AI框架中图层IR的分析
摘要:本文重点分析一下AI框架对IR有什么特殊的需求、业界有什么样的方案以及MindSpore的一些思考。
本文分享自华为云社区《MindSpore技术专栏 | AI框架中图层IR的分析》,原文作者:元气满满的少女月 。
IR(Intermediate Representation即中间表示)是程序编译过程中,源代码与目标代码之间翻译的中介,IR的设计对编译器来说非常关键,好的IR要考虑从源代码到目标代码编译的完备性、编译优化的易用性和性能。而AI框架本质的作用又是什么呢?AI框架本质的作用在于把一个把用户的模型表达翻译到可执行的代码,然后进行高效执行(训练和推理),其中从用户的模型表达(例如深度神经网络)到最后可执行的代码就是个编译器的行为,这个编译器也有一个IR,它的设计对AI框架的完备性/灵活性/易用性/性能都起到至关重要的作用。
本文重点分析一下AI框架对IR有什么特殊的需求、业界有什么样的方案以及MindSpore的一些思考。首先带大家了解下通用的编译器IR的分类以及各自特点。
业界IR的介绍
一、IR根据其组织结构[1],可以分为:Linear IR(线性IR)、Graphical IR(图IR)、Hybrid IR(混合IR),其中
- Linear IR(线性IR):
类似某些抽象机的伪代码,对应的算法通过迭代来遍历简单的线性操作序列
- Hybrid IR(混合IR):
结合了图IR和线性IR的要素。一种常见的混合IR使用底层的线性IR来表示无循环代码块,使用图IR来表示这些块之间的控制流
- Graphical IR(图IR):
将编译过程的知识/信息保存在图中,对应的算法通过对图中的对象(节点、边、列表和树)操作来描述
线性IR的一个例子是堆栈机代码(Stack-Machine Code),它是一种单地址代码,假定操作数存在一个栈中。大多数操作从栈获得操作数,并将其结果推入栈中。例如:表达式 b-a*3对应的堆栈机代码如下:
- push 3
- push a
- multiply
- push a
- substract
LLVM IR是一个典型的混合IR,它包含了两个层次(CFG+BB):
顶层是控制流图(Control Flow Graph,简写为CFG),来表示基本块(Basic Block,简写为BB)间的控制流。CFG的每个节点(Node)为一个基本块,基本块b1和b2之间有一条边(Edge):b1->b2,如果控制流可能从基本块b1的最后一条指令流向基本块b2的第一条指令
底层是基本块,在基本块中,每条指令是以SSA(Static Single Assignment)形式呈现,这些指令构成一个指令线性列表
Sea of Nodes IR(by Cliff Click)是一种典型的图IR[2],在这种IR中,简化了CFG图中BB+SSA指令的两层结构,去除了BB,剩下只包含指令的一层结构。它通过引入了特殊的REGION、IF、PROJECTION指令,将BB块中的全序指令放松为显式的数据依赖和控制依赖,并且对控制依赖和数据依赖采用相同的表示方式和处理方式,这样就简化了IR的分析和变换。如下为一个简单的IR示例:
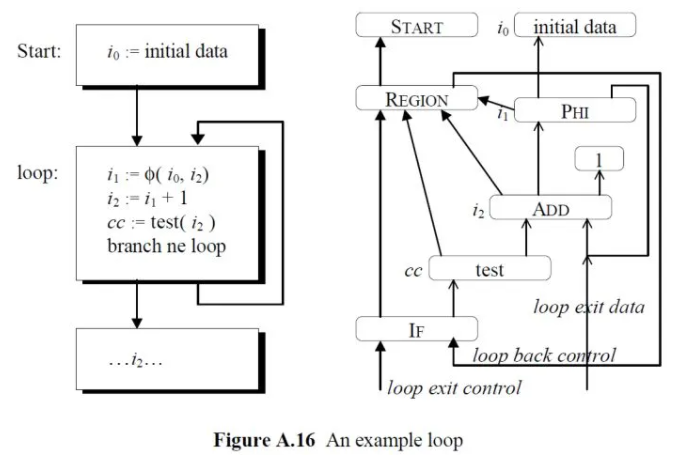
在这个示例中,方框为图的节点,表示SSA指令,箭头为图的边;实心箭头表示控制依赖;空心箭头表示数据依赖。从这个示例中可以看到此IR中显式的包含了use-def依赖,不需要进行额外的计算。
基于此IR中显式的use-def信息,可以方便的实现两类优化:Parse time优化(Pessimistic)全局优化(Optimistic)
在Parse的时候,由于还没有程序的全部信息,所以只可做局部的优化,如窥孔优化(例:常量折叠,Identity-function)。通过设计合适的类及继承体系,可以使用简单的算法实现peephole优化:

对于全局优化,比如Sparse Conditional Constant Propagation(SCCP),也可以很简单的实现;首先是基于图中显式的use-def计算出def-use chains,然后可以很容易的实现SCCPSea of Nodes IR提供了一种非常重要的思路:将依赖信息显式的表示在图IR中。FIRM IR中延续了这个思路
