SparkStreaming和Kafka的整合
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。需要满足以下几个先决条件:
1、输入的数据来自可靠的数据源和可靠的接收器;
2、应用程序的metadata被application的driver持久化了(checkpointed );
3、启用了WAL特性(Write ahead log)。
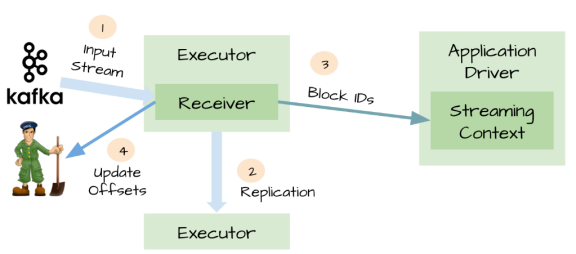
1. 可靠的数据源和可靠的接收器
可以从接收器挂掉的情况下恢复(或者是接收器运行的Exectuor和服务器挂掉都可以)
对于一些输入数据源(比如Kafka),Spark Streaming可以对已经接收的数据进行确认。输入的数据首先被接收器(receivers )所接收,
然后存储到Spark中(默认情况下,数据保存到2个执行器中以便进行容错)。数据一旦存储到Spark中,接收器可以对它进行确认
(比如,如果消费Kafka里面的数据时可以更新Zookeeper里面的偏移量)。
这种机制保证了在接收器突然挂掉的情况下也不会丢失数据:
因为数据虽然被接收,但是没有被持久化的情况下是不会发送确认消息的。所以在接收器恢复的时候,数据可以被原端重新发送。
2. 元数据持久化(Metadata checkpointing)
对应用程序的元数据进行Checkpint,Driver可以将应用程序的重要元数据持久化到可靠的存储中(如HDFS)
然后Driver可以利用这些持久化的数据进行恢复。元数据包括:
1、配置;
2、代码;
3、那些在队列中还没有处理的batch(仅仅保存元数据,而不是这些batch中的数据)
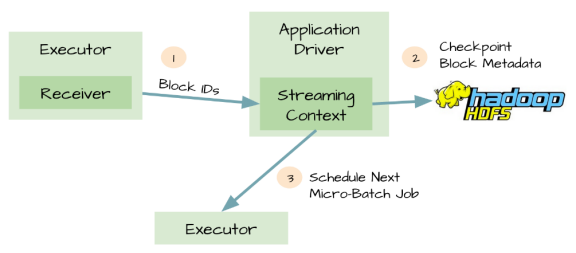
由于有了元数据的Checkpint,所以Driver可以利用他们重构应用程序,而且可以计算出Driver挂掉的时候应用程序执行到什么位置。
3. 可能存在数据丢失的场景
1、两个Exectuor已经从接收器中接收到输入数据,并将它缓存到Exectuor的内存中;
2、接收器通知输入源数据已经接收;
3、Exectuor根据应用程序的代码开始处理已经缓存的数据;
4、这时候Driver突然挂掉了;
5、从设计的角度看,一旦Driver挂掉之后,它维护的Exectuor也将全部被kill;
6、既然所有的Exectuor被kill了,所以缓存到它们内存中的数据也将被丢失。结果,这些已经通知数据源但是还没有处理的缓存数据就丢失了;
7、缓存的时候不可能恢复,因为它们是缓存在Exectuor的内存中,所以数据被丢失了。
4.WAL(Write ahead log)
针对上面情况,Spark Streaming 1.2开始引入了WAL机制。
启用了WAL机制,所以已经接收的数据被接收器写入到容错存储中(如HDFS),Driver可以从失败的点重新读取数据,即使Exectuor中内存的数据已经丢失了
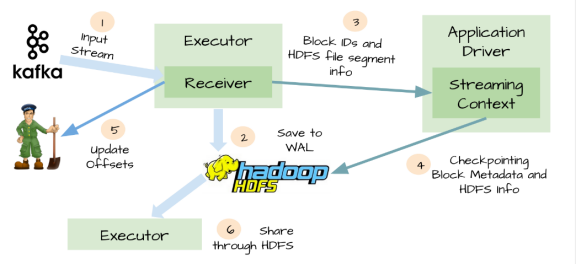
WAL虽然可以办证数据不丢失,但不能保证对数据源exactly-once语义,只读一次数据:
接收器接收数据并存储在WAL中,开始消费数据,在接收器向zookeeper更新偏移量之前,Executor挂掉了,
等Executor恢复会重新读取那些保存到WAL中但未被消费的数据,当从WAL读取完数据后,又开始消费数据,
因为接收器是采用Kafka的High-Level Consumer API实现的,它开始从Zookeeper当前记录的偏移量开始读取数据,
由于Zookeeper的偏移量没有更新,所以有些数据回被重复消费
WAL的缺点:
1、WAL减少了接收器的吞吐量,因为接受到的数据必须保存到可靠的分布式文件系统中。
2、对于一些输入源来说,它会重复相同的数据。比如当从Kafka中读取数据,你需要在Kafka的brokers中保存一份数据,而且你还得在Spark Streaming中保存一份。
5. Kafka direct API
为了解决由WAL引入的性能损失,并且保证 exactly-once 语义,Spark Streaming 1.3中引入了名为Kafka direct API。
Spark driver只需要简单地计算下一个batch需要处理Kafka中偏移量的范围,然后命令Spark Exectuor直接从Kafka相应Topic的分区中消费数据。
换句话说,这种方法把Kafka当作成一个文件系统,然后像读文件一样来消费Topic中的数据。
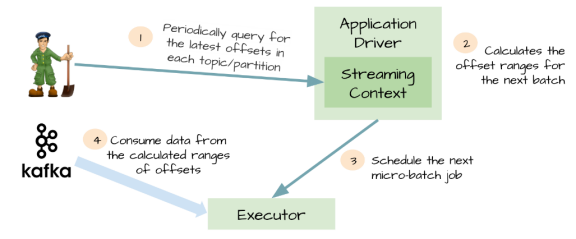
优点:
1、不再需要Kafka接收器,Exectuor直接采用Simple Consumer API从Kafka中消费数据。
2、不再需要WAL机制,我们仍然可以从失败恢复之后从Kafka中重新消费数据;
3、exactly-once语义得以保存,我们不再从WAL中读取重复的数据。
SparkStreaming和Kafka的整合的更多相关文章
- 图解SparkStreaming与Kafka的整合,这些细节大家要注意!
