大数据学习day32-----spark12-----1. sparkstreaming(1.1简介,1.2 sparkstreaming入门程序(统计单词个数,updateStageByKey的用法,1.3 SparkStreaming整合Kafka,1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中)
1. Spark Streaming
1.1 简介(来源:spark官网介绍)
Spark Streaming是Spark Core API的扩展,其是支持可伸缩、高吞吐量、容错的实时数据流处理。Spark Streaming的数据源可以为kafka,Flume,Kinesis或者是TCP socket,并且这些数据可以使用复杂的算法来处理,这些算法用高级函数表示,如map、reduce、join和window。最后被处理的数据可以被push到文件存储系统,数据库,live dashboards。实际上,我们也可以使用spark的machine learning和graph processing算法处理数据流

实际上,Spark Streaming是如下工作的。Spark Streaming 接收实时数据并将这些数据划分成多批小批次数据,然后由spark引擎处理,以批量生成最终的结果流。

Spark流提供了一种高级抽象,称为离散流或DStream,它表示连续的数据流。DStreams可以从Kafka、Flume和Kinesis等源的输入数据流创建,也可以通过对其他DStreams应用高级操作创建。实际上,DStream内部为RDDs序列。
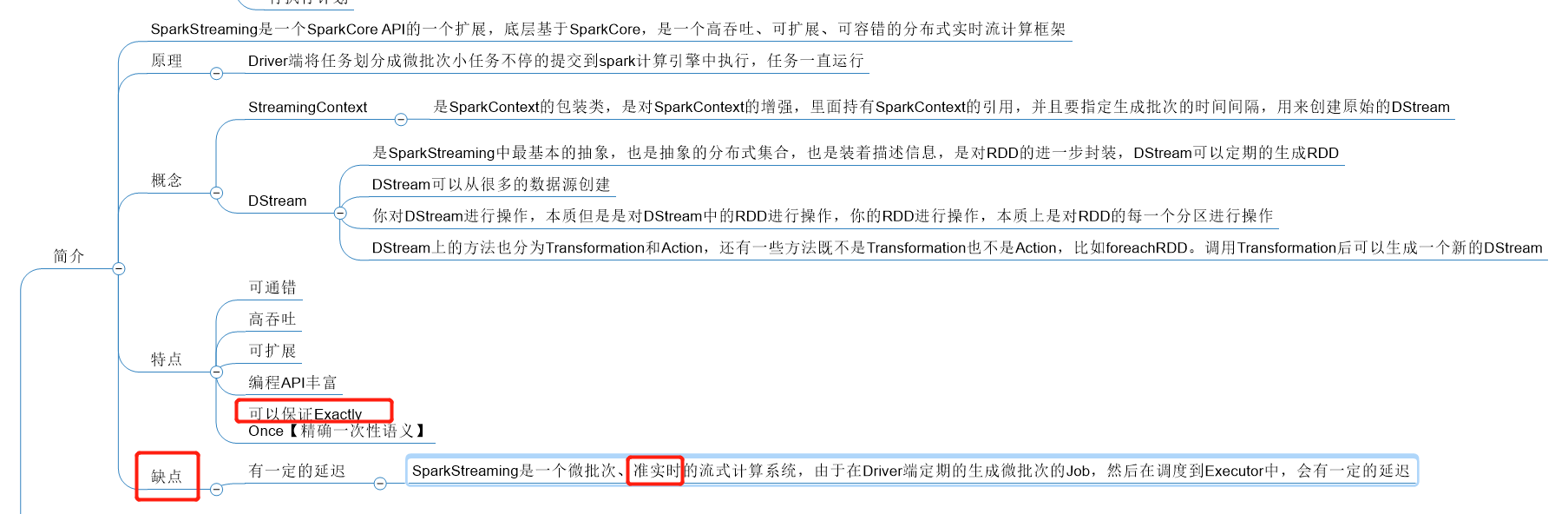
补充:sparkstreaming是一个高容错,可扩展,编程api丰富的分布式实时流计算框架,其是微批次、准实时的
高容错:当某个task所在的机器挂掉之后,其会被调度到其他的机器上去运行。而task是自己维护读取数据偏移量的,若task不运行完,其实不会记录偏移量的(事务)。所以是高容错的
高吞吐:spark读取完数据可以先放内存中(装满放磁盘),所以其可以将大量的数据存到内存中去
可扩展:当数据量增加时,可以增加rdd的数量来加快运算
编程api丰富:这是和storm比较,若是和flink比较则没有这个优点
注意:不管有没有数据,只要到了自己设置批次的时间(new StreamingContext时设置),driver端就会调度一批任务去executor中去。每个批次的任务处理的数据都是这段时间读取的数据
1.2 Spark Streaming入门程序
需求:利用Spark Streaming实时统计单词的个数
linux上安装nc:
yum -y install nc
在安装有nc的节点上开通一个socket服务
nc -lk 8888
SparkStreamingWordCount
object SparkStreamingWordCount {
def main(args: Array[String]): Unit = {
// 创建sparkcontext
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
val sc= new SparkContext(conf)
// 设置日志的级别
sc.setLogLevel("WARN")
// StreamingContext是对SparkContext包装和增强,后面传入的时间代表隔多久时间产生一个批次
val ssc: StreamingContext = new StreamingContext(sc, Seconds(5))
// 获取Dstream,ReceiverInputDStream为Dstream的孙子类
