论文解读(AGCN)《 Attention-driven Graph Clustering Network》
Paper Information
Title:《Attention-driven Graph Clustering Network》
Authors:Zhihao Peng, Hui Liu, Yuheng Jia, Junhui Hou
Source:2021, ACM Multimedia
Other:1 Citations, 46 References
Paper:Download
Code:Download
Task: Deep Clustering、Graph Clustering、Graph Convolutional Network
Abstract
研究现状:使用自动编码器提取节点属性特征,利用图卷积网络捕获拓扑图特征。
缺点如下:
- 没有一种灵活的机制融合 AE 和 GCN 产生的特征表示。[ 说白了就是实验效果不好 ]
- 忽略不同层 embedding 的多尺度信息,进行后续的聚类分配导致聚类结果较差。[ 本文的一个优势 ]
本文提出的方法:AGCN (无监督)
1 Introduction
AGCN 包括了两个 融合 模块
- AGCN heterogeneity-wise fusion module (
AGCN-H):AGCN-H 自适应地合并了来自同一层的 GCN 特征和 AE 特征。 - AGCN scale-wise fusion module (
AGCN-S):AGCN-S 动态地连接了来自不同层的多尺度特征。
- AGCN heterogeneity-wise fusion module (
上述两个模块都是基于 attention-based 机制 ,动态度量相应特征对后续特征融合的重要性。
Basic definition:如 Table 1 所示:
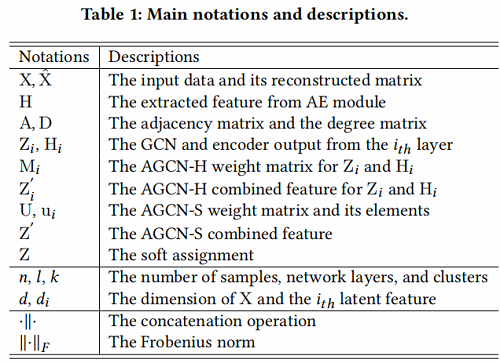
2 Related work
围绕着 AE 和 GCN 提出的聚类算法。此类方法存在的 缺点 如下:
- 将拓扑图特征和节点属性特征的重要性同等看待。[一个是从 GCN 抽取,一个是从 AE 中抽取 ]
- 忽略了不同嵌入层的多尺度信息。此外,图结构特征与节点属性特征之间的交互在一定程度上不够。[ 融合机制不好 ]
3 Proposed method
本章节,先介绍 AGCN-H 和 AGCN-S ,然后介绍训练过程。
AGCN 架构如下:
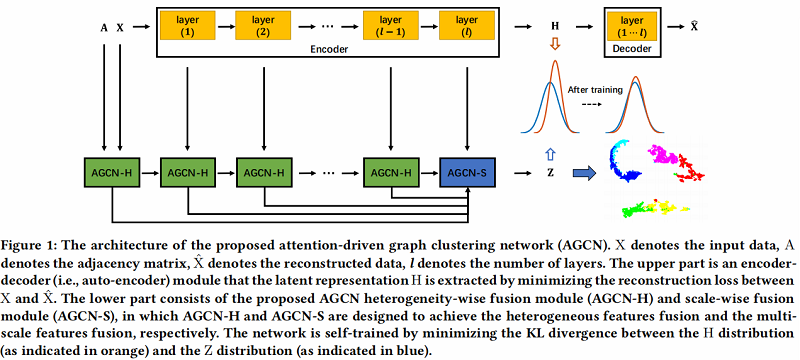
具体的两个模块:
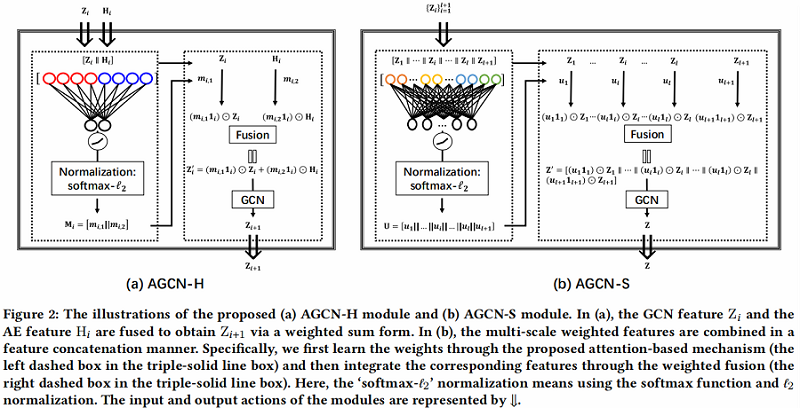
3.1 AGCN-H
AGCN-H 自适应地合并了来自同一层的 GCN 特征和 AE 特征。通过注意力系数学习,随后进行加权特征融合。
AGCN-H 的对应说明如 Figure 2(a) 所示,实现细节如下:
Step1:利用自编码器提取潜在表示,重构损失如下:
$\begin{array}{l}\mathcal{L}_{R}=\|\mathrm{X}-\hat{\mathrm{X}}\|_{F}^{2} \\\text { s.t. } \quad\left\{\mathrm{H}_{i}=\phi\left(\mathrm{W}_{i}^{\mathrm{e}} \mathrm{H}_{i-1}+\mathrm{b}_{i}^{\mathrm{e}}\right)\right. \\\left.\hat{\mathrm{H}}_{i}=\phi\left(\mathrm{W}_{i}^{d} \hat{\mathrm{H}}_{i-1}+\mathrm{b}_{i}^{d}\right), i=1, \cdots, l\right\}\end{array}\quad \quad \quad (1)$
其中:
- $\mathrm{X} \in \mathbb{R}^{n \times d}$ 代表了原始数据(raw data);
- $\hat{\mathrm{X}} \in \mathbb{R}^{n \times d}$ 代表了重构数据( reconstructed data);
- $\mathrm{H}_{i} \in \mathbb{R}^{n \times d_{i}}$ 代表了 Encoder 第 $i$ 层的输出;
- $\hat{\mathrm{H}}_{i} \in \mathbb{R}^{n \times \hat{d}_{i}}$ 代表了 Decoder 第 $i$ 层的输出;
- $\phi(\cdot)$ 代表了激活函数,如 Tanh, ReLU ;
- $W _{i}^{e}$ 和 $b _{i}^{e} $ 代表了 Encoder 第 $i$ 层的权重参数和偏置项;
- $ \mathrm{W}_{i}^{d}$ 和 $\mathrm{b}_{i}^{d}$ 代表了 Dncoder 第 $i$ 层的权重参数和偏置项;
- $ \hat{\mathrm{H}}_{l}$ 代表了重构后的 $\hat{\mathrm{X}}$ ;
- $Z_{i} \in \mathbb{R}^{n \times d_{i}}$ 代表了 GCN 从第 $i$ 层学到的特征;
- $\mathrm{Z}_{0}$ 和 $\mathrm{H}_{0} $ 代表原始数据 $\mathrm{X} $ ;
Step2:学习相应的注意力系数
- 将 $\mathrm{Z}_{i}$ 和 $\mathrm{H}_{i}$ 先进行拼接,
- 将上述拼接的 $ \left[\mathrm{Z}_{i} \| \mathrm{H}_{i}\right] \in \mathbb{R}^{n \times 2 d_{i}}$ ,进行全连接操作;
- 将上述结果使用激活函数 LeakyReLU ;
- 最后再使用 softmax function 和 $\ell_{2}$ normalization;
Step2 可以公式化为 :
$\mathrm{M}_{i}=\ell_{2}\left(\operatorname{softmax}\left(\left(\text { LeakyReLU }\left(\left[\mathrm{Z}_{i} \| \mathrm{H}_{i}\right] \mathrm{W}_{i}^{a}\right)\right)\right)\right)\quad \quad\quad(2)$
其中:
- $\mathrm{M}_{i}=\left[\mathrm{m}_{i, 1} \| \mathrm{m}_{i, 2}\right] \in \mathbb{R}^{n \times 2}$ 是 attention coefficient matrix ,且 每项大于 0;
