商业爬虫学习笔记day1
day1
一. HTTP
1.介绍:
https://www.cnblogs.com/vamei/archive/2013/05/11/3069788.html
http://blog.csdn.net/guyuealian/article/details/52535294
2.当用户输入网址(如www.baidu.com),发送网络请求的过程是什么?
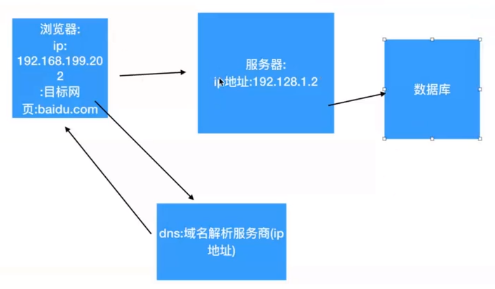
上图应该还有往回的箭头(即服务器从数据库获取得到指定的请求资源,返回给客户端)
a. 通过域名服务器解析出www.baidu.com对应的ip地址
(1)先要知道默认网关的mac地址(通过arp协议获取默认网关的mac地址)
(2)组织数据,发送给默认网关(ip还是dns服务器的ip,但是mac地址是默认网关的mac地址)
(3)默认网关拥有转发数据的能力,把数据转发给路由器
(4)路由器根据自己的路由协议,来选择一个合适的较快的路径,转发数据给目的网关
(5)目的网关(dns服务器所在的网关)把数据转发给dns服务器
(6)dns服务器查询解析出www.baidu.com对应的ip地址,并把它原路返回给请求这个域名的client
b. 得到了baidu.com的ip地址后,进行tcp的3次握手,从而达到client与server的连接
c.通过http协议发送请求数据给对应的web服务器
d.web服务器收到数据请求之后,通过查询自己的服务器从而得到client请求的资源,原路返回给请求者(浏览器)
d.浏览器收到数据后,通过浏览器自己的渲染功能来显示这个网页
e.浏览器关闭tcp连接,即4次挥手
2.http的请求方式
(1)get请求
向特定的资源发出请求,其参数直接出现在url中,不安全,此外请求有长度限制,获取的数据只能是ASCII码类型数据
(2)post请求
向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据(允许二进制数据)被包含在请求体中。请求方式安全,请求没有长度限制。POST请求可能会导致新的资源的创建或已有资源的修改
(3)PUT
向指定资源位置上传其最新内容
(4)delete
请求服务器删除Request-URI所标识的资源
(5)trace
客户端可以对请求消息的传输路径进行追踪,其是让web服务器端将之前的请求通信还给客户端的方法,主要用于测试和诊断
(6)head
类似get请求,其返回的响应中没有具体的内容(即不返回报文的主体部分)
(7)options
返回服务器针对特定资源所支持的HTTP请求方法(即客户端询问服务器可以提交哪些请求方法)
(8)connect
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器
connect方法要求在与代理服务器通信时简历隧道,实现用隧道协议进行TCP通信。主要使用SSL(安全套接层)和TLS(传输层安全)协议把通信内容加密后经网络隧道传输
虽然HTTP的请求方式有8种,但是我们再实际应用中常用的也就是get和post,其他请求方式也都可以通过这两种方式间接来实现
3.http和https的区别
(1)https协议要CA(Certificate Authority, 证书授权中心)证书,需要一定的经济成本
(2)http是明文传输,https是加密的安全传输,所以https相对于http传输比较安全
(3)连接端口不一样,http是80,https是443
4.请求头(request header)内容
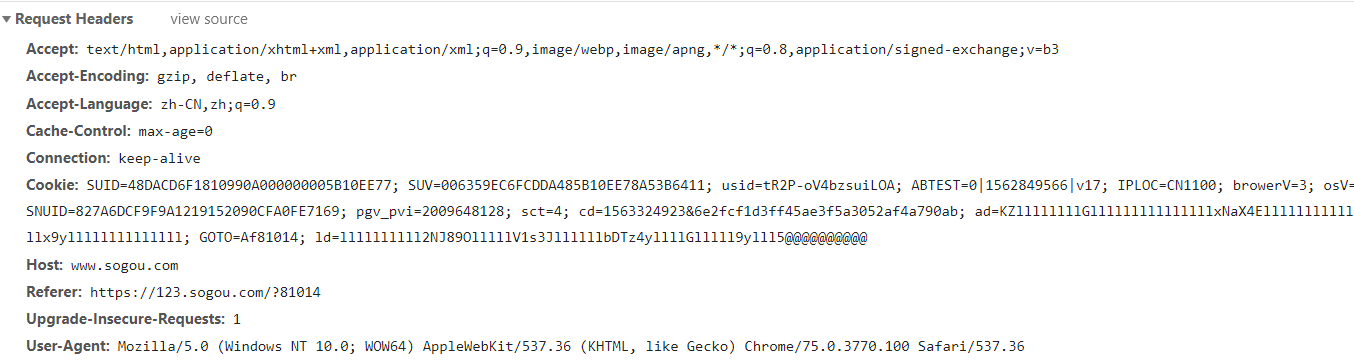
(1)Accept:⽂文本的格式
(2)Accept-Encoding:编码格式
(3)Connection:长链接 短链接
(4)Cookie:验证⽤的
(5)Host:域名
(6)Referer:标志从哪个页面跳转过来的
(7)User-Agent:浏览器和⽤户的信息
二. 爬虫入门
(1)爬虫的价值:
1.买卖数据(⾼高端的领域价格特别贵)
2.数据分析:出分析报告
3.流量量
4.指数阿里指数,百度指数
(2)合法性:灰⾊色产业
政府没有法律律规定爬⾍虫是违法的,也没有法律律规定爬⾍虫是合法的
公司概念:公司让你爬数据库(窃取商业机密)责任在公司
(3)爬⾍虫可以爬取所有东⻄西?(不是)爬⾍只能爬取⽤用户能访问到的数据
爱奇艺的视频(vip,非vip)
1.普通⽤用户 只能看非vip 爬取非vip的的视频
2.vip 爬取vip的视频
3.普通用户想要爬取vip视频(⿊黑客)
三. 爬虫的分类
(1)通⽤用爬⾍虫
1.使⽤用搜索引擎:百度 谷歌 360 雅虎 搜狗
优势:开放性 速度快
劣势:⽬标不明确
返回内容:基本上%90是⽤户不需要的
不清楚用户的需求在哪里
(2)聚焦爬⾍虫(学习)
1.⽬标明确
2.对⽤户的需求非常精准
3.返回的内容很固定
增量式:翻⻚:从第⼀⻚请求到最后⼀页
Deep 深度爬⾍虫:
静态数据:html css
动态数据:js代码,加密的js