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("feng05",8888)
// 对Dstream进行操作
val reduced: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//Action
reduced.print()
//开启spark streaming
ssc.start()
//让程序挂起,一直运行
ssc.awaitTermination()
}
}
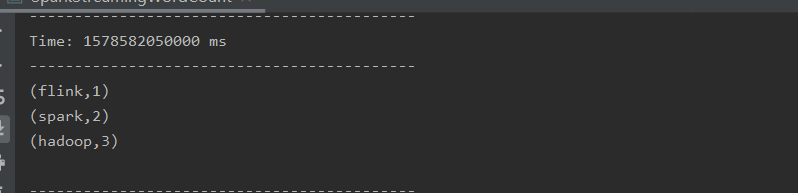
此时运行该程序,然后在socket服务中心输入一些单词,如下

在程序中会做出单词统计(此种形式只会统计当前数据,不会累加历史的数据),如下(对应最后一行)
现在需要累加历史批次的数据,代码可写成如下
UpdateStageWordCount


object UpdateStageWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
//创建StreamingContext,并指定批次生成的时间
val ssc = new StreamingContext(conf, Milliseconds(5000))
//设置日志级别
ssc.sparkContext.setLogLevel("WARN")
//对数据进行处理,累加历史批次的数据
//累加历史数据就要将中间结果保存起来【要求保存到靠谱的存储系统(安全),以后任务失败可以恢复State数据】
//设置checkpoint目录,保存历史状态
ssc.checkpoint("file:///javafile/spark/ck")
//创建DStream
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("feng05", 8889)
//Transformation 开始
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
//updateFunc: (Seq[V], Option[S]) => Option[S]
//第一个参数:当前批次计算的结果
//第二个参数:初始值或中间累加结果
val updateFunc: (Seq[Int], Option[Int]) => Some[Int] = (s: Seq[Int], o: Option[Int]) => {
//将当前批次累加的结果和初始值或中间累加结果进行累加
Some(s.sum + o.getOrElse(0))
}
val reduced: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc)
//Transformation 结束
//触发Action
reduced.print()
//开启Streaming程序
ssc.start()
//挂起一直运行
ssc.awaitTermination()
}
}
结果
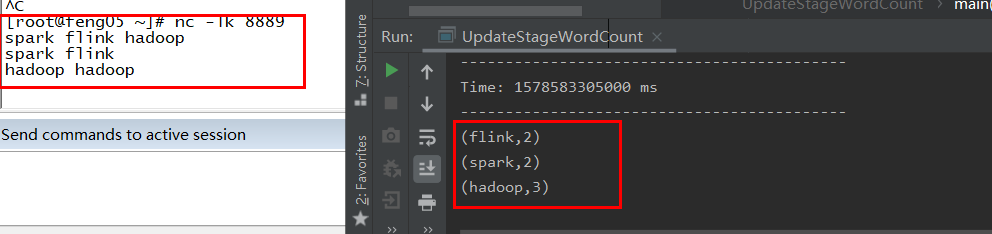
此处注意的两个点:(1)将中间结果checkpoint保存起来(2)updateStateByKey的用法
updateStateByKey()的用法
源码中有7中重载的方法,此处讲传入参数仅为一个函数的重载方法(最简单的形式)
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* In every batch the updateFunc will be called for each state even if there are no new values.
