SpringCloud微服务实战——搭建企业级开发框架(三十二):代码生成器使用配置说明
一、新建数据源配置
因考虑到多数据源问题,代码生成器作为一个通用的模块,后续可能会为其他工程生成代码,所以,这里不直接读取系统工程配置的数据源,而是让用户自己维护。
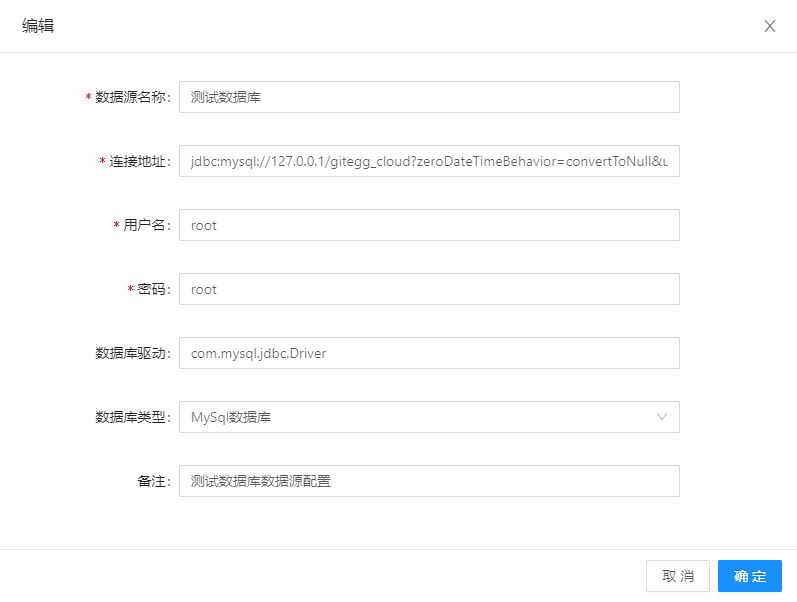
参数说明
- 数据源名称:用于查找区分数据源的名称
- 连接地址 : 连接方式:数据库类型:数据库地址等参数,例:jdbc:mysql://127.0.0.1/gitegg_cloud?zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=utf8&all owMultiQueries=true&serverTimezone=Asia/Shanghai
- 用户名:登录数据库的用户名
- 密码:登录数据库的密码
- 数据库驱动:数据库驱动类型,例:com.mysql.jdbc.Driver(MySQL5 )或 com.mysql.cj.jdbc.Driver(MySQL8 )
- 数据库类型:选择对应的数据库类型,如果有新增可以新增数据字典
- 备注:备注信息
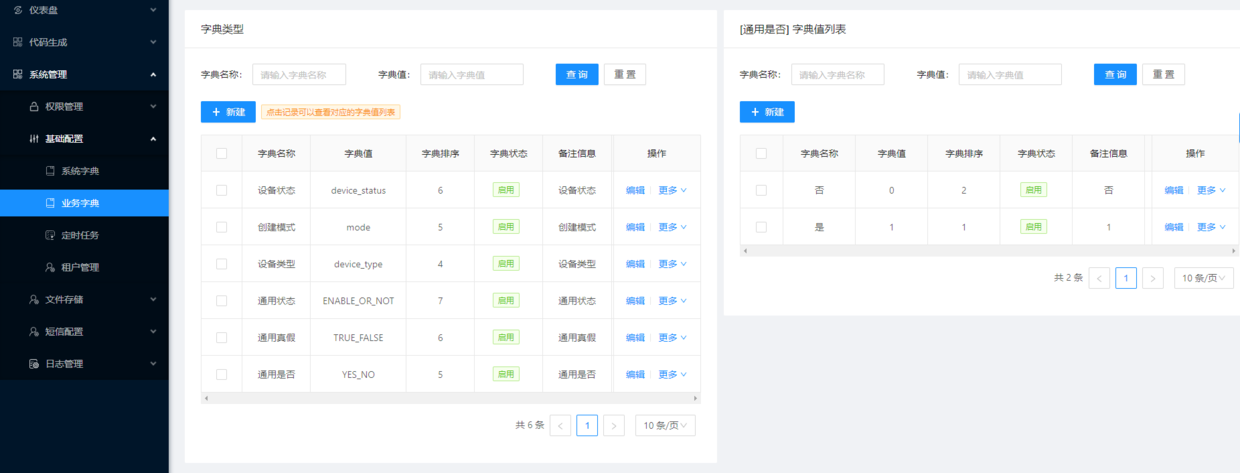
二、新建业务数据字典
界面的增删改查界面会有一些数据字典的下拉框或者单选、多选等基础数据,这些根据具体需要生成代码的表设计提前做好规划,在业务字典中提前建好数据字典。在自定类型表,点击一条记录所在的行即是选中,右侧字典值列表会出现对应的字典值列表。
