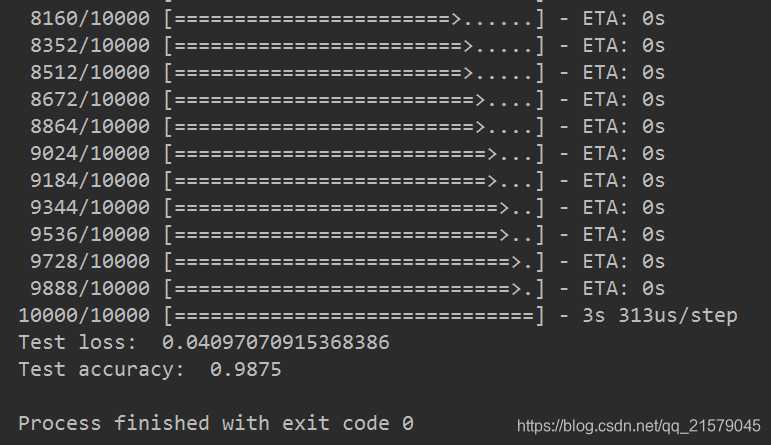
score = model.evaluate(testX, testY)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
运行之后(跑了我一夜呀我滴妈。。。):
下面是用原生态的Keras实现循环神经网络。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_rnn.py
@time: 2019/5/6 12:30
@desc: 用原生态的Keras实现循环神经网络
"""
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM
from keras.datasets import imdb
# 最多使用的单词数
max_features = 20000
# 循环神经网络的截断长度。
maxlen = 80
batch_size = 32
# 加载数据并将单词转化为ID,max_features给出了最多使用的单词数。和自然语言模型类似,
# 会将出现频率较低的单词替换为统一的的ID。通过Keras封装的API会生成25000条训练数据和
# 25000条测试数据,每一条数据可以被看成一段话,并且每段话都有一个好评或者差评的标签。
(trainX, trianY), (testX, testY) = imdb.load_data(num_words=max_features)
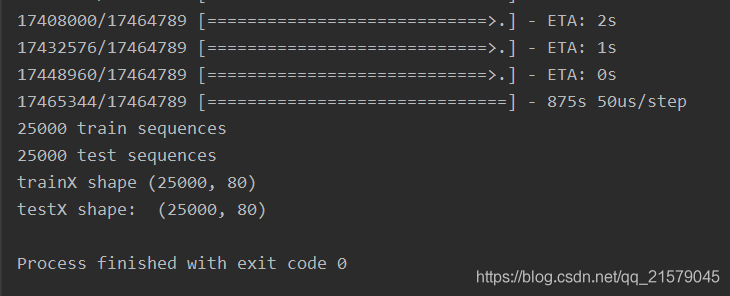
print(len(trainX), 'train sequences')
print(len(testX), 'test sequences')
# 在自然语言中,每一段话的长度是不一样的,但循环神经网络的循环长度是固定的,所以这里需要先将
# 所有段落统一成固定长度。对于长度不够的段落,要使用默认值0来填充,对于超过长度的段落
# 则直接忽略掉超过的部分。
trainX = sequence.pad_sequences(trainX, maxlen=maxlen)
testX = sequence.pad_sequences(testX, maxlen=maxlen)
print('trainX shape', trainX.shape)
print('testX shape: ', testX.shape)
# 在完成数据预处理之后构建模型
model = Sequential()
# 构建embedding层。128代表了embedding层的向量维度。
model.add(Embedding(max_features, 128))
# 构建LSTM层
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
# 构建最后的全连接层。注意在上面构建LSTM层时只会得到最后一个节点的输出,
# 如果需要输出每个时间点的结果,呢么可以将return_sequence参数设为True。
model.add(Dense(1, activation='sigmoid'))
# 与MNIST样例类似的指定损失函数、优化函数和测评指标。
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 在测试数据上评测模型。
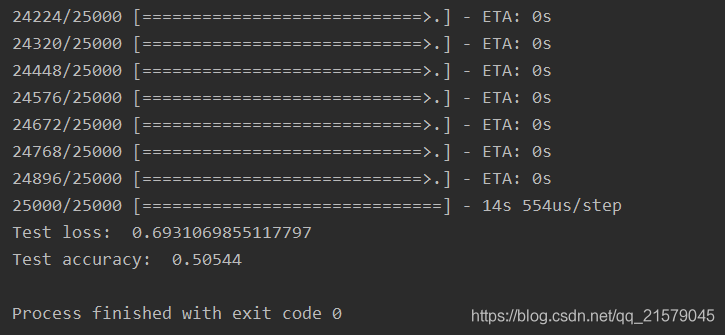
score = model.evaluate(testX, testY, batch_size=batch_size)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
睡了个午觉就跑完啦:
2.2 Keras高级用法
面对上面的例子,都是顺序搭建的神经网络模型,类似于Inception这样的模型结构,就需要更加灵活的模型定义方法了。
在这里我真的是忍不住要吐槽一下书上的内容,简直完全没有讲清楚在说什么鬼。。。没说清楚究竟是用的那一部分的数据,是MNIST还是rnn的数据。。。捣鼓了半天才知道是MNIST。然后这里的意思应该是用全连接的方式,即输入数据为(60000, -1),也就是说样本是60000个,然后把图片的维度拉伸为1维。(这里我也是摸索了好久才知道的),所以在代码中需要对数据进行reshape处理。不然会报错:
ValueError: Error when checking input: expected input_1 to have 2 dimensions, but got array with shape (60000, 28, 28)
参考链接:https://blog.csdn.net/u012193416/article/details/79399679
是真的坑爹,只能说。。。什么也没有说清楚,就特么瞎指挥。。。(然鹅,我是真的菜。。。摊手。。。)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_inception.py
@time: 2019/5/6 14:29
@desc: 用更加灵活的模型定义方法在MNIST数据集上实现全连接层模型。
"""
import keras
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
# 使用前面介绍的类似方法生成trainX、trainY、testX、testY,唯一的不同是这里只用了
# 全连接层,所以不需要将输入整理成三维矩阵。
num_calsses = 10
img_rows, img_cols = 28, 28
# 通过Keras封装好的API加载MNIST数据。其中trainX就是一个60000x28x28的数组,
# trainY是每一张图片对应的数字。
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX.reshape(len(trainX), -1)
testX = testX.reshape(len(testX), -1)
# 将图像像素转化为0到1之间的实数。
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
# 将标准答案转化为需要的格式(One-hot编码)。
trainY = keras.utils.to_categorical(trainY, num_calsses)