- $\mathrm{m}_{i, 1}$,$ \mathrm{~m}_{i, 2}$ 是衡量 $\mathrm{Z}_{i}$、$\mathrm{H}_{i}$ 重要性的权重向量;
Step 3:融合第 $i$ 层的 GCN 的特征 $Z_{i}$ 和 AE 的特征 $ \mathrm{H}_{i} $ :
$\mathrm{Z}_{i}^{\prime}=\left(\mathrm{m}_{i, 1} 1_{i}\right) \odot \mathrm{Z}_{i}+\left(\mathrm{m}_{i, 2} 1_{i}\right) \odot \mathrm{H}_{i}\quad \quad \quad (3)$
其中:
- $1_{i} \in \mathbb{R}^{1 \times d_{i}}$ 代表着全 $1$ 向量;
- $ '\odot'$ 代表着 Hadamard product ;
Step 4:将上述生成的 $Z_{i}^{\prime} \in \mathbb{R}^{n \times d_{i}}$ 当作第 $i+1$ 层 GCN 的输入,获得 $\mathrm{Z}_{i+1}$ :
$\mathrm{Z}_{i+1}=\text { LeakyReLU }\left(\mathrm{D}^{-\frac{1}{2}}(\mathrm{~A}+\mathrm{I}) \mathrm{D}^{-\frac{1}{2}} \mathrm{Z}_{i}^{\prime} \mathrm{W}_{i}\right)\quad \quad (4)$
其中
- GCN 原始模型中的邻接矩阵 $A$ 变形为 $ D^{-\frac{1}{2}}(A+ I) \mathrm{D}^{-\frac{1}{2}}$ ;
- $\mathrm{I} \in \mathbb{R}^{n \times n}$ ;
3.2 AGCN-S
Step1:将 multi-scale features $Z_{i}$ 拼接在一起。
$\mathrm{Z}^{\prime}=\left[\mathrm{Z}_{1}\|\cdots\| \mathrm{Z}_{i}\|\cdots\| \mathrm{Z}_{l} \| \mathrm{Z}_{l+1}\right]\quad\quad \quad (5)$
其中:
- $\mathrm{Z}_{l+1}=\mathrm{H}_{l} \in \mathbb{R}^{n \times d_{l}}$ 表示 $\mathrm{Z}_{l+1}$ 的信息只来自自编码器。
Step2:将上述生成的 $\mathrm{Z}^{\prime}$ 放入全连接网络,并使用 $\text { softmax- } \ell_{2}$ 标准化:
$\mathrm{U}=\ell_{2}\left(\operatorname{softmax}\left(\operatorname{LeakyReLU}\left(\left[\mathrm{Z}_{1}\|\cdots\| \mathrm{Z}_{i}\|\cdots\| \mathrm{Z}_{l} \| \mathrm{Z}_{l+1}\right] \mathrm{W}^{s}\right)\right)\right)\quad \quad\quad(6)$
其中:
- $\mathrm{U}=\left[\mathrm{u}_{1}\|\cdots\| \mathrm{u}_{i}\|\cdots\| \mathrm{u}_{l} \| \mathrm{u}_{l+1}\right] \in \mathbb{R}^{n \times(l+1)}$ 且每个数大于 $0$ ;
- $u_{i}$ 代表了 $\mathrm{Z}_{i}$ 的 parallel attention coefficient ;
Step3:为了进一步探究多尺度特征,考虑在 attention 系数上施加一个相应的权重:
$\mathrm{Z}^{\prime}= {\left[\left(\mathrm{u}_{1} 1_{1}\right) \odot \mathrm{Z}_{1}\|\cdots\|\left(\mathrm{u}_{i} 1_{i}\right) \odot \mathrm{Z}_{i}\|\cdots\|\left(\mathrm{u}_{l} 1_{l}\right) \odot \mathrm{Z}_{l} \|\right.} \left.\left(\mathrm{u}_{l+1} 1_{l+1}\right) \odot \mathrm{Z}_{l+1}\right]\quad \quad \quad (7)$
Step4 :$ Z^{\prime}$ 将作为最终预测的输入,预测输出为 $Z \in \mathbb{R}^{n \times k} $ ,其中 $k$ 代表聚类数。
$\begin{array}{l}\mathrm{Z}=\operatorname{softmax}\left(\mathrm{D}^{-\frac{1}{2}}(\mathrm{~A}+\mathrm{I}) \mathrm{D}^{-\frac{1}{2}} \mathrm{Z}^{\prime} \mathrm{W}\right) \\\text { s.t. } \quad \sum_{j=1}^{k} z_{i, j}=1, z_{i, j}>0\end{array}\quad \quad\quad (8)$
预测输出计算:
$\begin{array}{l} y_{i}=\underset{j}{\arg \max }\;\;\; \mathrm{z}_{i, j} \\ \text { s.t. } \quad j=1, \cdots, k \end{array}\quad\quad\quad (9)$
3.3 Training process
训练过程包括两个步骤:
Step 1:
使用 Student's t-distribution 作为核来度量 embedded point 和质心之间的相似度:
${\large q_{i, j}=\frac{\left(1+\left\|\mathrm{h}_{i}-\mu_{j}\right\|^{2} / \alpha\right)^{-\frac{\alpha+1}{2}}}{\sum_{j}\left(1+\left\|\mathrm{h}_{i}-\mu_{j}\right\|^{2} / \alpha\right)^{-\frac{\alpha+1}{2}}}}\quad\quad\quad(10) $
辅助目标分布 $P$:
${\large p_{i, j}=\frac{q_{i, j}^{2} / \sum_{i} q_{i, j}}{\sum_{j}^{\prime} q_{i, j}^{2} / \sum_{i} q_{i, j}}} \quad\quad\quad(11)$
Step 2 :
通过辅助目标分布 $P$ 最小化组合特征分布 $Z$ 和自编码器特征分布 $H$ 的 KL 散度。
$\begin{aligned}\mathcal{L}_{K L} &=\lambda_{1} * K L(\mathrm{P}, \mathrm{Z})+\lambda_{2} * K L(\mathrm{P}, \mathrm{H}) \\&=\lambda_{1} \sum\limits _{i} \sum\limits_{j} p_{i, j} \log \frac{p_{i, j}}{z_{i, j}}+\lambda_{2} \sum\limits_{i} \sum\limits_{j} p_{i, j} \log \frac{p_{i, j}}{q_{i, j}}\end{aligned}\quad\quad\quad(12)$
其中:
- $\lambda_{1}>0$ 和 $\lambda_{2}>0$ 是 trade-off parameters ;
联合 Eq.1 和 Eq.12 得到总损失为:
$\mathcal{L}=\mathcal{L}_{R}+\mathcal{L}_{K L}\quad\quad\quad(13)$
AGCN 的训练过程如 Algorithm 1 所示:

4 Experiments
4.1 Datasets
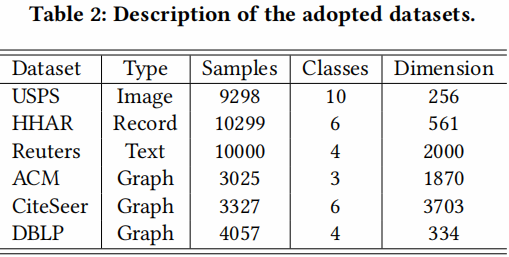
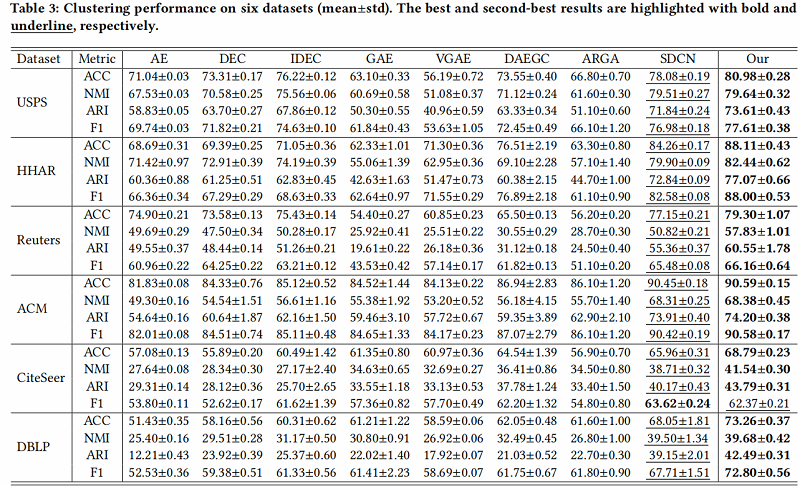
4.2 Results
4.3 Ablation Study
进行消融研究,以评估 AGCN-H 模块和 AGCN-S 模块的效率和有效性。此外,我们还分析了不同尺度特征对聚类性能的影响。结果如 Table 4 所示:
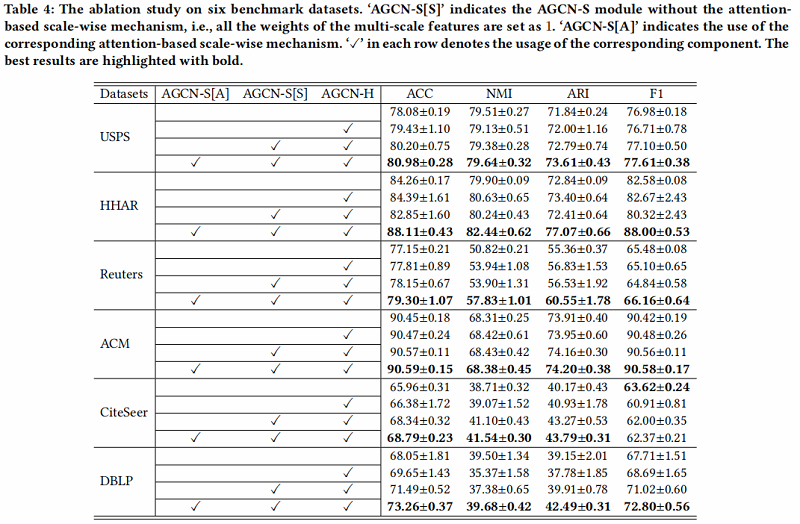
- Analysis of AGCN-H module
我们可以观察到,AGCN-H 模块在一定程度上提高了性能 【相较于没有使用】。
- Analysis of AGCN-S module
从两个方面评价 AGCN-S module:
- the multi-scale feature fusion (marked as AGCN-S[S]) ;
- the attention-based scale-wise strategy (marked as AGCN-S[A]) ;
在第一个方面,通过比较表4中每个数据集的第二行和第三行的实验结果,我们可以发现,在大多数情况下,多尺度特征融合可以帮助获得更好的聚类性能。唯一的例外是HHAR,其中间层的一些特征受到过度平滑的问题,导致负传播。
对于第二个方面,通过比较表4中第三行和第四行的每个数据集的结果,我们可以发现,考虑基于注意力的规模级策略能够获得最好的聚类性能。特别是在HHAR数据集中,考虑基于注意力的规模级策略可以充分应对上述性能下降的问题。这一现象被认为是由于基于注意力的尺度策略可以分配一些权值较小的负特征,避免了负传播。这曾经验证了基于注意力的机制的有效性。
- Analysis of different scale features.
