Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求。
一、headers的获取
就以博客园的首页为例:http://www.cnblogs.com/
打开网页,按下F12键,如下图所示:
点击下方标签中的Network,如下:
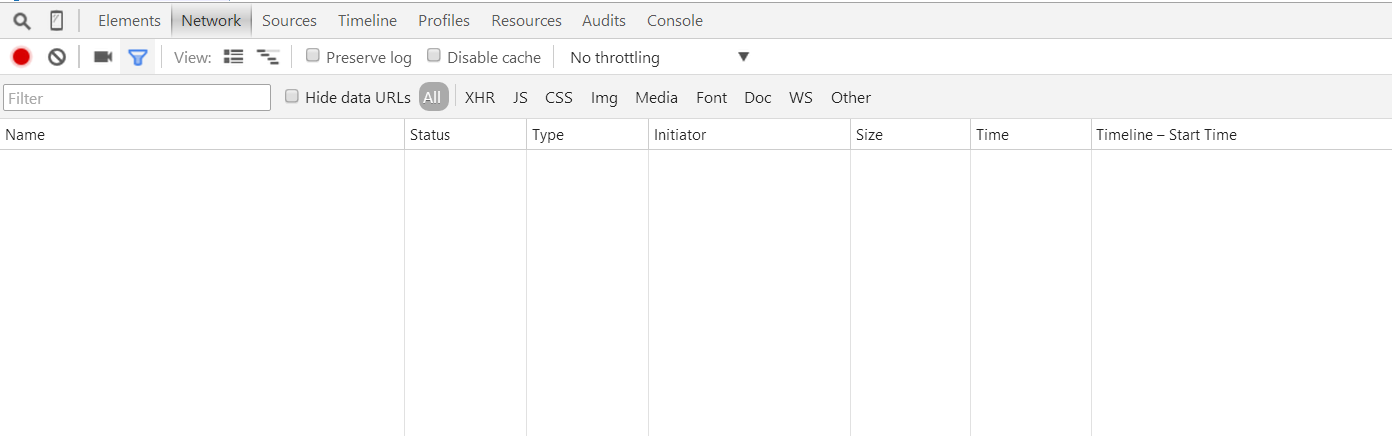
之后再点击下图所示位置:
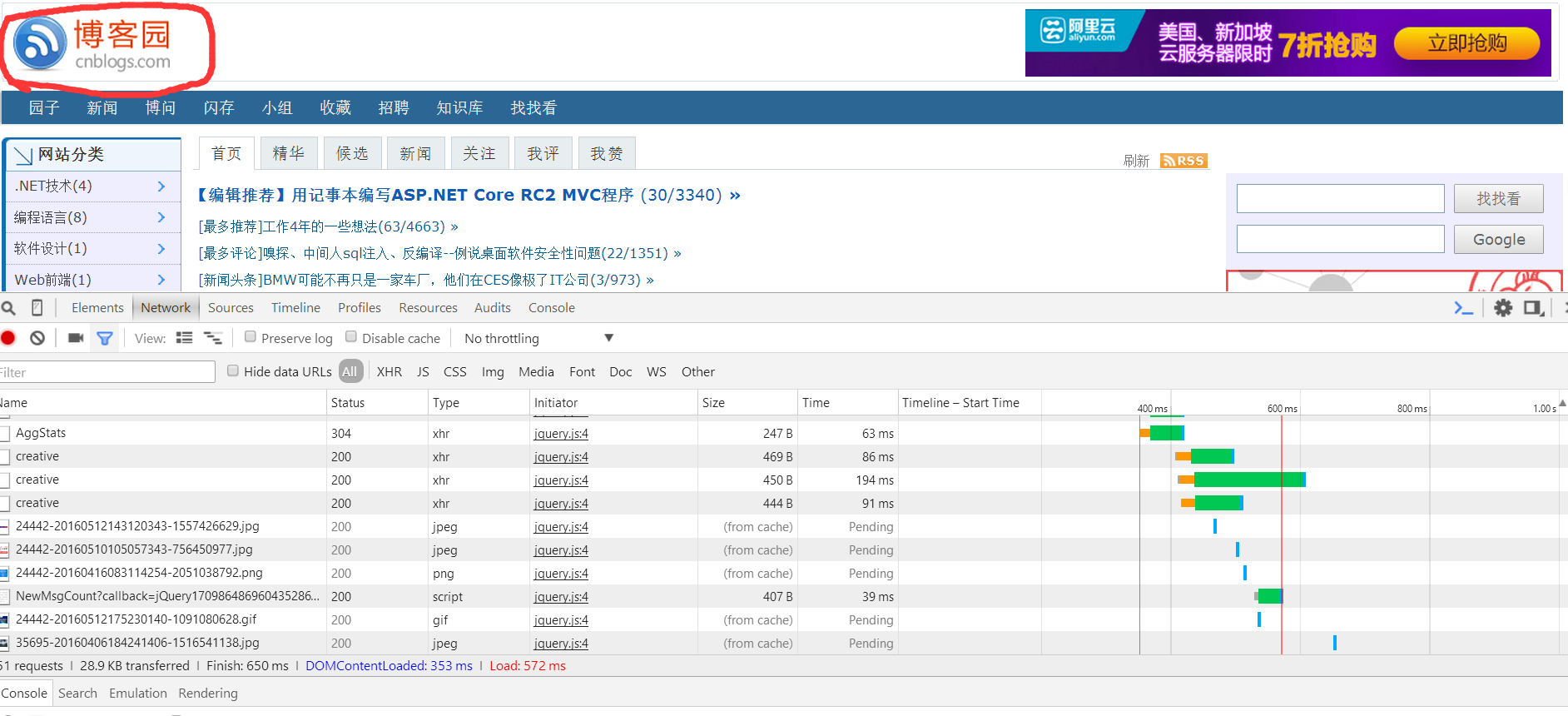
找到红色下划线位置所示的标签并点击,在右边的显示内容中可以查看到所需要的headers信息。
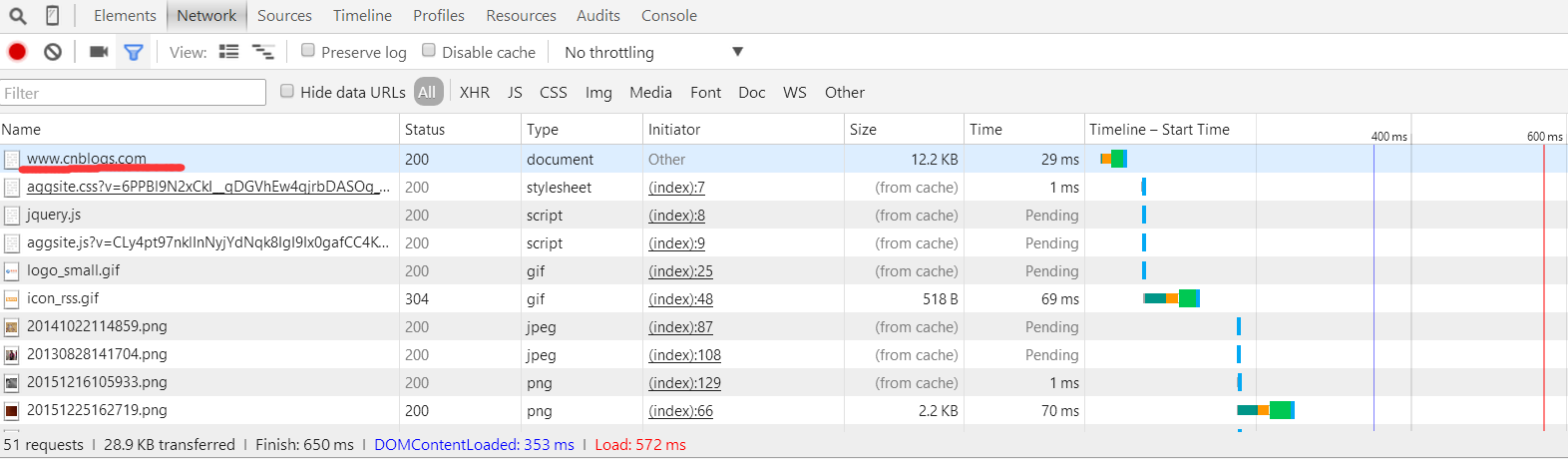
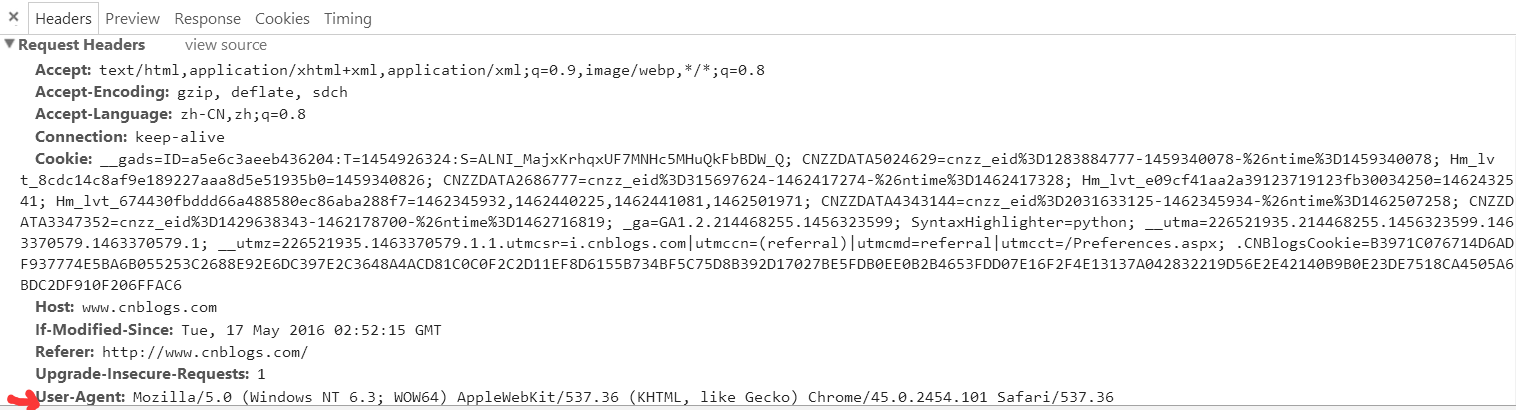
一般只需要添加User-Agent这一信息就足够了,headers同样也是字典类型;
user_agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
headers = { 'User-Agent' : user_agent }
二、data获取
以博客园登录界面为例:http://passport.cnblogs.com/user/signin?ReturnUrl=http%3A%2F%2Fwww.cnblogs.com%2F