testY = keras.utils.to_categorical(testY, num_calsses)
# 定义输入,这里指定的维度不用考虑batch大小。
inputs = Input(shape=(784, ))
# 定义一层全连接层,该层有500隐藏节点,使用ReLU激活函数。这一层的输入为inputs
x = Dense(500, activation='relu')(inputs)
# 定义输出层。注意因为keras封装的categorical_crossentropy并没有将神经网络的输出
# 再经过一层softmax,所以这里需要指定softmax作为激活函数。
predictions = Dense(10, activation='softmax')(x)
# 通过Model类创建模型,和Sequential类不同的是Model类在初始化的时候需要指定模型的输入和输出
model = Model(inputs=inputs, outputs=predictions)
# 使用与前面类似的方法定义损失函数、优化函数和评测方法。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy'])
# 使用与前面类似的方法训练模型。
model.fit(trainX, trainY, batch_size=128, epochs=10, validation_data=(testX, testY))
修改之后运行可以得到:
通过这样的方式,Keras就可以实现类似Inception这样的模型结构了。
现在又要说坑爹的部分了,这本书在这里直接照抄的Keras的手册中的例子,来解释用Keras实现Inception-v3的模型结构,所以给出的代码是这样的
from keras.layers import Conv2D, MaxPooling2D, Input
# 定义输入图像尺寸
input_img = Input(shape=(256, 256, 3))
# 定义第一个分支。
tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
# 定义第二个分支。与顺序模型不同,第二个分支的输入使用的是input_img,而不是第一个分支的输出。
tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
# 定义第三个分支。类似地,第三个分支的输入也是input_img。
tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)
# 将三个分支通过concatenate的方式拼凑在一起。
output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)
你可能要问“这就完啦?”,我想告诉你的是,对的。关于Inception-v3的部分就这么点。然后我给你看一眼网上官方的代码:
参考链接:https://keras.io/zh/getting-started/functional-api-guide/
是不是有种似曾相识的感觉。。。
踏马的根本就没有想着去实现好吗?
我也是醉了的,我就问一句,不是一直在用MNIST数据集作为例子吗!那这个
input_img = Input(shape=(256, 256, 3))
图像尺寸怎么突然就编程(256, 256, 3)了呢?而不是(28, 28, 1)呢?
这本书一点都不走心好吗!
我也是佛了,那么我只能靠自己理解,并自己写例子了。这里面的艰辛我就不说了,不卖惨了,是真的恨,我只希望每一个例子都能够有始有终,都能够有输出有结果,能运行!
下面贴一下我自己想的改的代码吧:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_inception2.py
@time: 2019/5/6 15:43
@desc: 用原生态的Keras实现Inception
"""
from keras.layers import Conv2D, MaxPooling2D, Input, Dense, Flatten
import keras
from keras.models import Model
from keras.datasets import mnist
from keras import backend as K
# 使用前面介绍的类似方法生成trainX、trainY、testX、testY,唯一的不同是这里只用了
# 全连接层,所以不需要将输入整理成三维矩阵。
num_calsses = 10
img_rows, img_cols = 28, 28
# 通过Keras封装好的API加载MNIST数据。其中trainX就是一个60000x28x28的数组,
# trainY是每一张图片对应的数字。
(trainX, trainY), (testX, testY) = mnist.load_data()
if K.image_data_format() == 'channels_first':
trainX = trainX.reshape(trainX.shape[0], 1, img_rows, img_cols)
testX = testX.reshape(trainX.shape[0], 1, img_rows, img_cols)
# 因为MNIST中的图片是黑白的,所以第一维的取值为1
input_shape = (1, img_rows, img_cols)
else:
trainX = trainX.reshape(trainX.shape[0], img_rows, img_cols, 1)
testX = testX.reshape(testX.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# 将图像像素转化为0到1之间的实数。
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
# 将标准答案转化为需要的格式(One-hot编码)。
trainY = keras.utils.to_categorical(trainY, num_calsses)
testY = keras.utils.to_categorical(testY, num_calsses)
# 定义输入图像尺寸
input_img = Input(shape=(28, 28, 1))
# 定义第一个分支。
tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