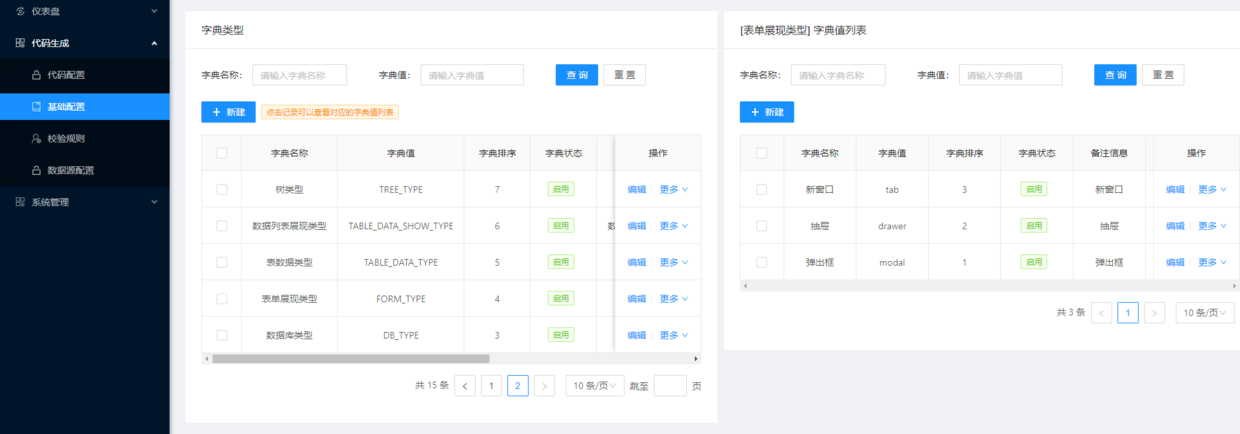
三、代码生成的基础配置
代码生成的基础配置实际也是一类数据字典,但这是只针对代码生成功能模块使用的数据字典,比如在界面上选择的数据库类型、表单展现类型、树类型等、都是获取这里的配置数据。在实际应用开发过程中,可以根据自己的需求进行新增、修改。
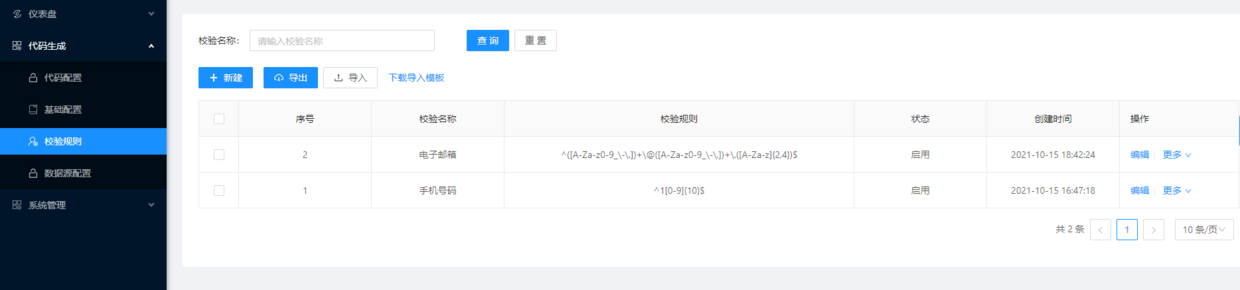
四、校验规则配置
在我们业务开发过程中,无论是界面还是接口,都会对数据字段的长度、大小、类型等进行校验,这里的配置主要是配置数据字段校验的正则表达式,在代码生成时,会在前端代码和后台代码添加校验方法进行数据校验。
五、代码配置(重点)
代码配置是实际代码生成的重点,以上几项配置都是为代码生成做前期准备工作,代码配置模块是实际的针对业务表进行配置,最终生成代码。
1、 新建代码配置
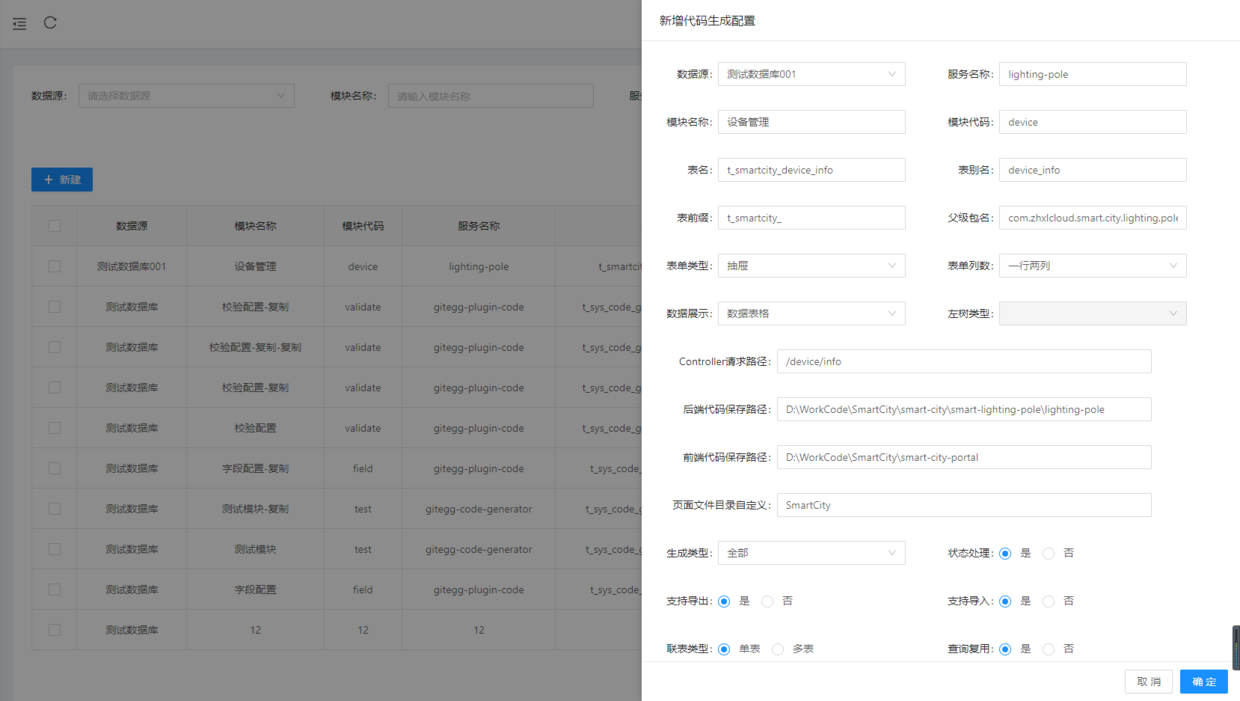
配置参数说明
- 数据源 :选择我们上面配置的需要生成代码的数据库。
- 模块名称:需要生成代码的模块名称,这个名称将用作菜单名称、系统提示等。
- 模块代码:系统在生成代码时会根据模块代码新建对应名称的目录,进行存放该模块的代码。
- 服务名称:微服务注册到Nacos上的名称,框架中这个取得的是微服务pom.xml里的artifactId配置,在生成代码时,微服务名称将加在请求url的前面,请一定确认这个字段的正确性,否则访问不到后台服务。