二、从常用编程语言的角度来分析IR,我们又可以看到IR的形式分为了两个不同的阵营:一类是命令式编程语言的编译器IR,另外一类是函数编程语言的编译器IR命令式编程语言的编译器IR以SSA为基本的组成形式,这里就不在赘述了,下面重点介绍一下函数式编程语言的IR,在函数式编程语言的IR中,CPS或者ANF是其基本的组成形式1. Continuation-passing style(CPS)直译为:连续传递风格CPS 表示这样一种形式:一个函数 f 除了它自身的参数外,总是有一个额外的参数continuationcontinuation也是一个函数,当f完成了自己的返回值计算之后,不是返回,而是将此返回值作为continuation的参数,调用continuation。所以CPS形式的函数从形式上看它不会return,当它要return 的时候会将所有的参数传递给continuation,让continuation继续去执行。比如:
- def foo(x):
- return x+1
转换为CPS形式,k就是一个continuation:
- def foo(x,k):
- k(x+1)
直观上看,函数不“return”,而是“continue”CPS的优点是让如下的信息显式化:过程返回(调用一个continuation),中间值(具有显式的名称),求值顺序,尾调用(采用相同的continuation调用一个过程)比如如下的一段python代码,求小于n的所有素数的积。
- def prodprimes(n):
- if n == 1:
- return 1
- if isprime(n):
- return n * prodprimes(n - 1)
- return prodprimes(n - 1)
当采用CPS形式表示时:
- def prodprimes(n, c):
- def k(b):
- if b == True:
- m = n - 1
- def j(p):
- a = n * p
- c(a)
- prodprimes(m, j)
- else:
- def h(q):
- c(q)
- i = n - 1
- prodprimes(i, h)
- if n == 1:
- c(1)
- else:
- isprime(n, k)
从上面的代码中可以看到,“过程返回”都被调用c、j、k、h等continuation代替;中间值a、b、m、i都被给予了变量名称。CPS形式非常适合编译器进行分析和变换,比如tail-recursion elimination变换:如果函数f的最后是调用函数g,那么函数g的continuation就不需要是在f内生成的一个continuation,而可以被替换为传递给f的continuation。上面的例子的原始代码中,“return prodprimes(n - 1)”语句就是一个尾递归在CPS形式中,可以很清楚的看到h(q)的定义其实就等于c(q),所以可以说h等于c,于是可以进行如下的变换[3]:
- def h(q): i = n - 1
- c(q) -> prodprimes(i, c)
- i = n - 1
- prodprimes(i, h)
虽然CPS非常一致和强大,但是它的一个很大问题是难以阅读。所以出现了A-norm Form(ANF)形式2. ANF形式直接对Direct Style的源码进行转换[4],不需要经过CPS形式
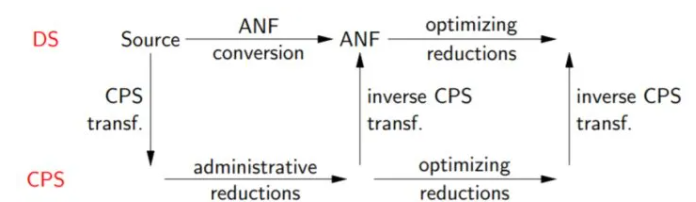
ANF形式将表达式划分为两类:原子表达式和复合表达式。
原子表达式表示一个常数值或一个变量或一个原语或一个匿名函数复合表达式由多个原子表达式复合组成,可以看成是一个匿名函数或原语函数调用,组合的第一个输入是调用的函数,其余输入是调用的参数。一个复合表达式要么被let-bound到一个变量,要么只能出现在最后的位置可以看到,ANF形式通过let-bound,显式表达了中间值和控制流及求值顺序它的文法定义如下[5]
- <aexp> ::= NUMBER | STRING | VAR | BOOLEAN | PRIMOP