# 定义第二个分支。与顺序模型不同,第二个分支的输入使用的是input_img,而不是第一个分支的输出。
tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
# 定义第三个分支。类似地,第三个分支的输入也是input_img。
tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)
# 将三个分支通过concatenate的方式拼凑在一起。
output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)
# 将卷积层的输出拉直后作为下面全连接的输入。
tower_4 = Flatten()(output)
# 全连接层,有500个节点。
tower_5 = Dense(500, activation='relu')(tower_4)
# 全连接层,得到最后的输出。
predictions = Dense(num_calsses, activation='softmax')(tower_5)
# 通过Model类创建模型,和Sequential类不同的是Model类在初始化的时候需要指定模型的输入和输出
model = Model(inputs=input_img, outputs=predictions)
# 使用与前面类似的方法定义损失函数、优化函数和评测方法。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy'])
# 使用与前面类似的方法训练模型。
model.fit(trainX, trainY, batch_size=128, epochs=20, validation_data=(testX, testY))
# 在测试数据上评测模型。
score = model.evaluate(testX, testY, batch_size=128)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
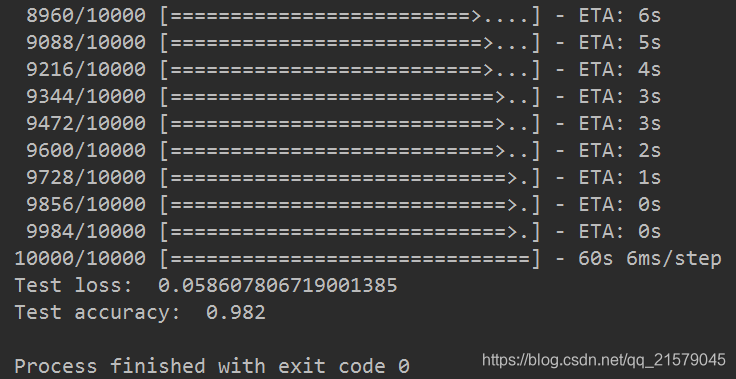
运行结果:
说明,我改了之后是能跑的。。。
对了,如果有杠精问我,人家只是抛砖引玉,让读者举一反三。。。那我没什么好说的。。。
又花了一晚上跑完。。。
用原生态的Keras实现非顺序模型,多输入和多输出模型。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_inception3.py
@time: 2019/5/7 14:54
@desc: 用原生态的Keras实现非顺序模型,多输入和多输出模型
"""
import keras
from tflearn.layers.core import fully_connected
from keras.datasets import mnist
from keras.layers import Input, Dense
from keras.models import Model
from keras import backend as K
# 类似前面的方式生成trainX、trainY、testX、testY
num_calsses = 10
img_rows, img_cols = 28, 28
# 通过Keras封装好的API加载MNIST数据。其中trainX就是一个60000x28x28的数组,
# trainY是每一张图片对应的数字。
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX.reshape(len(trainX), -1)
testX = testX.reshape(len(testX), -1)
# 将图像像素转化为0到1之间的实数。
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
# 将标准答案转化为需要的格式(One-hot编码)。
trainY = keras.utils.to_categorical(trainY, num_calsses)
testY = keras.utils.to_categorical(testY, num_calsses)
# 定义两个输入,一个输入为原始的图片信息,另一个输入为正确答案。
input1 = Input(shape=(784, ), name='input1')
input2 = Input(shape=(10, ), name='input2')
# 定义一个只有一个隐藏节点的全连接网络。
x = Dense(1, activation='relu')(input1)
# 定义只使用了一个隐藏节点的网络结构的输出层。
output1 = Dense(10, activation='softmax', name='output1')(x)
# 将一个隐藏节点的输出和正确答案拼接在一起,这个将作为第二个输出层的输入。
y = keras.layers.concatenate([x, input2])
# 定义第二个输出层。
output2 = Dense(10, activation='softmax', name='output2')(y)
# 定义一个有多个输入和多个输出的模型,这里只需要将所有的输入和输出给出即可。
model = Model(inputs=[input1, input2], outputs=[output1, output2])
# 定义损失函数、优化函数和评测方法。若多个输出的损失函数相同,可以只指定一个损失函数。
# 如果多个输出的损失函数不同,则可以通过一个列表或一个字典来指定每一个输出的损失函数。
# 比如可以使用:loss = {'output1': 'binary_crossentropy', 'output2': 'binary_crossentropy'}
# 来为不同的输出指定不同的损失函数。类似的,Keras也支持为不同输出产生的损失指定权重,
# 这可以通过通过loss_weights参数来完成。在下面的定义中,输出output1的权重为1,output2
# 的权重为0.1。所以这个模型会更加偏向于优化第一个输出。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), loss_weights=[1, 0.1], metrics=['accuracy'])
# 模型训练过程。因为有两个输入和输出,所以这里提供的数据也需要有两个输入和两个期待的正确
# 答案输出。通过列表的方式提供数据时,Keras会假设数据给出的顺序和定义Model类时输入输出
# 给出的顺序是对应的。为了避免顺序不一致导致的问题,这里更推荐使用字典的形式给出。
model.fit(