- 表名 : 需要生成代码的表。
- 表别名 :在生成多表联合代码时,这个作为表的别名在查询语句的mapper文件中使用。
- 表前缀 :在我们定义表时,t_代码是表(table的首字母),下划线后面代码子系统的名称,再后面是模块名称,那么在我们生成代码时,前面的前缀需要去掉,只保留模块名称,即生成代码时的实体类名称。
- 父级包名:定义生成模块代码的包路径,代码将存放在这个包名下。
- 表单类型:在进行增删查改时的展现方式,有弹出框、新打开一个页面、右侧伸缩抽屉等形式
- 表单列数:定义表单字段在表里每行展示几列
- 数据展示:配置数据查询列表的展示形式,有表格、树等形式
- 左树类型: 当数据展示形式包含左侧树时,这里可以选择左侧树的数据类型
- Controller请求路径:配置在Controller代码中的 @RequestMapping 参数,即模块的请求路径
- 后端代码保存路径:后端代码的存放路径,到具体微服务的根目录即可,即src目录的上一级目录,不需要具体到src目录和src下面的目录。
- 前端代码保存路径:前端代码的存放路径,到具体前端代码的根目录即可。
- 页面文件目录自定义: 前端代码默认放到views目录下,不设置的话会使用服务请求和模块代码两级字段开始生成目录,如果需要大的区分,这里可以再设置一级目录。
- 生成类型:有些代码生成可能只有接口,或者只想重新生成页面代码,那么这里可以选择是全部生成,还是只生成后端代码或前端代码。