- | (lambda (VAR …) <exp>)
- <cexp> ::= (<aexp> <aexp> …)
- | (if <aexp> <exp> <exp>)
- <exp> ::= (let ([VAR <cexp>]) <exp>) | <cexp> | <aexp>
例如上面的prodprimes函数,如果用上述的文法表示,应该为:
- (define prodprimes
- (lambda (n)
- (let (a (= n 1))
- (if a 1 (let (b isprime(n))
- (if b (let (m (- n 1))
- (let (p (prodprimes m))
- (* n p)))
- (let (s (- n 1))
- (prodprimes m))
- ))))))
这段ANF形式表达,如果翻译为python,应该类似于:
- def prodprimes(n):
- r = n == 1
- if r:
- return 1
- b = isprime(n)
- if b:
- m = n - 1
- p = prodprimes(m)
- return n * p
- s = n - 1
- return prodprimes(s)
通过这段代码,也可以看出,ANF形式比CPS形式简单易懂
AI 框架中图层IR的作用
现在主流的AI框架都有图层IR,好的图层IR有利于AI模型的编译优化和执行,是AI框架进行高效训练和推理的基础从训练的角度看,目前业界的AI框架有三种执行模式:Eager执行模式、图执行模式和Staging(混合)执行模式,其中高性能模式下(Graph执行模式和Staging执行模式)都要基于图层IR:Eager执行模式一般是利用宿主语言(现在主要是Python)的特性进行解释执行,里面使用了重载和Tape的一些技巧。
Graph执行模式主要是拿到AI模型的图结构,然后进行编译优化和执行,这里的编译优化和执行就要基于图IR,现在有三种方法拿到AI模型的图结构:第一种是程序员使用API构图(TF1.x版本等)第二种是Tracing JIT(JAX带来的潮流,现在TF2.0/Pytorch等都支持)即把用户的模型脚本模拟跑一下,拿到正向的执行序列,然后基于这个序列进行构图好处是与Eagle模式比较容易匹配,实现简单缺点是控制流的转换比较麻烦、执行序列如果与算子执行结果相关的话不好实现、不容易处理副作用所以TF的AutoGraph还需要结合AST分析解决控制流转换的问题第三种是AST JIT(Pytorch的TorchScript)基于Python的AST进行构图,优点是转换的功能可以比较全面,包括控制流等,缺点是实现复杂,许多Python动态特性实现起来工作量大
Staging执行模式类似在Eager模式中,通过Python修饰符,对部分子图进行编译执行加速(使用Tracing JIT或者AST JIT),也会用到图IR。
从推理的角度看,AI框架生成最终的推理模型时需要进行大量的编译优化,如量化、剪枝等,一般都在图层IR上进行,同时最终的推理模型格式也是直接或者间接使用到图层IRAI框架图层IR的需求和挑战与其他通用的IR相比,AI框架的图层IR有一些比较特殊的需求和挑战:
张量表达:AI的模型主要处理的是张量数据,这个与普通的应用差别是比较大的,不过增加张量数据类型对编译器的IR来说并不是件困难的事情。
自动微分:可微分是AI模型开发与一般应用开发区别最大的地方,现代的AI框架都会提供自动微分的功能,挑战在于实现的简洁性、性能以及未来高阶微分的扩展能力
JIT能力:无论是图模式还是Staging模式,从算法工程师角度看,由于没有显示编译的步骤,都可以认为是JIT方式。对于JIT来说,编译性能是一个主要挑战
隐式并行:从开发者来说,有两种并行方式一种是是显式并行,开发者明确告诉系统哪里并行,比如显示启动多线程/添加
并行修饰符:还有一种方式是隐式并行,通过编译器来分析依赖,自动实现并行一般而言,传统的CFG+BB的编译器,由于程序分析使用全序分析,方便做显式并行;函数式的编译器理论上易于数据依赖分析,方便进行隐式并行优化。有趣的是,在深度学习场景中,Kernel执行占了大部分开销,在运行时实现异步并发的模式也可以显著提升整体性能,隐式并行的作用相对会被弱化,但是想要实现极致性能,隐式并行还是有作用的