[trainX, trainY], [trainY, trainY],
batch_size=128,
epochs=20,
validation_data=([testX, testY], [testY, testY])
)
运行结果:
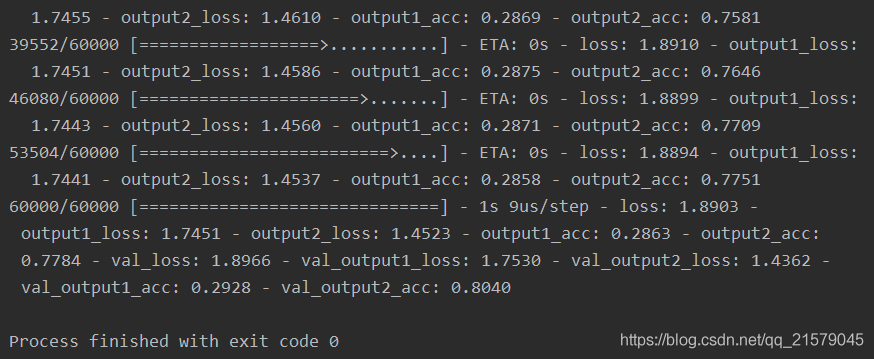
我们可以看出,由于输出层1只使用了一个一维的隐藏节点,所以正确率很低,输出层2虽然使用了正确答案最为输入,但是损失函数中的权重较低,所以收敛速度较慢,准确率只有0.804。现在我们把权重设置相同,运行得到:
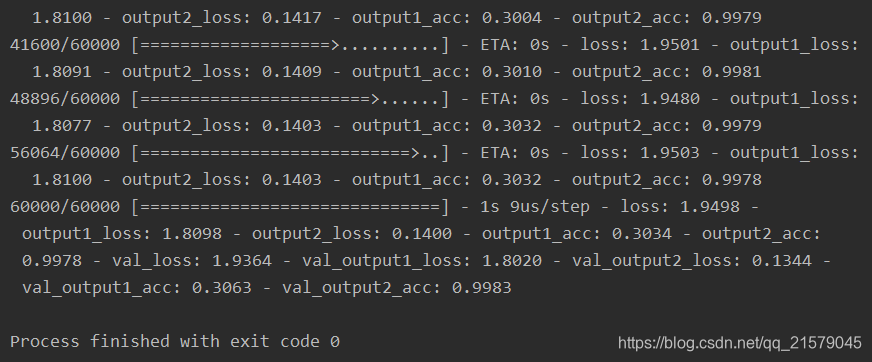
这样输出二经过了足够的训练,精度就提高了很多。
虽然通过返回值的方式已经可以实现大部分的神经网络模型,然而Keras API还存在两大问题。一是对训练数据的处理流程支持的不太好;二十无法支持分布式训练。为了解决这两个问题,Keras提供了一种与原生态TensorFlow结合得更加紧密的方式。下面的代码是:实现Keras与TensorFlow联合起来解决MNIST问题。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_test4.py
@time: 2019/5/7 15:45
@desc: 实现Keras与TensorFlow联合起来解决MNIST问题。
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist_data = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
# 通过TensorFlow中的placeholder定义输入。类似的,Keras封装的网络层结构也可以支持使用
# 前面章节中介绍的输入队列。这样可以有效避免一次性加载所有数据的问题。
x = tf.placeholder(tf.float32, shape=(None, 784))
y_ = tf.placeholder(tf.float32, shape=(None, 10))
# 直接使用TensorFlow中提供的Keras API定义网络结构。
net = tf.keras.layers.Dense(500, activation='relu')(x)
y = tf.keras.layers.Dense(10, activation='softmax')(net)
# 定义损失函数和优化方法。注意这里可以混用Keras的API和原生态TensorFlow的API
loss = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_, y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
# 定义预测的正确率作为指标。
acc_value = tf.reduce_mean(tf.keras.metrics.categorical_accuracy(y_, y))
# 使用原生态TensorFlow的方式训练模型。这样可以有效地实现分布式。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(10000):
xs, ys = mnist_data.train.next_batch(100)
_, loss_value = sess.run([train_step, loss], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (i, loss_value))
print(acc_value.eval(feed_dict={x: mnist_data.test.images,
y_: mnist_data.test.labels}))
运行结果:
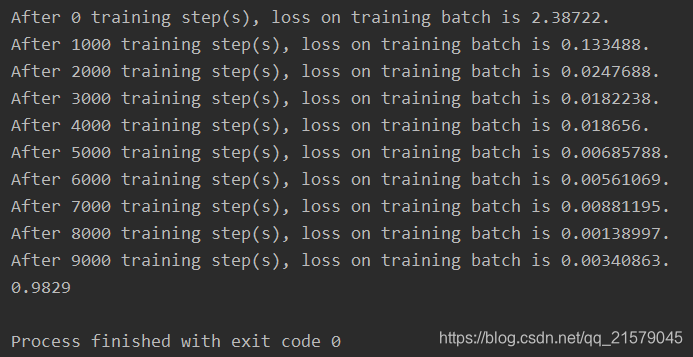
通过和原生态TensorFlow更紧密地结合,可以使建模的灵活性进一步提高,但是同时也会损失一部分封装带来的易用性。所以在实际问题中,需要根据需求合理的选择封装的程度。
3. Estimator介绍
3.1 Estimator基本用法
基于MNIST数据集,通过Estimator实现全连接神经网络。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: estimator_test1.py
@time: 2019/5/7 16:22
@desc: 基于MNIST数据集,通过Estimator实现全连接神经网络。
"""
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 将TensorFlow日志信息输出到屏幕
tf.logging.set_verbosity(tf.logging.INFO)
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
# 指定神经网络的输入层,所有这里指定的输入都会拼接在一起作为整个神经网络的输入。
feature_columns = [tf.feature_column.numeric_column("image", shape=[784])]
# 通过TensorFlow提供的封装好的Estimator定义神经网络模型。feature_columns参数
# 给出了神经网络输入层需要用到的数据,hidden_units列表中给出了每一层
# 隐藏层的节点数。n_classes给出了总共类目的数量,optimizer给出了使用的优化函数。
# Estimator会将模型训练过程中的loss变化以及一些其他指标保存到model_dir目录下,
# 通过TensorFlow可以可视化这些指标的变化过程。并通过TensorBoard可视化监控指标结果。
estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[500],
n_classes=10,
optimizer=tf.train.AdamOptimizer(),
model_dir="./log"
)