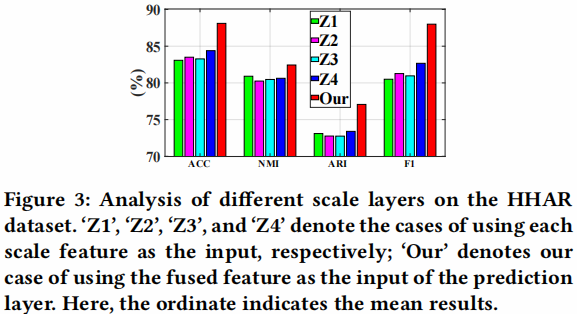
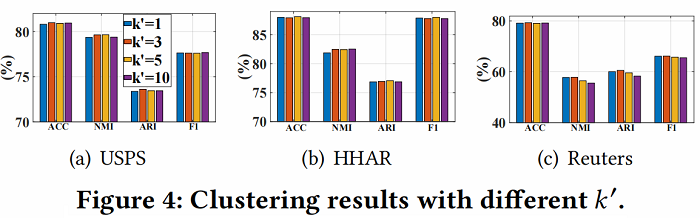
- Analysis of different ′.
由于邻域 ‘ 的数量显著影响邻接矩阵的质量,我们对非图数据集,即USPS、HHAR和路透社进行了 ’ 的参数分析。从 Figure 4 中,我们可以观察到我们的模型对 ‘ 不敏感。
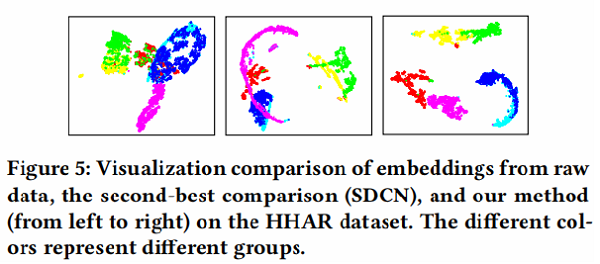
4.4 Visualization
为了直观地验证我们的方法的有效性,我们绘制了我们方法的学习表示的二维t分布随机邻域嵌入(t-SNE) 可视化,以及图5中HHAR数据集上比较最好的[24]可视化。我们可以发现,通过我们的方法获得的特征表示对不同的簇具有最好的可分性,其中来自同一类的样本自然地聚集在一起,不同组之间的差距是最明显的一个。这一现象证实了,与最先进的方法相比,我们的方法产生了最有区别的表示。
5 Conclusion
在本文中,我们提出了一种新的深度聚类方法,即注意驱动图聚类网络(AGCN),它同时考虑了动态融合策略和多尺度特征融合。通过利用两个新的基于注意力的融合模块,AGCN能够自适应地学习权重的异质性,以实现这些特征融合。此外,在常用的基准数据集上进行的大量实验,验证了所提出的网络优于最先进的方法,特别是对于低质量的图。
论文解读(AGCN)《 Attention-driven Graph Clustering Network》的更多相关文章
- 论文解读《Deep Attention-guided Graph Clustering with Dual Self-supervision》
论文信息 论文标题:Deep Attention-guided Graph Clustering with Dual Self-supervision论文作者:Zhihao Peng, Hui Liu ...
- 论文解读SDCN《Structural Deep Clustering Network》
前言 主体思想:深度聚类需要考虑数据内在信息以及结构信息. 考虑自身信息采用 基础的 Autoencoder ,考虑结构信息采用 GCN. 1.介绍 在现实中,将结构信息集成到深度聚类中通常需要解决以 ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- 论文解读 - Relational Pooling for Graph Representations
1 简介 本文着眼于对Weisfeiler-Lehman算法(WL Test)和WL-GNN模型的分析,针对于WL测试以及WL-GNN所不能解决的环形跳跃连接图(circulant skip link ...