- 状态处理:具体业务模块中,状态是一个常用的字段,如果要生成的代码有状态字段,那么这里可以选择是否生成对状态相关操作代码。
- 支持导出:配置该模块是否有导出功能。
- 支持导入:配置该模块是否有导入功能。
- 联表类型:配置该模块在操作时,是进行多表操作还是单表操作。
- 查询复用:代码中列表查询(分页或不分页)和单条记录查询可以使用同一条sql,基于性能方面考虑,这里可以选择是生成单独的查询方法,还是复用同一个查询方法。
2、配置代码生成规则
在已建好的代码配置列表中点击"配置规则"按钮,进入到代码生成规则配置页面。如果在上一步中选择的是多表查询,那么这里会进入多表配置界面,如果选择的是单表,那么这里直接进入字段配置界面。
- 配置联表
- 多表配置列表
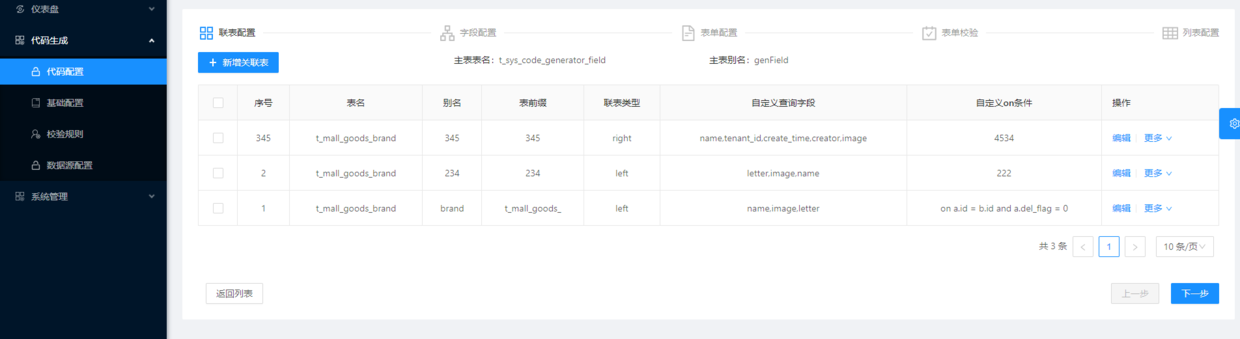
- 多表配置表单

配置参数说明
- 表名 : 选择相同数据源下的表。
- 别名 : 联表查询时,mapper.xml里面SQL语句的表别名。
- 表前缀 : 去除系统和模块标识,只保留实体名称。
- 排序 : 显示排序及在SQL查询时的排序。
- 联表方式 : 表连接方式,LEFT JOIN、RIGHT JOIN、INNER JOIN、UNION、UNION ALL等
- 查询字段 : 此表需要查询的字段
- 自定义on条件: 需要和主表关联的字段及自定义的条件
- 配置字段
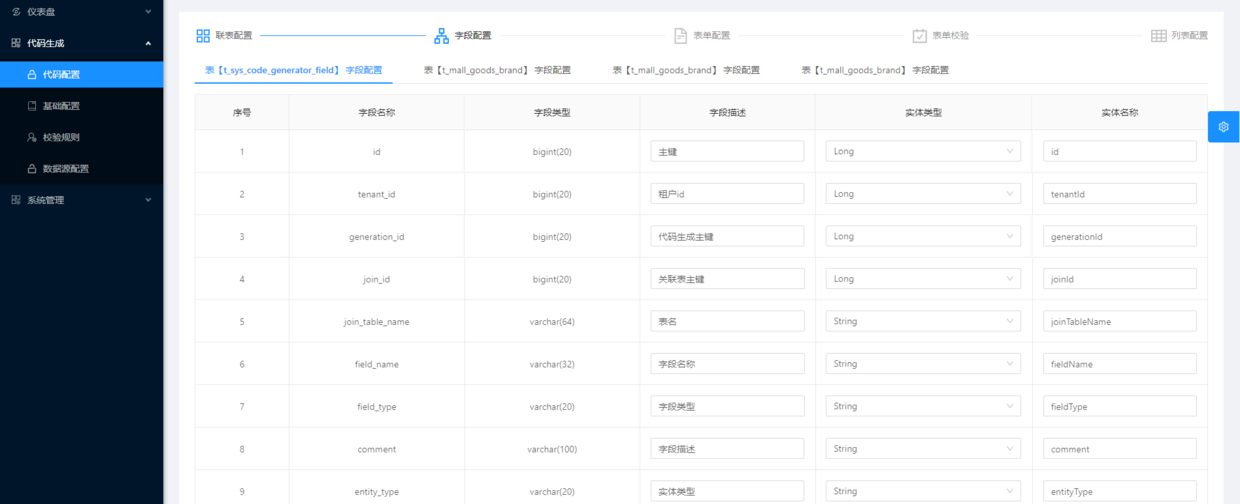