Loop优化:AI的计算涉及大量的Tensor运算,对编译器来说就是Loop优化(张量—>标量—>向量化),不过这个挑战主要还是在算子层的IR上当然,图层IR也是是一种编译器IR,应该具备通用性,包括类型系统、控制流和数据流分析、副作用消除等基本的功能
业界在图层IR上的一些流派
计算图的IR:一种以DAG为中心的实现方式,许多早期的框架都是使用了这种方案计算图的IR的设计比较自然,计算图主要由边和节点组成,节点一般用来表达算子、变量、常量等等;边对应于Tensors,实际上表达了一种数据依赖关系。后面的自动微分和优化都是基于这个DAG进行这个方案的优点是简单直观、优化时的性能开销小不足之处是计算图IR不算是真正形式化的编译器IR,在类型系统、复杂逻辑的支持(比如递归)、副作用处理、控制流和数据流分析方面支持不完整
CFG+BB:基于传统编译器的IR来做图层IR,比如TorchScript、Julia等如何实现自动微分?我们以Julia Zygote为例[6]:对于BB块内的普通代码(非phi,非branch),借助链式法则,可以按照反向的顺序生成AD代码

将上述的表达式表示为SSA后,并插入J及计算AD,可以得到如下图表示的伪SSA代码:

上图中的 %6 这里节点称为“alpha node”,对应的是Primal中的节点%6,也就是上面一排的B3,“/”operation的反向函数
对于CFG间的控制流,需要对控制流进行反向分析,并在Primal CFG中插入适当的哑phi节点来记录和回放控制流。例如这一段计算power的代码:

对应的 Primal CFG中,插入了 %1 phi节点作为哑phi节点来记录控制流。然后在AD CFG中使用此 %1 来进行控制(%1记录通过入栈控制流,然后在AD CFG中通过出栈来回放控制流)

通过后续的代码优化,AD的Power代码类似如下的伪代码:

可以看出,CFG+BB的自动微分最终是通过迭代的方式来实现的,带Scope的SSA形式需要解决边界传递的问题对自动微分还是会带来一些处理上的麻烦
如何做图优化?转化成use-def、def-use的形式进行优化
如何做并行优化?由于CFG+BB是全序的方式,需要转换成use-def,并结合副作用信息进行分析
使用CFG+BB方案的好处是功能完备、方案成熟、重用性高,不过CFG+BB的形式对自动微分/图优化/并行优化来说,都要进行一定的转换工作,并不是那么直观和高效
函数式IR
使用函数式的IR来做图层IR,典型的如Relay、Myia等,如何实现自动微分?对于非控制流,计算AD的方法和上述的BB块内计算AD的方法相同。对于控制流,函数式IR采用了不同的处理方式,将迭代转换为递归,并且通过switch函数来进行分支的选择。例如上述相同的pow()函数:
- def pow(x, n):
- return header_pow(n, 1, x)
- def header_pow(phi_n, phi_r, x):
- def body_pow():
- phi_n_1 = phi_n - 1
- phi_r_1 = phi_r * x
- return header_pow(phi_n_1, phi_r_1, x)
- def after_pow():
- return phi_r
- f = switch(phi_n > 0, header_pow, after_pow)
- f()
以pow(5,3) 为例,其递归调用过程如下:
pow(5, 3) -> header_pow(3, 1, 5) -> body_pow() -> header_pow(2, 5, 5) -> body_pow() -> header_pow(1, 5*5, 5) -> body_pow -> header_pow(0, 5*5*5, 5) -> after_pow() (此时return 5*5*5)
可以看到,这里的递归调用的调用和返回分别就对应了上述CFG+BB的控制流phi节点入栈和出栈操作