前言 老刘是一名即将找工作的研二学生,写博客一方面是复习总结大数据开发的知识点,一方面是希望帮助更多自学的小伙伴.由于老刘是自学大数据开发,肯定会存在一些不足,还希望大家能够批评指正,让我们一起进步! ...
- 【Spark】SparkStreaming和Kafka的整合
文章目录 Streaming和Kafka整合 概述 使用0.8版本下Receiver DStream接收数据进行消费 步骤 一.启动Kafka集群 二.创建maven工程,导入jar包 三.创建一个k ...
- SparkStreaming和Kafka基于Direct Approach如何管理offset实现exactly once
在之前的文章<解析SparkStreaming和Kafka集成的两种方式>中已详细介绍SparkStreaming和Kafka集成主要有Receiver based Approach和Di ...
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- Flume+Kafka+Storm整合
Flume+Kafka+Storm整合 1. 需求: 有一个客户端Client可以产生日志信息,我们需要通过Flume获取日志信息,再把该日志信息放入到Kafka的一个Topic:flume-to-k ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- sparkStreaming 读kafka的数据
目标:sparkStreaming每2s中读取一次kafka中的数据,进行单词计数. topic:topic1 broker list:192.168.1.126:9092,192.168.1.127 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- 第1节 kafka消息队列:10、flume与kafka的整合使用
11.flume与kafka的整合 实现flume监控某个目录下面的所有文件,然后将文件收集发送到kafka消息系统中 第一步:flume下载地址 http://archive.cloudera.co ...
随机推荐
- 零基础逆向工程32_Win32_06_通用控件_VM_NOTIFY
标准控件与可用控件 windows标准控件,标准控件总是可用的 Static Group Box Button Check Box Radio Button Edit ComboBox ListBox ...
- Python开发环境Wing IDE如何进行命令行调试
Wing IDE专业的调试探针提供了一种强大的方法来发现和解决复杂的错误.这很像Python Shell但允许用户直接参与进已经暂停的调试程序中: 通过键入在刚才发生异常的地方键入下列数值进行尝试: ...
- 【C++】【MFC】创建新的线程函数
DWORD WINAPI MyThreadProc (LPVOID lpParam){ somestruct* pN = (somestruct*)lpParam; // 将参数转为你的类型 ... ...
- 微信jssdk实现分享到微信
本来用的是这个插件http://overtrue.me/share.js/和百度分享 相同之处:在微信分享的时候,分享的链接都不能获取到缩略图... 不同之处:百度分享在微信低版本是可以看到缩略图的( ...
- C语言标准库之setjmp
协程的介绍 协程(coroutine),意思就是“协作的例程”(co-operative routines),最早由Melvin Conway在1963年提出并实现.跟主流程序语言中的线程不一样,线程 ...
- constraint的一些用法总结
主要就是增加约束的 以下几种约束 .并 一一列举: 1.主键约束: 要对一个列加主键约束的话,这列就必须要满足的条件就是分空 因为主键约束:就是对一个列进行了约束,约束为(非空.不重复) 以下是代码 ...
- 【BZOJ4698】[SDOI2008] Sandy的卡片(后缀数组+二分)
点此看题面 大致题意: 给你\(N\)个序列,若定义两个相同子串为一个子串内所有数加上一个数后能变成另一个串,求所有序列中的最长相同子串的长度. 简单的转化 首先,我们对题目进行一个简单的转化. 要求 ...
- 2017.12.13 Java中是怎样通过类名,创建一个这个类的数组
先在类方法中定义数组的方法: public int[] method6(int[] arr){ for(int i = 0; i<arr.length;i++){ arr[i] = (int)( ...
- 为什么L1稀疏,L2平滑?
使用机器学习方法解决实际问题时,我们通常要用L1或L2范数做正则化(regularization),从而限制权值大小,减少过拟合风险.特别是在使用梯度下降来做目标函数优化时,很常见的说法是, L1正 ...
- python_25_string
name="my name is 齐志光qizhiguang" print(name.capitalize())#首字母变大写 print(name.count('i'))#统计字 ...