(3)robots
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。
聚焦爬虫不遵守robots
四. 爬虫的工作原理
确定抓取目标的url是哪一个--->使用代码发送请求获取数据--->解析获取到的数据--->若有新的目标(url),回到第一步--->数据持久化(如,将数据写入文件中)
1. python3(原生提供的模块):urlib.request
(1) urlopen:
a.返回response对象
b. response.read()
c. bytes.decode("utf-8")
(2) get:传参 (没传data就默认使用get请求,传了data就post请求)
1.汉字报错 :解释器ascii没有汉字,url汉字转码
(3)post
(4)handle处理器的⾃定义
(5)urlError
五.代码
发送请求
import urllib.request def load_data():
url = "http://www.baidu.com/"
response = urllib.request.urlopen(url) # 发送请求
print(response)
data = response.read() # 读取到的内容为bytes
print(data)
# 将文件获取的内容转换成字符串
str_data = data.decode("utf-8")
print(str_data)
# 将数据写入文件
with open("baidu.html", "w",encoding="utf-8") as f: # 此处encoding="utf-8"一定要写,否则报错
f.write(str_data)
load_data()
#python爬取的类型:str bytes
#如果爬取回来的是bytes类型:但是你写入的时候需要字符串 decode("utf-8")
#如果爬取过来的是str类型:但你要写入的是bytes类型 encode(""utf-8")
发送带参数的请求
import urllib.request def get_method_params():
url = "http://www.baidu.com/s?wd="
name = "美女"
final_url = url + name
print(final_url)
# 使用代码发送网络请求
response = urllib.request.urlopen(final_url)
print(response) get_method_params()
这样运行会报错UnicodeEncodeError: 'ascii' codec can't encode characters in position 10-11: ordinal not in range(128)
原因:python:是解释性语言;解析器只支持 ascii 码,不支持中文,此处的final_url包含了中文,所以就要进行url的转译,如将url(https://www.baidu.com/s?wd=美女)复制到pycharm中会直接转译,如下:

但我复制到自己的pycharm不会产生转译(怀疑视频老师讲错了)
自己查到的原因(不知道是否正确):Url的编码格式采用的是ASCII,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会赵成问题
转译要用到parse,string模块,如下
import urllib.request
import urllib.parse
import string
def get_method_params():
url = "http://www.baidu.com/s?wd="
name = "美女"
final_url = url+name
print(final_url)
#将包含汉字的网址进行转译
encode_new_url = urllib.parse.quote(final_url,safe=string.printable)
print(encode_new_url)
# 使用代码发送网络请求
response = urllib.request.urlopen(encode_new_url)
print(response) # 返回的是http对象,如<http.client.HTTPResponse object at 0x0000028324337780>
#读取内容
data = response.read().decode() print(data)
#保存到本地
with open("02-encode.html","w",encoding="utf-8")as f:
f.write(data)
get_method_params()
商业爬虫学习笔记day1的更多相关文章
- 商业爬虫学习笔记day2
1. get传参 (1)url中包含中文报错解决方法 urllib.request.quote("包含中文的url", safe = "string.printtable ...