由于AD过程就是对函数进行变换的过程,所以AD后的图也是递归调用的结构,因此不需要类似CFG+BB的控制流phi节点入栈和出栈操作,递归调用过程天然的就代替了入栈和出栈的过程
# 对x求导数
- def x_grad_pow(x, n):
- phi_n = n
- phi_r = 1
- return x_bprop_header_pow(phi_n, phi_r, x, 1)
- def x_bprop_header_pow(phi_n, phi_r, x, sens):
- def env_x_bprop_body_pow():
- %3 = x_bprop_header_pow(phi_n – 1, phi_r * phi_x, x, 1)
- %4 = phi_r_bprop_header_pow(phi_n – 1, phi_r * phi_x, x, 1)
- %5 = %4 * phi_r
- return %3 + %5
- def env_x_bprop_after_pow():
- return 0
- f = switch(phi_n > 0, env_x_bprop_body_pow, env_x_bprop_after_pow)
- r = switch(phi_n > 0, f(), 0)
- return r
- def phi_r_bprop_header_pow(phi_n, phi_r, x, sens):
- def env_phi_r_bprop_body_pow():
- %3 = phi_r_bprop_header_pow(phi_n - 1, phi_r * x, x, 1)
- %4 = %3 * x
- return %4
- def env_phi_r_bprop_after_pow():
- return 1
- if phi_n > 0:
- %5 = env_phi_r_bprop_body_pow()
- else:
- %5 = env_phi_r_bprop_after_pow()
- return %5
函数式IR的好处是对自动微分友好,比较适合做并行分析,不过挑战在于函数IR的副作用消除以及函数式IR在执行态的性能(含有递归对执行不友好)
Mindspore的设计思考
MindSpore的图层IR叫做MindIR,MindIR选择的技术路线是采用Functional Graph IR(参考了Sea of Nodes 、Thorin、Myia等),具有如下特征:
Functional以更自然的自动微分实现方式和更方便的隐式并行分析能力:函数作为一等公民,支持高阶函数,包括控制流也通过特殊的函数来实现,可以以统一的形式来实现微分函数以无副作用的方式实现,与命令式语言相比,可简化分析和实现更多的优化原生支持闭包,一方面可以方便的表达用户源代码中的闭包表示,另外也可以自然的支持自动微分算法中在反向函数中要访问原始函数的中间结果的要求:反向函数访问中间结果,并且作为一个闭包返回使用基于数据依赖的偏序分析,这样可以便于乱序或者并行执行
Graph based以更适合JIT的快速优化能力:采用类似Sea of Nodes IR的只有一层的表示方式,控制流和数据流合一,更适合JIT优化
ANF形式:和Thorin类似,都采用Graph IR,都消除了Scope。但是没有采用Thorin IR的CPS形式,而是表达能力类似,更直观也更易检查的ANF形式MindIR希望通过Functional的方式更方便的实现自动微分和隐式并行分析,Graph Based方式把控制流和数据流合一支持更高效的JIT优化。一、MindIR的详解[7]MindIR文法继承于ANF,其定义如下所示:
- <ANode> ::= <ValueNode> | <ParameterNode>
- <ParameterNode> ::= Parameter
- <ValueNode> ::= Scalar | Named | Tensor | Type | Shape
- | Primitive | MetaFuncGraph | FuncGraph
- <CNode> ::= (<AnfNode> …)
- <AnfNode> ::= <CNode> | <ANode>