配置参数说明
- 字段描述 : 获取数据表的描述信息,用于字段名称和展示在页面字段的label。
- 字段类型 : 自动转换数据库定义的字段类型为JAVA对应的字段类型。
- 字段名称 : 实体类里面字段的定义。
- 配置表单
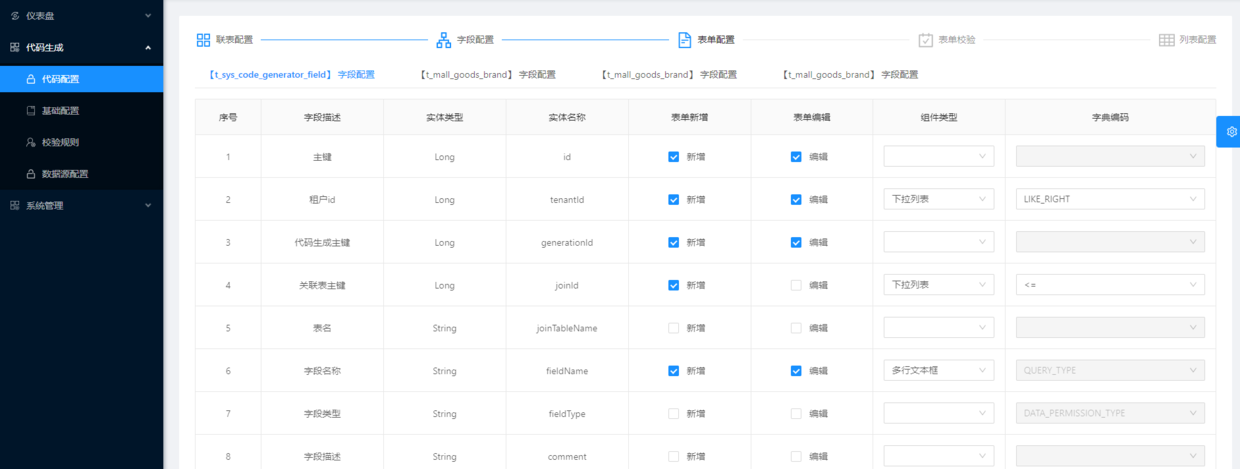
配置参数说明
- 表单新增 : 字段是否展示在界面的新增表单。
- 表单编辑 : 字段是否展示在界面的编辑表单。
- 组件类型 : 字段展示在界面的类型,INPUT、SELECT、CHECKBOX等。
- 字典编码 : 当字段的组件类型为选择类型时,提供选择的填充数据。此数据来自业务字典。
- 配置表单校验
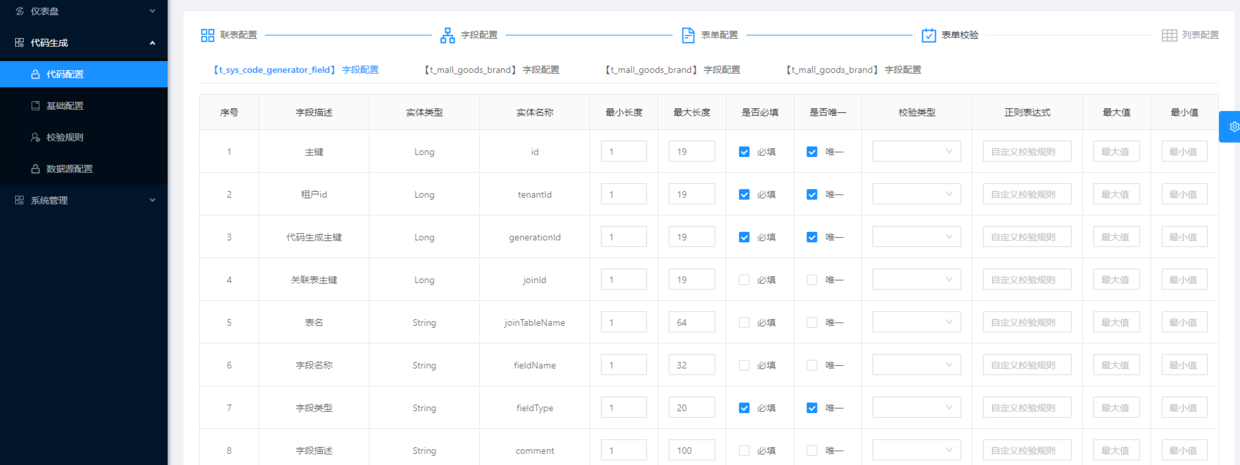
配置参数说明
- 最小长度 : 字段的最小长度,初始值来自数据库字段定义。
- 最大长度 : 字段的最大长度,初始值来自数据库字段定义。
- 是否必填 : 字段是否必填。
- 是否唯一 : 字段是否唯一,如果配置为唯一,那么在表单新增或编辑时会自动生成校验方法。
- 校验类型 : 选择已配置的通用正则表达式。
- 正则表达式 : 对于非通用的特殊字段,可以自定义正则表达式。
- 最大值 : 当字段为数值类型时,字段的最大值,初始值来自数据库字段定义。
- 最小值 : 当字段为数值类型时, 字段的最小值,初始值来自数据库字段定义。
- 配置数据展示列表