按下F12键,如下图所示:
点击Network,然后随意输入用户名和密码,点击登录可以看到如下图所示:

博客园登录的data信息:
data={
input1:"*******",
input2:"*******",
remember:"false"
}
以电驴下载网站为例:http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/
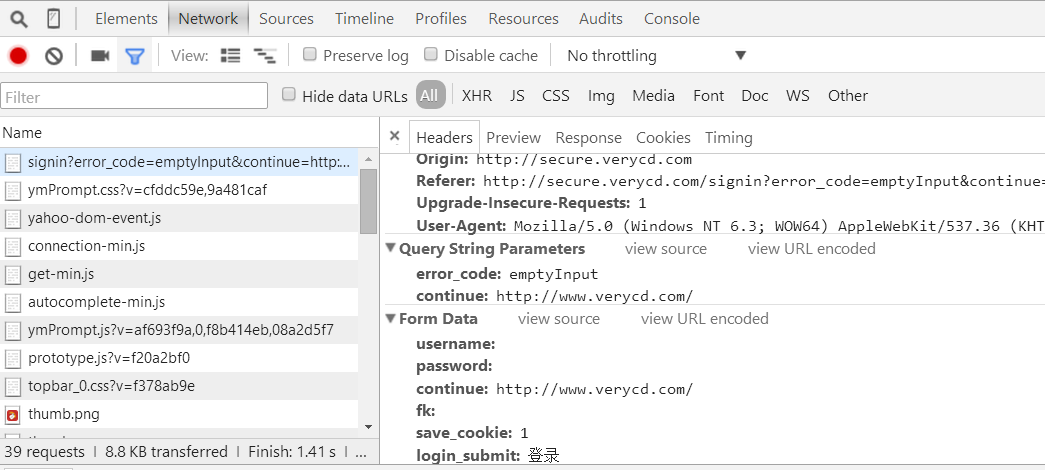
data信息在From Data标签中:
data={
username:"****",
password:"****",
continue:"http://www.verycd.com/"
fk:" ",
save_cookie:1,
login_submit:"登录"
}
每一个登录网站的data信息不一定一样,都需要进入网页确定。
好啦,今天就到这了~明天介绍一个实例:如何爬取糗百的段子。
转载时注明原作者出处:Maple2cat|Python爬虫学习:四、headers和data的获取
Python爬虫学习:四、headers和data的获取的更多相关文章
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