MindIR中的ANode对应于ANF的原子表达式,ANode有两个子类分别为ValueNode和ParameterNodeValueNode表示常数节点可承载一个常数值(标量、符号、张量、类型、维度等),也可以是一个原语函数(Primitive)或一个元函数(MetaFuncGraph)或一个普通函数(FuncGraph),因为在函数式编程中函数定义本身也是一个值,ParameterNode是参数节点表示函数的形参MindIR中CNode对应于ANF的复合表达式,表示一次函数调用在MindSpore自动微分时,会计算ParameterNode和CNode的梯度贡献,并返回最终ParameterNode的梯度,而不计算ValueNode的梯度
下面以一段程序作为示例,对比理解MindIR
- def func(x, y):
- return x / y
- @ms_function
- def test_f(x, y):
- a = x - 1
- b = a + y
- c = b * func(a, b)
- return c
这段Python代码对应的ANF表达为:
- lambda (x, y)
- let a = x - 1 in
- let b = a + y in
- let func = lambda (x, y)
- let ret = x / y in
- ret end in
- let %1 = func(a, b) in
- let c = b * %1 in
- c end
对应的MindIR为:https://w.url.cn/s/Ansh1KW
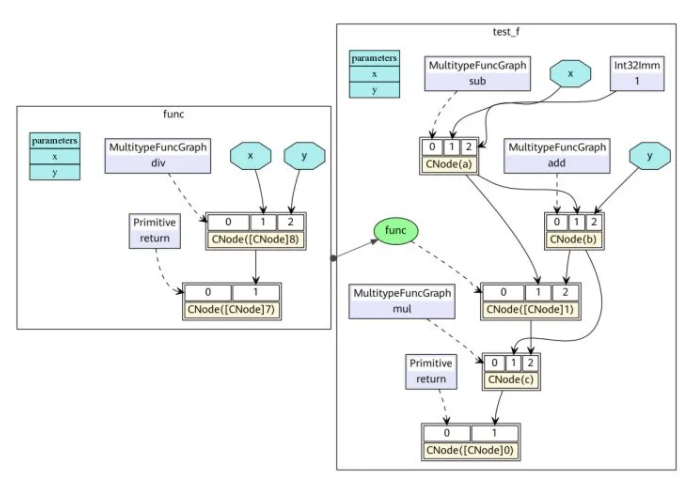
在MindIR中,一个函数图(FuncGraph)表示一个普通函数的定义,函数图一般由ParameterNode、ValueNode和CNode组成有向无环图,可以清晰地表达出从参数到返回值的计算过程在上图中可以看出,python代码中两个函数test_f和func转换成了两个函数图,其参数x和y转换为函数图的ParameterNode,每一个表达式转换为一个CNode。CNode的第一个输入链接着调用的函数,例如图中的add、func、return值得注意的是这些节点均是ValueNode,因为它们被理解为常数函数值。CNode的其他输入链接这调用的参数,参数值可以来自于ParameterNode、ValueNode和其他CNode。
在ANF中每个表达式都用let表达式绑定为一个变量,通过对变量的引用来表示对表达式输出的依赖,而在MindIR中每个表达式都绑定为一个节点,通过节点与节点之间的有向边表示依赖关系
函数式语义
MindIR较传统计算图的一个重要特性是不仅可以表达算子之间的数据依赖,还可以表达丰富的函数式语义
高阶函数
在MindIR中,函数的定义是由一个子图来定义,但其本身可以是一个被传递的值,作为其他高阶函数的输入或输出。例如下面一个简单的示例中,函数f作为参数传入了函数g,因此函数g是一个接收函数输入的高阶函数,函数f真正的调用点是在函数g内部
- @ms_function
- def hof(x):
- def f(x):
- return x + 3
- def g(function, x):
- return function(x) * function(x)
- res = g(f, x)
- return res
对应的MindIR为:https://w.url.cn/s/A8vb8X3
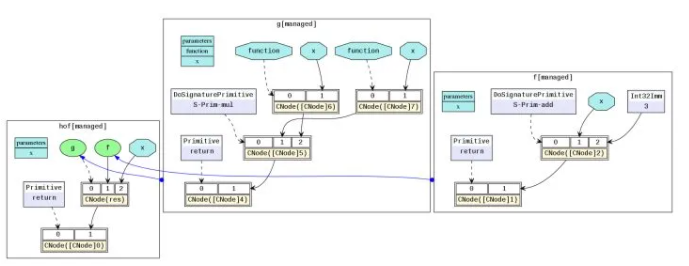
在实际网络训练脚本中,自动求导泛函GradOperation和优化器中常用到的Partial和HyperMap都是典型的高阶函数。高阶语义极大地提升了MindSpore表达的灵活性和简洁性
控制流
控制流在MindIR中是以高阶函数选择调用的形式表达。这样的形式把控制流转换为高阶函数的数据流,从而使得自动微分算法更加强大。不仅可以支持数据流的自动微分,还可以支持条件跳转、循环和递归等控制流的自动微分。下面以一个简单的斐波那契用例来演示说明
- @ms_function
- def fibonacci(n):
- if(n < 1):