* Hash partitioning is used to generate the RDDs with Spark's default number of partitions.
* @param updateFunc State update function. If `this` function returns None, then
* corresponding state key-value pair will be eliminated.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner()) // 没定义分区器时,使用默认的分区器
}
中文翻译:
返回一个新的“状态”DStream,其中通过对键的前一个状态和每个键的新值应用给定的函数来更新每个键的状态。在每个批处理中,即使没有新值,也会为每个状态调用updateFunc。散列分区用于生成具有Spark默认分区数的RDDs。
updateFunc函数中:
第一个参数:当前批次每个key新增值的集合(key为调用updateStateByKey的DStream中的key),如当新输入的单词为:hadoop hadoop spark flink,则此集合为[2,1,1]
第二个参数:当前键保存的前一个状态(本例中即为初始值或中间累加结果)
补充:(第二遍的理解)
//第一个参数:表示当前key对应的所有值
//第二个参数:Option[S] 是当前key的历史状态,返回的是新的封装的数据。

这块源码还有些看不懂(以后回头看)
foreachRdd:
其实一个普通的方法,既不是active算子也不是转化算子,用来取dstream中的rdd
1.3 SparkStreaming整合Kafka
SparkStreaming跟kafka进行整合
- 导入跟kafka整合的依赖
- 跟kafka整合,创建直连的DStream【即使用createDirectStream创建,使用底层的消费API,效率更高】
消费者直接连接到kafka的leader分区进行消费
直连的方式,RDD的分区数量和kafka的分区数量是一一对应的【数目一样】
官网上对这个新接口(createDirectStream)的介绍很多,大致就是不与zookeeper交互,直接去kafka中读取数据,自己维护offset,于是速度比KafkaUtils.createStream要快上很多。但有利就有弊:无法进行offset的监控。

两篇相关博客:
http://blog.selfup.cn/1665.html
https://www.cnblogs.com/hd-zg/p/6188287.html
(1)整合
package com._51doit import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Milliseconds, StreamingContext} object KafkaStreamingWordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
//创建StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Milliseconds(5000))
// 设置日志级别
ssc.sparkContext.setLogLevel("WARN")
val topics = Array("wordcount") //SparkSteaming跟kafka整合的参数
//kafka的消费者默认的参数就是每5秒钟自动提交偏移量到Kafka特殊的topic中: __consumer_offsets
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "feng05:9092,feng06:9092,feng07:9092",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"group.id" -> "g005",
"auto.offset.reset" -> "earliest"//如果没有记录偏移量,第一次从最开始读,有偏移量,接着偏移量读
//, "enable.auto.commit" -> (false: java.lang.Boolean) //消费者不自动提交偏移量
)
// 跟kafka进行整合,需要引入跟kafka整合的依赖
//createDirectStream更加高效,使用的是kafka底层的消费API,消费者直接连接到Kafka的Leader分区进行消费
//直连方式,RDD的分区数量和Kafka的分区数量是一一对应的【数目一样】
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent, //调度task到Kafka所在的节点
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //指定订阅Topic的规则
)
// kafkaDStream.print()
// val lines: DStream[String] = kafkaDStream.map(r=>r.key())
val lines: DStream[String] = kafkaDStream.map(r => r.value())
lines.print()
ssc.start()
ssc.awaitTermination()
}
}
(2)将统计到的数据统计写入redis
package com._51doit import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Milliseconds, StreamingContext}
import redis.clients.jedis.Jedis object KafkaStreamingWordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
//创建StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Milliseconds(5000))
// 设置日志级别
ssc.sparkContext.setLogLevel("WARN")
val topics = Array("wordcount") //SparkSteaming跟kafka整合的参数