# 定义数据输入。这里x中需要给出所有的输入数据。因为上面feature_columns只定义了一组
# 输入,所以这里只需要制定一个就好。如果feature_columns中指定了多个,那么这里也需要
# 对每一个指定的输入提供数据。y中需要提供每一个x对应的正确答案,这里要求分类的结果
# 是一个正整数。num_epochs指定了数据循环使用的轮数。比如在测试时可以将这个参数指定为1.
# batch_size指定了一个batch的大小。shuffle指定了是否需要对数据进行随机打乱。
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.train.images},
y=mnist.train.labels.astype(np.int32),
num_epochs=None,
batch_size=128,
shuffle=True
)
# 训练模型。注意这里没有指定损失函数,通过DNNClassifier定义的模型会使用交叉熵作为损失函数。
estimator.train(input_fn=train_input_fn, steps=10000)
# 定义测试时的数据输入。指定的形式和训练时的数据输入基本一致。
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.test.images},
y=mnist.test.labels.astype(np.int32),
num_epochs=1,
batch_size=128,
shuffle=False
)
# 通过evaluate评测训练好的模型的效果。
accuracy_score = estimator.evaluate(input_fn=test_input_fn)["accuracy"]
print("\nTest accuracy: %g %%" % (accuracy_score*100))
运行可得:
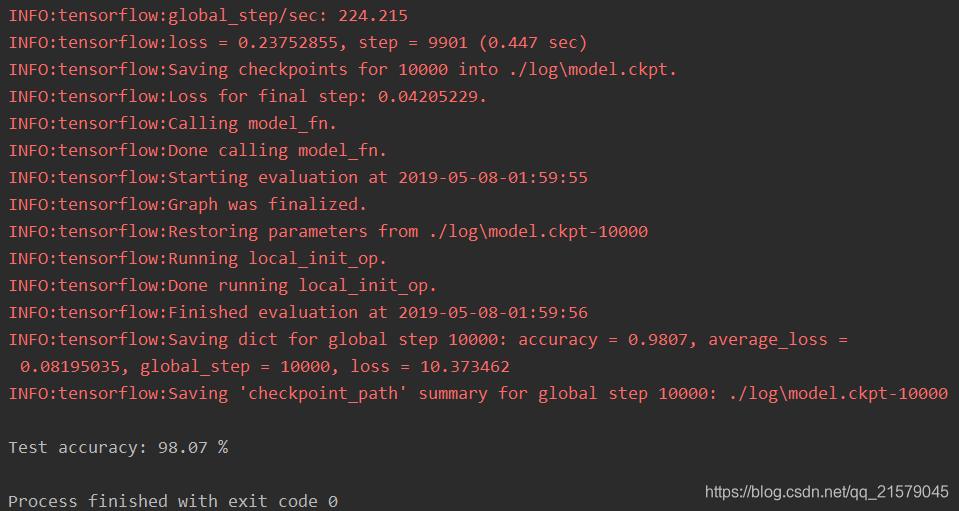
使用下面的命令开启tensorboard之旅:(我又要喷了,书里根本没说怎么开启tensorboard,我完全靠自行百度摸索的。。。)
tensorboard --logdir=""
引号里面填自己的log所在的地址。然后运行:
复制最下面的那个地址,在浏览器(我是谷歌浏览器)粘贴并转到。
记住!是粘贴并转到,不是ctrl+v,是右键,粘贴并转到。
别问!问就是吃了好多亏。。。
反正我的电脑是粘贴并转到之后,卡了一会儿,就出现了这个界面:
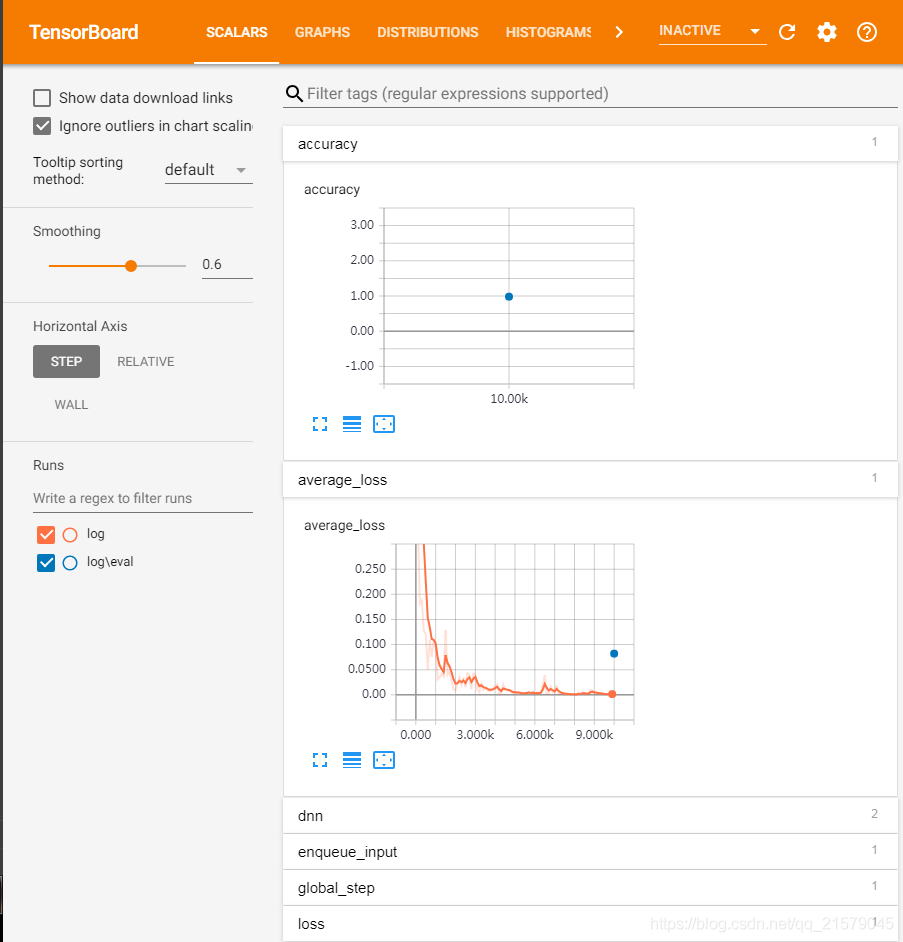
虽然跟书上的图的布局不一样,下面折叠的指标,展开也有图就是了。。。
当然GRAPHS也是有的嘿嘿。。。
3.2 Estimator自定义模型
通过自定义的方式使用卷积神经网络解决MNIST问题:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: estimator_test2.py
@time: 2019/5/9 12:31
@desc: 通过自定义的方式使用卷积神经网络解决MNIST问题
"""
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
tf.logging.set_verbosity(tf.logging.INFO)
# 通过tf.layers来定义模型结构。这里可以使用原生态TensorFlow API或者任何
# TensorFlow的高层封装。X给出了输入层张量,is_training指明了是否为训练。
# 该函数返回前向传播的结果。
def lenet(x, is_training):
# 将输入转化为卷积层需要的形状
x = tf.reshape(x, shape=[-1, 28, 28, 1])
net = tf.layers.conv2d(x, 32, 5, activation=tf.nn.relu)
net = tf.layers.max_pooling2d(net, 2, 2)
net = tf.layers.conv2d(net, 64, 3, activation=tf.nn.relu)
net = tf.layers.max_pooling2d(net, 2, 2)
net = tf.contrib.layers.flatten(net)
net = tf.layers.dense(net, 1024)
net = tf.layers.dropout(net, rate=0.4, training=is_training)
return tf.layers.dense(net, 10)
# 自定义Estimator中使用的模型,定义的函数有4个输入,features给出了在输入函数中
# 会提供的输入层张量。注意这是一个字典,字典里的内容是通过tf.estimator.inputs.numpy_input_fn
# 中x参数的内容指定的。labels是正确答案,这个字段的内容是通过numpy_input_fn中y参数给出的。
# mode的取值有3中可能,分别对应Estimator类的train、evaluate和predict这3个函数。通过
# 这个参数可以判断当前会否是训练过程。最后params是一个字典,这个字典中可以给出模型相关的任何超参数
# (hyper-parameter)。比如这里将学习率放在params中。
def model_fn(features, labels, mode, params):