- return 0
- elif(n == 1):
- return 1
- else:
- return fibonacci(n-1) + fibonacci(n-2)
对应的MindIR为:https://w.url.cn/s/AUiE9Mc
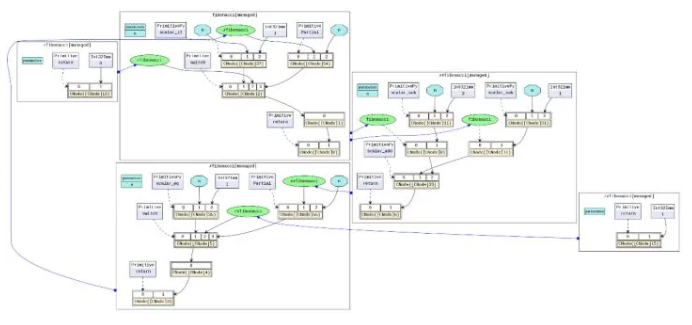
其中fibonacci是顶层函数图,在顶层中有两个函数图被switch选择调用✓fibonacci是第一个if的True分支,✗fibonacci是第一个if的False分支。在✗fibonacci中被调用的✓✗fibonacci是elif的True分支,✗✗fibonacci是elif的False分支。
这里需要理解的关键是在MindIR中,条件跳转和递归是以高阶控制流的形式表达的例如,✓fibonacci和✗fibonacci是作为switch算子的参数传入,switch根据条件参数选择哪一个函数作为返回值因此,switch是把输入的函数当成普通的值做了一个二元选择操作,并没有调用,而真正的函数调用是在紧随switch后的CNode上完成
自由变量和闭包
自由变量(free variable)是指在代码块中引用作用域环境中的变量而非局部变量
闭包(closure)是一种编程语言特性,它指的是代码块和作用域环境的结合
在MindIR中,代码块是以函数图呈现的,而作用域环境可以理解为该函数被调用时的上下文环境,自由变量的捕获方式是值拷贝而非引用。
一个典型的闭包用例如下:
- @ms_function
- def func_outer(a, b):
- def func_inner(c):
- return a + b + c
- return func_inner
- @ms_function
- def ms_closure():
- closure = func_outer(1, 2)
- out1 = closure(1)
- out2 = closure(2)
- return out1, out2
对应的MindIR为:https://w.url.cn/s/AsUMXTS
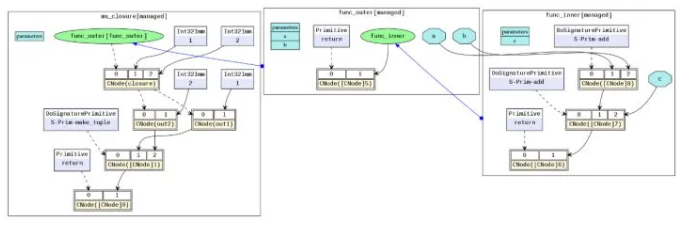
在例子中,a和b是自由变量,因为func_inner中变量a和b是引用的其父图func_outer中定义的参数。变量closure是一个闭包,它是函数func_inner与其上下文func_outer(1, 2)的结合。因此,out1的结果是4,因为其等价于1+2+1,out2的结果是5,因为其等价于1+2+2
参考文献
[1]《Engineering a Compiler》Second Edition,Chapter 5. Intermediate Representation
[2]《Combining Analyses, Combining Optimizations》
[3]《COMPILING WITH CONTINUATIONS》第一章
[4]《Functional programming languages Part V: functional intermediate representations》
[5] matt.might.net/articles
[6]《Don't Unroll Adjoint: Differentiating SSA-Form Programs》
[7] mindspore.cn/doc/note/z
AI框架中图层IR的分析的更多相关文章
- 设计模式(二十一)——解释器模式(Spring 框架中SpelExpressionParser源码分析)
1 四则运算问题 通过解释器模式来实现四则运算,如计算 a+b-c 的值,具体要求 1) 先输入表达式的形式,比如 a+b+c-d+e, 要求表达式的字母不能重复 2) 在分别输入 a ,b, c, ...
- 工作流中的数据持久化详解!Activiti框架中JPA的使用分析
Activiti中JPA简介 可以使用JPA实体作为流程变量, 并进行操作: 基于流程变量更新已有的JPA实体,可以在用户任务的表单中填写或者由服务任务生成 重用已有的领域模型,不需要编写显示的服务获 ...