随机推荐
- 关于sublime3的配置笔记
1.安装的插件有Anaconda, GitGutter, SublimeCodeIntel Anaconda会有长度超过80警报的问题, 影响写代码的时候的判断, 所以将Preferences/Pac ...
- 字典:当索引不好用时2 - 零基础入门学习Python026
字典:当索引不好用时2 让编程改变世界 Change the world by program 上节课我们学习到在一些情况下,比序列更实用的映射类型:字典.我们知道字典也有个关键符号就是大括号(也叫花 ...
- IC封装图片认识(一):BGA
在上篇文章<常用IC封装技术介绍>第一个提到的IC封装形式就是BGA,全称是Ball Grid Array(球栅阵列结构的PCB),它是集成电路采用有机载板的一种封装法.其具有以下五个特点 ...
- Send竞争对手:百度云一小时,QQ超大附件最多支持2G,邮件附件20M到50M不等(附国外所有storage列表)——痛点是,最大传输2G,最大容量只有3G(和微云不是一回事),转存到微云文件不能超过1G
QQ邮箱最大可发送50M普通附件(群邮件则限制在2M).此外也可以使用超大附件功能,支持将1G的文件发往任意邮箱.QQ邮箱根据你的QQ邮箱容量的不同制定相应的接受附件限制,包括附件在内,2G用户所发送 ...
- PowerShell因为在此系统中禁止执行脚本解决方法
PowerShell因为在此系统中禁止执行脚本解决方法 在Powershell直接脚本时会出现: 无法加载文件 ******.ps1,因为在此系统中禁止执行脚本.有关详细信息,请参阅 " ...
- cmake编译(编译目标)x86或x64
if(CMAKE_CL_64) #CMAKE的内建变量,如果是true,就说明编译器的64位的,自然可以编译64bit的程序 set(ADDRESS_MODEL 64) set(NODE_TAR ...
- 转:PHP变量作用域(花括号、global、闭包)
花括号 很多语言都以花括号作为作用域界限,PHP中只有函数的花括号才构成新的作用域. 01 <?php 02 if (True) { 03 $a = 'var a'; 04 } 05 ...
- unix c 03
C程序员的错误处理 errno/perror/strerror 都是系统设计好的 自定义函数中的错误处理 1 可以返回-1 代表错误 2 指针类型可以用 NULL 代表错误 ...
- OSCLI
- Ajax 获取数据代码
无刷新获取字符串: Html网页中: <script> //定义异步对象 var xmlHttp; //封装方法 function CreateXMLHTTP() { try { xmlH ...