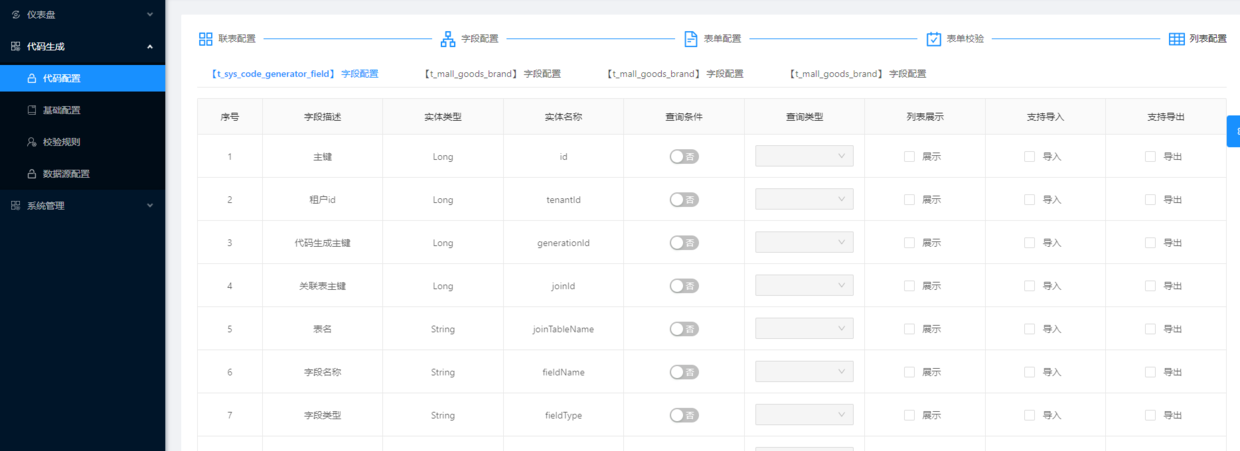
配置参数说明
- 查询条件 : 是否是查询条件,展示在界面的查询条件区域。
- 查询类型 : 字段的查询类型,等于、不等于、大于、小于等。
- 列表展示 : 是否展示在查询结果的数据表格中。
- 支持导入 : 字段是否支持导入,在代码配置中支持导入时,此字段生效。
- 支持导出 : 字段是否支持导出,在代码配置中支持导出时,此字段生效。
- 完成保存配置,在列表中点击生成代码按钮,生成代码。
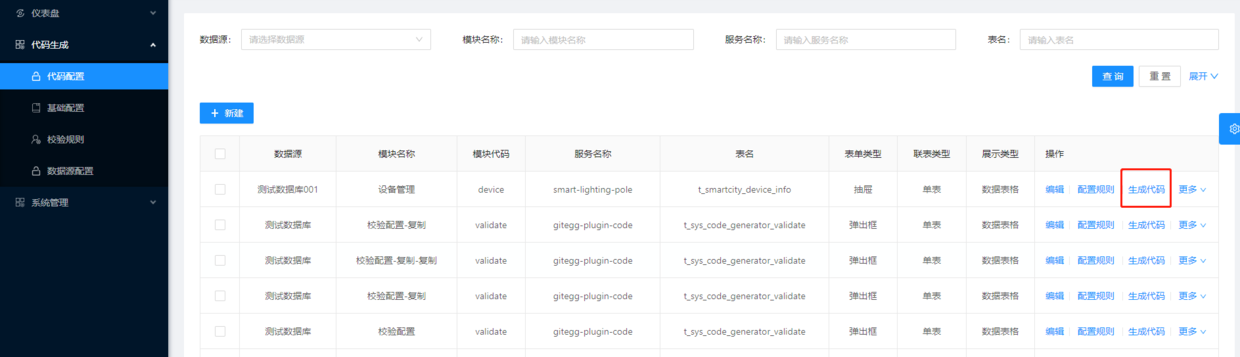
六、配置资源权限
执行完代码生成操作之后,会在后台代码的mapper.xml同级目录生成一个同名的.sql文件,这里面是访问新生成代码模块的资源菜单权限脚本。
源码地址:
Gitee: https://gitee.com/wmz1930/GitEgg
GitHub: https://github.com/wmz1930/GitEgg
SpringCloud微服务实战——搭建企业级开发框架(三十二):代码生成器使用配置说明的更多相关文章
- SpringCloud微服务实战——搭建企业级开发框架(十二):OpenFeign+Ribbon实现负载均衡
Ribbon是Netflix下的负载均衡项目,它主要实现中间层应用程序的负载均衡.为Ribbon配置服务提供者地址列表后,Ribbon就会基于某种负载均衡算法,自动帮助服务调用者去请求.Ribbo ...
- SpringCloud微服务实战——搭建企业级开发框架(十五):集成Sentinel高可用流量管理框架【熔断降级】
Sentinel除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一.由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积.Sentinel ...
- SpringCloud微服务实战——搭建企业级开发框架(十):使用Nacos分布式配置中心
随着业务的发展.微服务架构的升级,服务的数量.程序的配置日益增多(各种微服务.各种服务器地址.各种参数),传统的配置文件方式和数据库的方式已无法满足开发人员对配置管理的要求: 安全性:配置跟随源代码保 ...
- SpringCloud微服务实战——搭建企业级开发框架(十四):集成Sentinel高可用流量管理框架【限流】
Sentinel 是面向分布式服务架构的高可用流量防护组件,主要以流量为切入点,从限流.流量整形.熔断降级.系统负载保护.热点防护等多个维度来帮助开发者保障微服务的稳定性. Sentinel 具有 ...
- SpringCloud微服务实战——搭建企业级开发框架(十六):集成Sentinel高可用流量管理框架【自定义返回消息】
Sentinel限流之后,默认的响应消息为Blocked by Sentinel (flow limiting),对于系统整体功能提示来说并不统一,参考我们前面设置的统一响应及异常处理方式,返回相同的 ...