- 微擎框架中receive.php代码分析
- 昇思MindSpore全场景AI框架 1.6版本,更高的开发效率,更好地服务开发者
摘要:本文带大家快速浏览昇思MindSpore全场景AI框架1.6版本的关键特性. 全新的昇思MindSpore全场景AI框架1.6版本已发布,此版本中昇思MindSpore全场景AI框架易用性不断改 ...
- layui框架中layer父子页面交互的方法分析
本文实例讲述了layui框架中layer父子页面交互的方法.分享给大家供大家参考,具体如下: layer是一款近年来备受青睐的web弹层组件,官网地址是:http://layer.layui.com/ ...
- NNVM AI框架编译器
NNVM AI框架编译器 深度学习已变得无处不在且不可或缺.看到对在多种平台(例如手机,GPU,IoT设备和专用加速器)上部署深度学习工作负载的需求不断增长.TVM堆栈弥合深度学习框架与面向性能或效率 ...
- AI框架精要:设计思想
AI框架精要:设计思想 本文主要介绍飞桨paddle平台的底层设计思想,可以帮助用户理解飞桨paddle框架的运作过程,以便于在实际业务需求中,更好的完成模型代码编写与调试及飞桨paddle框架的二次 ...
- NNVM Compiler,AI框架的开放式编译器
NNVM Compiler,AI框架的开放式编译器 深度学习已变得无处不在且不可或缺.在多种平台(例如手机,GPU,IoT设备和专用加速器)上部署深度学习工作负载的需求不断增长.宣布了TVM堆栈,以弥 ...
- AI框架类FAQ
AI框架类FAQ 数据处理 问题:如何在训练过程中高效读取数量很大的数据集? 答复:当训练时使用的数据集数据量较大或者预处理逻辑复杂时,如果串行地进行数据读取,数据读取往往会成为训练效率的瓶颈.这种情 ...
随机推荐
- a标签美化
具体选中a标签给予宽高,这样才能在整个a标签范围内才能跳转 但是因为a标签是行内元素,所以要用display:blcok 转化为块状元素 且a标签不继承父元素的color 对a标签设置颜色,要选中a标 ...
- Flink使用二次聚合实现TopN计算-乱序数据
一.背景说明: 在上篇文章实现了TopN计算,但是碰到迟到数据则会无法在当前窗口计算,需要对其中的键控状态优化 Flink使用二次聚合实现TopN计算 本次需求是对数据进行统计,要求每隔5秒,输出最近 ...
- [bug] SpringBoot 集成 jsp,访问时页面报Whitelabel Error Page
参考 https://bbs.csdn.net/topics/392187702
- linux环境下/etc/hosts文件详解
linux环境下/etc/hosts文件详解 就没一个昵称能用关注 0.0632017.09.12 17:04:28字数 623阅读 27,096 介绍 hosts文件是linux系统中负责ip地址与 ...
- 【山外笔记-SVN命令】svn命令详解
本文打印版文件下载地址 [山外笔记-SVN命令]svn命令详解-打印版.pdf 一.命令简介 svn命令用于Subversion命令行客户端,执行svn相关的操作. 二.命令语法 1.svn语法: ( ...
- C++对象内存分布详解(包括字节对齐和虚函数表)
转自:https://www.jb51.net/article/101122.htm 1.C++对象的内存分布和虚函数表: C++对象的内存分布和虚函数表注意,对象中保存的是虚函数表指针,而不是虚函数 ...
- Jaxb的优点与用法(bean转xml的插件,简化webservice接口的开发工作量)
一.jaxb是什么 JAXB是Java Architecture for XML Binding的缩写.可以将一个Java对象转变成为XML格式,反之亦然. 我们把对象与关系数据库之间的映射称 ...
- windows下nginx配合nodejs进行反向代理
本文原创,转载请附上原作者链接!https://www.cnblogs.com/LSWu/articles/14848324.html 1.安装node.js 从node.js官网上下载node.js ...
- Docker Buildx插件
Docker Buildx插件 Overview Docker Buildx是一个CLI插件,它扩展了Docker命令,完全支持Moby BuildKit builder toolkit提供的功能.它 ...
- C++标准模板库(STL)——queue常见用法详解
queue的定义 queue<typename> name; queue容器内元素的访问 由于队列本身就是一种先进先出的限制性数据结构,因此在STL中只能通过front()来访问队首元素, ...