//kafka的消费者默认的参数就是每5秒钟自动提交偏移量到Kafka特殊的topic中: __consumer_offsets
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "feng05:9092,feng06:9092,feng07:9092",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"group.id" -> "g01",
"auto.offset.reset" -> "earliest"//如果没有记录偏移量,第一次从最开始读,有偏移量,接着偏移量读
//, "enable.auto.commit" -> (false: java.lang.Boolean) //消费者不自动提交偏移量
)
// 跟kafka进行整合,需要引入跟kafka整合的依赖
//createDirectStream更加高效,使用的是kafka底层的消费API,消费者直接连接到Kafka的Leader分区进行消费
//直连方式,RDD的分区数量和Kafka的分区数量是一一对应的【数目一样】
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent, //调度task到Kafka所在的节点
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //指定订阅Topic的规则
)
// kafkaDStream.print()
// val lines: DStream[String] = kafkaDStream.map(r=>r.key())
val lines: DStream[String] = kafkaDStream.map(r => r.value())
val words: DStream[String] = lines.flatMap(_.split(" "))
val WordAndOne: DStream[(String, Int)] = words.map((_,1))
// 计算当前批次
val reduced: DStream[(String, Int)] = WordAndOne.reduceByKey(_+_)
// 将当前批次数据和历史批次数据进行累加
reduced.foreachRDD(rdd => {
// 将数据收集到driver端
val res: Array[(String, Int)] = rdd.collect()
//将数据写入到Redis
//创建Jedis
val jedis: Jedis = new Jedis("feng05", 6379)
jedis.auth("feng")
jedis.select(2)
res.foreach(t => {
jedis.hincrBy("Streaming_wordcount", t._1, t._2)
})
jedis.close()
})
// lines.print()
ssc.start()
ssc.awaitTermination()
}
}
1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中
JedisConnectionPool(redis连接池代码)
package utils
import redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig}
object JedisConnectionPool {
private val config: JedisPoolConfig = new JedisPoolConfig()
config.setMaxTotal(20) //设置最大的连接数
config.setMaxIdle(10) // 设置最大空闲连接数
//timeout等待可用连接的最大时间,单位毫秒,默认值为-1,表示永不超时。
private val pool: JedisPool = new JedisPool(config, "feng05", 6379,10000,"feng")
def getConnection: Jedis ={
pool.getResource
}
}
业务代码
package com._51doit import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Milliseconds, StreamingContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{CanCommitOffsets, ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import redis.clients.jedis.Jedis
import utils.JedisConnectionPool object KafkaStreamingWordCountManageOffset {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
//创建StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Milliseconds(5000))
// 设置日志级别
ssc.sparkContext.setLogLevel("WARN")
val topics = Array("wordcount") //SparkSteaming跟kafka整合的参数
//kafka的消费者默认的参数就是每5秒钟自动提交偏移量到Kafka特殊的topic中: __consumer_offsets
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "feng05:9092,feng06:9092,feng07:9092",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"group.id" -> "g03",
"auto.offset.reset" -> "earliest"//如果没有记录偏移量,第一次从最开始读,有偏移量,接着偏移量读
//, "enable.auto.commit" -> (false: java.lang.Boolean) //消费者不自动提交偏移量
)
// 跟kafka进行整合,需要引入跟kafka整合的依赖