- 商业爬虫学习笔记day5
一. 发送post请求 import requests url = "" # 发送post请求 data = { } response = requests.post(url, d ...
- 商业爬虫学习笔记day4
一.获取登录后页面信息的两种方法 1.第一种方法: 人为把有效cookies加到请求头中,代码如下 import urllib.request # 确定url url = "https:// ...
- 商业爬虫学习笔记day3
一. 付费代理发送请求的两种方式 第一种方式: (1)代理ip,形式如下: money_proxy = {"http":"username:pwd@192.168.12. ...
- 商业爬虫学习笔记day8-------json的使用
一. 简介 JSON,全称为JavaScript Object Notation(JavaScript对象标记),它通过对象和数组的组合来表示数据,是一种轻量级的数据交换格式.它基于 ECMAScri ...
- 商业爬虫学习笔记day7-------解析方法之bs4
一.Beautiful Soup 1.简介 Beautiful Soup 是python的一个库,最主要的功能是从网页抓取数据.其特点如下(这三个特点正是bs强大的原因,来自官方手册) a. Beau ...
- 商业爬虫学习笔记day6
一. 正则解析数据 解析百度新闻中每个新闻的title,url,检查每个新闻的源码可知道,其title和url都位于<a></a>标签中,因为里面参数的具体形式不一样,同一个正 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- OpenCV图像处理学习笔记-Day1
OpenCV图像处理学习笔记-Day1 目录 OpenCV图像处理学习笔记-Day1 第1课:图像读入.显示和保存 1. 读入图像 2. 显示图像 3. 保存图像 第2课:图像处理入门基础 1. 基本 ...
随机推荐
- python中将xmind转成excel
需求:最近公司项目使用tapd进行管理,现在遇到的一个难题就是,使用固定的模板编写测试用例,使用excel导入tapd进行测试用例管理,觉得太过麻烦,本人一直喜欢使用导图来写测试用例,故产生了这个工具 ...
- 算法学习->求解三角形最小路径及其值
00 问题 00-1 描述 对给定高度为n的一个整数三角形,找出从顶部到底部的最小路径和.每个整数只能向下移动到与之相邻的整数. 找到一个一样的力扣题:120. 三角形最小路径和 - 力扣(LeetC ...
- [mysql课程作业]我的大学|作业
第八周周五 1.将xs表中王元的专业改为"智能建筑". # update xs set 专业名='智能建筑' where 姓名='王元'; # select * from xs w ...
- 【java+selenium3】自动化截图 (十四)
一.截图 1. Firefox浏览器截图 FirefoxDriver firefoxDriver = new FirefoxDriver(); firefoxDriver.getScreenshotA ...
- adb 安装与使用(一)
一.ADB简介 1. 什么是adb? adb(Android Debug Bridage)是Android sdk的一个工具: adb 是用来连接安卓手机和PC端的桥梁,要有adb作为二者之间的维系, ...
- 攻防世界 Misc 新手练习区 give_you_flag Writeup
攻防世界 Misc 新手练习区 give_you_flag Writeup 题目介绍 题目考点 gif图片分离 细心的P图 二维码解码 Writeup 下载附件打开,发现是一张gif图片,打开看了一下 ...
- Jmeter接口数据流测试及持续集成部署:(一)Jmeter环境搭建:安装JDK、安装Jmeter、安装Fiddler、安装ant
Jmeter环境搭建 1.安装JDK 官方下载地址:https://www.oracle.com/java/technologies/downloads/ 安装方法:双击jdk安装包,一直下一步安装即 ...
- 菜鸡的Java笔记 Eclipse 的使用
Eclipse 的使用 1. Eclipse 简介 2. Eclipse 中的JDT 的使用 3. Eclipse 中的使用 junit 测试 Eclipse (中文翻 ...
- 菜鸡的Java笔记 第十四 String 类常用方法
/*String 类常用方法 将所有String类的常用方法全部记下来,包括方法名称,参数作用以及类型 一个成熟的编程语言,除了它的语法非常完善之外,那么也需要提供有大量的开发类库 ...
- [loj3462]括号路径
对于两条边$(x_{1},y,c)$和$(x_{2},y,c)$,不难发现$x_{1}$与$x_{2}$完全等价,因此可以合并 重复此过程,合并之后用启发式合并来合并边集(注意自环也可以参与合并,即$ ...