- 论文解读(MCGC)《Multi-view Contrastive Graph Clustering》
论文信息 论文标题:Multi-view Contrastive Graph Clustering论文作者:Erlin Pan.Zhao Kang论文来源:2021, NeurIPS论文地址:down ...
- 论文解读(CGC)《CGC: Contrastive Graph Clustering for Community Detection and Tracking》
论文信息 论文标题:CGC: Contrastive Graph Clustering for Community Detection and Tracking论文作者:Namyong Park, R ...
- 论文解读(SCGC))《Simple Contrastive Graph Clustering》
论文信息 论文标题:Simple Contrastive Graph Clustering论文作者:Yue Liu, Xihong Yang, Sihang Zhou, Xinwang Liu论文来源 ...
- 点云配准的端到端深度神经网络:ICCV2019论文解读
点云配准的端到端深度神经网络:ICCV2019论文解读 DeepVCP: An End-to-End Deep Neural Network for Point Cloud Registration ...
- 论文笔记:(2019)GAPNet: Graph Attention based Point Neural Network for Exploiting Local Feature of Point Cloud
目录 摘要 一.引言 二.相关工作 基于体素网格的特征学习 直接从非结构化点云中学习特征 从多视图模型中学习特征 几何深度学习的学习特征 三.GAPNet架构 3.1 GAPLayer 局部结构表示 ...
随机推荐
- CentOS7 防火墙firewalld 和 CentOS6 防火墙iptables 开放zabbix-agent端口的方法
我们在生产环境中,一般都是把防火墙打开的,不像测试环境,可以直接关闭掉.最近安装zabbix ,由于公司服务器既有centos 7又有centos 6,遇到了一些防火墙的问题,现在正好把centos防 ...
- Centos6.8安装并配置VNC
一般服务器都会在IDC或云端,为了可以看到服务器的图形化界面,需要安装配置VNC,本例为Centos6.8上安装配置VNC. [root@hostname ~]#yum install -y tige ...
- Mybatis实现分包定义数据库
Mybatis实现分包定义数据库 背景 业务需求中需要连接两个数据库处理数据,需要用动态数据源.通过了解mybatis的框架,计划 使用分包的方式进行数据源的区分. 原理 前提: 我们使用mybati ...
- 彻底剖析JVM类加载机制
本文仍然基于JDK8版本,从JDK9模块化器,类加载器有一些变动. 0 javac编译 java代码 public class Math { public static final int initD ...
- 如何管理leader对你的能力预期?
在内网看到一个讨论帖,原文如下: 如何管理leader对你的能力预期? 你一个项目做得好,之后类似项目,leader认为你也就是合格水平,而且认为你只会做这种项目. SAD.. 思考 在开始之前先想下 ...
- 5.13-jsp分页功能实现
1.分页共能的实现 可以在dao层中创建方法 List<Member> pager(Long pageSize, Long pageNum);(方法灵活运用)其中传入的两个参数pageSi ...
- 【HarmonyOS】【JS】鸿蒙Js camera怎么拍照并使用image显示出来
官网中有描述camera组件功能界面属性介绍,但是官网没有具体的demo让我们感受拍照的功能,今天写一篇demo来完善一下拍照的功能 demo 功能如下 第一步首先进行拍照功能 第二步 进行js页面跳 ...
- gin框架使用Air实时加载
Air实时加载 本章我们要介绍一个神器--Air能够实时监听项目的代码文件,在代码发生变更之后自动重新编译并执行,大大提高gin框架项目的开发效率. 1.1.1. 为什么需要实时加载? 之前使用Pyt ...
- gin中的多模板和模板继承的用法
1. 简单用法 package main import ( "github.com/gin-contrib/multitemplate" "github.com/gin- ...
- golang中的25个关键字
Go 语言中会使用到的 25 个关键字或保留字: 1. 程序声明 import 导入 package 包 2. 程序实体声明和定义 chan 通道 var 变量声明 const 常量声明 func 用 ...