# 定义神经网络的结构并通过输入得到前向传播的结果。
predict = lenet(features["image"], mode == tf.estimator.ModeKeys.TRAIN)
# 如果在预测模式,那么只需要将结果返回即可。
if mode == tf.estimator.ModeKeys.PREDICT:
# 使用EstimatorSpec传递返回值,并通过predictions参数指定返回的结果。
return tf.estimator.EstimatorSpec(
mode=mode,
predictions={"result": tf.argmax(predict, 1)}
)
# 定义损失函数
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=predict, labels=labels))
# 定义优化函数。
optimizer = tf.train.GradientDescentOptimizer(learning_rate=params["learning_rate"])
# 定义训练过程。
train_op = optimizer.minimize(loss=loss, global_step=tf.train.get_global_step())
# 定义评测标准,在运行evaluate时会计算这里定义的所有评测标准。
eval_metric_ops = {
"my_metric": tf.metrics.accuracy(tf.argmax(predict, 1), labels)
}
# 返回模型训练过程需要使用的损失函数、训练过程和评测方法。
return tf.estimator.EstimatorSpec(
mode=mode,
loss=loss,
train_op=train_op,
eval_metric_ops=eval_metric_ops
)
mnist = input_data.read_data_sets("D:/Python3Space/BookStudy/book2/MNIST_data", one_hot=False)
# 通过自定义的方式生成Estimator类。这里需要提供模型定义的函数并通过params参数指定模型定义时使用的超参数。
model_params = {"learning_rate": 0.01}
estimator = tf.estimator.Estimator(model_fn=model_fn, params=model_params)
# 和前面的类似,训练和评测模型。
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.train.images},
y=mnist.train.labels.astype(np.int32),
num_epochs=None,
batch_size=128,
shuffle=True
)
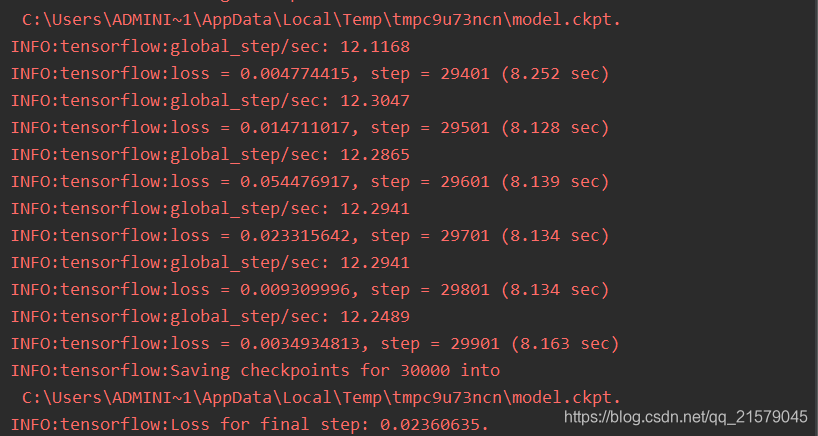
estimator.train(input_fn=train_input_fn, steps=30000)
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.test.images},
y=mnist.test.labels.astype(np.int32),
num_epochs=1,
batch_size=128,
shuffle=False
)
test_results = estimator.evaluate(input_fn=test_input_fn)
# 这里使用的my_metric中的内容就是model_fn中eval_metric_ops定义的评测指标。
accuracy_score = test_results["my_metric"]
print("\nTest accuracy: %g %%" % (accuracy_score*100))
# 使用训练好的模型在新数据上预测结果。
predict_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.test.images[:10]},
num_epochs=1,
shuffle=False
)
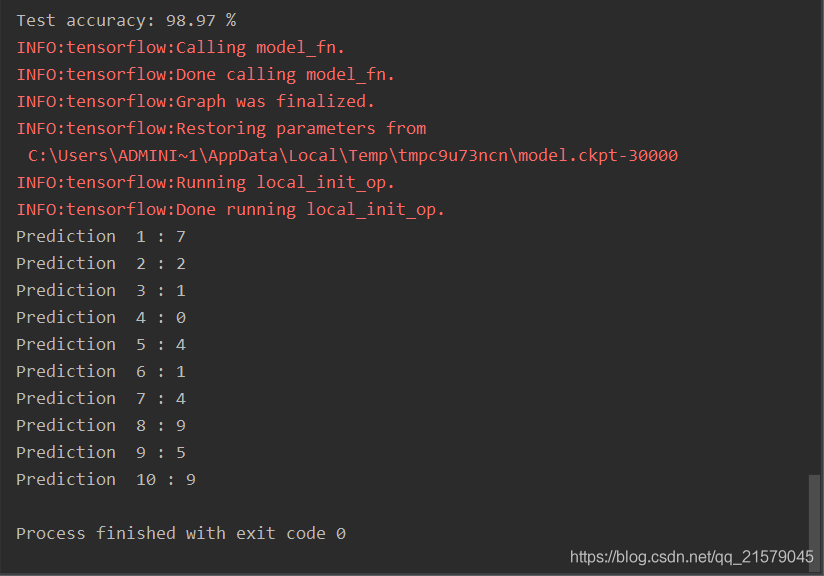
predictions = estimator.predict(input_fn=predict_input_fn)
for i, p in enumerate(predictions):
# 这里result就是tf.estimator.EstimatorSpec的参数predicitons中指定的内容。
# 因为这个内容是一个字典,所以Estimator可以很容易支持多输出。
print("Prediction %s : %s" % (i + 1, p["result"]))
运行之后得到:
预测结果:
3.3 使用数据集(Dataset)作为Estimator输入
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: estimator_test3.py
@time: 2019/5/9 14:13