- SpringCloud微服务实战——搭建企业级开发框架(十九):Gateway使用knife4j聚合微服务文档
本章介绍Spring Cloud Gateway网关如何集成knife4j,通过网关聚合所有的Swagger微服务文档 1.gitegg-gateway中引入knife4j依赖,如果没有后端代码编 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十八):搭建ELK日志采集与分析系统
一套好的日志分析系统可以详细记录系统的运行情况,方便我们定位分析系统性能瓶颈.查找定位系统问题.上一篇说明了日志的多种业务场景以及日志记录的实现方式,那么日志记录下来,相关人员就需要对日志数据进行 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十四):SpringCloud + Docker + k8s实现微服务集群打包部署-Maven打包配置
SpringCloud微服务包含多个SpringBoot可运行的应用程序,在单应用程序下,版本发布时的打包部署还相对简单,当有多个应用程序的微服务发布部署时,原先的单应用程序部署方式就会显得复杂且 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十六):使用Spring Cloud Stream实现可灵活配置消息中间件的功能
在以往消息队列的使用中,我们通常使用集成消息中间件开源包来实现对应功能,而消息中间件的实现又有多种,比如目前比较主流的ActiveMQ.RocketMQ.RabbitMQ.Kafka,Stream ...
- SpringCloud微服务实战——搭建企业级开发框架(三十五):SpringCloud + Docker + k8s实现微服务集群打包部署-集群环境部署
一.集群环境规划配置 生产环境不要使用一主多从,要使用多主多从.这里使用三台主机进行测试一台Master(172.16.20.111),两台Node(172.16.20.112和172.16.20.1 ...
随机推荐
- C++中gSOAP的使用
目录 SOAP简介 gSOAP 准备工作 头文件 构建客户端应用程序 生成soap源码 建立客户端项目 构建服务端应用程序 生成SOAP源码 建立服务端项目 打印报文 SOAP测试 项目源码 本文主要 ...
- Linux&C open creat read write lseek 函数用法总结
一:五个函数的参数以及返回值. 函数 参数 返回值 open (文件名,打开方式以及读 ...
- webpack 之开发环境优化 HMR
webpack 之开发环境优化 HMR // webpack.config.js /** * HMR hot module replacement 热模块替换 / 模块热替换 * 作用:一个模块发生变 ...
- Go语言核心36讲(Go语言实战与应用五)--学习笔记
27 | 条件变量sync.Cond (上) 前导内容:条件变量与互斥锁 我们常常会把条件变量这个同步工具拿来与互斥锁一起讨论.实际上,条件变量是基于互斥锁的,它必须有互斥锁的支撑才能发挥作用. 条件 ...
- dart系列之:dart类中的泛型
目录 简介 为什么要用泛型 怎么使用泛型 类型擦除 泛型的继承 泛型方法 总结 简介 熟悉JAVA的朋友可能知道,JAVA在8中引入了泛型的概念.什么是泛型呢?泛型就是一种通用的类型格式,一般用在集合 ...
- ECharts + jsp 图表
... <%@ page language="java" pageEncoding="UTF-8"%> <%@page import=&quo ...
- Matplotlib (一)
Matplotlib 用于 创建出版质量图标的绘图工具库 目的是为python构建一个 Matlab 式的绘图接口 import matplotlib.pyplot as plt pyplot 模块包 ...
- Ubuntu軟件商店加載失敗的解決方法
Ubuntu軟件商店有的时候加载不出来,先用下面的试试 sudo apt install python-apt 如果不行,继续下面的方法 打开终端,运行下面的命令: sudo apt-get upda ...
- linux 系统ssh超时设置
1.修改client端的etc/ssh/ssh_config添加以下:(在没有权限改server配置的情形下) ServerAliveInterval 60 #client每隔60秒发送一次请求给se ...
- [atARC114F]Permutation Division
由于是排列,即任意两个数字都各不相同,因此字典序最大的$q_{i}$就是将每一段的第一个数从大到小排序 接下来,考虑第一个元素,也就是每一段开头的最大值,分类讨论: 1.当$p_{1}\le k$时, ...