//createDirectStream更加高效,使用的是kafka底层的消费API,消费者直接连接到Kafka的Leader分区进行消费
//直连方式,RDD的分区数量和Kafka的分区数量是一一对应的【数目一样】
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent, //调度task到Kafka所在的节点
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //指定订阅Topic的规则
)
// 调用完createDirectStream后,直接用kafkaDStream调用foreeachRDD,,只有KafkaRDD中有偏移量
kafkaDStream.foreachRDD(rdd => {
// println(rdd.collect().toBuffer)
// 计算当前批次的数据
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val lines: RDD[String] = rdd.map(r => r.value())
val words: RDD[String] = lines.flatMap(_.split(" "))
val WordAndOne: RDD[(String, Int)] = words.map((_,1))
val reduced: RDD[(String, Int)] = WordAndOne.reduceByKey(_+_)
// 触发action
reduced.foreachPartition(it => {
//在Executor端获取redis连接
val jedis: Jedis = JedisConnectionPool.getConnection
jedis.select(1)
// 将分区中的结果写入redis
it.foreach(t => {
jedis.hincrBy("Streaming_wordcount", t._1, t._2)
})
// 将连接还回redis连接池
jedis.close()
})
//再更新这个批次每个分区的偏移量
//异步提交偏移量,将偏移量写入到Kafka特殊的topic中了
kafkaDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
ssc.start()
ssc.awaitTermination()
}
}
注意:只有kafkardd中有偏移量,若想获取偏移量,则需要通过此rdd获取
asdas
大数据学习day32-----spark12-----1. sparkstreaming(1.1简介,1.2 sparkstreaming入门程序(统计单词个数,updateStageByKey的用法,1.3 SparkStreaming整合Kafka,1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中)的更多相关文章
- 大数据学习day33----spark13-----1.两种方式管理偏移量并将偏移量写入redis 2. MySQL事务的测试 3.利用MySQL事务实现数据统计的ExactlyOnce(sql语句中出现相同key时如何进行累加(此处时出现相同的单词))4 将数据写入kafka
1.两种方式管理偏移量并将偏移量写入redis (1)第一种:rdd的形式 一般是使用这种直连的方式,但其缺点是没法调用一些更加高级的api,如窗口操作.如果想更加精确的控制偏移量,就使用这种方式 代 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- 我的笔记本电脑瞬间扩大一个T的容量!
前言 不知道有多少人在家里搭建中央存储设备的,也就是NAS.这个东西在我日常生活中,存储了大量的个人资料,家人们的照片,技术的资料,还有各种高清影视剧.搭配公网的IP,可以真正做到,任何时候任何地点的 ...
- ELK 脚本自动化删除索引
kibana有自带接口,可通过自带的API接口 通过传参来达到删除索引的目的. # 删除15天前的索引 curl -XDELETE "http://10.228.81.161:9201/pa ...
- Java 网络编程 - 总结概述
IP地址 IP地址IntAddress 唯一定位一台网络上的计算机 127.0.0.1:本地localhost IP地址的分类 ipV4/ipV6 ipV4:127.0.0.1,4个字节组成:0~25 ...
- Java测试开发--Java基础知识(二)
一.java中8大基本类型 数值类型:byte.short.int .float.double .long 字符类型:char 布尔类型:boolean 二. 封装:将属性私有化,不允许外部数据直接访 ...
- 后台管理系统:vue&node&MongoDB(一)
后台管理系统 使用工具: Vue Node Mongodb Element-ui 一.后台(Node+Mongodb) 前期准备: 需要下载的包: mongooes -------- ...
- js判断是否是同一域名
可以判断自己的网页是否是嵌入别的网页中 /** * 是否相同域名 * @returns {boolean} * @constructor */ function SameDomain() { try ...
- spring boot+vue实现H5聊天室客服功能
spring boot+vue实现H5聊天室客服功能 h5效果图 vue效果图 功能实现 spring boot + webSocket 实现 官方地址 https://docs.spring.io/ ...
- 我罗斯方块最终篇(Interface类)
负责的任务 游戏过场及界面设计 Interface类的基础实现 根据队友需求完善Interface类功能 Interface类的本地测试 辅助队友改良游戏操作 代码要点 我们主要是通过控制台进行界面渲 ...
- 大爽Python入门教程 2-1 认识容器
大爽Python入门公开课教案 点击查看教程总目录 1 什么是容器 先思考这样一个场景: 有五个学生,姓名分别为: Alan, Bruce, Carlos, David, Emma. 需要给他们都打一 ...
- DECODE 与CASE WHEN 的比较
1.DECODE 只有Oracle 才有,其它数据库不支持; 2.CASE WHEN的用法, Oracle.SQL Server. MySQL 都支持; 3.DECODE 只能用做相等判断,但是可以配 ...