@desc: 通过Estimator和数据集相结合的方式完成整个数据读取和模型训练的过程。
"""
import tensorflow as tf
tf.logging.set_verbosity(tf.logging.INFO)
# Estimator的自定义输入函数需要每一次被调用时可以得到一个batch的数据(包括所有的
# 输入层数据和期待的正确答案标注),通过数据集可以很自然地实现这个过程。虽然Estimator
# 要求的自定义输入函数不能有参数,但是通过python提供的lambda表达式可以快速将下面的
# 函数转化为不带参数的函数。
def my_input_fn(file_path, perform_shuffle=False, repeat_count=1):
# 定义解析csv文件中一行的方法。
def decode_csv(line):
# 将一行中的数据解析出来。注意iris数据中最后一列为正确答案,前面4列为特征。
parsed_line = tf.decode_csv(line, [[0.], [0.], [0.], [0.], [0]])
# Estimator的输入函数要求特征是一个字典,所以这里返回的也需要是一个字典。
# 字典中key的定义需要和DNNclassifier中feature_columns的定义匹配。
return {"x": parsed_line[:-1]}, parsed_line[-1:]
# 使用数据集处理输入数据。数据集的具体使用方法可以参考前面。
dataset = (tf.data.TextLineDataset(file_path).skip(1).map(decode_csv))
if perform_shuffle:
dataset = dataset.shuffle(buffer_size=256)
dataset = dataset.repeat(repeat_count)
dataset = dataset.batch(12)
iterator = dataset.make_one_shot_iterator()
# 通过定义的数据集得到一个batch的输入数据。这就是整个自定义的输入过程的返回结果。
batch_features, batch_labels = iterator.get_next()
# 如果是为预测过程提供输入数据,那么batch_labels可以直接使用None。
return batch_features, batch_labels
# 与前面中类似地定义Estimator
feature_columns = [tf.feature_column.numeric_column("x", shape=[4])]
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 10],
n_classes=3
)
# 使用lambda表达式将训练相关的信息传入自定义输入数据处理函数并生成Estimator需要的输入函数
classifier.train(input_fn=lambda: my_input_fn("./iris_data/iris_training (1).csv", True, 10))
# 使用lambda表达式将测试相关的信息传入自定义输入数据处理函数并生成Estimator需要的输入函数。
# 通过lambda表达式的方式可以大大减少冗余代码。
test_results = classifier.evaluate(input_fn=lambda: my_input_fn("./iris_data/iris_test (1).csv", False, 1))
print("\nTest accuracy: %g %%" % (test_results["accuracy"]*100))
运行之后,玄学报错。。。
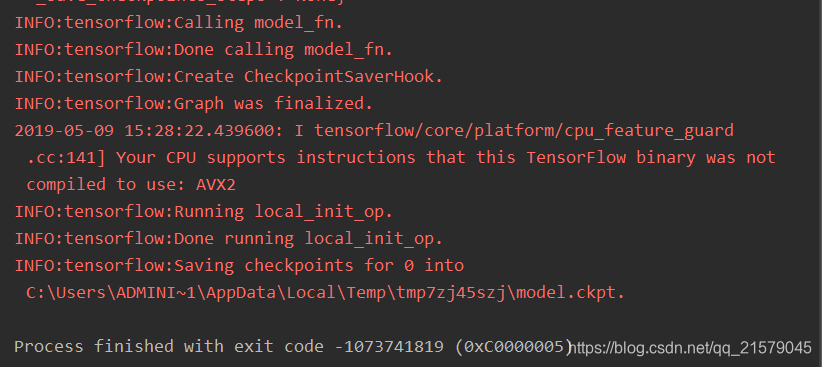
我佛了,查了一万种方法,也解决不了玄学报错。。。
然后,我换了个机器,macbook。。。就正常运行了。。。
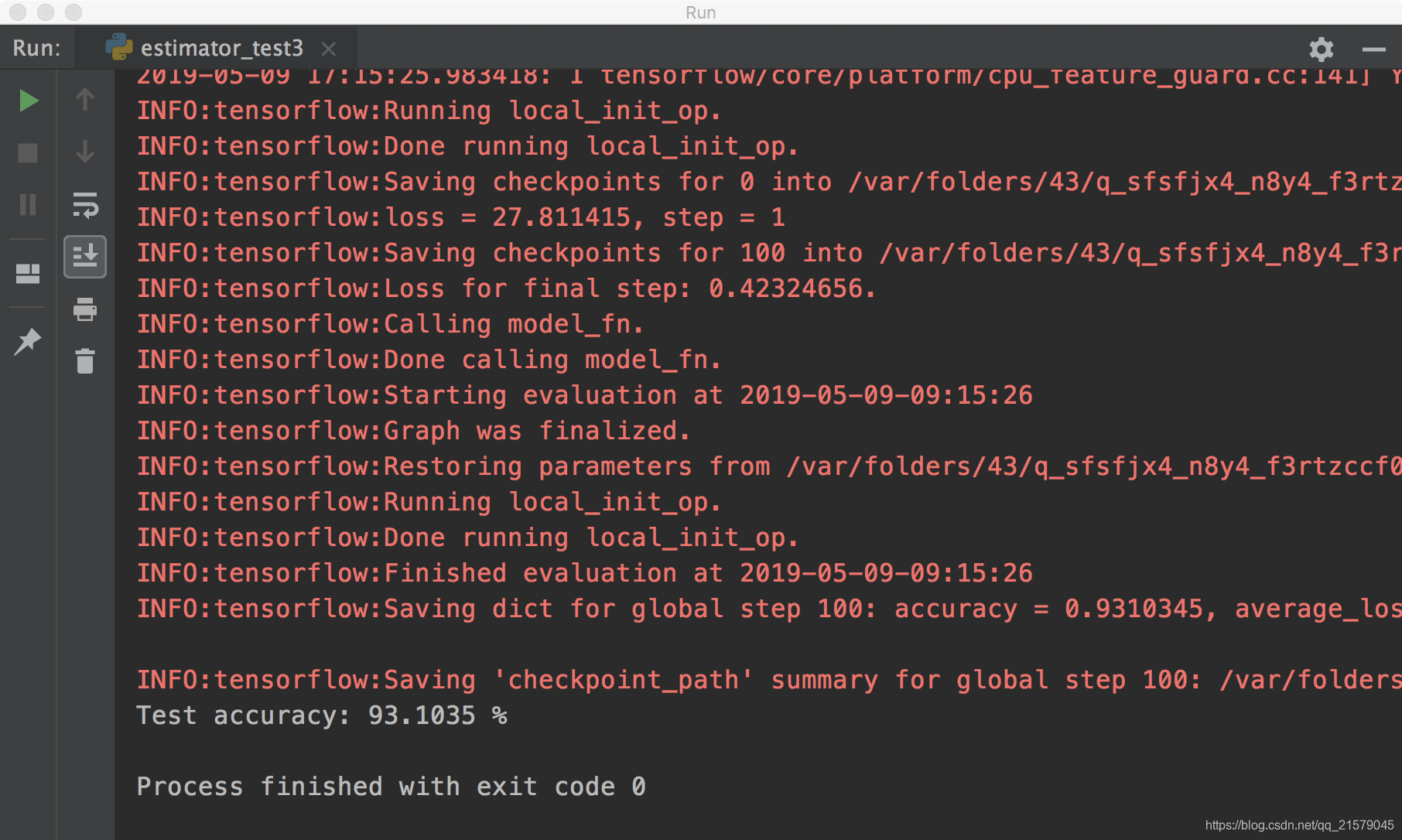
头就很疼。。。
4. 总结
要什么总结,不就是几种常见的TensorFlow高层封装嘛!包括TensorFlow-Slim、TFLearn、Keras和Estimator。反正就是结合起来,反正就是头疼。
我的CSDN:https://blog.csdn.net/qq_21579045
我的博客园:https://www.cnblogs.com/lyjun/
我的Github:https://github.com/TinyHandsome
纸上得来终觉浅,绝知此事要躬行~
欢迎大家过来OB~
by 李英俊小朋友
TensorFlow高层封装:从入门到喷这本书的更多相关文章
- 吴裕雄--天生自然TensorFlow高层封装:Estimator-自定义模型
# 1. 自定义模型并训练. import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist i ...
- 吴裕雄--天生自然TensorFlow高层封装:Estimator-DNNClassifier
# 1. 模型定义. import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist impor ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-TensorFlow API
# 1. 模型定义. import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist_ ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-多输入输出
# 1. 数据预处理. import keras from keras.models import Model from keras.datasets import mnist from keras. ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-返回值
# 1. 数据预处理. import keras from keras.models import Model from keras.datasets import mnist from keras. ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-CNN
# 1. 数据预处理 import keras from keras import backend as K from keras.datasets import mnist from keras.m ...
- 吴裕雄--天生自然TensorFlow高层封装:使用TensorFlow-Slim处理MNIST数据集实现LeNet-5模型
# 1. 通过TensorFlow-Slim定义卷机神经网络 import numpy as np import tensorflow as tf import tensorflow.contrib. ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-RNN
# 1. 数据预处理. from keras.layers import LSTM from keras.datasets import imdb from keras.models import S ...
- 吴裕雄--天生自然TensorFlow高层封装:解决ImportError: cannot import name 'tf_utils'
将原来版本的keras卸载了,再安装2.1.5版本的keras就可以了.
随机推荐
- POJ题目算法分类总结博客地址
http://blog.csdn.net/sunbaigui/article/details/4421705 又从这个地址找了一些:http://blog.csdn.net/koudaidai/art ...
- BZOJ 1604 [Usaco2008 Open]Cow Neighborhoods 奶牛的邻居:队列 + multiset + 并查集【曼哈顿距离变形】
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1604 题意: 平面直角坐标系中,有n个点(n <= 100000,坐标范围10^9) ...
- MongoDB 使用经验笔记
bin下的mongod就是MongoDB的服务端进程,mongo就是其客户端,其它的命令用于MongoDB的其它用途如MongoDB文件导出等 启动方式: 1.直接启动,指定各项参数: /usr/lo ...
- Hover show tips
像上面这种效果,hover1时显示2,且1和2有一定间距的东东,一般有两种实现办法: 1.用JS,原理:over1时让2显示,out1时开个定时器延迟500ms再消失,over2时清除定时器,out2 ...
- Codeforces 755B. PolandBall and Game 贪心
题目大意: 有两个人轮流说单词,已经说过的单词不能再说.给出两人掌握的不同的单词,两人可能掌握相同的单词,但是这个单词也只能说一边.问在两人都是最优策略下先手是否必胜. 题解: 我们发现最优策略一定是 ...
- Set_ML
参考资料:斯坦福(http://cs231n.github.io/linear-classify/:http://cs231n.stanford.edu/slides/2017/) Mastering ...
- poj1456Supermarket——并查集压缩查找
题目:http://poj.org/problem?id=1456 排序+贪心,每次选利润最大的,放在可能的最靠后的日期卖出,利用并查集快速找到下一个符合的日期. 代码如下: #include< ...
- jdk、tomcat如何配置环境变量
一.安装JDK和Tomcat 1,安装JDK:直接运行jdk-7-windows-i586.exe可执行程序,默认安装即可. 备注:路径可以其他盘符,不建议路径包含中文名及特殊符号. 2.安装Tomc ...
- .NETFramework-Web.Services:WebMethodAttribute
ylbtech-.NETFramework-Web.Services:WebMethodAttribute 1.程序集 System.Web.Services, Version=4.0.0.0, Cu ...
- qt 安装编译
项目编译的时候提示 cannot find -lGL sudo apt-get install libgl1-mesa-dev